







Hadoop资源管理分两部分:资源表示模型和资源分配模型。
- 资源表示模型:hadoop用槽位(slot)来组织各节点上的资源。hadoop将各个节点上的资源等量切分为若干份,每一份用一个slot表示,同时规定一个task可根据需要占用多个slot。slot也分map slot和reduce slot,可根据参数修改分配的slot数,节点的slot数回决定该节点的最大允许任务并发度。
- 资源分配模型:由一个可插拔式的调度器完成。资源分配实际上的任务调度问题,是一个多目标优化问题,hadoop中,map task和reduce task使用的资源不同,需要分开调度。
一次作业提交到执行的过程:
- Client断调用作业提交函数将程序提交到JobTracker端
- JobTracker收到新作业后,通知任务调度器(TaskSchedule)对作业进行初始化
- 某个TaskTracker向JobTracker汇报心跳,其中包含剩余的slot数目是否接收新任务等信息。
- 如果该TaskTracker能够接收新任务,则JobTracker调用TaskTracker对外函数assignTasks为该TaskTracker分配新任务。
- TaskScheduler按照一定的调度策略为该TaskTrackder选择最合适的任务列表,并将该列表返回给JobTracker。
- JobTracker将任务列表以心跳应答的形式返回给对应的TaskTracker。
- TaskTracker收到心跳应答后,发现有需要启动的新任务,则直接启动该任务。
任务调度框架
可插拔模块。
hadoop提供了一个调度器公共基础类TaskScheduler,继承该类并重新实现其中的函数就可以实现自己的调度器。
任务调度器和JobTracker有函数互相调用的关系,JobTracker需要调用任务调度器的assignTasks函数为TaskTracker分配新任务,同时,JobTracker保存的节点、作业和任务的运行时状态信息,是任务调度器进行调度决策时需要用到的,任务调度器通过一个或者多个JobInProgressListener对象从JobTracker端监听作业状态的变化。
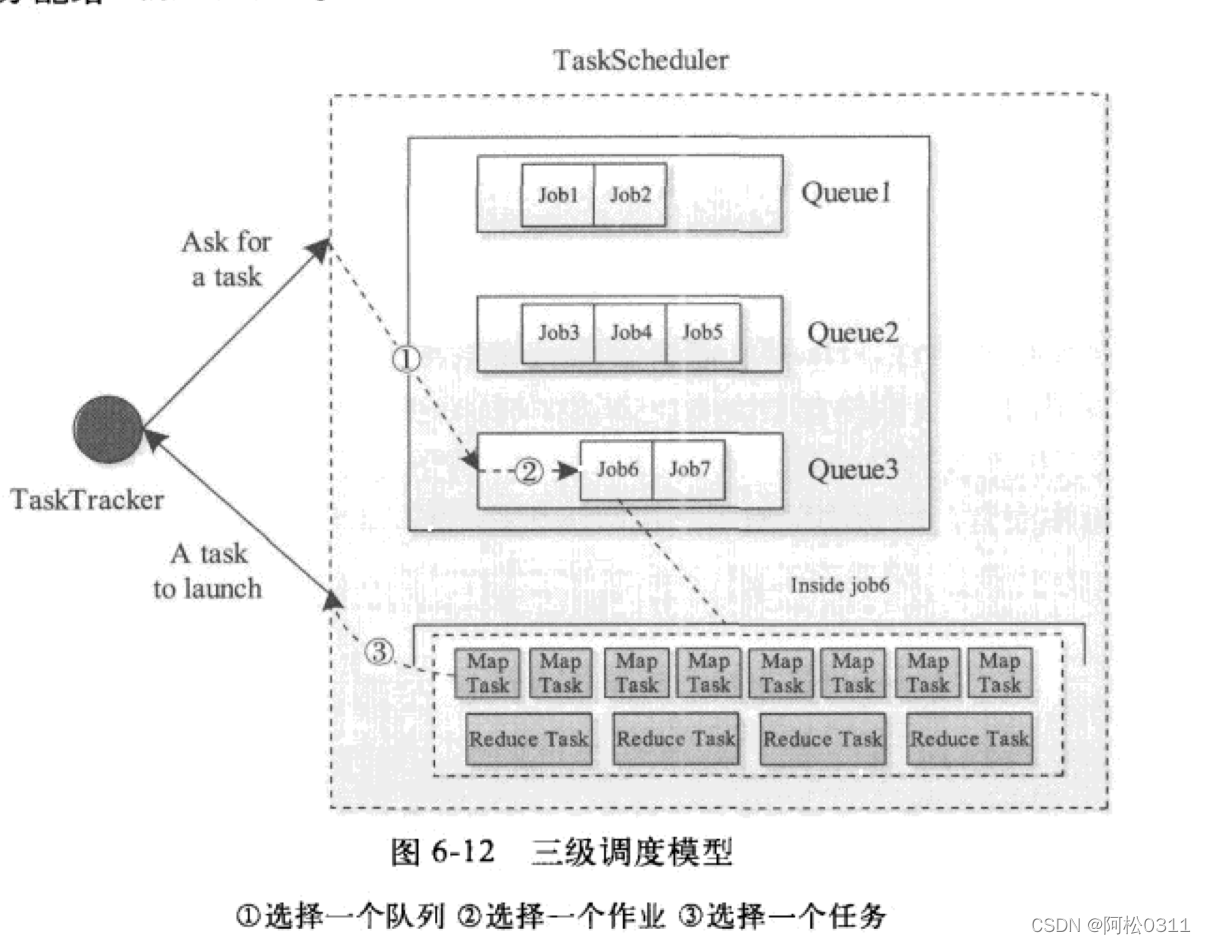
hadoop以队列为单位管理作业和资源,hadoop调度器本质上采用三级调度模型,如上图,当一个TaskTracker出现空闲资源时,调度器回一次选择一个队列、队列中的作业、作业中的任务,并最终将这个任务分配给TaskTracker。
任务选择策略
对于Map Task,最重要的因素是数据本地性, 尽量将任务调度到数据所在的节点,还要考虑失败任务、备份任务的调度顺序等;
对于Reduce Task,没有数据本地性,只考虑未运行任务和备份任务的调度顺序。
数据本地性
分布式环境中,数据本地性是将任务调度到输入数据所在的计算节点,减少任务过程中的网络传输开销。
hadoop集群一般采用三层网络拓扑结构,根节点表示整个集群,第一层代表数据中心,第二层代表机架或者交换机,第三层代表实际用于计算和存储的物理节点。(目前各个hadoop版本而言,采用二层架构,没有数据中心)
hadoop根据输入数据与实际分配的计算资源之间的距离将任务分成三类:node-local(输入数据与计算资源同节点),rack-local(同机架),off_switch(跨机架),当输入数据与计算资源位于不同节点上时,hadoop需将数据远程复制到计算资源所在节点进行计算,距离越远,需要的网络开销越大,因此调度器进行任务分配时尽量选择离输入数据近的节点资源。
hadoop进行任务选择时,采用了自上而下查找的策略,任务优先级从高到低:node-local , rack-local , off-switch。
Map Task选择策略
主要思想:优先选择运行失败的任务,以让其快速获取重新运行的机会,其次是按照数据本地性策略选择尚未运行的任务,最后是查找正在运行的任务,尝试为“拖后腿”任务启动备份任务。
Reduce Task选择策略
两个数据结构:nonRunningReduces和runningReduces,分别表示尚未运行的TIP列表和正在运行的TIP列表。
任务选择步骤:
- 合法性检查:对节点可靠性和磁盘空间进行检查
- 从nonRunningReduces列表中选择任务,无须考虑数据本地性,依次遍历该列表中的任务,选择第一个满足条件的任务。
- 从runningReduces列表中选择任务,为“拖后腿”任务启动备份任务。
FIFO调度器
hadoop的任务调度器:FIFO、Capacity Scheduler、Fair Scheduler。
FIFO,先到先得。
依靠JobQueueTaskScheduler实现。
JobQueueTaskScheduler向JobTracker注册了两种作业监听器,功能如下:
- EagerTaskInitializationListener对用户提交的作业进行初始化:初始化的作业可能很多,要采用一定策略决定新提交作业的初始化顺序,基本策略是优先选优先级高的, 优先级相同选提交时间早的。
- JobQueueJobInProgressListener维护作业的调度顺序:该作业监听器维护了作业被调度的顺序,其排序原则跟初始化顺序类似:先按优先级,然后提交时间,最后作业ID。
调度机制:
- 计算可用slot数目:FIFO尽量把所有任务均衡调度到每个TaskTracker,以便均衡使用。
- 分配任务:遍历作业队列,给TaskTracker分配任务。
hadoop资源管理优化
三种,基于动态slot的方案、基于无类别slot的方案、基于真实资源需求量的方案。
基于动态slot的资源管理方案
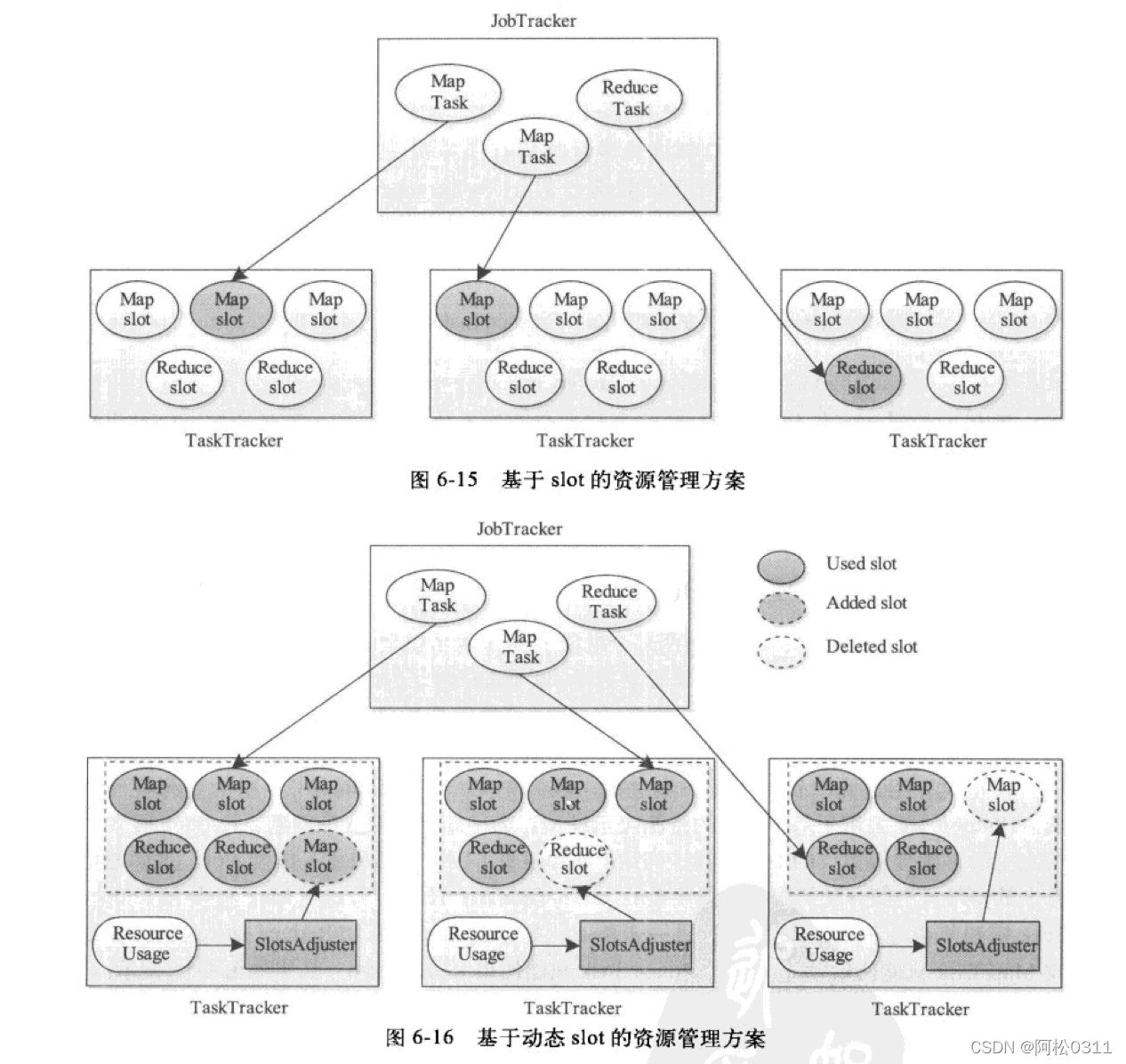
该方案再每个节点上安装一个slot数目动态调整模块SlotAdjuster,可以根据节点上的资源利用率动态调整slot数目,以便更合理使用资源。
基于无类别slot的资源管理方案
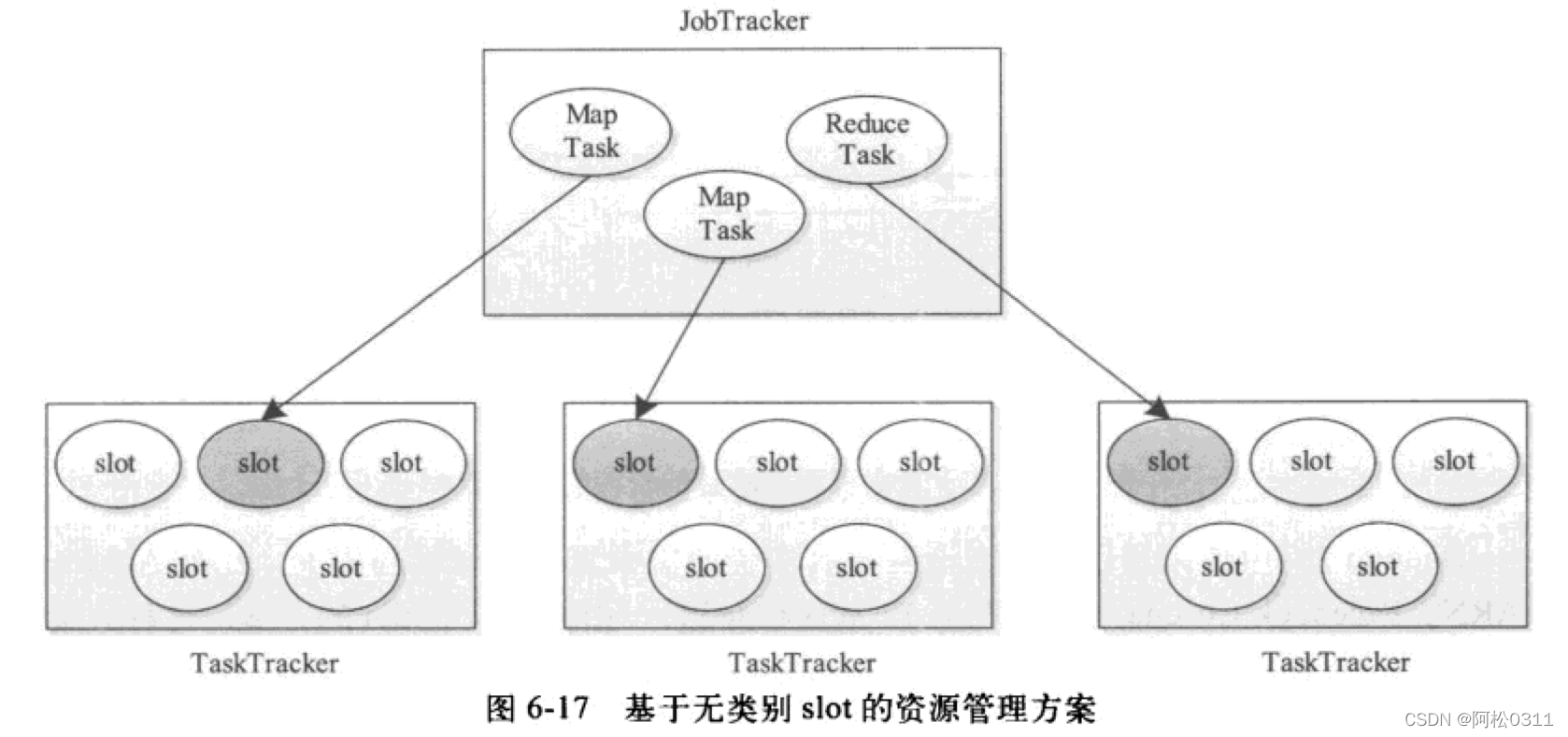
对于一个MapReduce程序,Map Task先调度,当Map Task完成数目到达一定比例(默认5%),才会调度Reduce Task,所以从单个程序来看,刚开始运行时,Map Slot资源紧缺而Reduce slot空闲,当Map Task结束后,Reduce slot紧缺而Map slot空闲,这样利用率就不高,所以采用不区分map slot和reduce slot的方式来提高slot的利用率,至于如何将slot分配给map task和reduce task,由调度器决定。
基于真实资源需求量的资源管理方案
无差别的slot的坏处:slot无差别, 就成同质了,代表slot上是相同的资源,但是实际应用环境中,用户程序对资源需求往往是多样化的,五类别slot的资源规划方法粒度过粗,回造成节点资源利用率过高或者过低,比如:实现规划一个slot代表2GB内存和1个CPU,如果一个程序的内存只需要1GB,就产生了资源碎片,降低了集群资源的利用率;如果一个程序需要3GB,就会抢占其他任务的资源,导致集群利用率过高。
回归资源分配的本质,根据任务资源需求为它分匹配各类资源,资源本身是多维度的,内存、CPU、网络IO、磁盘IO等,如果要精确控制资源分配,就不能有slot的概念,最直接的方法就是任务直接向调度器申请自己需要的资源,调度器按需分配。
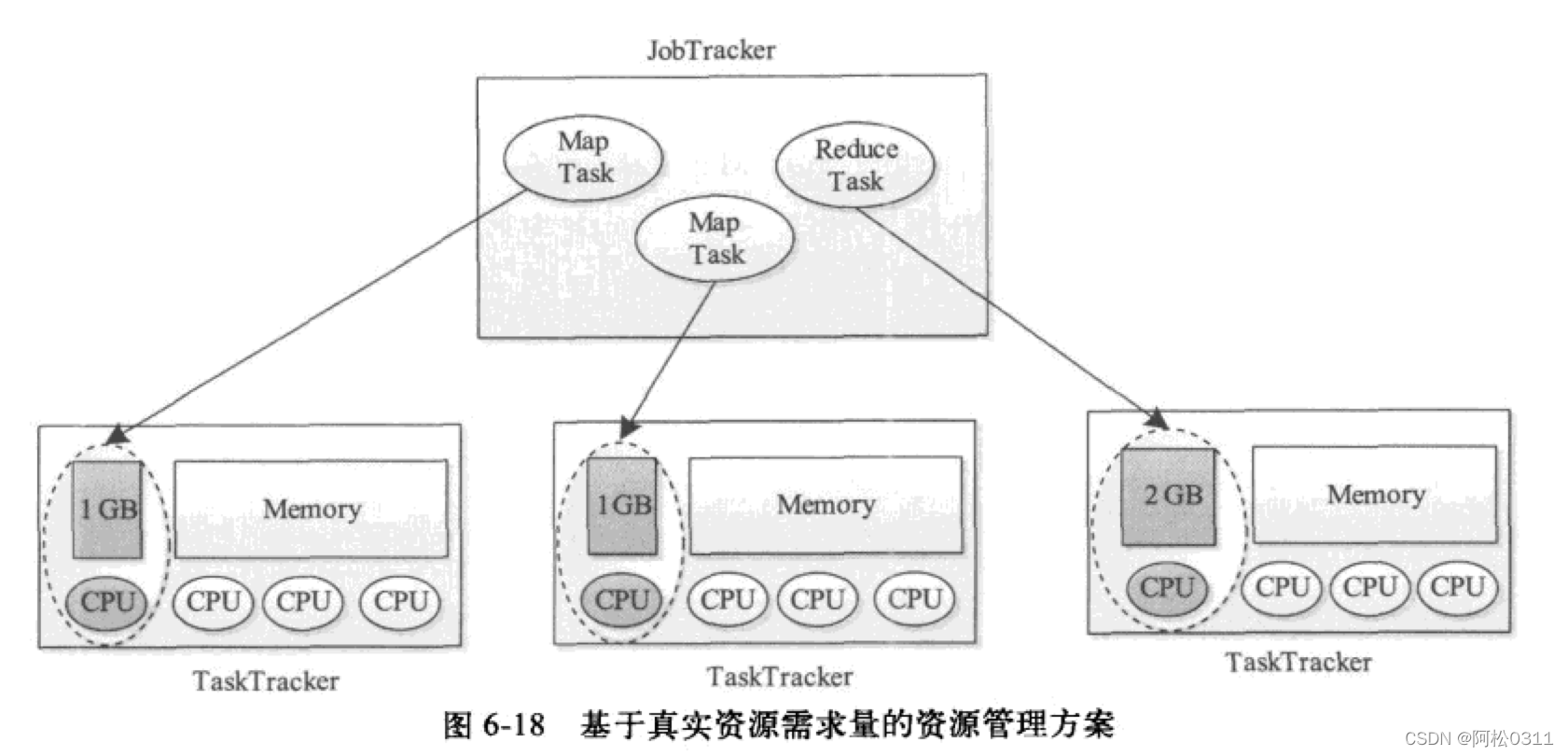
hadoop2.0中就采用了这种方式,用YARN管理。














 1953
1953











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









