






1.索引
1.1 索引是什么
将数据排好序的用来快速查询的一个数据结构
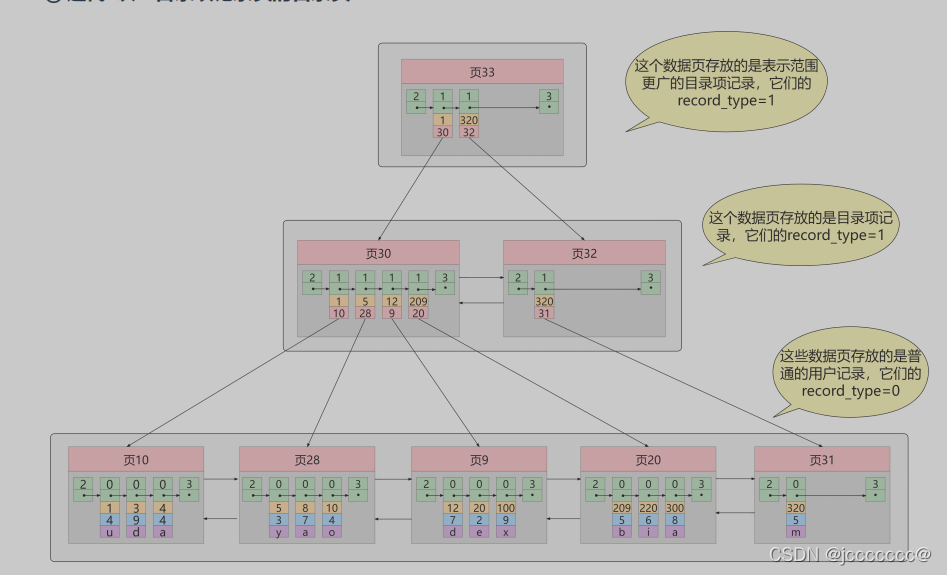
叶子节点保存了完整的用户记录,其他节点只是保存指向下一页的指针,和提供指引作用的数据项
1.2 索引分类
1.2.1 聚簇索引
页之间由双向链表链接,里面的主键单向链表
优:查找出来直接在索引上就可以获取数据
缺:一般不更新主键
1.2.2 二级索引(非聚簇索引)
回表:在二级索引中查询得到了主键,再到聚簇索引中查询完整用户记录
1.2.3 联合索引
为多个列进行建立索引,比方说我们想让B+树按
照 c2和c3列 的大小进行排序,这个包含两层含义:
先把各个记录和页按照c2列进行排序。 在记录的c2列相同的情况下,采用c3列进行排序
本质上也是二级索引
1.3 关于索引的详情
https://www.cnblogs.com/bypp/p/7755307.html
2. 索引的创建
2.1 宜创建
经常用于查询
2.2 不宜创建
3.性能分析工具
3.1 慢查询日志
long_query_time的默认值为10,意思是运行10秒以上的语句,认为是超出了我们最大的忍耐时间,收集时间过长的语句,结合explain来进行分析
3.1.1 开启慢查询
慢查询默认是关闭的,只有我们去调优时才去开启
show variables like '%slow_query_log'
set slow_query_log = on; # 开启慢查询日志
show variables like 'slow_query_log%' # 查看慢查询日志文件位置
set global long_query_time = # 修改全局的longquerytime,
3.1.2 查询慢查询数据条数
show status like 'slow_queries' # 查询有多少个慢查询记录(语句)
3.1.3 慢查询日志分析工具
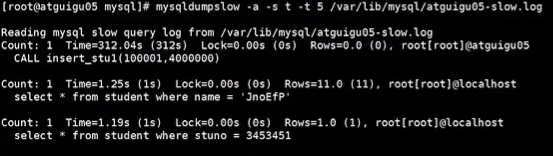
查询具体的慢查询语句:mysqldumpslow,一个脚本,需要在linux的root根目录执行

参数
- a: 不将数字抽象成N,字符串抽象成S
- -s: 是表示按照何种方式排序:
c: 访问次数
l: 锁定时间
r: 返回记录
t: 查询时间
al:平均锁定时间
ar:平均返回记录数
at:平均查询时间 (默认方式)
ac:平均查询次数 - t: 即为返回前面多少条的数据;
- g: 后边搭配一个正则匹配模式,大小写不敏感的;
使用
3.1.4 关闭与删除查询日志
看康师傅的笔记
3.2 查看sql执行成本 show profile
3.2.1 开启show profile
show variables like 'profiling';
set profiling = 'ON';
3.2.2 操作步骤
从满查询日志中发现查询比较慢的语句
然后,再将该语句执行一遍,
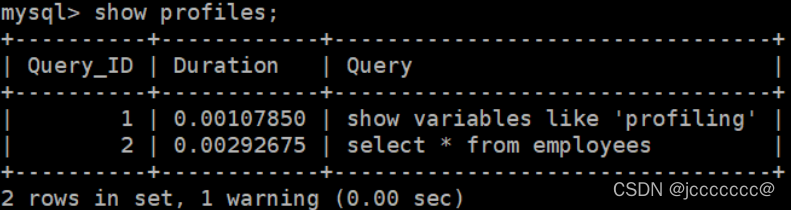
然后使用show profiles
查看最近的查询语句执行成本,具体看康师傅笔记
3.3 分析查询语句:explain
定位了慢查询语句之后,就用explain进行剖析,查看执行计划。‘explain 语句’
- 有哪些可以用的索引
- 有那些索引被使用 *
- 表读取的顺序
- 表之间的引用
- 每张表有多少行被优化器优化 *
3.3.1 字段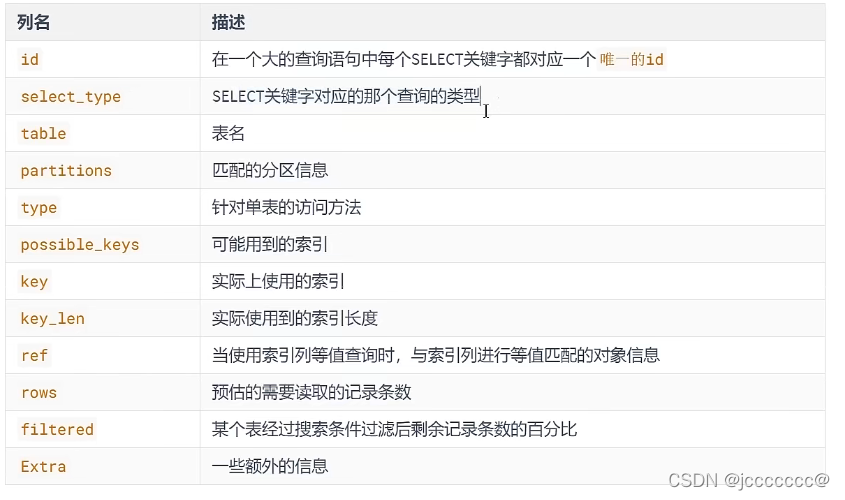
熟悉个各个字段可以使用康师傅的这个文件来学习温习
以下只作为康师傅笔记的补充
-
table:表名,第一个是驱动表,第二个是被驱动表















 12万+
12万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









