







detectron2数据集注册时候会产生一个字典链表,但这个data_dict并不能直接送给模型作为模型的输入,而是需要进过一个map的操作
DataMapper位于detectron2/data/dataset_mapper.py中,将数据集映射成模型需要的格式,可以使用默认的DataMapper,也可以根据自己的需要,写一个DataMapper,只要符合模型的输入格式即可
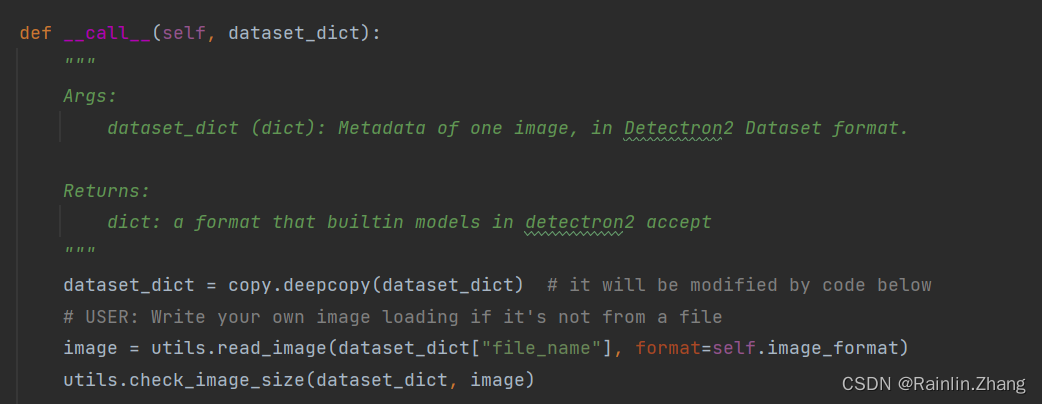
dataset_dict是数据集中一张图片的dict,如下图所示

build dataloader的相关代码在detectron2/data/build.py中,build_detection_train_loader会调用DatasetMapper, list[dict] 中的字典会被一个其映射到模型可接受的格式
@configurable(from_config=_train_loader_from_config)
def build_detection_train_loader(
dataset,
*,
mapper,
sampler=None,
total_batch_size,
aspect_ratio_grouping=True,
num_workers=0,
collate_fn=None,
):
"""
Build a dataloader for object detection with some default features.
Args:
dataset (list or torch.utils.data.Dataset): a list of dataset dicts,
or a pytorch dataset (either map-style or iterable). It can be obtained
by using :func:`DatasetCatalog.get` or :func:`get_detection_dataset_dicts`.
mapper (callable): a callable which takes a sample (dict) from dataset and
returns the format to be consumed by the model.
When using cfg, the default choice is ``DatasetMapper(cfg, is_train=True)``.
sampler (torch.utils.data.sampler.Sampler or None): a sampler that produces
indices to be applied on ``dataset``.
If ``dataset`` is map-style, the default sampler is a :class:`TrainingSampler`,
which coordinates an infinite random shuffle sequence across all workers.
Sampler must be None if ``dataset`` is iterable.
total_batch_size (int): total batch size across all workers.
aspect_ratio_grouping (bool): whether to group images with similar
aspect ratio for efficiency. When enabled, it requires each
element in dataset be a dict with keys "width" and "height".
num_workers (int): number of parallel data loading workers
collate_fn: a function that determines how to do batching, same as the argument of
`torch.utils.data.DataLoader`. Defaults to do no collation and return a list of
data. No collation is OK for small batch size and simple data structures.
If your batch size is large and each sample contains too many small tensors,
it's more efficient to collate them in data loader.
Returns:
torch.utils.data.DataLoader:
a dataloader. Each output from it is a ``list[mapped_element]`` of length
``total_batch_size / num_workers``, where ``mapped_element`` is produced
by the ``mapper``.
"""
if isinstance(dataset, list):
dataset = DatasetFromList(dataset, copy=False) #将多个数据集组合到一起
if mapper is not None:
dataset = MapDataset(dataset, mapper) #将data_dict映射成模型接收的格式
if isinstance(dataset, torchdata.IterableDataset):
assert sampler is None, "sampler must be None if dataset is IterableDataset"
else:
if sampler is None:
sampler = TrainingSampler(len(dataset)) #数据集采样
assert isinstance(sampler, torchdata.Sampler), f"Expect a Sampler but got {type(sampler)}"
return build_batch_data_loader(
dataset,
sampler,
total_batch_size,
aspect_ratio_grouping=aspect_ratio_grouping,
num_workers=num_workers,
collate_fn=collate_fn,
)
Demo演示:
import detectron2.data.transforms as T
from detectron2.data import detection_utils as utils
from detectron2.data.dataset_mapper import DatasetMapper
mapper = DatasetMapper(is_train=True,
augmentations=[
T.Resize((800, 800))],image_format="RGB")
train_loader = build_detection_train_loader(dataset=data_dict,mapper=mapper,total_batch_size=4)#data_dict是注册好的数据集的字典链表
for i,data in enumerate (train_loader):
if i==1:
print(data)
batchsize设置为4,我们来看一下第一个batch里有哪些内容:
还是一个字典链表,每个字典就是一张图片的信息
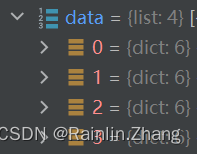
来看一个字典有什么内容
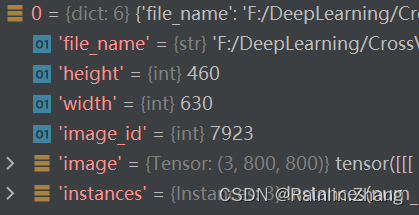
instances字段是一个instance类,在detectron2/structures/instances.py中有定义,这个类会告诉我们mapp后图片的尺寸,一个图片有多少实例,bbox的label,每个instance的类别。
instances字段返回的内容并不是唯一的,如果是分割任务,会有mask信息,如果是关键点检测,会有keypoints信息,或者根据你自定义的map得到新的内容。















 479
479











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









