







(图片来源:北风网)
源码所在目录:

首先进入BlockManagerMasterEndpoint看看
/**
* BlockManagerMasterEndpoint is an [[ThreadSafeRpcEndpoint]] on the master node to track statuses
* of all slaves' block managers.
*/
BlockManagerMasterEndpoint 是主节点上的 [[ThreadSafeRpcEndpoint]],用于跟踪所有从节点的BlockManager的状态。
一些数据结构
class BlockManagerMasterEndpoint(
override val rpcEnv: RpcEnv,
val isLocal: Boolean,
conf: SparkConf,
listenerBus: LiveListenerBus)
extends ThreadSafeRpcEndpoint with Logging {
//一些数据结构
// Mapping from block manager id to the block manager's information.
//维护了blockManagerInfo,就是blockManager的元数据
//管理了blockManager id到block manager的映射
private val blockManagerInfo = new mutable.HashMap[BlockManagerId, BlockManagerInfo]
// Mapping from executor ID to block manager ID.
//维护了executor id到block manager 的映射,因为一个executor和一个block manager相关联的
private val blockManagerIdByExecutor = new mutable.HashMap[String, BlockManagerId]
// Mapping from block id to the set of block managers that have the block.
//维护了block id到block集的映射,因为一个block可能在多个blockmanager上
private val blockLocations = new JHashMap[BlockId, mutable.HashSet[BlockManagerId]]
private val askThreadPool = ThreadUtils.newDaemonCachedThreadPool("block-manager-ask-thread-pool")
private implicit val askExecutionContext = ExecutionContext.fromExecutorService(askThreadPool)
private val topologyMapper = {
val topologyMapperClassName = conf.get(
"spark.storage.replication.topologyMapper", classOf[DefaultTopologyMapper].getName)
val clazz = Utils.classForName(topologyMapperClassName)
val mapper =
clazz.getConstructor(classOf[SparkConf]).newInstance(conf).asInstanceOf[TopologyMapper]
logInfo(s"Using $topologyMapperClassName for getting topology information")
mapper
}
//打日志,BlockManagerMasterEndpoint启动
logInfo("BlockManagerMasterEndpoint up")
register方法,就是BlockManagerMaster注册BlockManager的代码
/**
* Returns the BlockManagerId with topology information populated, if available.
* 如果可用的话,返回填充了拓扑信息的BlockManagerId
*/
private def register(
idWithoutTopologyInfo: BlockManagerId,
maxMemSize: Long,
slaveEndpoint: RpcEndpointRef): BlockManagerId = {
// the dummy id is not expected to contain the topology information.
// we get that info here and respond back with a more fleshed out block manager id
//获取blockmanager id
val id = BlockManagerId(
idWithoutTopologyInfo.executorId,
idWithoutTopologyInfo.host,
idWithoutTopologyInfo.port,
topologyMapper.getTopologyForHost(idWithoutTopologyInfo.host))
val time = System.currentTimeMillis()
if (!blockManagerInfo.contains(id)) {
//这里其实是做安全检查
//就是说,如果blockManagerInfo中没有blockmanagerId
//那么blockManagerIdByExecutor中也应该没有blockmanagerId
//如果有,应该去除
//如果没有,就没事
blockManagerIdByExecutor.get(id.executorId) match {
case Some(oldId) =>
//如果一个executor上出现两个block manager,就代替掉老的那个
// A block manager of the same executor already exists, so remove it (assumed dead)
logError("Got two different block manager registrations on same executor - "
+ s" will replace old one $oldId with new one $id")
//移除掉executor id相关的block manager
removeExecutor(id.executorId)
case None =>
}
logInfo("Registering block manager %s with %s RAM, %s".format(
id.hostPort, Utils.bytesToString(maxMemSize), id))
//安全检查完事了
//该注册了
//保存一份executor和blockmanager的id映射
blockManagerIdByExecutor(id.executorId) = id
//保存blockmanager id到blockmanagerInfo里
blockManagerInfo(id) = new BlockManagerInfo(
id, System.currentTimeMillis(), maxMemSize, slaveEndpoint)
}
listenerBus.post(SparkListenerBlockManagerAdded(time, id, maxMemSize))
id
}
OK,注册完事
看看更新blockInfo,每个blockmanager上,如果block发生变化,那么就要发送updateBlockInfo请求来BlockManagerMaster这进行blockInfo的更新。
private def updateBlockInfo(
blockManagerId: BlockManagerId,
blockId: BlockId,
storageLevel: StorageLevel,
memSize: Long,
diskSize: Long): Boolean = {
if (!blockManagerInfo.contains(blockManagerId)) {
if (blockManagerId.isDriver && !isLocal) {
// We intentionally do not register the master (except in local mode),
// so we should not indicate failure.
return true
} else {
return false
}
}
if (blockId == null) {
blockManagerInfo(blockManagerId).updateLastSeenMs()
return true
}
//在这更新
blockManagerInfo(blockManagerId).updateBlockInfo(blockId, storageLevel, memSize, diskSize)
//每个block可能存在多个的blockmanager中,因为如果将storagelevel设置成带_2的这种,就需要将block复制一份放到其他blockmanager上
//blockLocations map保存了每个block id对应的blockmanager set集合
//所以这里会更新blockLocations的信息,因为用set存储,可以自动去重
var locations: mutable.HashSet[BlockManagerId] = null
if (blockLocations.containsKey(blockId)) {
locations = blockLocations.get(blockId)
} else {
locations = new mutable.HashSet[BlockManagerId]
blockLocations.put(blockId, locations)
}
if (storageLevel.isValid) {
locations.add(blockManagerId)
} else {
locations.remove(blockManagerId)
}
// Remove the block from master tracking if it has been removed on all slaves.
if (locations.size == 0) {
blockLocations.remove(blockId)
}
true
}
进入blockManagerInfo.updateBlockInfo看看
def updateBlockInfo(
blockId: BlockId,
storageLevel: StorageLevel,
memSize: Long,
diskSize: Long) {
updateLastSeenMs()
//如果内部已经有这个block
if (_blocks.containsKey(blockId)) {
// The block exists on the slave already.
val blockStatus: BlockStatus = _blocks.get(blockId)
val originalLevel: StorageLevel = blockStatus.storageLevel
val originalMemSize: Long = blockStatus.memSize
//如果storeLevel是用内存,则剩余内存加上当前内存量
if (originalLevel.useMemory) {
_remainingMem += originalMemSize
}
}
//给block创建一份blockStatus,根据其持久化级别,对相应的资源进行计算
if (storageLevel.isValid) {
/* isValid means it is either stored in-memory or on-disk.
* The memSize here indicates the data size in or dropped from memory,
* externalBlockStoreSize here indicates the data size in or dropped from externalBlockStore,
* and the diskSize here indicates the data size in or dropped to disk.
* They can be both larger than 0, when a block is dropped from memory to disk.
* Therefore, a safe way to set BlockStatus is to set its info in accurate modes. */
var blockStatus: BlockStatus = null
if (storageLevel.useMemory) {
//如果内存
blockStatus = BlockStatus(storageLevel, memSize = memSize, diskSize = 0)
//把所占资源去掉
_blocks.put(blockId, blockStatus)
_remainingMem -= memSize
logInfo("Added %s in memory on %s (size: %s, free: %s)".format(
blockId, blockManagerId.hostPort, Utils.bytesToString(memSize),
Utils.bytesToString(_remainingMem)))
}
if (storageLevel.useDisk) {
blockStatus = BlockStatus(storageLevel, memSize = 0, diskSize = diskSize)
_blocks.put(blockId, blockStatus)
logInfo("Added %s on disk on %s (size: %s)".format(
blockId, blockManagerId.hostPort, Utils.bytesToString(diskSize)))
}
if (!blockId.isBroadcast && blockStatus.isCached) {
_cachedBlocks += blockId
}
} else if (_blocks.containsKey(blockId)) {
//如果storageLevel非法,且之前的blockid保存过
//则把block remove掉
// If isValid is not true, drop the block.
val blockStatus: BlockStatus = _blocks.get(blockId)
_blocks.remove(blockId)
_cachedBlocks -= blockId
if (blockStatus.storageLevel.useMemory) {
logInfo("Removed %s on %s in memory (size: %s, free: %s)".format(
blockId, blockManagerId.hostPort, Utils.bytesToString(blockStatus.memSize),
Utils.bytesToString(_remainingMem)))
}
if (blockStatus.storageLevel.useDisk) {
logInfo("Removed %s on %s on disk (size: %s)".format(
blockId, blockManagerId.hostPort, Utils.bytesToString(blockStatus.diskSize)))
}
}
}
总之,BlockManagerMasterEndPoint就是维护各个executor的BlockManager的元数据BlockManagerInfo,BlockStatus的
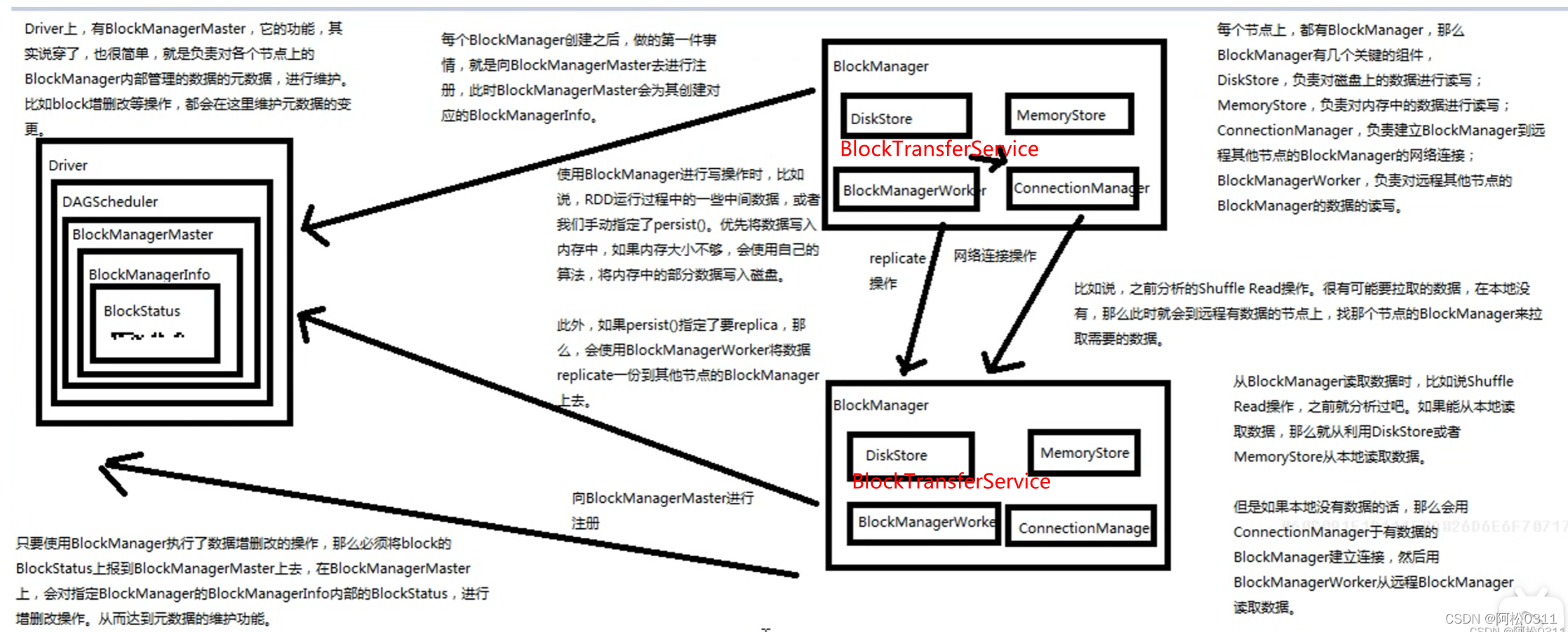
接下来看看BlockManager:
/**
* Manager running on every node (driver and executors) which provides interfaces for putting and
* retrieving blocks both locally and remotely into various stores (memory, disk, and off-heap).
*
* Note that [[initialize()]] must be called before the BlockManager is usable.
*/
运行在每个节点(driver和executor)上的manager,它提供用于在本地和远程将块放入和检索到各种存储(内存、磁盘和堆外)的接口。
首先看它的initialize方法
/**
* Initializes the BlockManager with the given appId. This is not performed in the constructor as
* the appId may not be known at BlockManager instantiation time (in particular for the driver,
* where it is only learned after registration with the TaskScheduler).
*使用给定的 appId 初始化 BlockManager。
这不会在构造函数中执行,因为在 BlockManager 实例化时可能不知道 appId(特别是对于driver,只有在向 TaskScheduler 注册后才能获知)。
* This method initializes the BlockTransferService and ShuffleClient, registers with the
* BlockManagerMaster, starts the BlockManagerWorker endpoint, and registers with a local shuffle
* service if configured.
* 此方法初始化 BlockTransferService 和 ShuffleClient,
* 向 BlockManagerMaster 注册,启动 BlockManagerWorker 端点,
* 并在配置后向本地 shuffle 服务注册
*/
def initialize(appId: String): Unit = {
//首先初始化BlockTransferService 和 ShuffleClient
blockTransferService.init(this)
shuffleClient.init(appId)
blockReplicationPolicy = {
val priorityClass = conf.get(
"spark.storage.replication.policy", classOf[RandomBlockReplicationPolicy].getName)
val clazz = Utils.classForName(priorityClass)
val ret = clazz.newInstance.asInstanceOf[BlockReplicationPolicy]
logInfo(s"Using $priorityClass for block replication policy")
ret
}
//创建一个BlockManagerId
//使用到了executorId(每个block关联一个executor),blockTransferService.hostName, blockTransferService.port
//从初始化就可以看到,一个block通过一个节点的executor唯一标识
val id =
BlockManagerId(executorId, blockTransferService.hostName, blockTransferService.port, None)
//调用master的注册blockmanager方法,会发送消息给BlockManagerMasterEndpoint
val idFromMaster = master.registerBlockManager(
id,
maxMemory,
slaveEndpoint)
blockManagerId = if (idFromMaster != null) idFromMaster else id
shuffleServerId = if (externalShuffleServiceEnabled) {
logInfo(s"external shuffle service port = $externalShuffleServicePort")
BlockManagerId(executorId, blockTransferService.hostName, externalShuffleServicePort)
} else {
blockManagerId
}
// Register Executors' configuration with the local shuffle service, if one should exist.
if (externalShuffleServiceEnabled && !blockManagerId.isDriver) {
registerWithExternalShuffleServer()
}
logInfo(s"Initialized BlockManager: $blockManagerId")
}
这样,初始化过程完成了初始化 BlockTransferService 和 ShuffleClient,
向 BlockManagerMaster 注册,启动 BlockManagerWorker 端点。
由于BlockManager主要负责数据的存取,所以来看看关于数据存取的方法
读取分本地读取和远程读取
先看看本地读取getLocal
/**
* Get block from local block manager as an iterator of Java objects.
*/
def getLocalValues(blockId: BlockId): Option[BlockResult] = {
logDebug(s"Getting local block $blockId")
//加锁,读可抢占,写要等待
//如果block为空,返回null
//否则,返回blockinfo
blockInfoManager.lockForReading(blockId) match {
case None =>
logDebug(s"Block $blockId was not found")
None
case Some(info) =>
//获取存储级别
val level = info.level
logDebug(s"Level for block $blockId is $level")
//如果使用内存并且内存中存储了这个blockid
if (level.useMemory && memoryStore.contains(blockId)) {
//如果可以反序列化
val iter: Iterator[Any] = if (level.deserialized) {
//直接从内存中取
memoryStore.getValues(blockId).get
} else {
//如果不能序列化
//使用serializerManager来序列化
serializerManager.dataDeserializeStream(
blockId, memoryStore.getBytes(blockId).get.toInputStream())(info.classTag)
}
//序列化完后
val ci = CompletionIterator[Any, Iterator[Any]](iter, releaseLock(blockId))
Some(new BlockResult(ci, DataReadMethod.Memory, info.size))
} else if (level.useDisk && diskStore.contains(blockId)) {
//如果使用的是磁盘level,且磁盘中包含此block
val iterToReturn: Iterator[Any] = {
val diskBytes = diskStore.getBytes(blockId)
if (level.deserialized) {
val diskValues = serializerManager.dataDeserializeStream(
blockId,
diskBytes.toInputStream(dispose = true))(info.classTag)
maybeCacheDiskValuesInMemory(info, blockId, level, diskValues)
} else {
val stream = maybeCacheDiskBytesInMemory(info, blockId, level, diskBytes)
.map {_.toInputStream(dispose = false)}
.getOrElse { diskBytes.toInputStream(dispose = true) }
serializerManager.dataDeserializeStream(blockId, stream)(info.classTag)
}
}
val ci = CompletionIterator[Any, Iterator[Any]](iterToReturn, releaseLock(blockId))
Some(new BlockResult(ci, DataReadMethod.Disk, info.size))
} else {
handleLocalReadFailure(blockId)
}
}
}
看看远程读取getRemote,它有重试机制和刷新locations机制,来提供一些容错办法
/**
* Get block from remote block managers.
*
* This does not acquire a lock on this block in this JVM.
*/
private def getRemoteValues[T: ClassTag](blockId: BlockId): Option[BlockResult] = {
val ct = implicitly[ClassTag[T]]
getRemoteBytes(blockId).map { data =>
val values =
serializerManager.dataDeserializeStream(blockId, data.toInputStream(dispose = true))(ct)
new BlockResult(values, DataReadMethod.Network, data.size)
}
}
/**
* Get block from remote block managers as serialized bytes.
*/
def getRemoteBytes(blockId: BlockId): Option[ChunkedByteBuffer] = {
logDebug(s"Getting remote block $blockId")
require(blockId != null, "BlockId is null")
//计数
var runningFailureCount = 0
var totalFailureCount = 0
//获取位置
val locations = getLocations(blockId)
/*
/**
* Return a list of locations for the given block, prioritizing the local machine since
* multiple block managers can share the same host.
private def getLocations(blockId: BlockId): Seq[BlockManagerId] = {
//从blockmanagerMaster上获取block的blockManager信息
//然后随机打乱
val locs = Random.shuffle(master.getLocations(blockId))
//优先先择本地机器,loc.host==blockMnagerId.host
val (preferredLocs, otherLocs) = locs.partition { loc => blockManagerId.host == loc.host }
//最佳位置++
preferredLocs ++ otherLocs
}
*/
val maxFetchFailures = locations.size
var locationIterator = locations.iterator
while (locationIterator.hasNext) {
val loc = locationIterator.next()
//从loc取block
logDebug(s"Getting remote block $blockId from $loc")
val data = try {
//使用这个Service进行远程block获取
//连接时使用的blockmanager的唯一标识,host,port,executorid
blockTransferService.fetchBlockSync(
loc.host, loc.port, loc.executorId, blockId.toString).nioByteBuffer()
} catch {
case NonFatal(e) =>
runningFailureCount += 1
totalFailureCount += 1
//失败次数过多, 退出
if (totalFailureCount >= maxFetchFailures) {
// Give up trying anymore locations. Either we've tried all of the original locations,
// or we've refreshed the list of locations from the master, and have still
// hit failures after trying locations from the refreshed list.
//放弃尝试更多地点。
//要么我们已经尝试了所有原始位置,要么我们已经从主服务器刷新了位置列表,但在尝试了刷新列表中的位置后仍然失败。
logWarning(s"Failed to fetch block after $totalFailureCount fetch failures. " +
s"Most recent failure cause:", e)
return None
}
logWarning(s"Failed to fetch remote block $blockId " +
s"from $loc (failed attempt $runningFailureCount)", e)
// If there is a large number of executors then locations list can contain a
// large number of stale entries causing a large number of retries that may
// take a significant amount of time. To get rid of these stale entries
// we refresh the block locations after a certain number of fetch failures
//如果有大量executor,则位置列表可能包含大量陈旧条目,
//从而导致可能需要大量时间的大量重试。
//为了摆脱这些陈旧的条目,我们在一定数量的获取失败后刷新块位置
if (runningFailureCount >= maxFailuresBeforeLocationRefresh) {
locationIterator = getLocations(blockId).iterator
logDebug(s"Refreshed locations from the driver " +
s"after ${runningFailureCount} fetch failures.")
runningFailureCount = 0
}
// This location failed, so we retry fetch from a different one by returning null here
null
}
if (data != null) {
return Some(new ChunkedByteBuffer(data))
}
logDebug(s"The value of block $blockId is null")
}
logDebug(s"Block $blockId not found")
None
}
再来看看提交数据,核心操作就是先写内存,内存不够就写磁盘
/**
* Put the given bytes according to the given level in one of the block stores, replicating
* the values if necessary.
* 根据给定级别将给定字节放入块存储之一,如有必要,复制这些值。
*
* If the block already exists, this method will not overwrite it.
*如果块已经存在,则此方法不会覆盖它。
* '''Important!''' Callers must not mutate or release the data buffer underlying `bytes`. Doing
* so may corrupt or change the data stored by the `BlockManager`.
*'''重要!''' 调用者不得改变或释放 `bytes` 底层的数据缓冲区。这样做可能会损坏或更改“BlockManager”存储的数据。
* @param keepReadLock if true, this method will hold the read lock when it returns (even if the
* block already exists). If false, this method will hold no locks when it
* returns.
* @return true if the block was already present or if the put succeeded, false otherwise.
*/
private def doPutBytes[T](
blockId: BlockId,
bytes: ChunkedByteBuffer,
level: StorageLevel,
classTag: ClassTag[T],
tellMaster: Boolean = true,
keepReadLock: Boolean = false): Boolean = {
//这里调用了doPut方法
doPut(blockId, level, classTag, tellMaster = tellMaster, keepReadLock = keepReadLock) { info =>
val startTimeMs = System.currentTimeMillis
// Since we're storing bytes, initiate the replication before storing them locally.
// This is faster as data is already serialized and ready to send.
val replicationFuture = if (level.replication > 1) {
Future {
// This is a blocking action and should run in futureExecutionContext which is a cached
// thread pool
//复制
replicate(blockId, bytes, level, classTag)
}(futureExecutionContext)
} else {
null
}
val size = bytes.size
//如果使用的是内存级别
if (level.useMemory) {
// Put it in memory first, even if it also has useDisk set to true;
// We will drop it to disk later if the memory store can't hold it.如果内存不够,则落盘
val putSucceeded = if (level.deserialized) {
//如果需要反序列化
val values =
serializerManager.dataDeserializeStream(blockId, bytes.toInputStream())(classTag)
memoryStore.putIteratorAsValues(blockId, values, classTag) match {
//尝试将给定的块作为值放入内存中
//迭代器可能太大而无法在内存中实现和存储。
//为了避免OOM异常,这个方法会在周期性的检查是否有足够的空闲内存的同时,逐步展开迭代器。
//如果块被成功实现,那么在实现过程中使用的临时展开内存“转移”到存储内存,
//因此我们不会获得比存储块实际需要的更多的内存
case Right(_) => true//right表示写成功
case Left(iter) =>//left表示写失败
// If putting deserialized values in memory failed, we will put the bytes directly to
// disk, so we don't need this iterator and can close it to free resources earlier.
//如果写内存失败,就直接写磁盘
//iterator直接关掉
iter.close()
false
}
} else {
//不需要反序列化
val memoryMode = level.memor yMode
memoryStore.putBytes(blockId, size, memoryMode, () => {
if (memoryMode == MemoryMode.OFF_HEAP &&
bytes.chunks.exists(buffer => !buffer.isDirect)) {
bytes.copy(Platform.allocateDirectBuffer)
} else {
bytes
}
})
}
//如果内存放不成功且支持放磁盘,则使用放磁盘
if (!putSucceeded && level.useDisk) {
logWarning(s"Persisting block $blockId to disk instead.")
diskStore.putBytes(blockId, bytes)
}
} else if (level.useDisk) {
//指明了用磁盘
diskStore.putBytes(blockId, bytes)
}
val putBlockStatus = getCurrentBlockStatus(blockId, info)
val blockWasSuccessfullyStored = putBlockStatus.storageLevel.isValid
if (blockWasSuccessfullyStored) {
// Now that the block is in either the memory or disk store,
//现在block在内存或者磁盘中了,表示已经写入数据
// tell the master about it.告诉master
info.size = size
if (tellMaster && info.tellMaster) {
reportBlockStatus(blockId, putBlockStatus)
}
addUpdatedBlockStatusToTaskMetrics(blockId, putBlockStatus)
}
logDebug("Put block %s locally took %s".format(blockId, Utils.getUsedTimeMs(startTimeMs)))
if (level.replication > 1) {
// Wait for asynchronous replication to finish
try {
Await.ready(replicationFuture, Duration.Inf)
} catch {
case NonFatal(t) =>
throw new Exception("Error occurred while waiting for replication to finish", t)
}
}
if (blockWasSuccessfullyStored) {
None
} else {
Some(bytes)
}
}.isEmpty
}
看看doPut方法,主要是一些多线程并发同步的操作
/**
* Helper method used to abstract common code from [[doPutBytes()]] and [[doPutIterator()]].
*
* @param putBody a function which attempts the actual put() and returns None on success
* or Some on failure.
*/
private def doPut[T](
blockId: BlockId,
level: StorageLevel,
classTag: ClassTag[_],
tellMaster: Boolean,
keepReadLock: Boolean)(putBody: BlockInfo => Option[T]): Option[T] = {
require(blockId != null, "BlockId is null")
require(level != null && level.isValid, "StorageLevel is null or invalid")
val putBlockInfo = {
//创建blockinfo
val newInfo = new BlockInfo(level, classTag, tellMaster)
//获取一个写锁
if (blockInfoManager.lockNewBlockForWriting(blockId, newInfo)) {
newInfo
} else {
logWarning(s"Block $blockId already exists on this machine; not re-adding it")
if (!keepReadLock) {
// lockNewBlockForWriting returned a read lock on the existing block, so we must free it:
releaseLock(blockId)
}
return None
}
}
val startTimeMs = System.currentTimeMillis
var exceptionWasThrown: Boolean = true
val result: Option[T] = try {
val res = putBody(putBlockInfo)
exceptionWasThrown = false
if (res.isEmpty) {
// the block was successfully stored
if (keepReadLock) {
//如果持有读锁,锁降级
blockInfoManager.downgradeLock(blockId)
} else {
//否则解锁
blockInfoManager.unlock(blockId)
}
} else {
//写block失败
removeBlockInternal(blockId, tellMaster = false)
logWarning(s"Putting block $blockId failed")
}
res
} finally {
// This cleanup is performed in a finally block rather than a `catch` to avoid having to
// catch and properly re-throw InterruptedException.
if (exceptionWasThrown) {
logWarning(s"Putting block $blockId failed due to an exception")
// If an exception was thrown then it's possible that the code in `putBody` has already
// notified the master about the availability of this block, so we need to send an update
// to remove this block location.
removeBlockInternal(blockId, tellMaster = tellMaster)
// The `putBody` code may have also added a new block status to TaskMetrics, so we need
// to cancel that out by overwriting it with an empty block status. We only do this if
// the finally block was entered via an exception because doing this unconditionally would
// cause us to send empty block statuses for every block that failed to be cached due to
// a memory shortage (which is an expected failure, unlike an uncaught exception).
addUpdatedBlockStatusToTaskMetrics(blockId, BlockStatus.empty)
}
}
if (level.replication > 1) {
logDebug("Putting block %s with replication took %s"
.format(blockId, Utils.getUsedTimeMs(startTimeMs)))
} else {
logDebug("Putting block %s without replication took %s"
.format(blockId, Utils.getUsedTimeMs(startTimeMs)))
}
result
}
看看memoryStore.putIteratorAsValues方法
private[storage] def putIteratorAsValues[T](
blockId: BlockId,
values: Iterator[T],
classTag: ClassTag[T]): Either[PartiallyUnrolledIterator[T], Long] = {
require(!contains(blockId), s"Block $blockId is already present in the MemoryStore")
// Number of elements unrolled so far
//到目前为止展开的element
var elementsUnrolled = 0
// Whether there is still enough memory for us to continue unrolling this block
//是否还有足够内存去展开block
var keepUnrolling = true
// Initial per-task memory to request for unrolling blocks (bytes).
//每个任务中,请求展开block的初始内存
val initialMemoryThreshold = unrollMemoryThreshold
// How often to check whether we need to request more memory
//检查是否需要更多内存的频率
val memoryCheckPeriod = 16
// Memory currently reserved by this task for this particular unrolling operation
//此task当前为此特定展开操作保留的内存
var memoryThreshold = initialMemoryThreshold
// Memory to request as a multiple of current vector size
//作为当前向量大小的倍数请求的内存
val memoryGrowthFactor = 1.5
// Keep track of unroll memory used by this particular block / putIterator() operation
//跟踪此特定块 putIterator() 操作使用的展开内存
var unrollMemoryUsedByThisBlock = 0L
// Underlying vector for unrolling the block
//用于展开块的底层向量
var vector = new SizeTrackingVector[T]()(classTag)
// Request enough memory to begin unrolling
//申请zug
keepUnrolling =
reserveUnrollMemoryForThisTask(blockId, initialMemoryThreshold, MemoryMode.ON_HEAP)
if (!keepUnrolling) {
logWarning(s"Failed to reserve initial memory threshold of " +
s"${Utils.bytesToString(initialMemoryThreshold)} for computing block $blockId in memory.")
} else {
unrollMemoryUsedByThisBlock += initialMemoryThreshold
}
// Unroll this block safely, checking whether we have exceeded our threshold periodically
while (values.hasNext && keepUnrolling) {
vector += values.next()
if (elementsUnrolled % memoryCheckPeriod == 0) {
// If our vector's size has exceeded the threshold, request more memory
val currentSize = vector.estimateSize()
if (currentSize >= memoryThreshold) {
val amountToRequest = (currentSize * memoryGrowthFactor - memoryThreshold).toLong
keepUnrolling =
reserveUnrollMemoryForThisTask(blockId, amountToRequest, MemoryMode.ON_HEAP)
if (keepUnrolling) {
unrollMemoryUsedByThisBlock += amountToRequest
}
// New threshold is currentSize * memoryGrowthFactor
memoryThreshold += amountToRequest
}
}
elementsUnrolled += 1
}
if (keepUnrolling) {
// We successfully unrolled the entirety of this block
val arrayValues = vector.toArray
vector = null
val entry =
new DeserializedMemoryEntry[T](arrayValues, SizeEstimator.estimate(arrayValues), classTag)
val size = entry.size
def transferUnrollToStorage(amount: Long): Unit = {
// Synchronize so that transfer is atomic
memoryManager.synchronized {
releaseUnrollMemoryForThisTask(MemoryMode.ON_HEAP, amount)
val success = memoryManager.acquireStorageMemory(blockId, amount, MemoryMode.ON_HEAP)
assert(success, "transferring unroll memory to storage memory failed")
}
}
// Acquire storage memory if necessary to store this block in memory.
val enoughStorageMemory = {
if (unrollMemoryUsedByThisBlock <= size) {
val acquiredExtra =
memoryManager.acquireStorageMemory(
blockId, size - unrollMemoryUsedByThisBlock, MemoryMode.ON_HEAP)
if (acquiredExtra) {
transferUnrollToStorage(unrollMemoryUsedByThisBlock)
}
acquiredExtra
} else { // unrollMemoryUsedByThisBlock > size
// If this task attempt already owns more unroll memory than is necessary to store the
// block, then release the extra memory that will not be used.
val excessUnrollMemory = unrollMemoryUsedByThisBlock - size
releaseUnrollMemoryForThisTask(MemoryMode.ON_HEAP, excessUnrollMemory)
transferUnrollToStorage(size)
true
}
}
if (enoughStorageMemory) {
entries.synchronized {
entries.put(blockId, entry)
}
logInfo("Block %s stored as values in memory (estimated size %s, free %s)".format(
blockId, Utils.bytesToString(size), Utils.bytesToString(maxMemory - blocksMemoryUsed)))
Right(size)
} else {
assert(currentUnrollMemoryForThisTask >= unrollMemoryUsedByThisBlock,
"released too much unroll memory")
Left(new PartiallyUnrolledIterator(
this,
MemoryMode.ON_HEAP,
unrollMemoryUsedByThisBlock,
unrolled = arrayValues.toIterator,
rest = Iterator.empty))
}
} else {
// We ran out of space while unrolling the values for this block
logUnrollFailureMessage(blockId, vector.estimateSize())
Left(new PartiallyUnrolledIterator(
this,
MemoryMode.ON_HEAP,
unrollMemoryUsedByThisBlock,
unrolled = vector.iterator,
rest = values))
}
}














 268
268











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









