







 该专栏为热销专栏榜 第21名
该专栏为热销专栏榜 第21名摘要
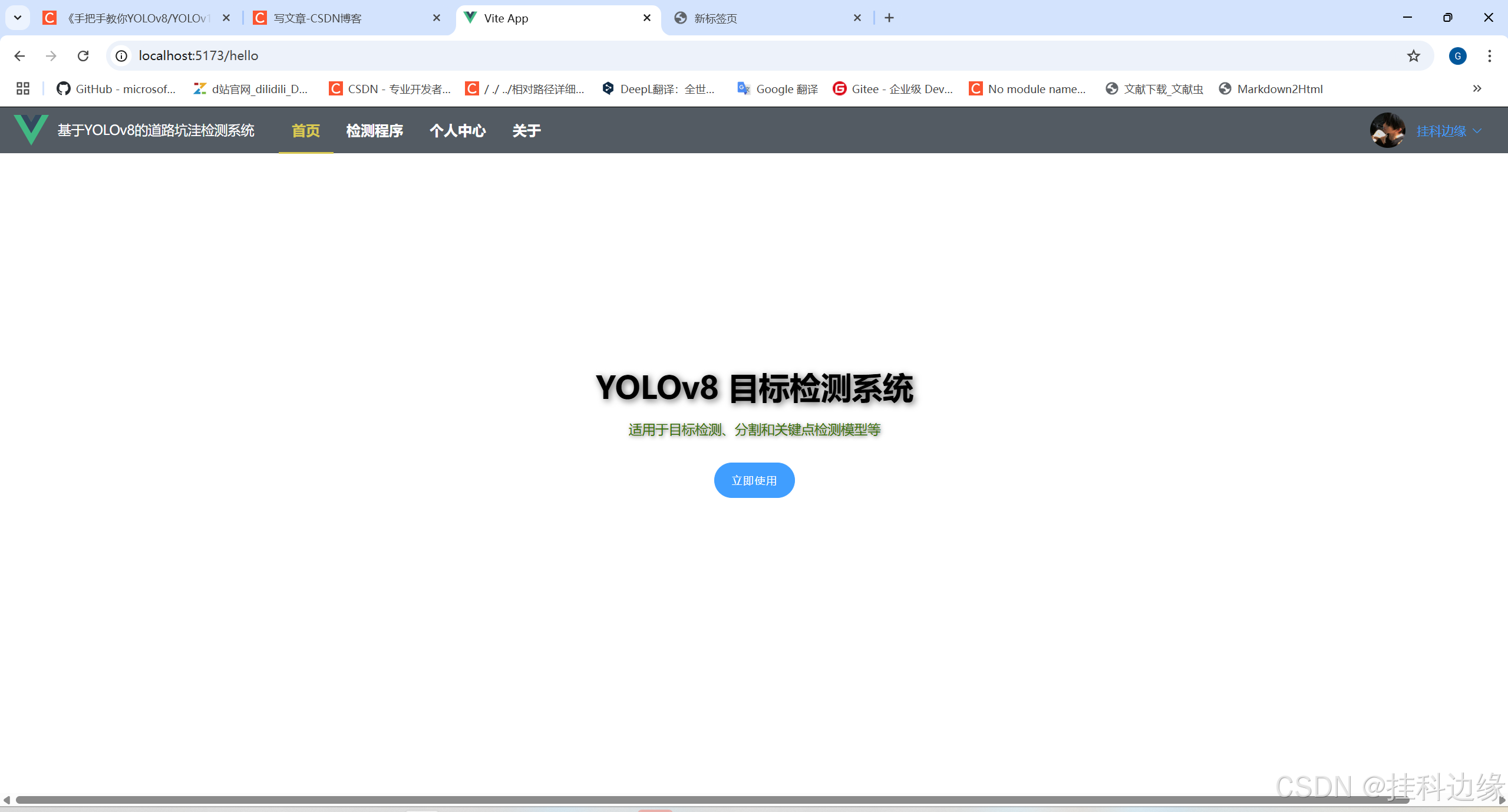
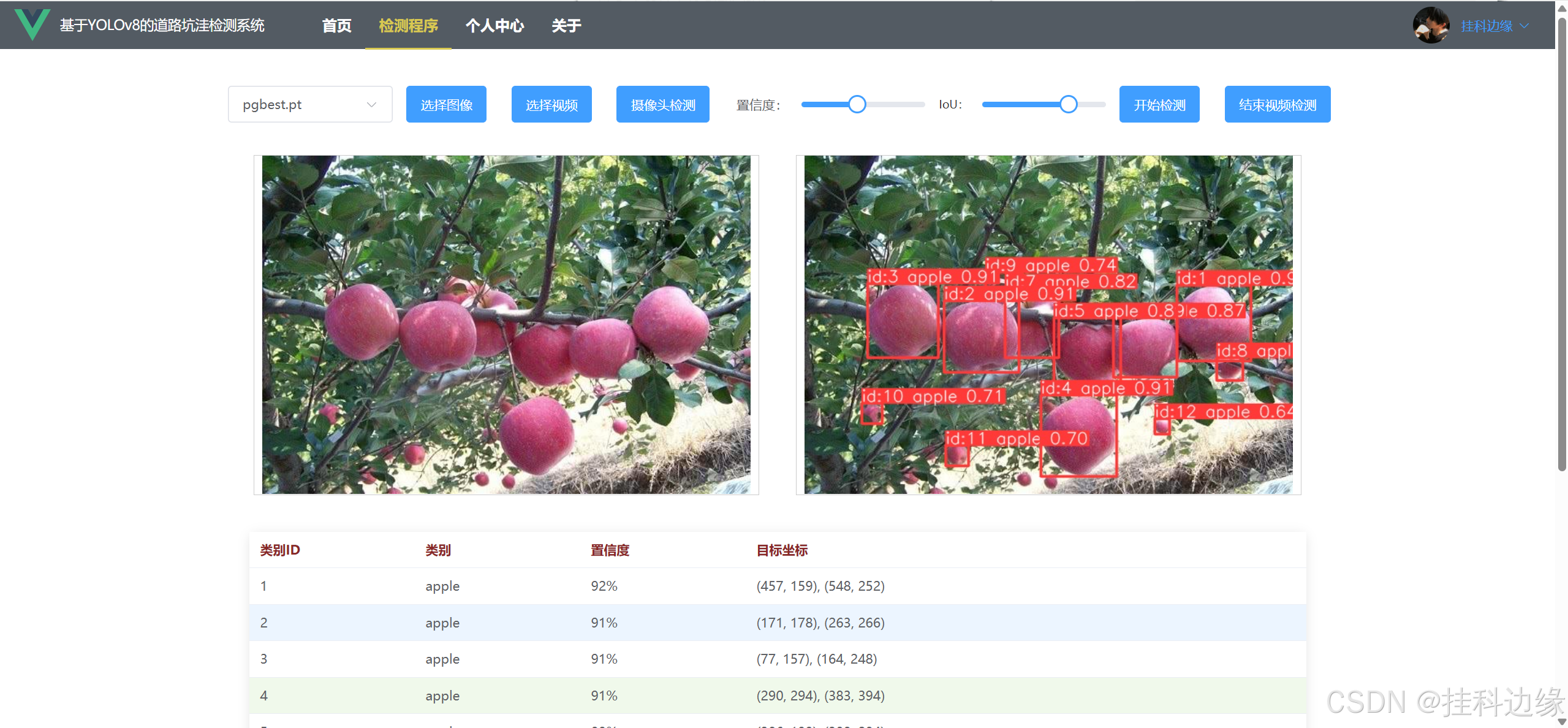
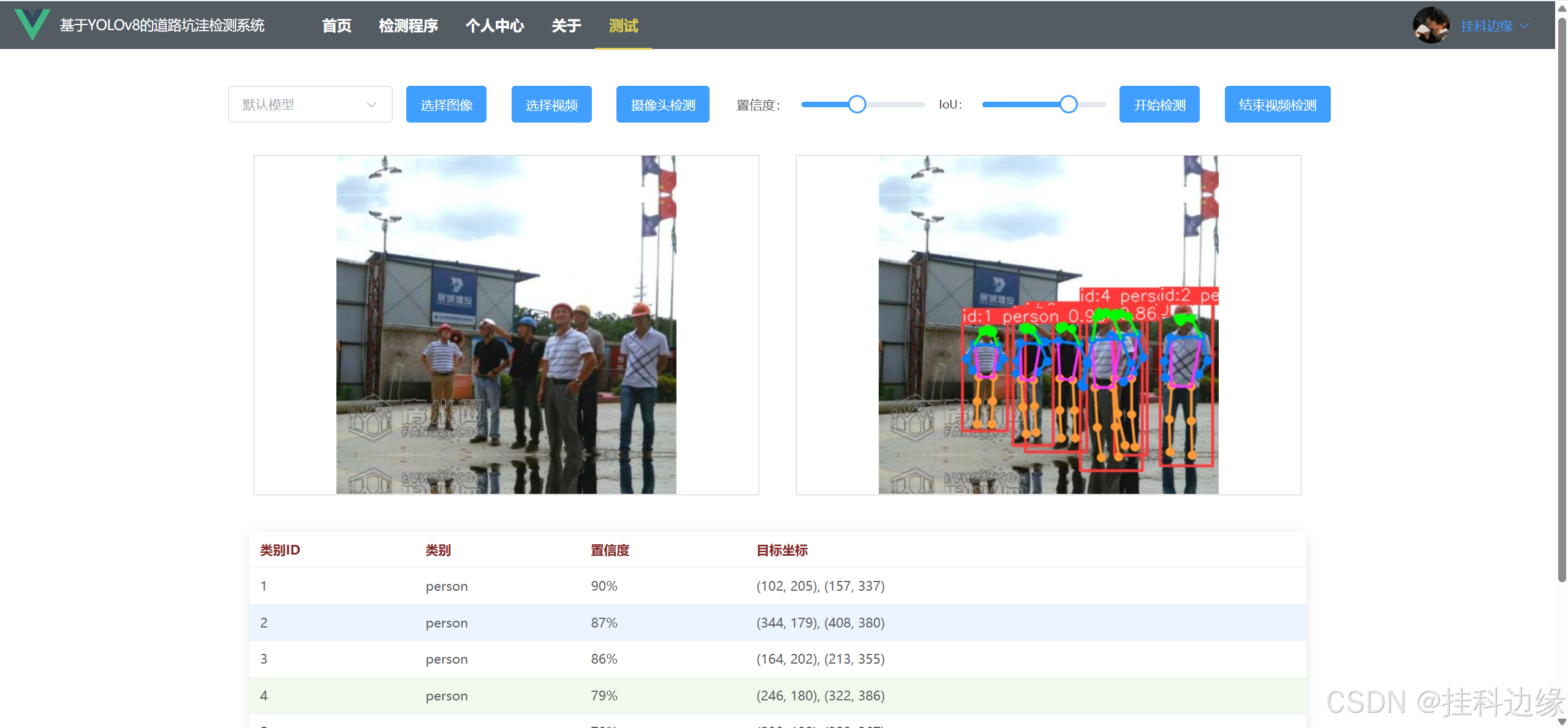
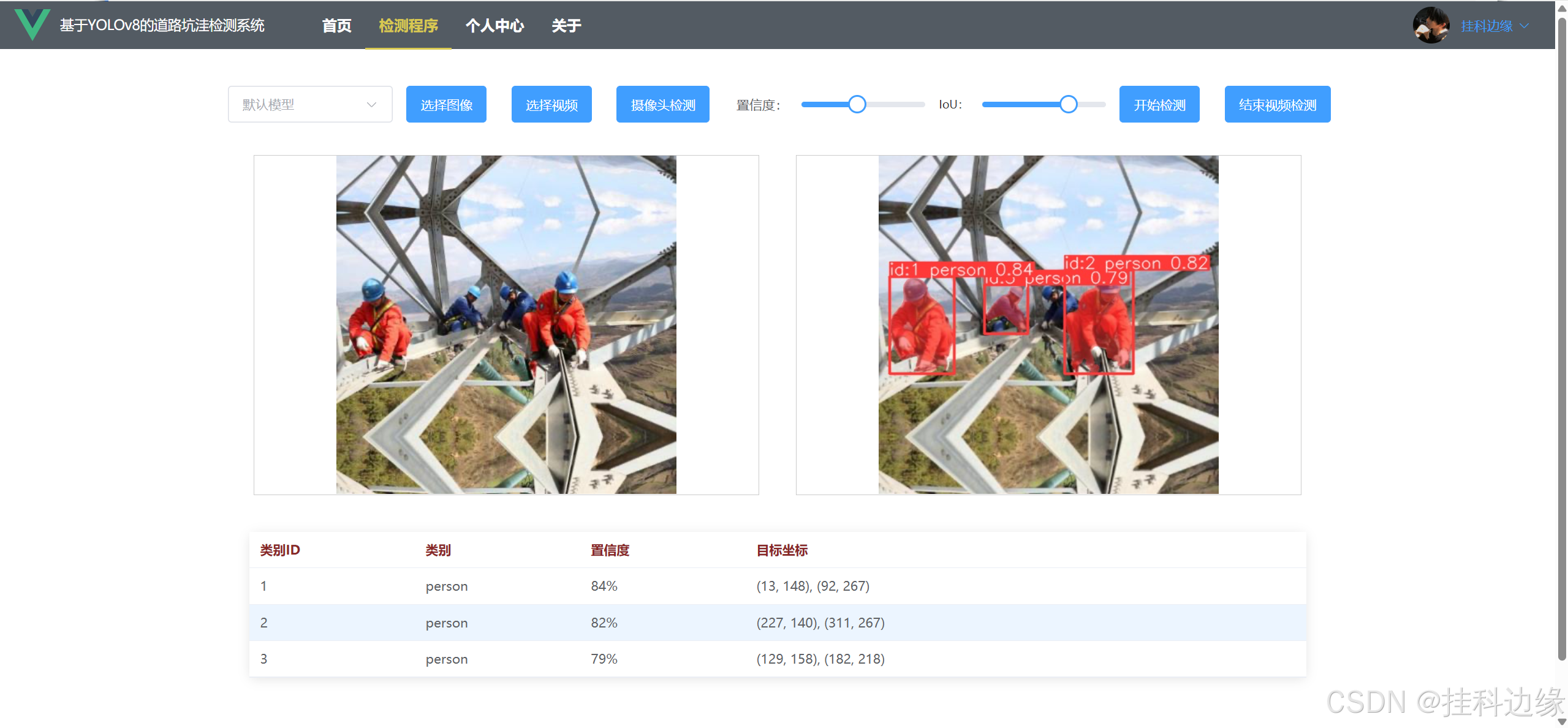
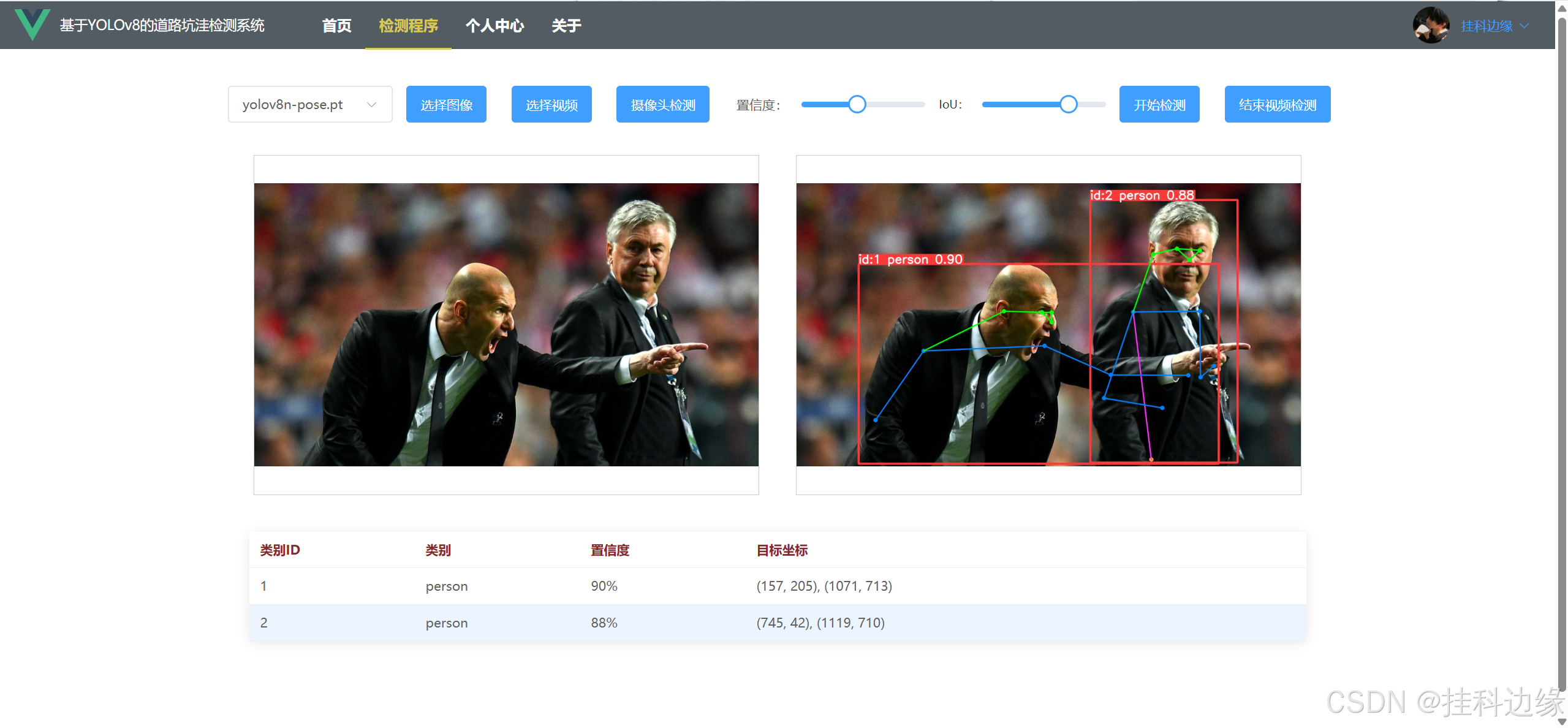
目标检测是计算机视觉中的重要任务,广泛应用于安防监控、自动驾驶、智能家居等领域。YOLO系列模型由于其高效的检测速度和较高的准确率,成为目标检测任务的首选算法之一。本项目结合 YOLOv8 与 Django + Vue3,构建了一个通用的 Web 前后端系统,便于用户进行目标检测的操作和展示,实现对图片、视频实时目标检测和摄像头实时检测,不仅可以用于大论文的工作量展示,还可以作为毕业设计。支持更换自己模型、图片检测、实时视频检测、置信度调节和IoU参数调节。同时支持目标检测、实例分割、关键点检测等任务,兼顾科研、大作业、个人学习、毕设、工业等应用场景。
✔️功能:图片检测、视频检测、摄像头检测、登录和注册功能、退出登录、界面保存登录状态、个人信息修改、密码修改、头像修改、,前端界面代码使用 Vue3,后端代码使用 YOLOv8 + Django,真正实现前后端分离,前端发送数据,后端处理再返回给前端展示,界面如下:


 订阅专栏 解锁全文
订阅专栏 解锁全文


















 4255
4255

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











