






在机器学习过程中无法收集足够多的有效样本,导致机器学习算法没有足够的数据进行训练。但是在机器学习过程中,并非所有的特征但是重要的,,通过特征提取(feature extraction)进行降维的目的就是对原始特征集合P(original)进行变换,变换后得到的新的特征集合记为P(new),这里P(original)>P(new),but P(new)保留了大部分信息。通过牺牲一小部分数据减少特征的数量,并且保证能够做出准确的预测。
特征提取存在一个缺点,新产生的特征对人类而言是不可解释的,新特征具有训练模型的能力,但是在我们看来只是一些随机数字的集合。如果希望能够解释模型的话,可以选择特征选择来进行数据降维。
9.1 使用主成分进行特征降维
对于给定的数据在保留信息的同时减少特征的数量
scikit-learn库中的主成分分析工具(PCA)
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn import datasets
#加载数据
digits = datasets.load_digits() #玩具数据集
#标准化特征矩阵
features = StandardScaler().fit_transform(digits.data)
#创建可以保留99%信息量(用方差表示)的PCA
pca = PCA(n_components=0.99,whiten=True) #保留99%的信息
#执行PCA
features_pca = pca.fit_transform(features)
#显示结果
print("Original number of features:",features.shape[1])
print("Reduced number of features:",features_pca.shape[1])
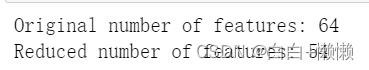
PCA参数
n_components:大于1,则n_components将会返回i和这个值相同数量的特征,但随着而来是的是如何选择合适的特征向量。
大于0小于1,pca返回维持一定的信息量(在算法中,用方差代表信息量)的最少特征数,一般取值为0.95、0.99意味着保留保留99%、95%的原始特征数
whiten=True:对每一个主成分都进行转换以保证它们的平均值为0、方差为1.
svd_solver=“randomizad”:代表使用随机方法找到第一个主成分
主成分分析方法(principal Component Analysis,PCA)一种主流的线性降维方法。PCA将样本数据映射到特征矩阵的主成分空间(主成分空间保留了大部分的数据差异,一般具有更低的维度)是一种无监督学习方法,它只需要考虑特征矩阵而不需要目标向量的信息。
9.2 对线性不可分数据进行特征降维
Kernel PCA(核主成分分析,PCA的一种扩展)进行非线性降维
from sklearn.decomposition import PCA,KernelPCA
from sklearn.datasets import make_circles
#创建线性不可分数据
features, _ = make_circles(n_samples=1000,random_state=1,noise=0.1,factor=0.1) #make_circles生成一个模拟的数据集(线性不可分数据,其中一个分类被另一个分类从外部完全包围),两个分类,两个特征的目标向量,
#应用基于径向基函数(Radius Basis Function,RBF)核的Kernel PCA方法
kpca = KernelPCA(kernel="rbf", gamma=15, n_components=1)
features_kpca = kpca.fit_transform(features)
#显示结果
print("Original number of features:",features.shape[1])
print("Reduced number of features:",features_kpca.shape[1])
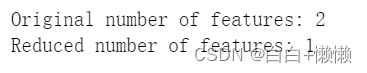
PCA能够降低矩阵特征矩阵的维度(例如:减少特征的数量)。标准PCA使用线性映射减少特征的数量。如果数据是线性可分(可以用一条直线或者超平面将两类数据分开)则PCA的处理效果会很好;如果数据是不可分的(例如,只能用曲线边界分类的数据),则线性变换的效果不好。
线性PCA对数据进行降维,两类数据会被线性映射到第一个主成分上。
核(kernel,核函数):能够将线性不可分数据映射到更高的维度,数据在这个维度是线性可分的,这种叫做核机制(kernel trick)。 核机制可以看作是映射数据一种方法。scikit-learn的KernelPCA中提供了很多可用的核函数。,使用参数kernel来指定。 高斯径向基函数(rbf)、多项式核(poly)、sigmoid核甚至可以指定一个线性映射。,利用它可以得到于与标准PCA相同的结果。
KernerlPCA需要指定很多参数。
9.3 通过最大化类间可分性进行特征降维
对数据进行降维操作,将处理后的数据应用于分类器
from sklearn import datasets
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
#加载鸢尾花数据集
iris = datasets.load_iris()
features = iris.data
target = iris.target
#创建并运行LDA,然后用它对特征做变换
lda = LinearDiscriminantAnalysis(n_components=1)
features_lda = lda.fit(features,target).transform(features)
#打印特征的数量
print("Original number of features:",features.shape[1])
print("Reduced number of features:",features_lda.shape[1])
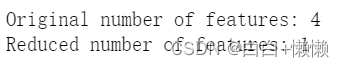
可以使用参数explained_variance_ratio_来查看每个成分保留的信息量(即数据的差异)的情况。
lda.explained_variance_ratio_ #可以看到单个成分保留了99%的信息量

LDA是一种分类方法,也是一种常用的降维方法。LDA与PCA的原理相似,它将特征空间映射到较低维的空间。在PCA中,只需要关注数据差异最大化的成分轴,;在LDA中,找到使得类间差异最大的主成分轴。
LDA包含参数n_components,表示需要返回的特征数量。为了找出n_components的最优解,可以参考explained_variance_ratio_ 的输出,该排序数组表示每个输出的特征所保留的信息量,例如:
lda.explained_variance_ratio_

可以运行LinearDiscriminantAnalysis(将参数n_components设置为None)返回每个成分特征保留的信息量的百分比,然然后计算需要多少个成分特征才能保留高于阈值(通常为0.95、0.99)的信息量:
#创建并运行LDA
lda = LinearDiscriminantAnalysis(n_components=None)
deatures_lda = lda.fit(features,target)
#获取方差的百分比数组
lda_var_ratios=lda.explained_variance_ratio_
#定义函数
def select_n_components(var_ratio,goal_var:float) -> int:
#设置总方差的初始值
total_variance = 0.0
#设置特征数量的初始值
n_components=0
#遍历方差百分比数组的元素
for explained_variance in var_ratio:
#将该百分比加入方差
total_variance += explained_variance
#n_components的值加1
n_components += 1
#如果达到目标阈值
if total_variance >= goal_var:
#结束遍历
break
#返回n_components的值
return n_components
#运行函数
select_n_components(lda_var_ratios,0.95)

9.4 使用矩阵分解法进行特征降维
对非负特征矩阵进行降维
使用非负矩阵分解法(Non-Negative Matrix Factorization,NMF)
from sklearn.decomposition import NMF
from sklearn import datasets
#加载数据
digits = datasets.load_digits()
#加载特征矩阵
features = digits.data
#创建NMF,进行变化并应用
nmf = NMF(n_components=10,random_state=1)
features_nmf = nmf.fit_transform(features)
#显示结果
print("Original number of features:",features.shape[1])
print("Reduced number of features:",features_nmf.shape[1])
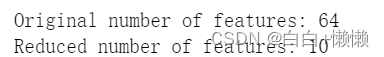
NMF简单的来讲就是将特征矩阵分解成两个矩阵的乘积形式从而降低特征矩阵的维数,但是只针对于非负特征矩阵。NMF不会告诉我们原始数据中保留那些数据。
9.5 对稀疏数据进行特征降维
对稀疏特征矩阵进行特征降维操作
截断奇异值分解(Truncated Singular Value Decomposition,TSVD)法
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import TruncatedSVD
from scipy.sparse import csr_matrix
from sklearn import datasets
import numpy as np
#加载数据
digits = datasets.load_digits()
#标准化特征矩阵
features = StandardScaler().fit_transform(digits.data)
#生成系数矩阵
features_sparse = csr_matrix(features)
#创建tsvd
tsvd = TruncatedSVD(n_components=10)
#在稀疏矩阵上执行TSVD
features_sparse_tsvd = tsvd.fit(features_sparse).transform(features_sparse)
#显示结果
print("Original number of features:",features.shape[1])
print("Reduced number of features:",features_sparse_tsvd.shape[1])
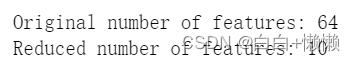
PCA常常在某一步骤使用非截断奇异值分解(SVD)法。在常规SVD中,对于给定的d个特征,SVD将创建d x d维的因子矩阵,而TSVD将返回n x n 维的因子矩阵,其中n是预先指定的参数。与PCA相比,TSVD的优势在于它更适用于稀疏矩阵
TSVD输出值的符号回在多次拟合中不断变化(这是由其使用随机数生成器的方式决定的)。简单的解决办法是对每个预处理的管道只使用一次fit方法,然后多次使用transform方法。
TSVD需要通过参数n_components指定想要输出的特征数。
#对前三个成分的信息量占比求和
tsvd.explained_variance_ratio_[0:3].sum()

为摆脱手动调参,可以将调参过程实现自动化
创建一个运行TSVD的函数,使这个过程自动化(将参数n_components设置为原始特征数量减1),然后计算能够保留所需信息量的特征数量
#用比原特征数量小1的值为n_components的值,创建并运行TSVD
tsvd = TruncatedSVD(n_components=features_sparse.shape[1]-1)
features_tsvd = tsvd.fit(features)
#获取方差百分比数组
tsvd_var_ratios = tsvd.explained_variance_ratio_
#定义函数
def select_n_components(var_ratio,goal_var):
#设置总方差的初始值
total_variance = 0.0
#设置特征数量的初始值
n_components=0
#遍历方差百分比数组的元素
for explained_variance in var_ratio:
#将该百分比加入方差
total_variance += explained_variance
#n_components的值加1
n_components += 1
#如果达到目标阈值
if total_variance >= goal_var:
#结束遍历
break
#返回n_components的值
return n_components
#运行函数
select_n_components(tsvd_var_ratios,0.95)















 165
165











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









