






个人博客:无奈何杨(wnhyang)
个人语雀:wnhyang
共享语雀:在线知识共享
Github:wnhyang - Overview
参考
https://www.elastic.co/guide/en/elasticsearch/reference/8.14/fix-common-cluster-issues.html
Elasticsearch运维指南-腾讯云开发者社区-腾讯云
elasticsearch重启后,unassigned索引重新分片失败YELLO、RED恢复处理_es报错分片失败-CSDN博客
磁盘空间不足导致 Elasticsearch 锁定索引无法写入数据 | Anonymity94
Elasticsearch - 随笔分类 - 散尽浮华 - 博客园
尤其是最后这个链接非常建议看一下,太棒了!
命令
小提示
在请求后加上?v触发详细响应信息,拼上?pretty后json美化。
如:curl -X GET localhost:9200/_cat/nodes?pretty响应为
192.168.168.100 66 99 4 0.45 0.22 0.22 mdi - node-2
192.168.168.101 57 99 4 0.35 0.21 0.21 mdi * node-1
192.168.168.102 52 99 4 0.20 0.15 0.18 mdi - node-3
改命令为:curl -X GET localhost:9200/_cat/nodes?v&pretty后响应为
可以看到已经有头信息了。
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
192.168.168.100 60 99 4 0.36 0.21 0.22 mdi - node-2
192.168.168.101 56 99 4 0.36 0.23 0.22 mdi * node-1
192.168.168.102 52 99 4 0.13 0.13 0.18 mdi - node-3
常用
# 集群健康检查
curl -X GET localhost:9200/_cluster/health
# 集群设置
curl -X GET localhost:9200/_cluster/settings
# 节点查看
curl -X GET localhost:9200/_cat/nodes
# 所有索引查询
curl -X GET localhost:9200/_cat/indices
# 指定索引设置查询
curl -X GET lcoalhost:9200/${my_index}/_settings
# 所有分片查询
curl -X GET localhost:9200/_cat/shards
# 指定索引分片查询
curl -X GET localhost:9200/_cat/shards/${my_index}
# 所有别名查询
curl -X GET localhost:9200/_cat/aliases
# 指定别名查询
curl -X GET localhost:9200/_cat/aliases/${my_aliases}
# 磁盘使用情况
curl -X GET localhost:9200/_cat/allocation
# 筛选未分配的分片
curl -X GET localhost:9200/_cat/shards?v | grep UNASSIGNED
# 查看allocation失败原因
curl -X GET localhost:9200/_cluster/allocation/explain?pretty
检查集群状态
通常使用curl -X GET localhost:9200/_cluster/health?pretty检查es集群状态,如下面的响应数据。
{
"cluster_name": "xxxCluster",
"status": "green",
"timed_out": false,
"number_of_nodes": 3,
"number_of_data_nodes": 3,
"active_primary_shards": 1370,
"active_shards": 2724,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 0,
"delayed_unassigned_shards": 0,
"number_of_pending_tasks": 0,
"number_of_in_flight_fetch": 0,
"task_max_waiting_in_queue_millis": 0,
"active_shards_percent_as_number": 100
}
每个字段说明如下:
- cluster_name:集群的名称。
- status:集群的整体状态,可能的值有:
-
- green:所有主分片和副本分片都处于活动状态。
- yellow:所有主分片都处于活动状态,但不是所有副本分片都处于活动状态。
- red:至少有一个主分片不处于活动状态。
- timed_out:布尔值,指示请求是否超时。
- number_of_nodes:集群中节点的总数。
- number_of_data_nodes:集群中数据节点的总数。
- active_primary_shards:当前活动的主分片数量。
- active_shards:当前活动的分片总数(包括主分片和副本分片)。
- relocating_shards:正在迁移的分片数量。
- initializing_shards:正在初始化的分片数量。
- unassigned_shards:未分配的分片数量。
- delayed_unassigned_shards:延迟分配的未分配分片数量。
- number_of_pending_tasks:等待执行的任务数量。
- number_of_in_flight_fetch:正在执行的远程获取请求数量。
- task_max_waiting_in_queue_millis:任务队列中的最长等待时间(以毫秒为单位)。
- active_shards_percent_as_number:活动分片的百分比。
集群中宕掉一个节点会发生什么
假如有5个节点组成es集群,5个节点分别是node1、node2、node3、node4、node5,宕掉了node1。
1、假死与节点下线检测
其他节点会尝试与失联节点建立通信。如果节点在一段时间内没有响应,其他节点会将其标记为失联。心跳检测ping超时时间、重试次数等配置查看discovery.zen开头的配置项。
2、重新分配分片
当一个节点失联时,它上面的分片将被重新分配到其他可用节点上,以保持数据的可用性和可靠性。
以其中一个索引来分析,此索引主分片设置5,副本设置2。
查看此索引设置curl -X GET lcoalhost:9200/${my_index}/_settings
查看此索引分片curl -X GET localhost:9200/_cat/shards/${my_index}
index shard prirep state docs store ip node
xxx-20240530 2 p STARTED 5043 15.2mb es3 node3
xxx-20240530 2 r STARTED 5043 15.6mb es5 node5
xxx-20240530 2 r STARTED 5043 15.6mb es1 node1
xxx-20240530 1 r STARTED 5164 15.5mb es1 node1
xxx-20240530 1 r STARTED 5164 15.5mb es3 node3
xxx-20240530 1 p STARTED 5164 15.5mb es2 node2
xxx-20240530 0 r STARTED 5042 15.6mb es2 node2
xxx-20240530 0 r STARTED 5042 15.6mb es4 node4
xxx-20240530 0 p STARTED 5042 15.6mb es3 node3
xxx-20240530 3 r STARTED 5164 15.5mb es5 node5
xxx-20240530 3 r STARTED 5164 15.5mb es2 node2
xxx-20240530 3 p STARTED 5164 15.5mb es4 node4
xxx-20240530 4 r STARTED 5042 15.6mb es1 node1
xxx-20240530 4 r STARTED 5042 15.6mb es4 node4
xxx-20240530 4 p STARTED 5042 15.6mb es5 node5
索引分片分布如下图,P表示主分片,R表示副本分片,a、b只是为了区分副本分片。

当node1下线后,其上的分片都变为不可用状态。仅从此索引来看的话就是主分片P2、副本R1.a、R4.b不可用,重新分配分片要做的就是重新建立或移动这些分片。
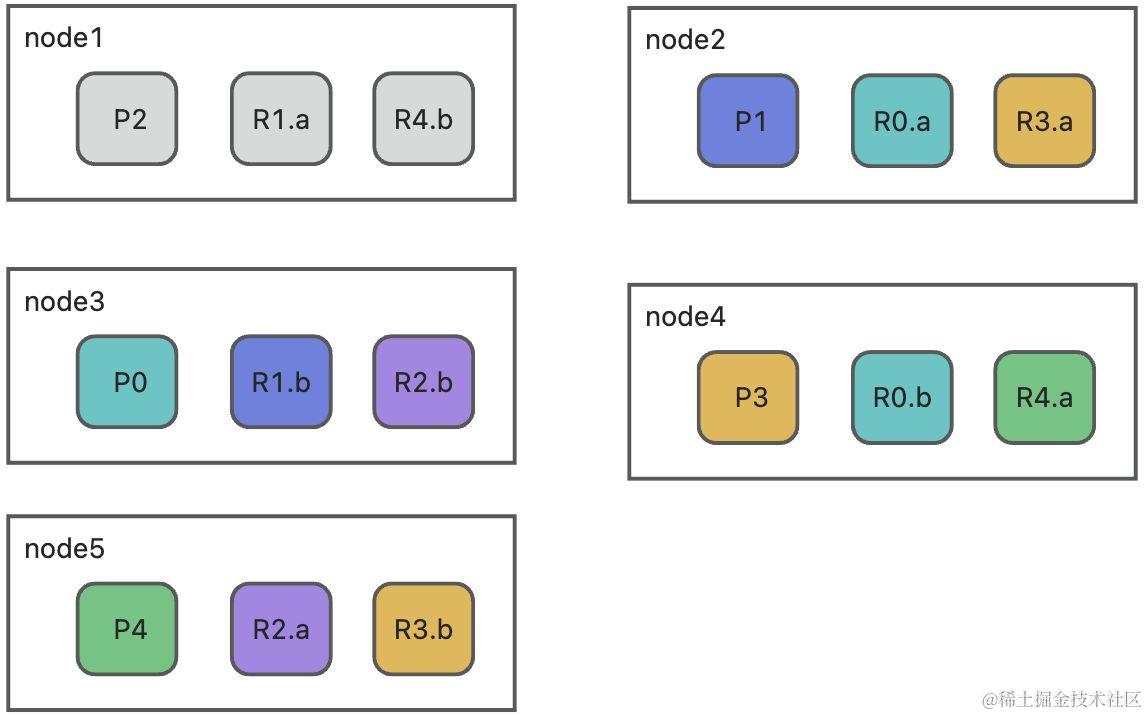
3、主分片的重新选举
如果失联节点上有主分片,其他副本分片会参与选举新的主分片。这确保了即使失联节点上的主分片不可用,集群仍能继续工作。
因为node1下线,此索引主分片P2不在了,所以要从已有R1.a和R1.b两个副本分片中选取一个作为主分片。
4、更新集群状态
集群状态会根据重新分配的分片数量和状态更新。如果主分片无法分配,集群状态可能会变为yellow或red。
在集群状态变为yellow或red的同时,通常伴随着其他指标(relocating_shards 、 initializing_shards 、 unassigned_shards等)的异常。
集群状态不仅是/_cluster/health看到的集群状态,还包括,索引、分片的状态。
5、副本分片复制
如果失联节点上有副本分片,这些副本分片会被用于重新分配到其他节点上。这保证了数据的冗余性和可靠性。
在上面例子中,node1下线后,索引分片2的主分片P2丢失,在已有R1.a和R1.b两个副本分片中选取一个作为主分片后,假如node5上的R1.a晋升为主分片,主分片是有了,但是副本数不够,需要在除node5、node3上创建副本分片。除了丢失了主分片的分片需要创建副本,原本因为节点下线而缺少副本分片的也要创建新的副本,例子中分片1、4都需要再新建一个副本。

此时通过/_cluster/health检查集群,因为并没有冗余或是需要平衡的分片,relocating_shards(重定位/转移分片)为0;根据机器性能和es配置情况initializing_shards 、 unassigned_shards和任务数会有差别。
同时/_cat/indices中会存在red或yellow索引,/_cat/shards存在UNASSIGNED分片。
关于UNASSIGNED分片,原因有下。
curl XGET 'http://ip:9200/_cat/shards?h=index,shard,prirep,state,unassigned.reason' | grep UNASSIGNED
- INDEX_CREATED:索引刚刚创建,分片尚未分配。
- NODE_LEFT:一个或多个节点离开了集群,导致分片无法分配。
- REROUTE_CANCELLED:重新路由过程被取消。
- REPLICA_ADDED:副本分片添加到节点上,但尚未被分配。
- ALLOCATION_FAILED:分配分片到节点上失败。
- CLUSTER_RECOVERED:集群正在恢复。
- EXCEPTION:发生了异常情况,导致分片无法分配。
- IN_SYNC:副本分片已经处于与主分片同步的状态,但尚未被分配。
- INITIALIZING:正在初始化分片。
- PRIMARY_MISSING:主分片丢失,无法找到主分片。
- REBALANCE_CLUSTER_SETTING:由于重新平衡集群设置而导致的未分配。
- RECOVERY_FAILED:分片恢复失败。
- UNKNOWN:未知的未分配原因。
如果在es集群中,UNASSIGNED分片一直存在,长时间没有变化,可以从以上原因方向去分析。
顺带一讲如果你看了一些博客将通过/_cluster/settings看到结果为
{
"persistent" : { },
"transient" : { }
}
博客讲的是自动分配功能未开启,但是其实并不是这样的,es具有许多默认设置,如果没有对集群进行显式的自定义配置,那么集群设置中可能会显示为空。自动分配就是默认开启的。
6、管理维护
这就不属于es集群自治的范围了,需要人工介入。如果节点持续失联,管理员可能会手动将其从集群中移除。这样可以确保集群不会因为失联节点而进一步受到影响。集群的监控系统可能会生成警报,通知运维人员和开发人员来处理问题。
集群中新加入一个节点会发生什么
1、节点发现和加入
新节点会通过集群的发现机制发现已知节点,并向它们发送加入请求。这些请求包含了新节点的基本信息和能力,例如它的IP地址、角色(数据节点、主节点等)、硬件配置等。
2、节点启动和初始化
新节点收到加入请求后,会启动并初始化自身。这包括加载配置、启动Elasticsearch服务、加入集群、并与集群中的其他节点建立通信。
3、角色分配
根据集群的配置和节点的能力,新节点会被分配适当的角色。例如,如果集群需要更多的数据节点来存储数据,新节点可能会被分配为数据节点;如果集群需要更多的主节点来处理集群级别的操作,新节点可能会被分配为主节点。
4、分片重新平衡
一旦新节点加入集群并分配了角色,集群可能会启动分片的重新平衡过程。这意味着一些分片可能会从现有节点重新分配到新节点上,以实现数据的均衡分布和提高集群的整体性能。
计算分片分配方案
集群中的协调节点(coordinating node)负责计算分片的分配方案。它会根据集群的配置、节点的状态和负载情况等因素,确定哪些分片需要移动,以及移动到哪些节点上。
移动分片
根据计算的分配方案,Elasticsearch会将需要重新分配的分片从源节点移动到目标节点上。这个过程涉及分片的复制、同步和迁移,确保数据的一致性和可用性。
更新元数据
在分片移动完成后,Elasticsearch会更新集群的元数据,包括分片的位置、状态和分配情况等信息。这样,集群就能够知道每个分片的当前位置和状态。
触发复制和同步
如果移动的是副本分片,Elasticsearch会触发副本分片的复制和同步过程。这确保了数据的冗余性和高可用性,即使在节点故障时也能保持数据的完整性。
分片的平衡被多方面影响,你可能听过“理论存在,实践开始”这句话。在负载中有轮询、hash、权重,用于平衡服务差异,目标是做到所有服务的请求稳定。在数据分布上,我们也期待着平衡,也有磁盘占用率、CPU处理效率、IO读写效率差异而带来的不同平衡机制。虽然这些平衡机制存在,但是在无论是在服务多活还是中间件集群中尽量都要使用相同配置的机器,这样就能减少因为硬件差异带来的软件性能的差异。
5、管理运维
属于人工范畴,集群状态更新时应该被监控系统监听到并通知相应的运维人员和开发负责人,根据具体情况处理。
锁文件node.lock
Elasticsearch中的node.lock文件是用于跟踪节点是否已经启动的标记文件。当一个Elasticsearch节点启动时,它会尝试在数据目录下创建一个名为node.lock的文件。这个文件的存在表示节点已经在该数据目录下启动了,而且已经拥有了这个数据目录的控制权。
这个node.lock文件的存在确保了在同一个数据目录下只能运行一个Elasticsearch节点。这是因为如果尝试在一个数据目录下启动第二个节点,第二个节点会检测到已经存在一个node.lock文件,从而拒绝启动。这有助于防止数据目录被多个节点同时使用,从而导致数据的损坏或不一致。
通常情况下,node.lock文件的存在是Elasticsearch节点正常运行的标志。如果你看到这个文件存在,说明节点已经在该数据目录下启动了。如果你想要启动另一个节点,你需要选择一个不同的数据目录,或者删除现有的node.lock文件。
写在最后
拙作艰辛,字句心血,望诸君垂青,多予支持,不胜感激。
个人博客:无奈何杨(wnhyang)
个人语雀:wnhyang
共享语雀:在线知识共享
Github:wnhyang - Overview

















 371
371











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











