









Spark Streaming 实时计算框架
3、Spark Streaming 整合 Kafka,实现交流
一、实时计算概述
近年来,在Web应用、网络监控、传感监测、电信金融、生产制造等领域,增强了对数据实时处理的需求,而 Spark 中的 Spark Streaming 实时计算框架就是为实现对数据实时处理的需求而设计。
在电子商务中,淘宝、京东网站从用户点击的行为和浏览的历史记录中发现用户的购买意图和兴趣,然后通过 Spark Streaming 实时计算框架的分析处理,为之推荐相关商品,从而有效地提高商品的销售量,同时也增加了用户的满意度,可谓是“一举二得”。
本章主要对 Spark Streaming 实时计算框架相关知识进行介绍。
1.1 什么是实时计算?
在传统的数据处理流程(离线计算)中,复杂的业务处理流程会造成结果数据密集,结果数据密集则存在数据反馈不及时,若是在实时搜索的应用场景中,需要实时数据做决策,而传统的数据处理方式则并不能很好地解决问题,这就引出了一种新的数据计算——实时计算,它可以针对海量数据进行实时计算,无论是在数据采集还是数据处理中,都可以达到秒级别的处理要求。
简单来说,实时计算就是在数据采集与数据处理中,都可以达到秒级别的处理要求。
1.2 常用的实时计算框架
- Apache Spark Streaming
Apache公司开源的实时计算框架。Apache Spark Streaming主要是把输入的数据按时间进行切分,切分的数据块并行计算处理,处理的速度可以达到秒级别。 - Apache Storm
Apache公司开源的实时计算框架,它具有简单、高效、可靠地实时处理海量数据,处理数据的速度达到毫秒级别,并将处理后的结果数据保存到持久化介质中(如数据库、HDFS)。 - Apache Flink
Apache公司开源的实时计算框架。Apache Spark Streaming 主要是把输入的数据按时间进行切分,切分的数据块并行计算处理,处理的速度可以达到秒级别。 - Yahoo! s4
Yahoo公司开源的实时计算平台。Yahoo ! S4是通用的、分布式的、可扩展的,并且还具有容错和可插拔能力,供开发者轻松地处理源源不断产生的数据。
二、Spark Streaming
2.1 Spark Streaming 介绍
Spark Streaming 是构建在Spark上的实时计算框架,且是对Spark Core API的一个扩展,它能够实现对流数据进行实时处理,并具有很好的可扩展性、高吞吐量和容错性。Spark Streaming具有易用性、容错性及易整合性的显著特点。
- 易用性:
- 容错性
- 易整合性
2.2 Spark Streaming 工作原理
Spark Streaming支持从多种数据源获取数据,包括 Kafka 、 Flume 、Twitter 、ZeroMQ 、Kinesis、TCP Sockets 数据源。当Spark Streaming 从数据源获取数据之后,则可以使用诸如map 、reduce 、join和window等高级函数进行复杂的计算处理,最后将处理结果存储到分布式文件系统、数据库中,最终利用实时计算实现操作。

Spark Streaming 接受实时数据流,把数据按照指定的时间段切成一片片小的数据块(spark streaming把每个小的数据块当成RDD来处理),然后把这些数据块传给Spark Engine处理,最终得到一批批的结果。
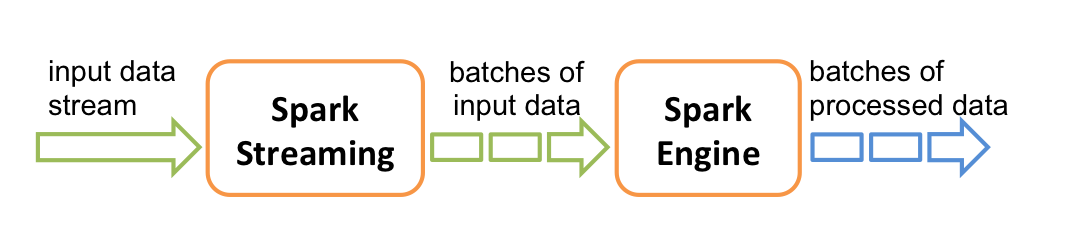
2.2 Spark Streaming 工作机制
- 在Spark Streaming中,会有一个组件Receiver,作为一个长期运行的任务 task 跑在一个Executor上;
- 每个Receiver都会负责一个input DStream(比如从文件中读取数据的文件流,比如套接字流,或者从Kafka中读取的一个输入流等等);
- Spark Streaming通过input DStream与外部数据源进行连接,读取相关数据。
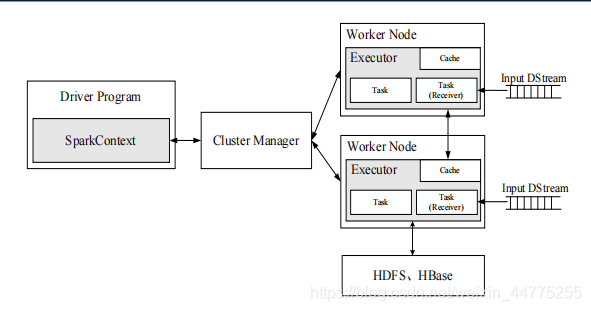
2.3 Spark Streaming 程序的基本步骤
- 通过创建输入DStream来定义输入源;
- 通过对DStream应用转换操作和输出操作来定义流计算;
- 用streamingContext.start()来开始接收数据和处理流程;
- 通过streamingContext.awaitTermination()方法来等待处理结束(手动结束或因为错误而结束);
- 可以通过streamingContext.stop()来手动结束流计算进程。
- 运行一个Spark Streaming程序,首先要生成一个 StreamingContext 对象,它是Spark Streaming程序的主入口
- 可以从一个SparkConf对象创建一个StreamingContext对象
- 登录Linux系统后,启动spark-shell。进入spark-shell以后,就已经获得了一个默认的SparkConext,也就是sc。
2.4 创建 StreamingContext 对象
在交互式界面:
import org.apache.spark.streaming._ # 导包
val ssc = new StreamingContext(sc, Seconds(1)) # 创建对象,间隔时间1秒

Spark Streaming程序代码:
import org.apache.spark._
import org.apache.spark.streaming._
val conf = new SparkConf().setAppName("主程序名").setMaster("local[2]")
val ssc = new StreamingContext(conf, Seconds(1))
三、Spark Streaming 操作
3.1 DStream简介
Spark Streaming 提供了一个高级抽象的流,即DStream (离散流) 。DStream 表示连续的数据流,可以通过 Kafka 、Flume、kinesis 等数据源创建,也可以通过现有DStream的高级操作来创建。DStream 的内部结构是由一系列连续的RDD组成,每个RDD都是一小段时间分隔开来的数据集。对DStream的任何操作,最终都会转变成对底层RDDs的操作。
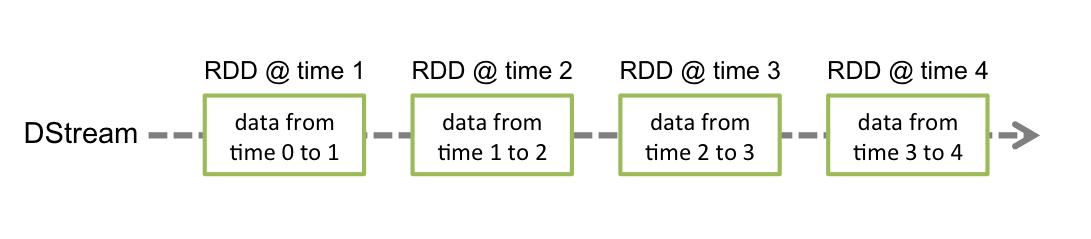
3.2 DStream 编程模型
批处理引擎 Spark Core 把输入的数据按照一定的时间片(如1s) 分成一段一段的数据,每一段数据都会转换成RDD输入到Spark Core中,然后将 DStream 操作转换为RDD算子的相关操作,即转换操作、窗口操作、输出操作。RDD算子操作产生的中间结果数据会保存在内存中,也可以将中间的结果数据输出到外部存储系统中进行保存。
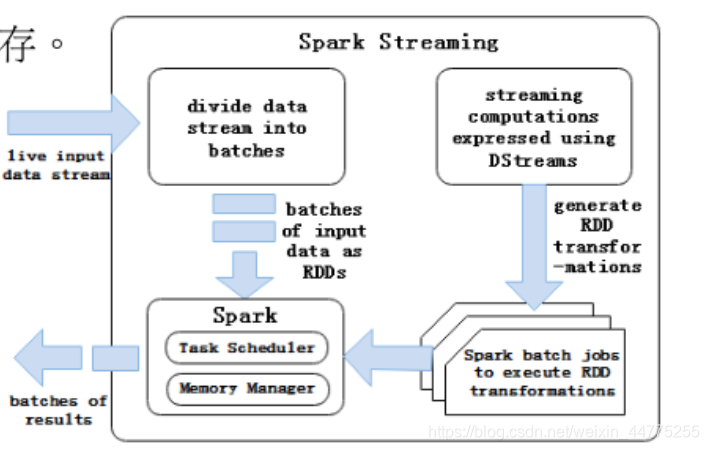
3.3 DStream 转换操作
Spark Streaming 中对 DStream 的转换操作都要转换为对RDD的转换操作。
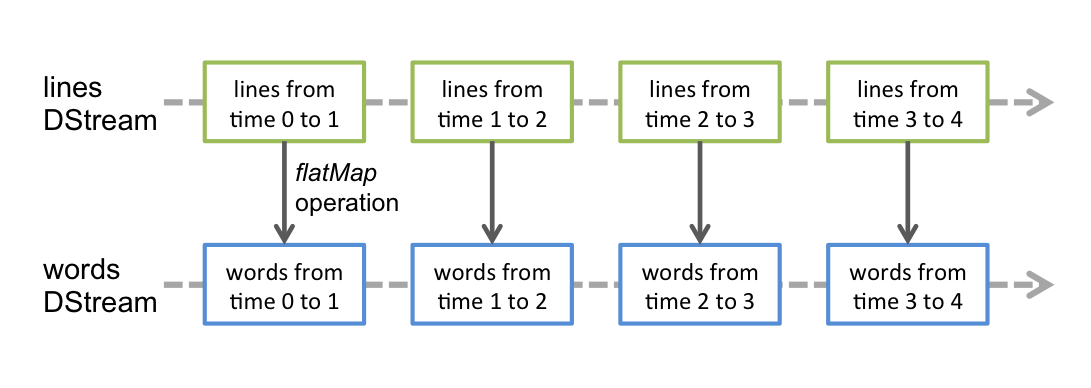
其中, lines 表示转换操作前的DStream , words 表示转换操作后生成的 DStream 。对lines做flatMap转换操作,也就是对它内部的所有RDD做flatMap转换操作。
3.4 DStream API 转换操作
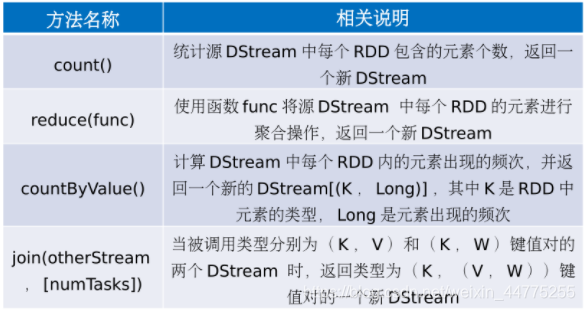

整体上来讲,Spark Streaming 的处理思路:将连续的数据持久化、离散化,然后进行批量处理。
- 数据持久化:接收到的数据暂存,方便数据出错进行回滚。
- 离散化:按时间分片,形成处理单元。
- 分片处理:采用RDD模式将数据分批处理。
- DStream 相当于对 RDD 的再次封装 ,它提供了转化操作和输出操作两种操作方法。
3.5 Transformation:转换算子
Spark支持RDD进行各种转换,因为DStream是由RDD组成的Spark Streaming 提供了一个可以在 DStream 上使用的转换集合,这些集合和RDD上可用的转换类似;转换应用到DStream的每个RDD。
Spark Streaming提供了reduce和count这样的算子,但不会直接触发DStream计算 。
常用算子: Map、flatMap、join、reduceByKey
3.6 Output:执行算子、或输出算子
- Print: 控制台输出;
- saveAsObjectFile、saveAsTextFile、saveAsHadoopFiles:将一批数据输出到Hadoop文件系统中,用批量数据的开始时间戳来命名;
- forEachRDD:允许用户对DStream的每一批量数据对应的RDD本身做任意操作。
3.7 Transformation 抽象逻辑
c = a.join(b), d = c.filter() 时, 它们的 DAG 逻辑关系是:a/b → c,c → d,但在 Spark Streaming 在进行物理记录时却是反向的 a/b ← c, c ← d, 目的为了追溯。
3.8、DStreamGraph
Dstream之间的转换所形成的的依赖关系全部保存在DStreamGraph中, DStreamGraph对于后期生成RDD Graph至关重要。
DStreamGraph有点像简洁版的DAG scheduler,负责根据某个时间间隔生成一序列JobSet,以及按照依赖序列化。
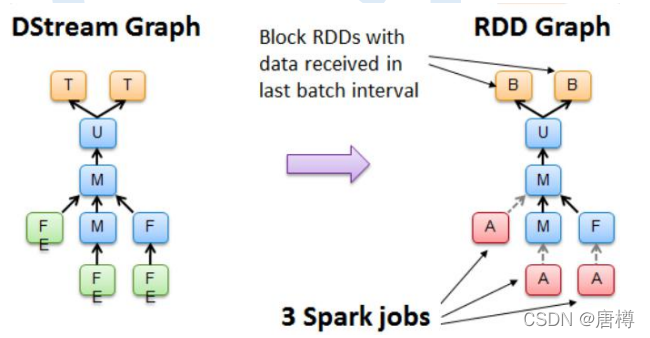
每个时间间隔会积累一定的数据 ,这些数据可以看成由event组成(假设以kafka或者Flume为例),时间间隔是固定的,在时间间隔内的数据就是固定的。也就是RDD是由一个时间间隔内所有数据构成。时间维度的不同,导致每次处理的数据量及内容不同。
随着时间的流逝,基于DStream Graph会不断的生成RDD Graph也就是DAG的方式产生Job,并通过Jobscheduler的线程池提交给Spark Cluster不断的执行。
四、Spark Streaming 架构
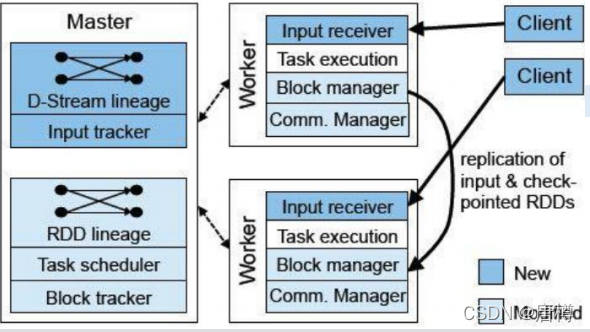
整个架构由3个模块组成:
- Master:记录Dstream之间的依赖关系或者血缘关系,并负责任务调度以生成新的RDD。
- Worker:①从网络接收数据并存储到内存中;②执行RDD计算。
- Client:负责向SparkStreaming中灌入数据(flume\kafka)
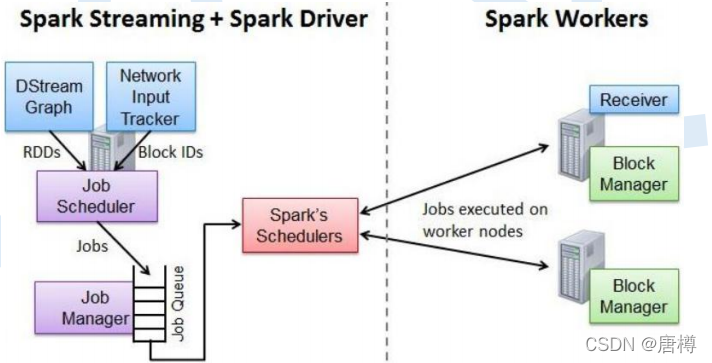
五、Spark Streaming 作业提交
Network Input Tracker:跟踪每一个网络received数据,并且将其映射到相应的input Dstream上。
Job Scheduler:周期性的访问DStream Graph并生成Spark Job,将其交给Job Manager执行。
Job Manager:获取任务队列,并执行Spark任务。
六、Streaming 的容错性
实时的流式处理系统必须是7*24运行的,同时可以从各种各样的系统错误中恢复,在设计之初 ,Spark Streaming就支持driver和worker节点的错误恢复。
Worker容错:spark和rdd保证worker节点的容错性。spark streaming构建在spark之上, 所以它的worker节点也有同样的容错机制。
Driver容错:依赖 WAL(Write Ahead Log)持久化日志。启动WAL需要做如下的配置:
- 给streamingContext设置checkpoint的目录,该目录必须是HADOOP支持的文件系统hdfs,用来保存WAL和 做Streaming的checkpoint;
- spark.streaming.receiver.writeAheadLog.enable 设置为true;
- 注意receiver才有WAL。
6.1 Streaming 中的 WAL 简介
Spark应用分布式运行的,如果driver进程挂了,所有的executor进程将不可用,保存在这些进程所持有内存中的数据将会丢失。为了避免这些数据的丢失,Spark Streaming中引入了一个WAL (write ahead logs)。
WAL 在文件系统和数据库中用于数据操作的持久化,先把数据写到一个持久化的日志中,然后对数 据做操作,如果操作过程中系统挂了,恢复的时候可以重新读取日志文件再次进行操作。
如果WAL启用了,所有接收到的数据会保存到一个日志文件中去(HDFS), 这样保存接收数据的持久性,此外,如果只有在数据写入到log中之后接收器才向数据源确认,这样drive重启后,那些保存在内存中,但没有写入到Log中的数据将会重新发送,这样就保证的数据的无丢失。
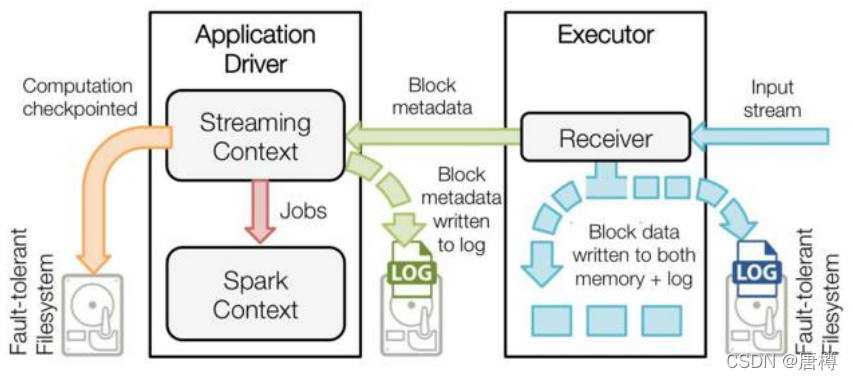
解读上图的工作原理:
- 蓝色的箭头表示接收的数据:接收器(input stream)把数据流打包成块,存储在Executor的内存中,如果开启了WAL,将会把数据写入到有容错文件系统的日志文件中。
- 青色的箭头表示提醒 Driver:把接收到的数据块(Block)的元信息发送给 Driver中的StreamingContext,这些元数据包括:Executor内存中数据块的引用ID和日志文件中数据块的偏移信息。
- 红色箭头表示处理数据:每一个批处理间隔,StreamingContext使用块信息用来生成RDD和Jobs,SparkContext执行这些job用于处理executor内存中的数据块。
- 橙色箭头表示checkpoint计算:以便于数据恢复,流式处理会周期的被checkpoint到文件中。
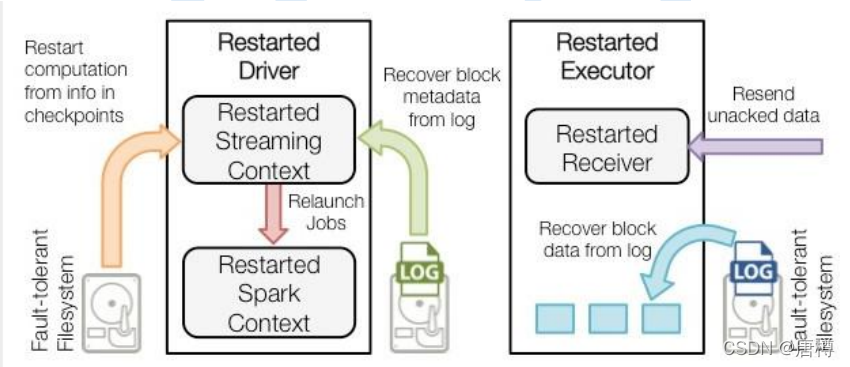
当Driver 失败重启,恢复流程原理:
- 橙色的箭头用于恢复计算:checkpointed的信息是用于重启Driver,重新构造上下文和重启所有的 Receiver;
- 青色箭头恢复块元数据信息:所有的块信息对恢复计算很重要;
- 红色箭头重新生成未完成的job:会使用到恢复的元数据信息;
- 蓝色箭头读取保存在日志(Log)中的块:当job重新执行的时候,块数据将会直接从日志中读取;
- 紫色的箭头重发没有确认的数据:缓冲的数据没有写到WAL中去将会被重新发送。
6.2 Spark Streaming 接受数据的方式
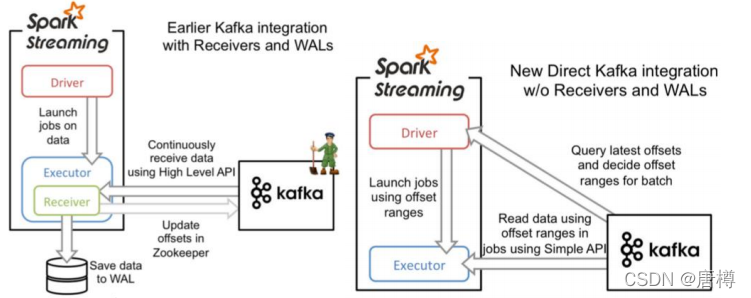
Direct Approach (No Receivers):offset 自己存储和维护,由Spark维护,且可以从每个分区读取数据,调用Kafka 低阶API。
Receiver-based Approach:offset 存储在zookeeper,由 Receiver 维护,Spark获取数据存入Executor中,调用 Kaka高阶API。
Direct Approach (No Receivers):
- Direct 的方式是会直接操作kafka底层的元数据信息
- 由于直接操作的是kafka,kafka就相当于底层的文件系统(对应receiver的executor内存)。
- 由于底层是直接读数据,没有所谓的Receiver,直接是周期性(Batch Intervel)的查询kafka, 处理数据的时候,我们会使用基于kafka原生的consumer api来获取kafka中特定范围(offset 范围)中的数据。
- 读取多个kafka partition,Spark也会创建RDD的partition,这个时候RDD的partition和 kafka的partition是一致的。
- 且不需要开启wal机制,从数据零丢失的角度来看,极大的提升了效率,还至少能节省一倍的磁盘 空间。从kafka获取数据,比从hdfs获取数据,因为zero copy的方式,速度肯定更快。
两种方式对比:
Receiver(高层次的消费者API):在失败的情况下,有些数据很有可能会被处理不止一次。 接收到的数据被可靠地保存到WAL中,但是还没有来得及更新Zookeeper中的Kafka偏移量,因此导致数据不一致性:。Streaming知道数据被接收,但Kafka认为数据正常接收。这样导致系统恢复正常时,Kafka会再一次发送这些数据。
Direct(低层次消费者API):给出每个batch区间需要读取的偏移量位置,每个batch的Job被运行时, 对应偏移量的数据从Kafka拉取,偏移量信息也被可靠地存储(checkpoint),重新数据恢复可以直接读取这些偏移量信息。
Direct API消除了需要使用WAL的Receivers的情况,而且确保每个Kafka记录仅被接收一次并被高效地接收 。这就使得我们可以将Spark Streaming和Kafka很好地整合在一起。
总体来说,这些特性使得流处理管道拥有高容错性,高效性,而且很容易地被使用。


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











