







Spark Streaming实时计算框架
近年来,在Web应用、网络监控、传感监测、电信金融、生产制造等领域,增强了对数据实时处理的需求,而Spark中的Spark Streaming实时计算框架就是为实现对数据实时处理的需求而设计
1,什么是实时计算
在传统的数据处理流程(离线计算)中,复杂的业务处理流程会造成结果数据密集,结果数据密集则存在数据反馈不及时,若是在实时搜索的应用场景中,需要实时数据做决策,而传统的数据处理方式则并不能很好地解决问题,这就引出了一种新的数据计算——实时计算,它可以针对海量数据进行实时计算,无论是在数据采集还是数据处理中,都可以达到秒级别的处理要求。
2,Spark Streaming概述
- Spark Streaming是一个构建在Spark之上,是Spark四大组件之一
- 是Spark系统中用于处理流式数据的分布式流式处理框架
- 具有可伸缩、高吞吐量、容错能力强等特点。
- 能够和Spark SQL、MLlib、GraphX无缝集成
- 处理的数据源可以来自Kafka,Flume,Twitter,ZeroMQ,Kinesis or TCP sockets
- 不仅可以通过调用map,reduce,join和window等API函数来处理数据,也可- 以使用机器学习、图算法来处理数据
- 最终结果可以保存在文件系统、数据库或者实时Dashboard展示
3,Spark Streaming运行原理
- Spark Streaming的输入数据按照时间片(batch size)分成一段一段的数据,得到批数据(batch data),每一段数据都转换成Spark中的RDD,然后将Spark Streaming中对DStream的Transformation操作变为针对Spark中的RDD的Transformation操作,将RDD经过操作变成中间结果保存在内存中。整个流式计算根据业务的需求可以对中间的结果进行叠加或者存储到外部设备。
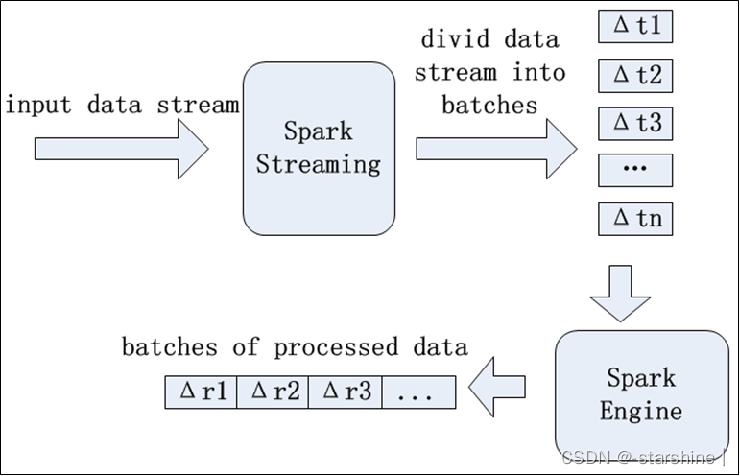
4,初步使用Spark Streaming(词频统计)
1,创建StreamingContext对象
2,创建InputDStream:Spark Streaming需要指明数据源,DStream输入源包括基础来源和高级来源,基础来源是在StreamingContext API中直接可用的来源,如文件系统、Socket连接和Akka actors。高级来源包括Kafka、Flume、Kinesis、Twitter等,高级来源可以通过额外的实用工具类创建
3,操作DStream:对于从数据源得到的DStream,用户可以在其基础上进行各种操作
3,启动Spark Streaming:之前的所有步骤只是创建了执行流程,程序没有真正连接上数据源,也没有对数据进行任何操作,只是设定好了所有的执行计划,当ssc.start()启动后程序才真正进行所有预期的操作
具体代码:
1,在slave1下载nc监听服务
yum -y install nc
2,在 master节点启动spark-shell
[hadoop@master spark]$ bin/spark-shell --master local[2]
3,编写代码:
scala> import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.StreamingContext
scala> import org.apache.spark.streaming.StreamingContext._
import org.apache.spark.streaming.StreamingContext._
scala> import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.dstream.DStream
scala> import org.apache.spark.streaming.Duration
import org.apache.spark.streaming.Duration
scala> import org.apache.spark.streaming.Seconds
import org.apache.spark.streaming.Seconds
scala> sc.setLogLevel("WARN")
scala> val ssc = new StreamingContext(sc,Seconds(1))
ssc: org.apache.spark.streaming.StreamingContext = org.apache.spark.streaming.StreamingContext@664f49f
scala> val lines = ssc.socketTextStream("slave1",8888)
lines: org.apache.spark.streaming.dstream.ReceiverInputDStream[String] = org.apache.spark.streaming.dstream.SocketInputDStream@53432aef
scala> val words=lines.flatMap(_.split(" "))
words: org.apache.spark.streaming.dstream.DStream[String] = org.apache.spark.streaming.dstream.FlatMappedDStream@fd0e118
scala> val wordCounts = words.map(x => (x,1)).reduceByKey(_+_)
wordCounts: org.apache.spark.streaming.dstream.DStream[(String, Int)] = org.apache.spark.streaming.dstream.ShuffledDStream@22561412
scala> wordCounts.print()
scala> ssc.start()
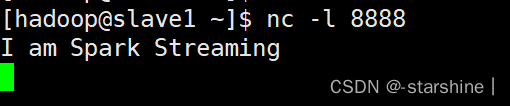
4,在slave1启动nc
[hadoop@slave1 ~]$ nc -l 8888
5,在slave1输入内容,查看master。
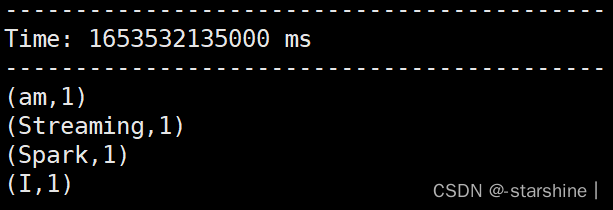















 1273
1273











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









