









文章目录
启动集群先:hadoop集群、hive服务端、spark集群,进入spark-shell。
使用orders,priors表。
val orders = spark.sql("select * from badou.orders").cache
val priors = spark.sql("select * from badou.priors").cache
1、每个用户平均购买订单的间隔周期
需要用户ID(user_id)、订单周期(days_since_prior_order)。
import spark.sql
sql("use badou")
sql("select * from orders ").show(5)
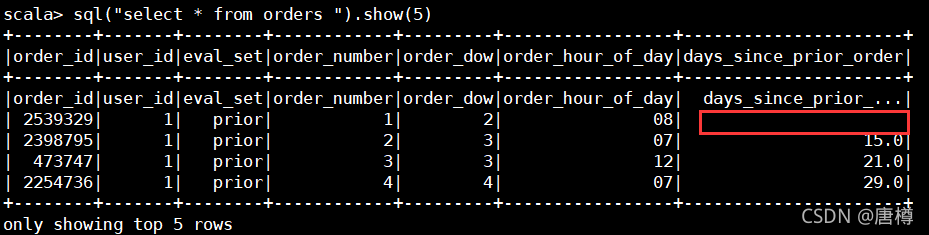
通过查看数据,发现用户的第一个订单没有间隔天数的,需要进行数据缺失处理,保持数据完整性。
val orderNew = orders.selectExpr("*", "if(days_since_prior_order='',0.0,days_since_prior_order) as dspo").drop("days_since_prior_order")
orderNew.show(5)
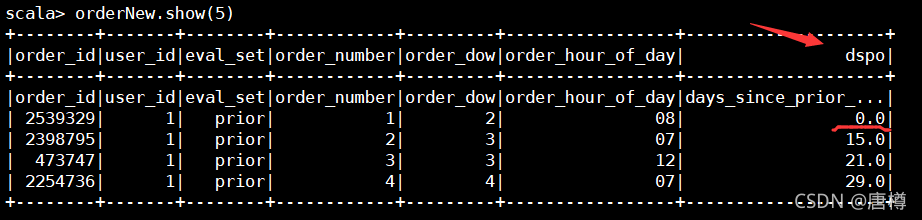
对数据进行处理后,对用户id分组,平均avg 订单间隔天数(dspo),重命名dspo 为 avg_day_gap。
val userGap = orderNew.selectExpr("user_id","cast(dspo as int) as dspo ").groupBy("user_id").avg("dspo").withColumnRenamed("avg(dspo)","avg_day_gap")
userGap.show(5)

可以发现每个用户平均购买订单的间隔周期,例如用户296,他的间隔天数约5.43天。用户675 间隔天数20天,因此用户675比较不活跃,需要我们提供策略刺激该用户的订单消费。
2、每个用户的总订单数量(分组)
这个用orders表即可,对用户ID分区,再对订单count。
val user_pro_count= orders.groupBy("user_id").count()
user_pro_count.show(5)
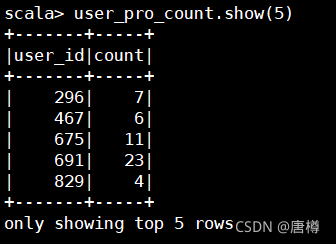
看用户296的订单数较少,而他的订单间隔天数较短,可以推断该用户在一段持续时间内积极下单消费。
3、每个用户购买的product商品去重后的集合数据
先整合 orders与priors表的用户购买商品数据,可以用join 连接两个表的数据另存。
val all_orders = orders.join(priors,"order_id")
val user_pro = all_orders.select("user_id","product_id").cache
user_pro.show(5)
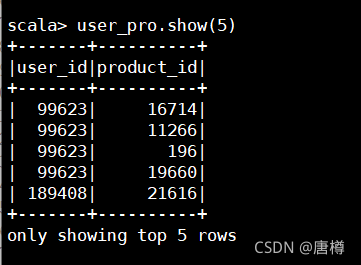
- 把两个表的数据结果赋予 user_pro 变量。
- 把"user_id"作为key, "product_id"作为Value。
- mapValues对"product_id"进行toSet.mkString(",") 逗号分割。
import spark.implicits._
// 将DataFrame 转变为RDD
val rddRecords = user_pro.rdd.map{x=>(x(0).toString, x(1).toString())}.groupByKey().mapValues(record=>record.toSet.mkString(","))
// 格式化输出
rddRecords.toDF("user_id", "product_records").show(5)
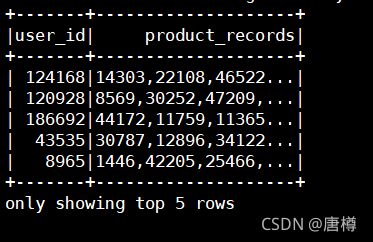
可以得到每个用户购买的所有订单。
4、每个用户总商品数量以及去重后的商品数量(distinct count)
// 每个用户总商品数量
val userAllProd = user_pro.groupBy("user_id").count()
// 每个用户去重后的商品数量
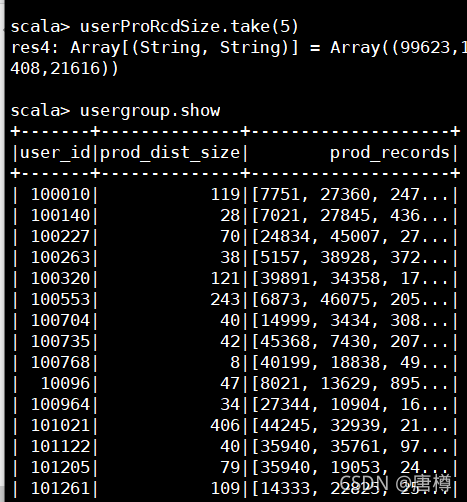
val userUnOrdCnt = user_pro.rdd.map{x=>(x(0).toString, x(1).toString)}.groupByKey().mapValues(_.toSet.size).toDF("user_id","prod_dis_cnt")
// 方式一:同时计算两个
val userProRcdSize = user_pro.rdd.map{x=>(x(0).toString, x(1).toString)}
.groupByKey().mapValues{records=> val rs = records.toSet;
(rs.size, rs.mkString(","))}.toDF("user_id", "tuple")
.selectExpr("user_id","tuple._1 as prod_dist_size", "tuple._2 as prod_records")
// 方式二:使用自带的函数的处理
val usergroup = user_pro.groupBy("user_id").agg(size(collect_set("product_id")).as("prod_dist_size"),collect_set("product_id").as("prod_records"))

5、每个用户购买的平均每个订单的商品数量(hive已经实现过了)
// 每个订单有多少个商品
val ordProdCnt = priors.groupBy("order_id").count()
// 求每个用户订单商品数量的平均值 user_id product_id
val userPerOrdProdCnt = orders.join(ordProdCnt, "order_id")
.groupBy("user_id").agg(avg("count").as("avg_ord_prods"))















 1189
1189











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











