






 本文介绍了如何在Python环境下安装scikit-learn库,处理鸢尾花数据集,进行数据预处理,训练SVM分类器,以及模型评估和结果可视化的过程。
本文介绍了如何在Python环境下安装scikit-learn库,处理鸢尾花数据集,进行数据预处理,训练SVM分类器,以及模型评估和结果可视化的过程。
步骤一:准备环境
安装python和scikit-learn
更新软件命令
sudo apt update
安装python
sudo apt install python3 python3-pip
安装Scikit-learn matplotlib
pip3 install scikit-learn matplotlib
这里安装出错,尝试解决问题,一是没有权限,所以使用sudo再次执行,还是出错;二是缺少依赖项,尝试先安装依赖,但还是出错。最后使用的第三个办法,尝试换源,问题得到解决。
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple scikit-learn matplotlib
步骤二:下载数据集
从scikit-learn的内置数据集中获取鸢尾花数据集
使用python代码加载
from sklearn.datasets import load_iris
#加载鸢尾花数据集
iris = load_iris()
#输出数据集的描述信息
print(iris.DESCR)步骤三:数据预处理
将数据集分割为训练集和测试集,并进行特征缩放(归一化)
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
#将数据集划分为训练集和测试集
X_train,X_test,y_train,y_test = train_test_split(iris.data,iris.target,test_size=0.2,random_state=42)
#特征缩放(归一化)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
步骤四:训练模型
这里使用支持向量机(SVM)作为分类器。(可以根据需要选择其他模型)
from sklearn.svm import SVC
#创建支持向量机分类器
svm_clf = SVC(kernel='linear',C=1.0,random_state=42)
#在训练集上训练模型
svm_clf.fit(X_train_scaled,y_train)
步骤五:模型评估
将模型早测试集上进行评估,并输出评估指标。
from sklearn.metrics import
accuracy_score,classification_report,confusion_matrix
#在测试集上进行预测
y_pred = svm_clf.predict(X_test_scaled)
#输出准确率
accuracy = accuracy_score(y_test,y_pred)
print("Accuracy:",accuracy)
#输出分类报告
print(“Classification Report:")
print(classification_report(y_test,y_pred))
#输出混淆矩阵
print("Confusion Matrix:")
print(confusion_matrix(y_test,y_pred))步骤六:结果可视化
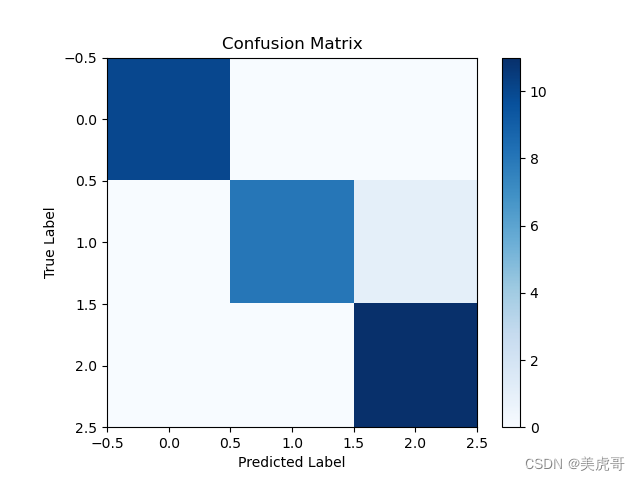
将模型预测结果可视化,更好的理解模型的性能。
import matplotlib.pyplot as plt
#可视化混淆矩阵
plt.imshow(confusion_matrix(y_test,y_pred),cmap='Blues',interpolation='nearest')
plt.colorbar()
plt.title('Confusion Matrix')
plt.xlabel('Predicted Label')
plt.ylabel('True Label')
plt.show()















 4084
4084











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









