






前言
当我们想要截图页面上某个元素(DOM) 的图片时,作为一名前端,你可能下意识的会进行 F12 -> Capture node screenshot 的操作,就像下图的操作一样,然后图片就会自动下载下来。
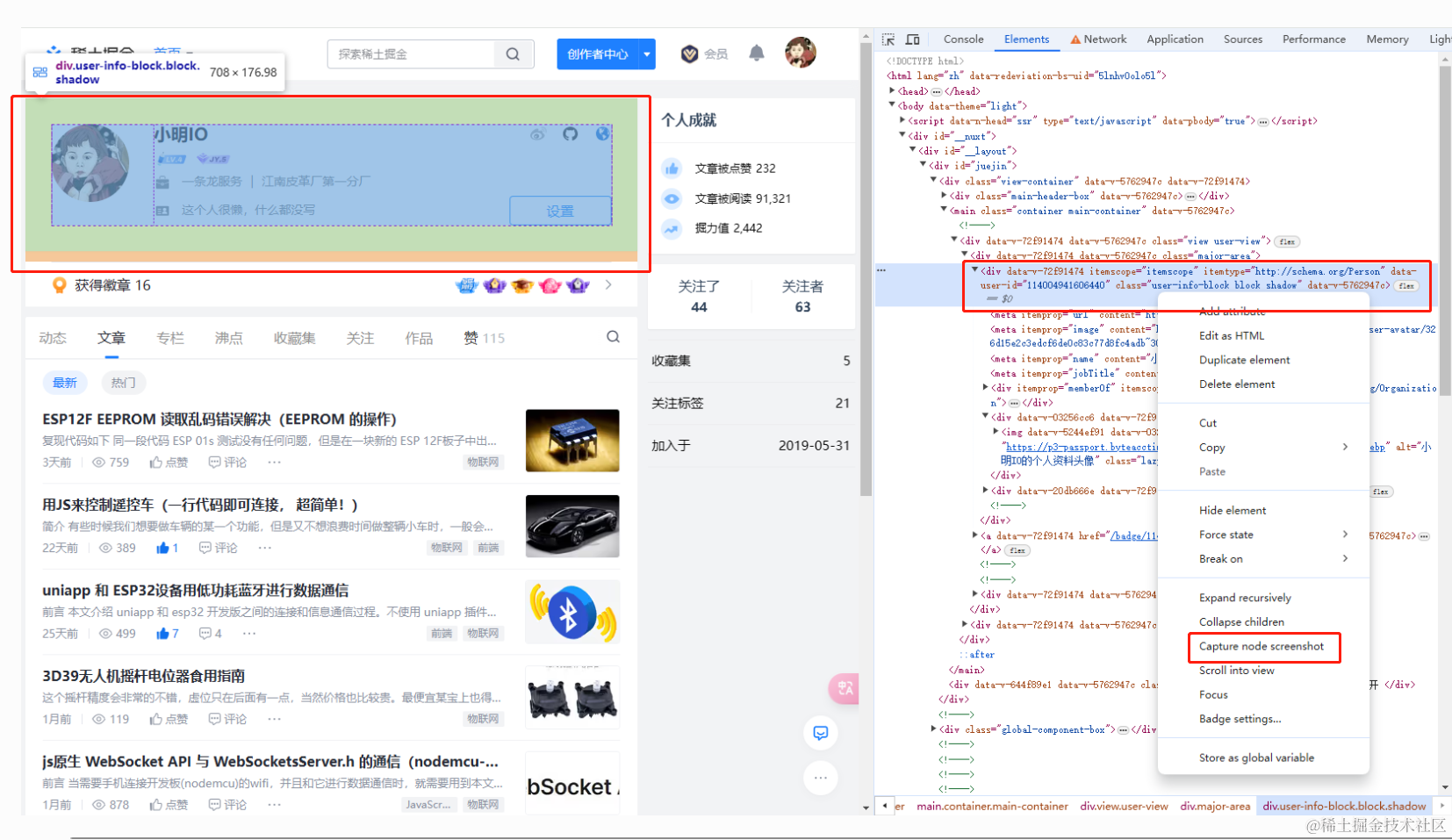
但是非前端人员遇到这个需求该怎么办呢?又或者有一个需求需要不断截图页面的某个区域来进行一些业务操作呢?
那就只能 emo… 了?

不!勇敢牛牛,不怕困难,跟着本文自己来写一个浏览器插件吧!
插件名字叫:web-screenshot
本文会提供插件下载地址,也可以直接下载使用,软件开源免费。
本文涉及的 Chrom 扩展知识点
Service Worker后台运行脚本content.js内容脚本i18n国际化- 使用
storage来存储用户配置 - 各个脚本间的通信
- 页面截图及图片裁剪
Chrome扩展的调试、打包、发布
实现效果 & 功能
功能点
- 任意DOM截图或者任意区域截图
- 可配置复制到黏贴板中的是文件还是
base64
在开始前很有必要先看下最后的实现效果,带着目的去写代码会更简单。
实现效果
这个视频有点大,多等会哦~
开发时环境
Manifest V3 是最新版扩展程序平台,如果你不清楚这是什么,不用管,开发环境中用不到。是相对于以前的扩展程序开发而言的。只是不同版本提供了一些不同的 API。
实现思路
- 拿到用户想要截图的
DOM,或者选取的区域 - 截图整个页面
- 裁剪出来需要的区域(也可以是整个页面)
- 复制图片到用户的剪切板中(可配置要文件流还是base64)或者下载图片
总结下,需要一个简单的配置面板给用户配置复制到粘贴板中的数据是文件流还是base64。
文件流可以直接黏贴到聊天框或者文件夹里面,base64 是字符串,需要转换才能变成图片。
有了思路后就一步一步实现!
前置知识
在开始编码之前很有必要先了解下 Chrome 扩展程序(插件)的开发过程,为了规范,下文中都称为 Chrome 扩展程序,而不是 Chrom 插件。
了解下面四个对象后就可以进行开发啦!
manifest.json一个 Chrome 扩展程序中必须包含的文件,这个文件相当于工程化项目中的package.json,里面描述了该文件所有相关的资源以及各种定义。有兴趣详细研究的点击链接即可。详细文档戳我Service Worker在后台运行并处理浏览器事件,在浏览打开后就开始一直运行。这个脚本里面操作不了DOM,但是在里面可以调用很多 Chrome 提供的 API,也可以和其他脚本进行通信。content_scripts内容脚本在网页环境中运行 JavaScript,可以在这个脚本中操作页面中的DOM,并且可以和 Service Worker 通信。action制扩展程序在 Chrome 工具栏中的图标,就是浏览器右上角扩展图标,可以点击打开一个弹出层或者直接接受一个点击事件。
项目结构
-- web-screenshot [根目录]
-- icons [应用图标]
-- 128.png
-- 48.png
-- 38.png
-- 19.png
-- 16.png
-- setting [设置页面]
-- index.html
-- index.css
-- index.js
-- _locales [国际化]
空,暂时啥都不放~
-- libs [放第三方插件]
空,暂时啥都不放~
-- manifest.json [描述文件]
-- content.js [内容脚本]
-- service-worker.js [Service Worker脚本]
icons 文件夹下放的是不同尺寸的图标,扩展程序会在合适时候使用。
描述文件 manifest.json
第一步当然是把清单列出来,要写什么文件都会记录到这个文件中。
为了更丝滑的理解,我会在下面这段 json 中写注释,复制后请自行删除注释。
{
// 扩展名字
"name": "DOM截图",
"version": "0.1",
// 定死为 3,就是最新版。
"manifest_version": 3,
"description": "给页面中的dom截图~",
"author": "1746809408@qq.com",
// 应用图标,如果不定义,在浏览器中默认是个灰色的
"icons": {
"16": "/icons/16.png",
"19": "/icons/19.png",
"38": "/icons/38.png",
"48": "/icons/48.png",
"128": "/icons/128.png"
},
// 后台进程脚本
"background": {
"service_worker": "service-worker.js"
},
// 配置页面, 配置项很多的话可以单独写到一个页面中
// "options_page": "setting/index.html",
// 浏览器右上角扩展图标和点击后弹出的页面,这里点击不弹出页面, 这里点击要直接截屏而不是打开浮窗,所以不配置页面。
"action": {
// 配置项不多的话直接写到弹出层中使用起来更简单
// 暂时先注释掉,一会再加配置页面
// "default_popup": "./setting/index.html",
"default_icon": {
"16": "/icons/16.png",
"19": "/icons/19.png",
"38": "/icons/38.png",
"48": "/icons/48.png",
"128": "/icons/128.png"
}
},
// 内容脚本,可以直接操作页面 dom
"content_scripts": [
{
"js": [
"content.js"
],
// 在所有网址都执行该脚本
"matches": [
"<all_urls>"
]
}
],
// 快捷键定义
"commands": {
"domScreenshot": {
"description": "dom 截图",
"suggested_key": {
"default": "Alt+Shift+D"
}
},
"areaScreenshot": {
"description": "区域截图",
"suggested_key": {
"default": "Alt+Shift+Q"
}
}
},
// 权限定义
"permissions": [
// 用来存储扩展程序的数据
"storage",
// 用来操作浏览器页面
"activeTab",
// 使用 `chrome.scripting` API 在不同上下文中执行脚本。
"scripting",
// 桌面消息通知
"notifications"
],
// 点击图标后跳转的地址
"homepage_url": "https://github.com/wangzongming/screenshot-dom"
}
调试扩展程序
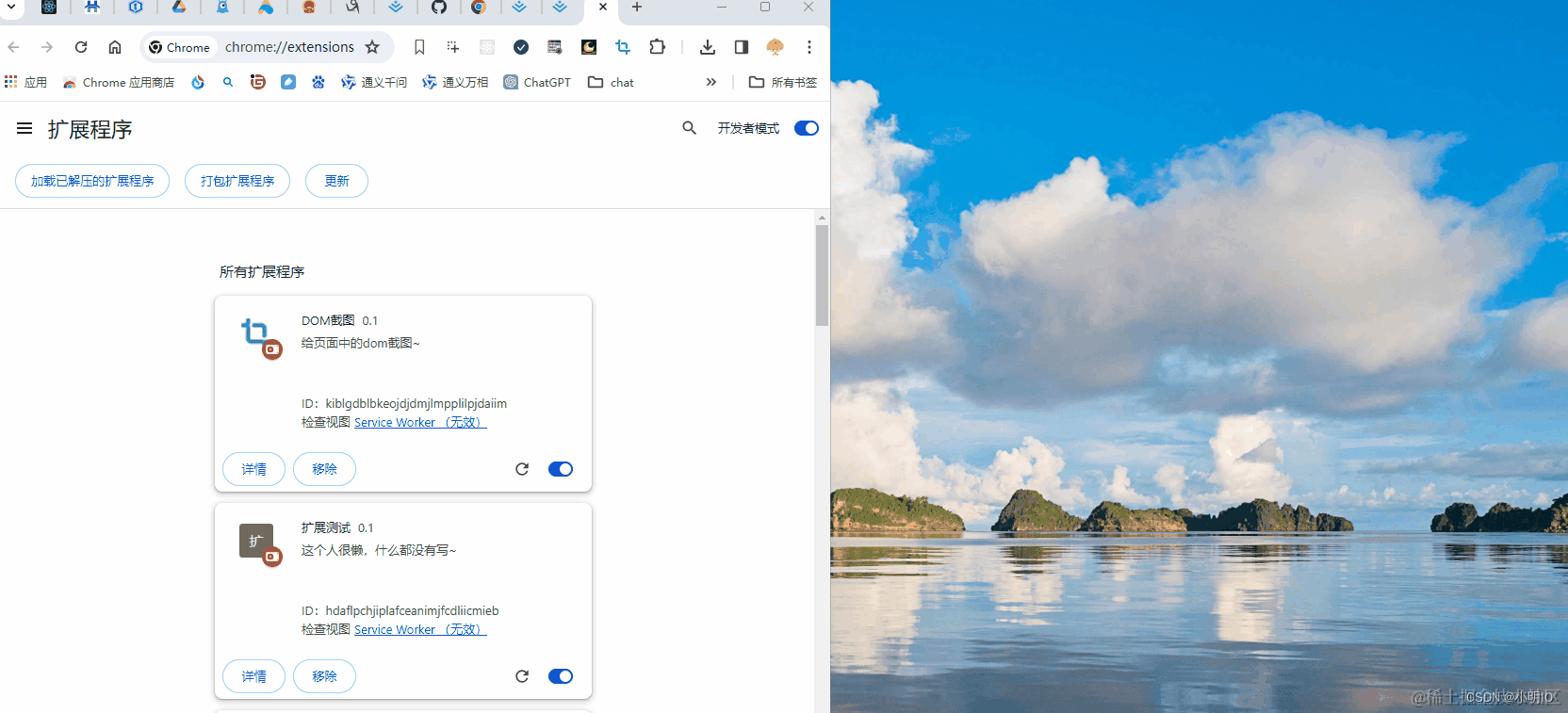
有了 manifest.json 文件后就可以直接安装扩展进行调试了,虽然其他文件还没写,但是不影响导入浏览器了。
- 打开网址 chrome://extensions/
- 页面右上角打开开发者模式
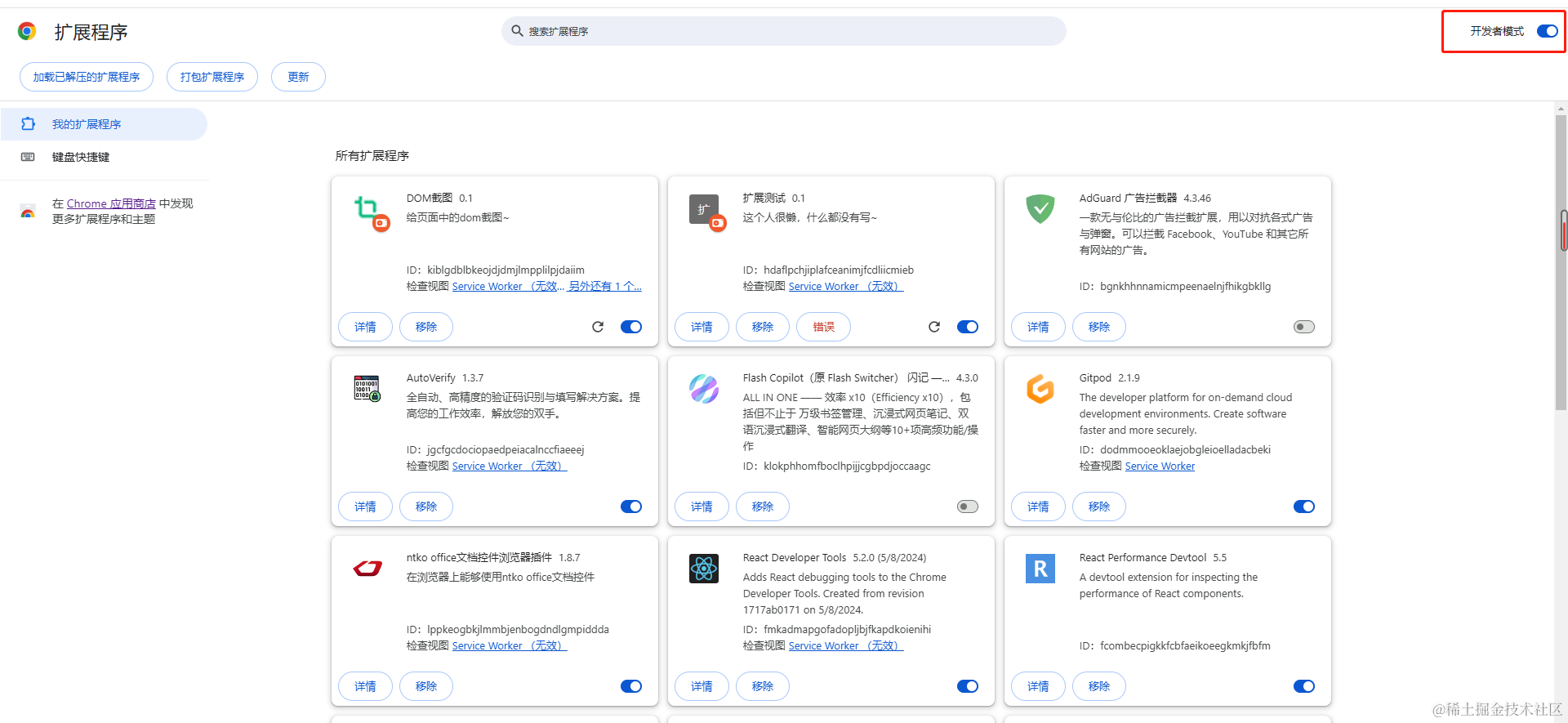
- 导入扩展程序
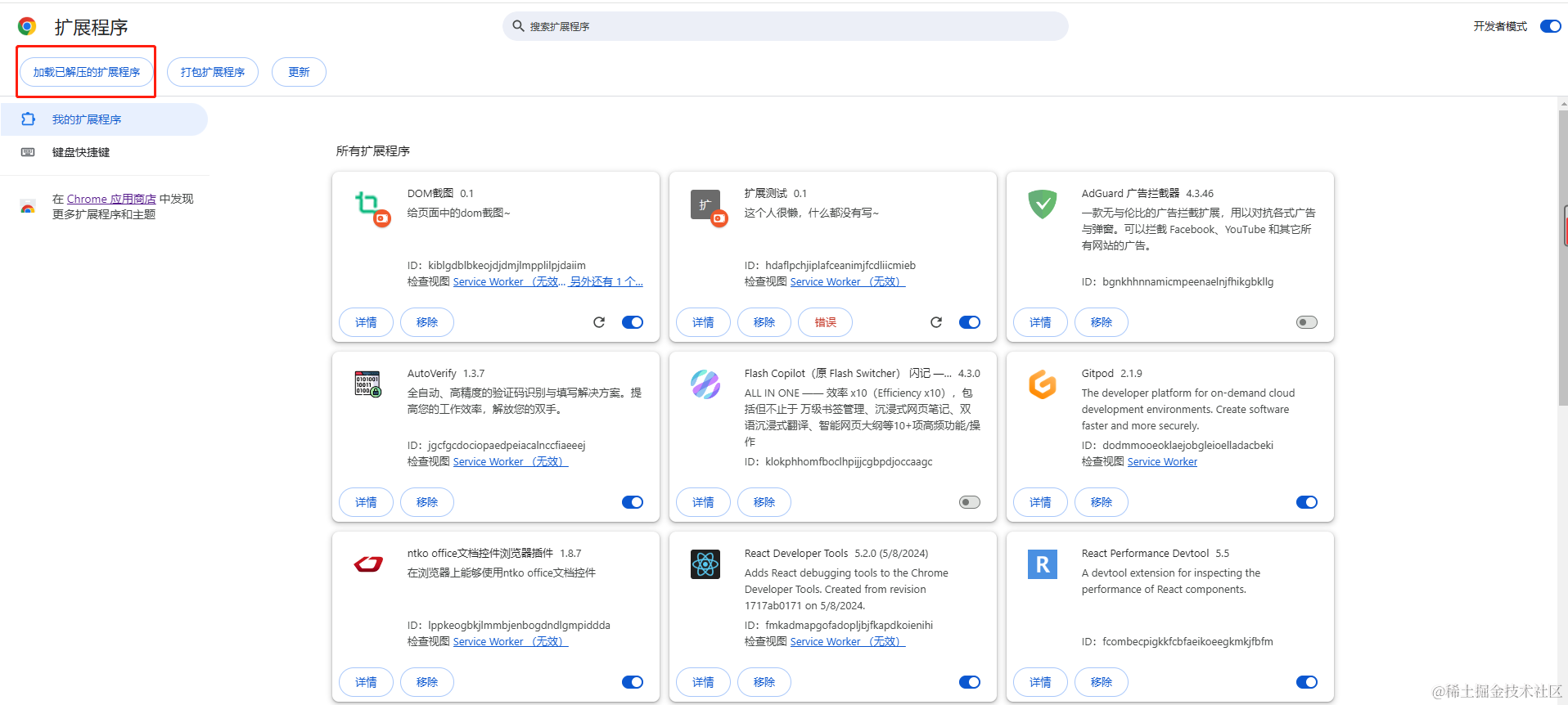
导入成功后
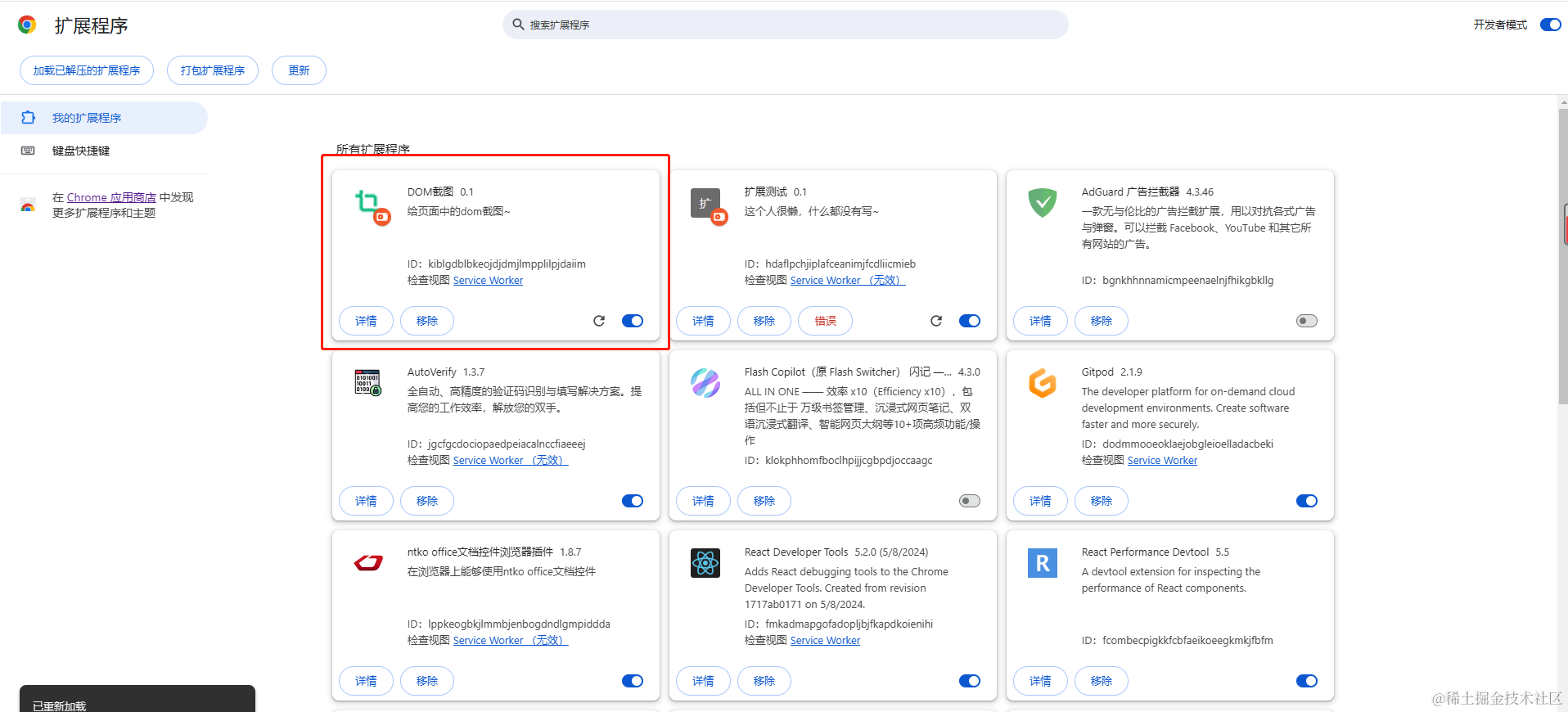
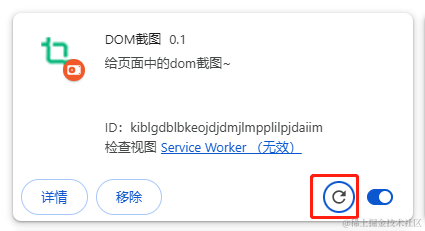
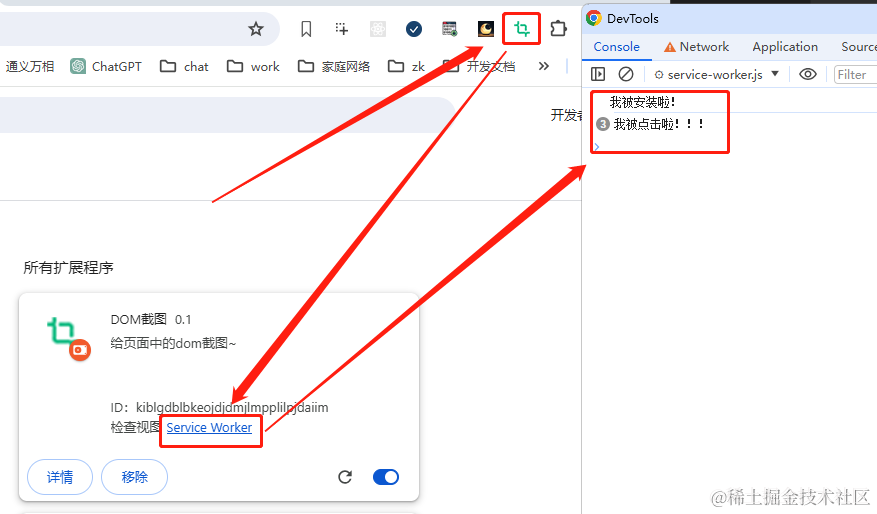
扩展程序导入后,如果本地代码改了,需要点这个按钮进行刷新,每次改代码都需要刷新看效果。
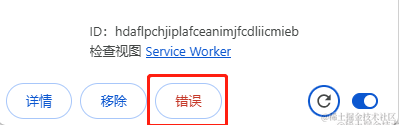
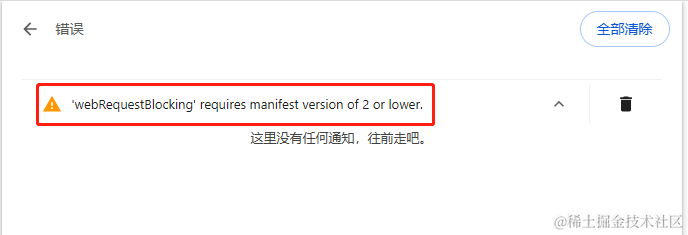
可以看到遇到错误后也会提示出来,截图上面的提示是因为那个文件还是空的。如果遇到文件内有错误,在 移除 按钮的右边还会有一个错误按钮,点击就可以看到错误列表。
- 将扩展固定
如果不固定的话每次找都要打开面板,比较麻烦,按下方步骤固定即可。
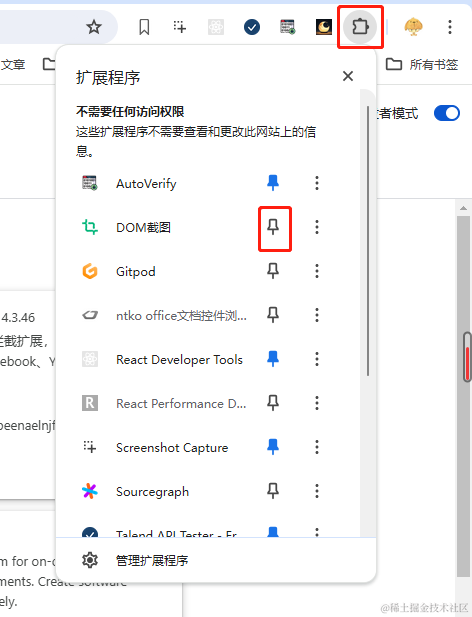
固定后就不用每次打开下拉面板了。
注意:内容脚本,在本文中也就是content.js,当它更改后不但要刷新扩展程序,网页也需要重新刷新下才会生效。
后台脚本 service-worker.js
这个脚本中能调用全部的 Chrome 提供的 API, 所以先这里监听右上角图标被点击的事件。
写入代码,然后点击一下扩展的刷新按钮。
chrome.runtime.onInstalled.addListener(() => {
console.log("我被安装啦!")
});
chrome.action.onClicked.addListener((tab) => {
console.log("我被点击啦!!!")
})
调试方法
点击截图中绿色文字能打开 service-worker.js 的控制台。
页面截图功能
接下来先实现对整个页面的截图。改下点击监听代码。
chrome.action.onClicked.addListener((tab) => {
console.log("截图")
chrome.tabs.query({ active: true, currentWindow: true }, (tab) => {
// 详细文档:https://developer.chrome.com/docs/extensions/reference/api/tabs?hl=zh-cn#method-captureVisibleTab
chrome.tabs.captureVisibleTab(tab.windowId, { format: "png", quality: 100 }, (image) => {
// 会返回 base64 图片
console.log("image:", image)
})
})
})
代码中先用 chrome.tabs.query查询到当前 tab 页面,拿到页面 id 然后调用 chrome.tabs.captureVisibleTab 来对整个页面进行截图,后文对某个 DOM 和某个区域的截图也会用这个实现。
来看下效果
然后把控制台中 base64 字符串复制后直接放到浏览器网址上打开,看到没有?是不是和刚刚的页面一模一样,连滚动条都是如此的逼真~
总结
既然已经实现了整页截屏了,那就来考虑对某个 DOM 截屏。
首先要让用户点击图标后能够选择某个DOM,而不是直接截屏。所以这里我们要让页面配合我们。
拿到 DOM 后再分析出 DOM 的坐标和尺寸信息,然后对图片进行裁剪就完成啦!
与内容脚本间的通信
既然说到页面那就是内容脚本的任务了,没错也就是 content.js。
现在来在改下代码,把截图代码先注释下,然后改为通知content.js打开DOM选择模式,就模仿控制台的选择元素功能。
我们将 service-worker.js 代码改一下
chrome.runtime.onInstalled.addListener(() => {
console.log("我被安装啦!")
});
chrome.action.onClicked.addListener(async (tab) => {
// const res = await chrome.runtime.sendMessage({ type: 'select-dom' });
// console.log("选择的 dom 信息: ", res)
chrome.tabs.query({ active: true, currentWindow: true }, function (tabs) {
chrome.tabs.sendMessage(tabs[0].id, { type: 'select-dom' }, function(res){
console.log("选择的 dom 信息: ", res)
});
});
// chrome.tabs.query({ active: true, currentWindow: true }, (tab) => {
// // 详细文档:https://developer.chrome.com/docs/extensions/reference/api/tabs?hl=zh-cn#method-captureVisibleTab
// chrome.tabs.captureVisibleTab(tab.windowId, { format: "png", quality: 100 }, (image) => {
// // 会返回 base64 图片
// console.log("image:", image)
// })
// })
})
再来写一下 content.js。
这个文件本来应该写到下个章节的,但是剧情需要所以这里先打个样。
/**
* 监听 service-worker.js 发来的消息
*/
chrome.runtime.onMessage.addListener((req, sender, res) => {
if (req.type === 'select-dom') {
// 返回出去 dom 的坐标和尺寸信息
res({ x: 0, y: 0, h: 0, w: 0 })
}
// 这里要返回 true 不然接收端收不到信息
return true;
})
注意,这时候点击这个扩展按钮时需要到正常的网页上面去点击,因为扩展管理页面运行内容脚本会报错。
成功后如下图:
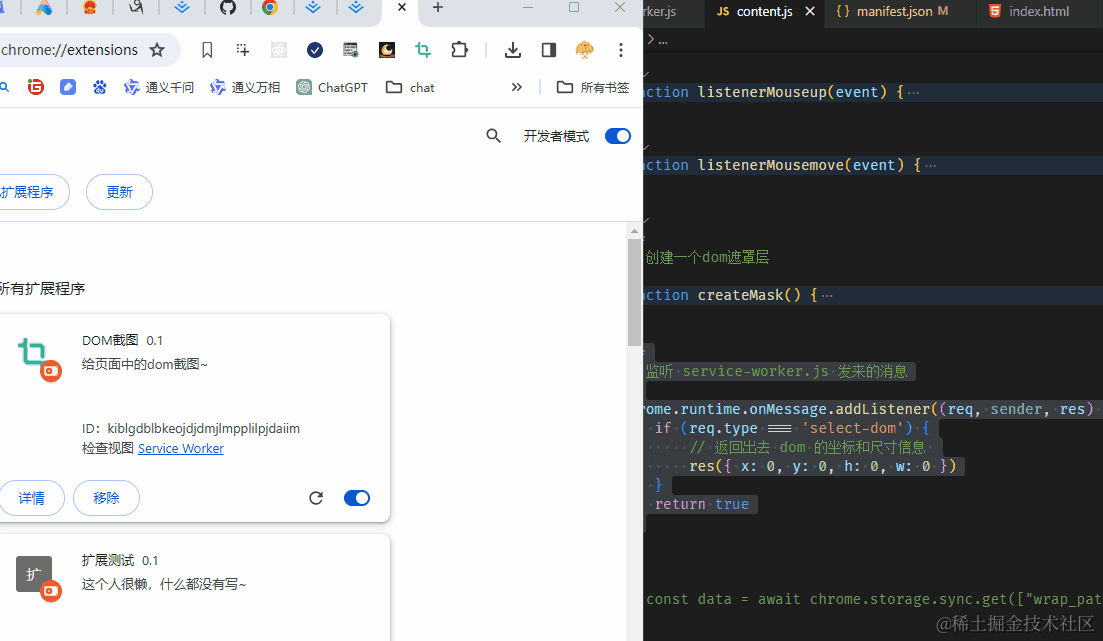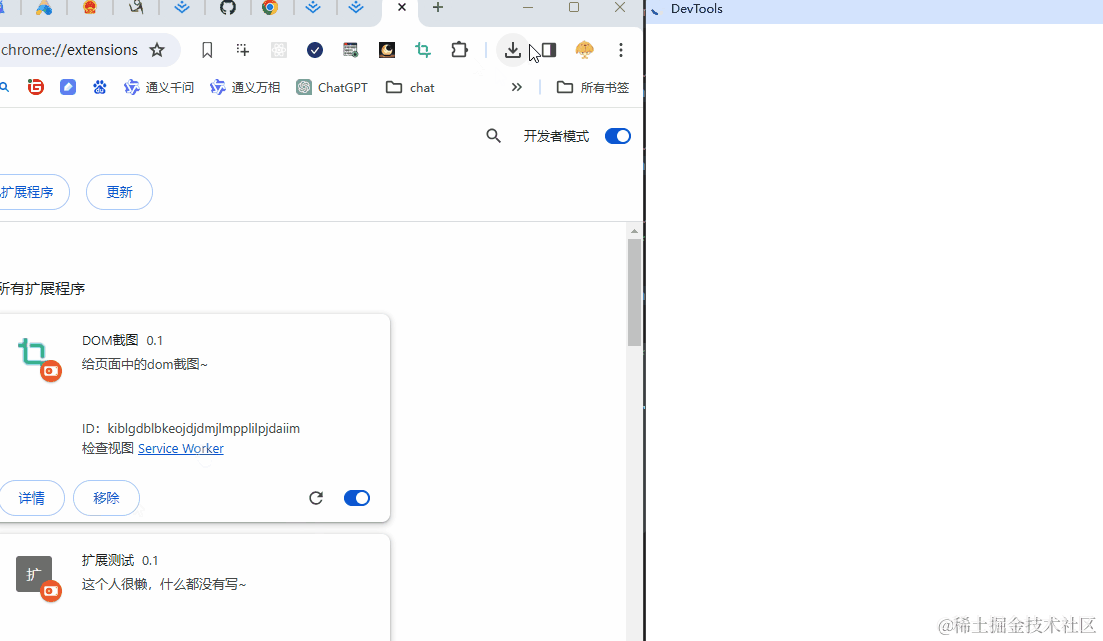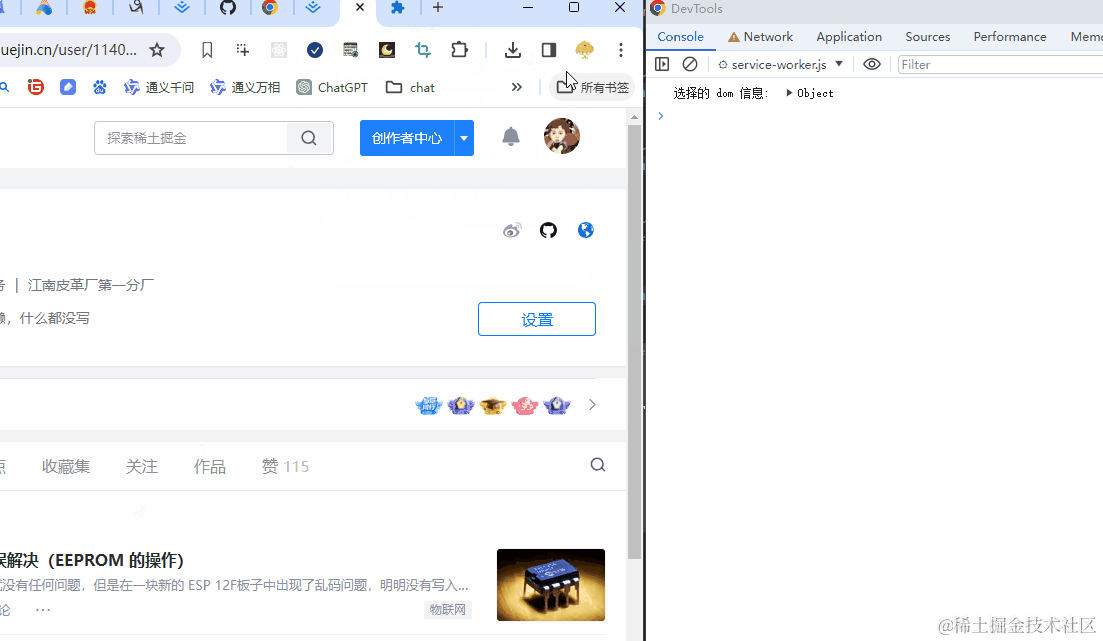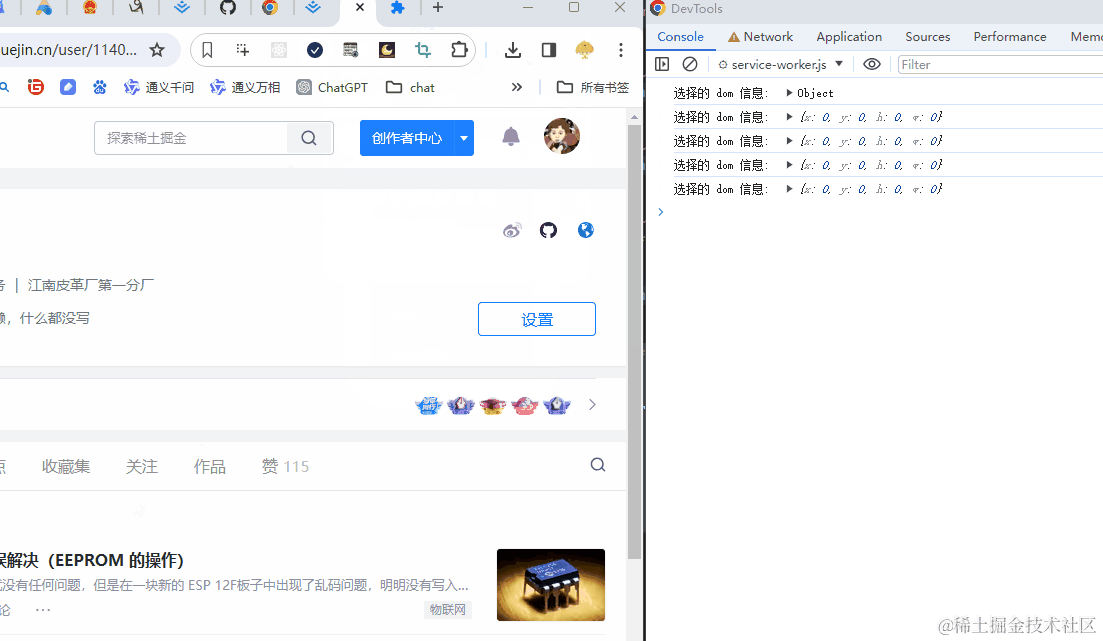
题外话
如果想要从 content.js 向 service-worker.js 发送消息只需要这么写即可:
const res = await chrome.runtime.sendMessage({
message: 'capture', format: "png", quality: 100
});
console.log(res); // { message: 'hello-res' }
chrome.runtime.onMessage.addListener((req, sender, res) => {
if (req.message === 'hello') {
res({ message: 'hello-res' })
}
// 这里要返回 true 不然接收端收不到信息
return true;
})
向 service-worker 通信会更加简单,因为每个页面都会运行内容脚本也就是content.js, 所以要选择一个标签页面进行通信,而 service-worker 只会运行一个。
国际化 i18n
扩展程序提供了国际化支持,所以在写下面的配置界面前,先来配置下国际化。
插件根目录新建一个名为_locales的文件夹,再在下面新建一些语言的文件夹,如en、zh_CN、zh_TW,然后再在每个文件夹放入一个messages.json,同时必须在清单文件中设置default_locale。
目录结构图示
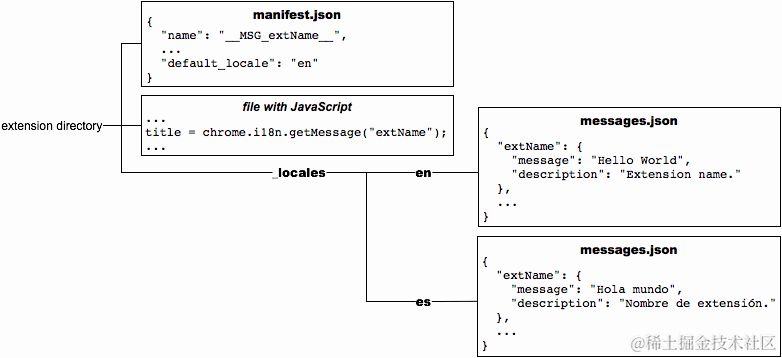
使用案例
从图中可以看出来
-
在
manifest.json和CSS文件中,用 MSG_xxx 的字符串就可以获取到messages.json中定义的文本。 -
在
JavaScript代码中,需要调用方法chrome.i18n.getMessage("xxx")来获取文本。 -
在
html中只能这么写(非常的不nice🧐):
var message = chrome.i18n.getMessage("xxx");
document.getElementById("languageSpan").innerHTML = message;
占位符(变量)
当一个文本用运用于多个地方时,并且只有某几个词不一样时,就可以在message中增加占位符。
placeholders 用来描述每一个占位符在第几个位置(content) 从1开始数,example 只是一个案例,和description 一样。
定义一个占位符:
在某个 js 文件中引用:
// const text = chrome.i18n.getMessage("test", ["小明", "小丽"]); // 多个的情况
const text = chrome.i18n.getMessage("test", "小明");
console.log('text', text)
效果
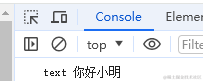
实际使用
接下来将 manifest.json 中的文字描述都更改下, 也同时配置项国际化相关配置
{
"name": "__MSG_pluginName__",
"description": "__MSG_pluginDesc__",
"default_locale": "zh_CN",
"commands": {
"dom-screenshot": {
"description": "__MSG_domScreenshotDesc__",
"suggested_key": {
"default": "Alt+Shift+D"
}
},
"area-screenshot": {
"description": "__MSG_areaScreenshotDesc__",
"suggested_key": {
"default": "Alt+Shift+Q"
}
}
},
...
}
上面引用了四个占位符,现在去定义下。这里我们只考虑简体中文和英文两种语言。
- 创建文件
_locales\zh_CN\messages.json和_locales\en\messages.json - 编写
_locales\zh_CN\messages.json
- 编写
_locales\en\messages.json
- 切换浏览器语言测试下,这里直接用最朴素的方式切换语言。
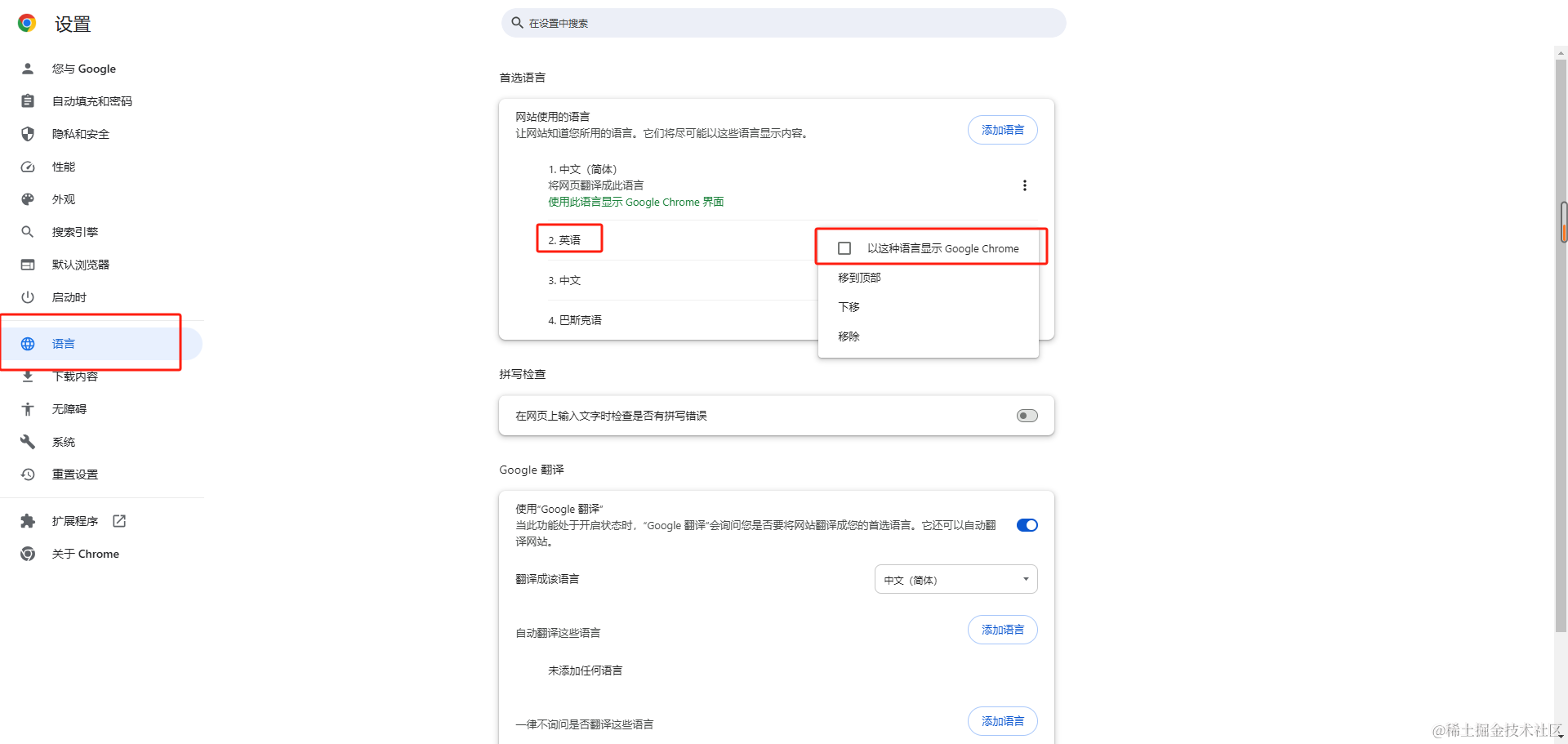
中文语言下显示内容:
英文语言下显示内容:
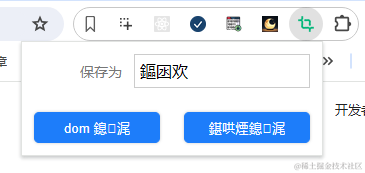
工具栏操作 action
直接利用工具栏图标提供的弹出层来配置我们的扩展程序。我们先来配置两个按钮,用来区分用户想使用哪种截图:DOM截图或者任意区域截图。
前面都是直接点击扩展图标就进行截图,所以这里要改一下,让点击图标时候弹出一个浮窗,浮窗中有两个按钮DOM截图 和 区域截图
manifest.json 修改
增加弹出页面路径配置
{
...
"action": {
"default_popup": "./setting/index.html",
...
},
...
}
html 文件编写
setting/index.html
<html lang="en">
<head>
<title></title>
<link rel="stylesheet" href="./index.css">
</head>
<body>
<div class="content">
<div class="form-item">
<label for="model" id="model-label"></label>
<select id="model">
<option value="file" id="model-option-file"></option>
<option value="base64" id="model-option-base64">base64</option>
</select>
</div>
<div class="btns">
<button id="dom-screenshot"></button>
<button id="area-screenshot"></button>
</div>
</div>
<script src="./index.js"></script>
</body>
</html>
如果直接在 html 写中文,最后渲染出来的是乱码哦~,要解决的话只能将 html 文件改为 UTF-16 LE 才行。但是直接用 i18n 方式就能避免这个问题。所以上面代码中没有任何中文。截图中的 另存为 使用 i18n 方式。
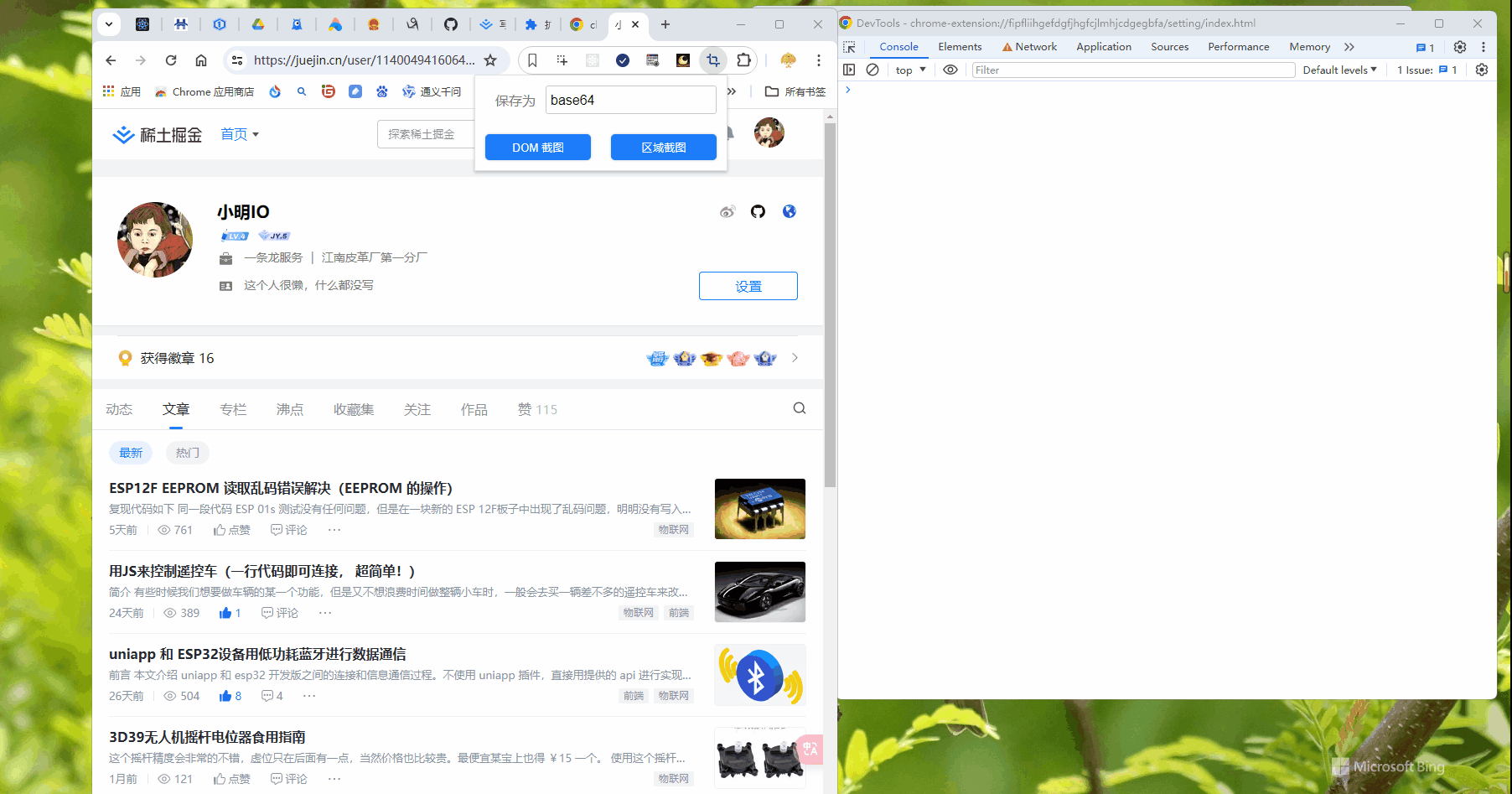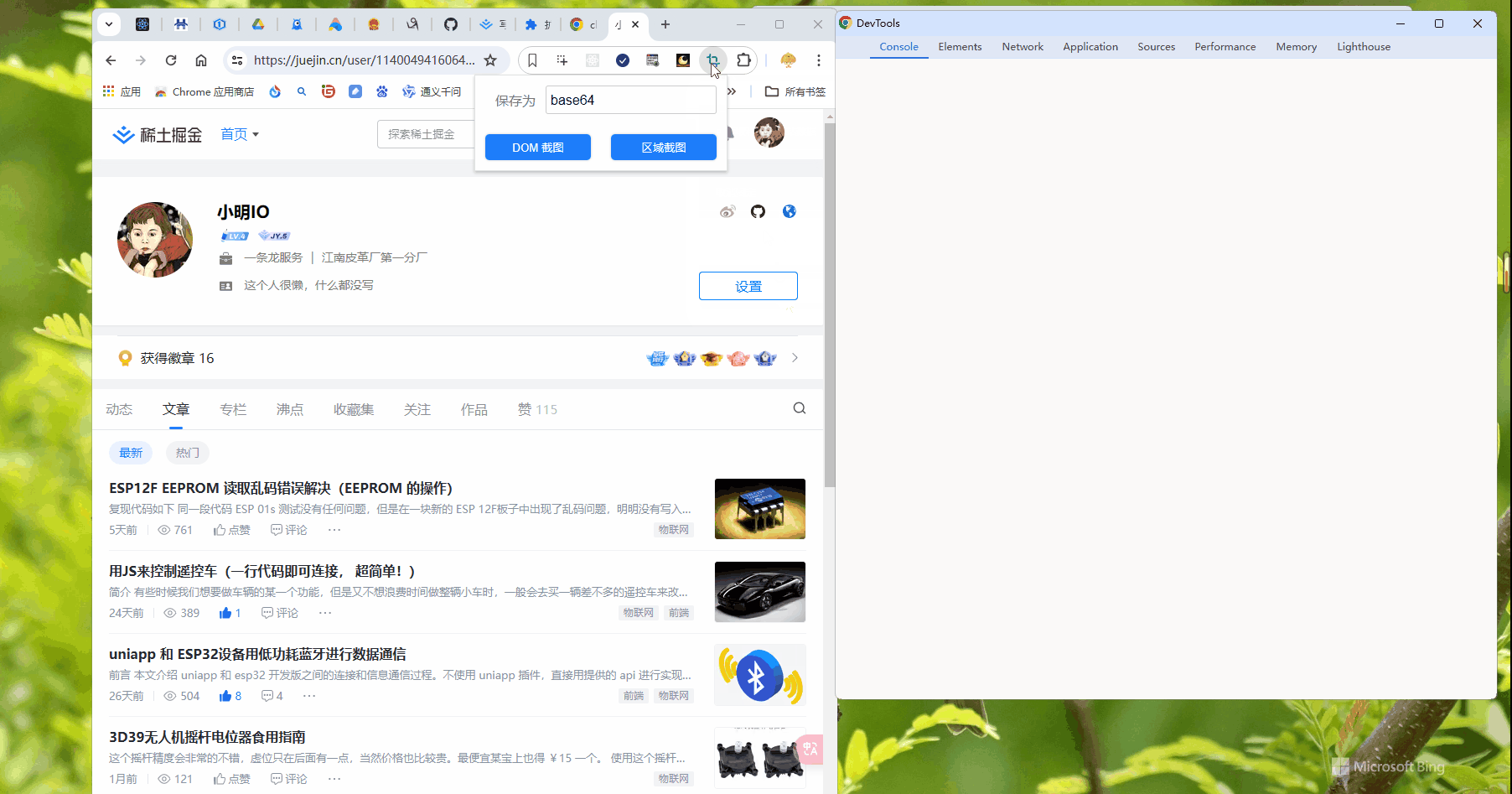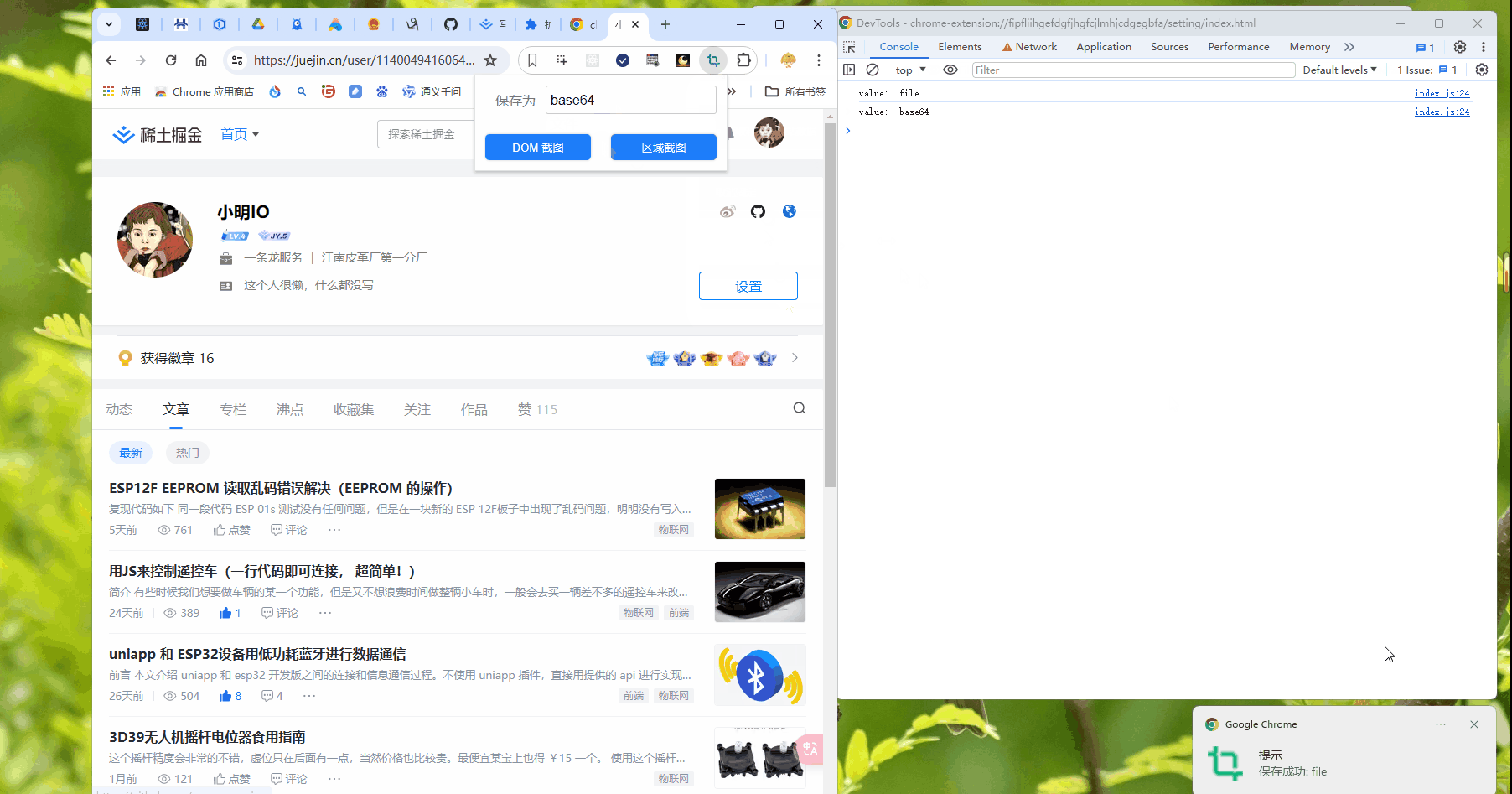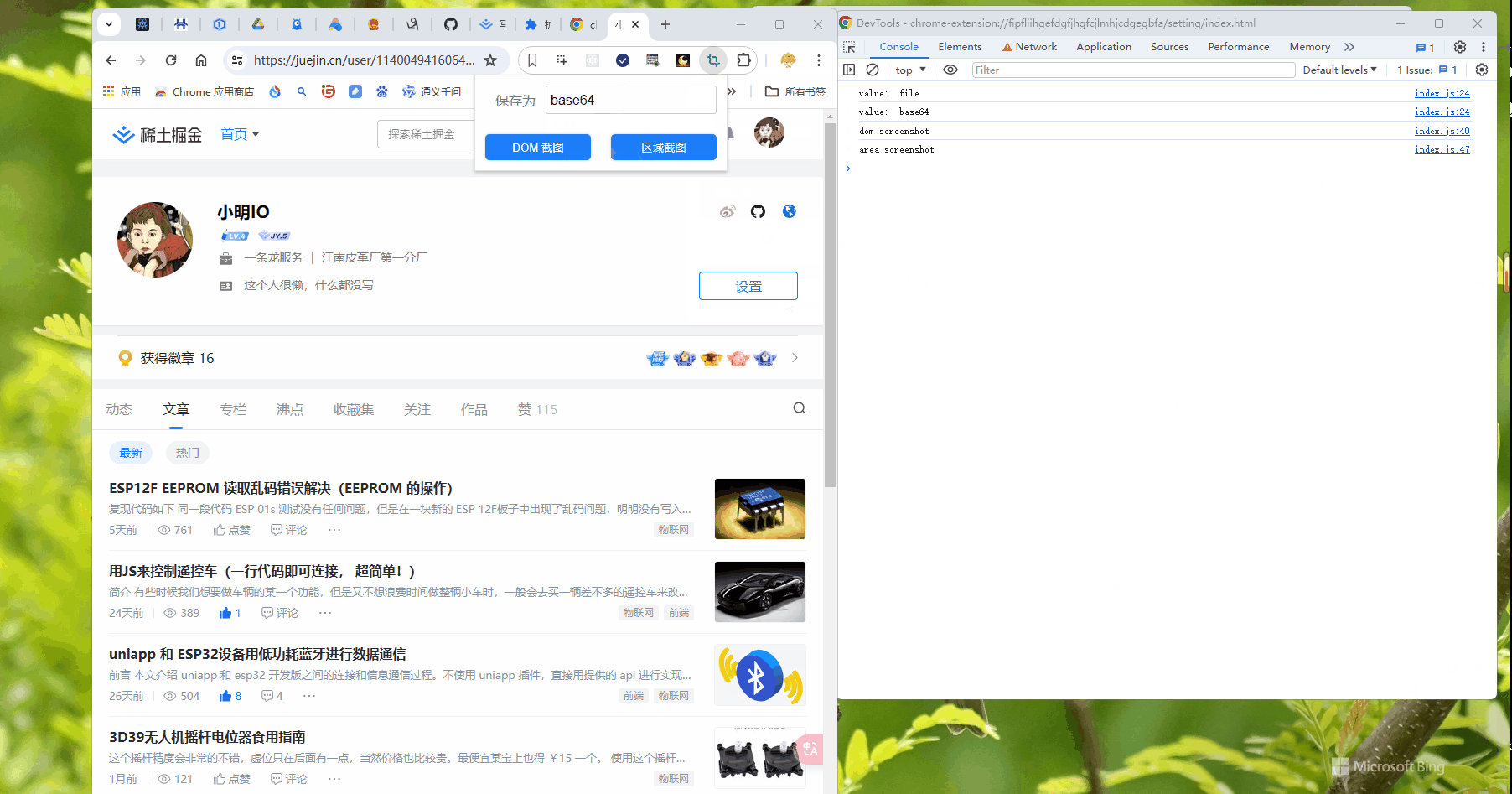
js 文件编写
setting/index.js
window.onload = function () {
main();
}
async function main() {
const dom_screenshot = document.getElementById('dom-screenshot');
const area_screenshot = document.getElementById('area-screenshot');
// 界面文字设置
document.getElementById('model-label').innerText = chrome.i18n.getMessage('modelLabel');
document.getElementById('model-option-file').innerText = chrome.i18n.getMessage('modelOptionFile');
dom_screenshot.innerText = chrome.i18n.getMessage('domScreenshotDesc');
area_screenshot.innerText = chrome.i18n.getMessage('areaScreenshotDesc');
// 存储用户设置和回显设置逻辑
const model_input = document.getElementById('model');
// 回显设置过的数据
const storage_data = await chrome.storage.sync.get(["model"]);
model_input.value = storage_data.model || "file";
// 保存设置
model_input.addEventListener('change', async (event) => {
const value = event.target.value;
console.log("value: ", value)
// 将设置存入本地
await chrome.storage.sync.set({ model: value });
// 弹出通知
chrome.notifications.create(null, {
type: 'basic',
iconUrl: '../icons/48.png',
title: chrome.i18n.getMessage('msgTitle') ,
message:chrome.i18n.getMessage('saveSuccessMsg') + `: ${value}` ,
})
});
// dom 截图
dom_screenshot.addEventListener('click', () => {
console.log("dom screenshot")
// 关闭面板
// window.close();
});
// 区域截图
area_screenshot.addEventListener('click', () => {
console.log("area screenshot")
// 关闭面板
// window.close();
});
}
storage.sync 非常的有用,浏览器同步功能已启用,数据会同步到用户登录的任何 Chrome 浏览器。如果停用,其行为类似于 storage.local。
当浏览器离线时,Chrome 会将数据存储在本地,并在浏览器恢复在线状态后恢复同步。配额限制大约为 100 KB,每项内容 8 KB。
代码中的 window.close(); 是注释掉的,因为关闭面板就看不到日志了。
css 文件编写
setting/index.css
body {
width: 300px;
font-family: 苹方, 黑体;
font-size: 14px;
color: #777;
margin: 0px;
}
.content {
padding: 12px;
box-sizing: border-box;
}
.form-item {
display: flex;
justify-content: space-between;
align-items: center;
padding-bottom: 12px;
}
.form-item>label{
text-align: right;
width: 60px;
padding-right: 12px;
font-size: 16px;
}
.form-item>select,
.form-item>select>option {
background: transparent;
flex: 1;
padding: 5px;
font-size: 16px;
border: 1px solid #ccc;
height: 34px;
-webkit-appearance: none;
outline: none;
border-radius: 3px;
}
.btns {
padding-top: 12px;
display: flex;
justify-content: space-between;
}
.btns button {
border: 1px solid #1d7dfa;
background: #1d7dfa;
color: #fff;
box-shadow: 0px 0px 3px #ccc;
padding: 6px 12px;
border-radius: 5px;
cursor: pointer;
width: calc(50% - 12px);
transition: 0.3s;
}
.btns button:hover {
box-shadow: 2px 2px 5px #9e9d9d;
transition: 0.3s;
}
文件样式就没啥好说的了,懂的都懂~
效果
内容脚本 content.js
内容脚本中能访问的底层 api 很少,主要是用来操作页面 DOM 的。但是可以和 service_worker 通信,所以在这个脚本入如果要调用某个 chrome 扩展 api 那就用通信告诉 service_worker, service_worker 处理完再告诉 content.js 即可。
需要特别注意: 浏览器会选择一个时间,在“document_end”之间以及 window.onload 事件触发后立即注入脚本。注入的确切时刻取决于文档的复杂程度和加载用时,并针对网页加载速度进行了优化。在“document_idle”运行的内容脚本不需要监听 window.onload 事件;它们一定会在 DOM 完成后运行。如果脚本确实需要在 window.onload 之后运行,该扩展程序可以使用 document.readyState 属性检查 onload 是否已触发。
如果想要在其他的时机执行内容脚本,那自行参照详细文档中的 RunAt 章节。
实现 DOM 截图
思路
- 用户点击 DOM 截图 按钮后,
- 让用户选择页面中的一个
DOM元素, - 然后拿到
DOM坐标和尺寸信息 - 对整个页面进行截屏
- 根据
DOM信息对原始页面截屏进行裁剪。
实现选择 DOM 功能
弹出层代码实现
对 setting/index.js 文件进行修改,监听到用户点击 DOM 截图 按钮时通知 content.js 来提供一个选择 DOM 的功能。
...
// dom 截图
dom_screenshot.addEventListener('click', () => {
chrome.tabs.query({ active: true, currentWindow: true }, function (tabs) {
// 通知 content.js 提供选择 dom 的功能
chrome.tabs.sendMessage(tabs[0].id, { type: 'select-dom' });
});
// 关闭面板
window.close();
});
...
内容脚本代码实现
content.js 文件中的内容写入如下代码,其实就是在页面中创建一个隐藏的 dom, 然后鼠标移入被聚焦的dom时,获取该dom信息。然后给到隐藏的那个dom,然后显示出来,就出现了一个选择 dom 的效果。
需要注意的是点击事件在代码中自行实现了一个,没有用 click 因为有些元素一旦阻止了冒泡可能就点击不到想要的dom了。
还有另一个知识点就是对pointerEvents的运用,因为点击页面的 a 标签等情况时,会跳转页面,我们只是想要截图,不能要点击事件。但是也不能直接把元素事件去除了,因为 mousemove 还得获取元素信息。所以按下鼠标时直接禁用该dom的指针事件,因为按鼠标时候已经获取完该元素的信息了。
// 聚焦 dom 的遮罩
var maskDom = createMask();
// 是否为选择模式,可以使用鼠标指针选择字段进行编辑,由平台程序改变
var isSelectModel = false;
// 鼠标是否按下状态
var isMousedown = false;
var target = null;
// 为防止页面上面有禁止冒泡的元素。所以使用 mouse 实现点击监听
window.globalClickMouseDowned = null;
window.globalClickDownTime = null;
/** 各类鼠标事件监听 **/
document.addEventListener("mousedown", listenerMousedown);
document.addEventListener("mouseup", listenerMouseup);
document.addEventListener("mousemove", listenerMousemove);
function listenerMousedown(event) {
if (!isSelectModel) return;
target.style.pointerEvents = "none";
isMousedown = true;
if (event.which === 1) {
window.globalClickMouseDowned = true;
window.globalClickDownTime = new Date().getTime();
}
};
function listenerMouseup(event) {
if (!isSelectModel) return;
isMousedown = false;
target.style.pointerEvents = "auto";
// 点击某个 dom
if (window.globalClickMouseDowned && event.which === 1) {
window.globalClickMouseDowned = false;
const now = new Date().getTime();
if (now - window.globalClickDownTime < 300) {
const infos = {
x: parseInt(maskDom.style.left),
y: parseInt(maskDom.style.top),
w: parseInt(maskDom.style.width),
h: parseInt(maskDom.style.height)
};
console.log('dom infos: ', infos)
isSelectModel = false;
maskDom.style.display = "none";
}
}
};
function listenerMousemove(event) {
if (!isSelectModel) return;
/**
* 鼠标移入时的高亮处理
*/
if (!isMousedown) {
// 拿到鼠标移入的元素集合
const paths = document.elementsFromPoint(event.x, event.y);
// 这里取第一个就行
target = paths[0];
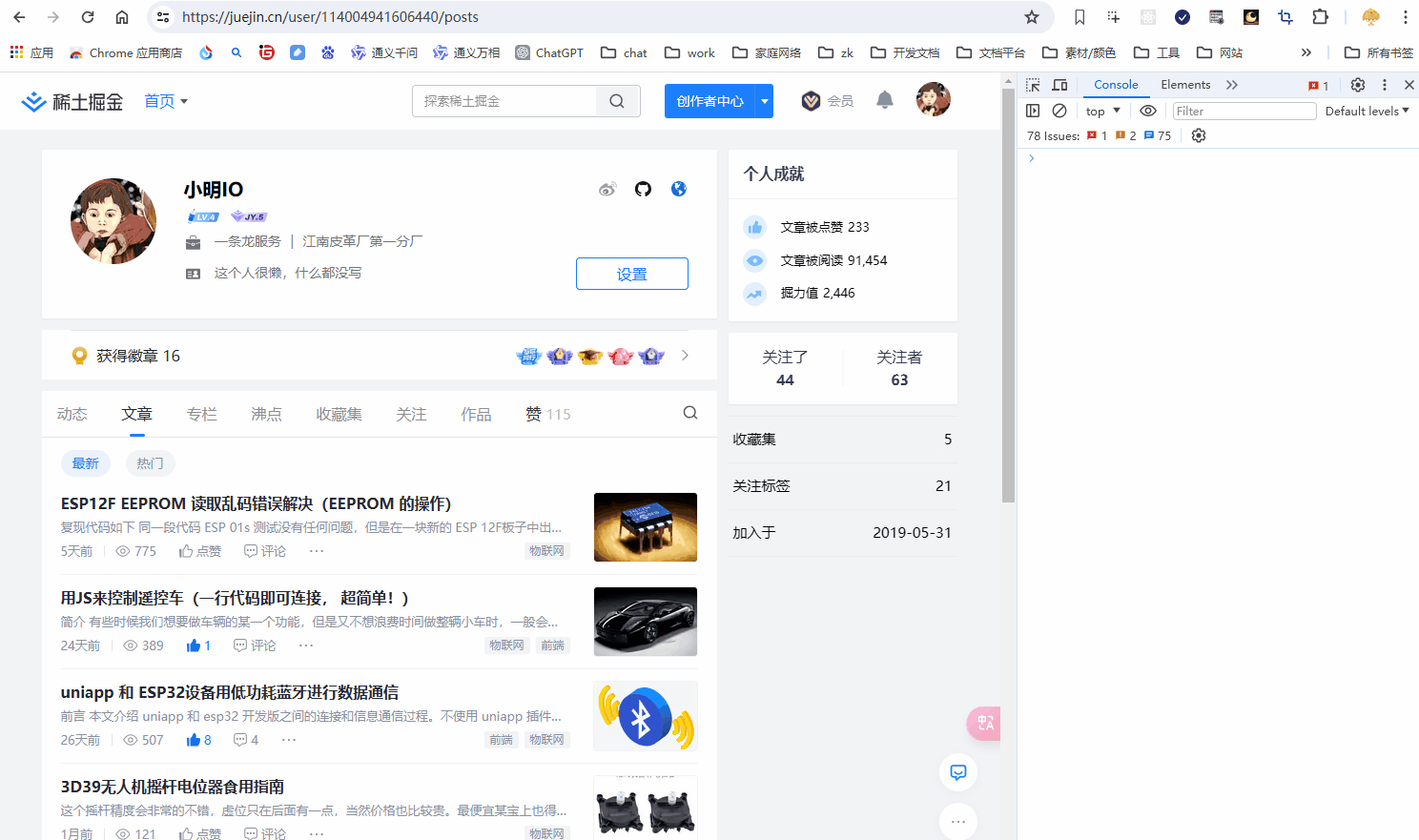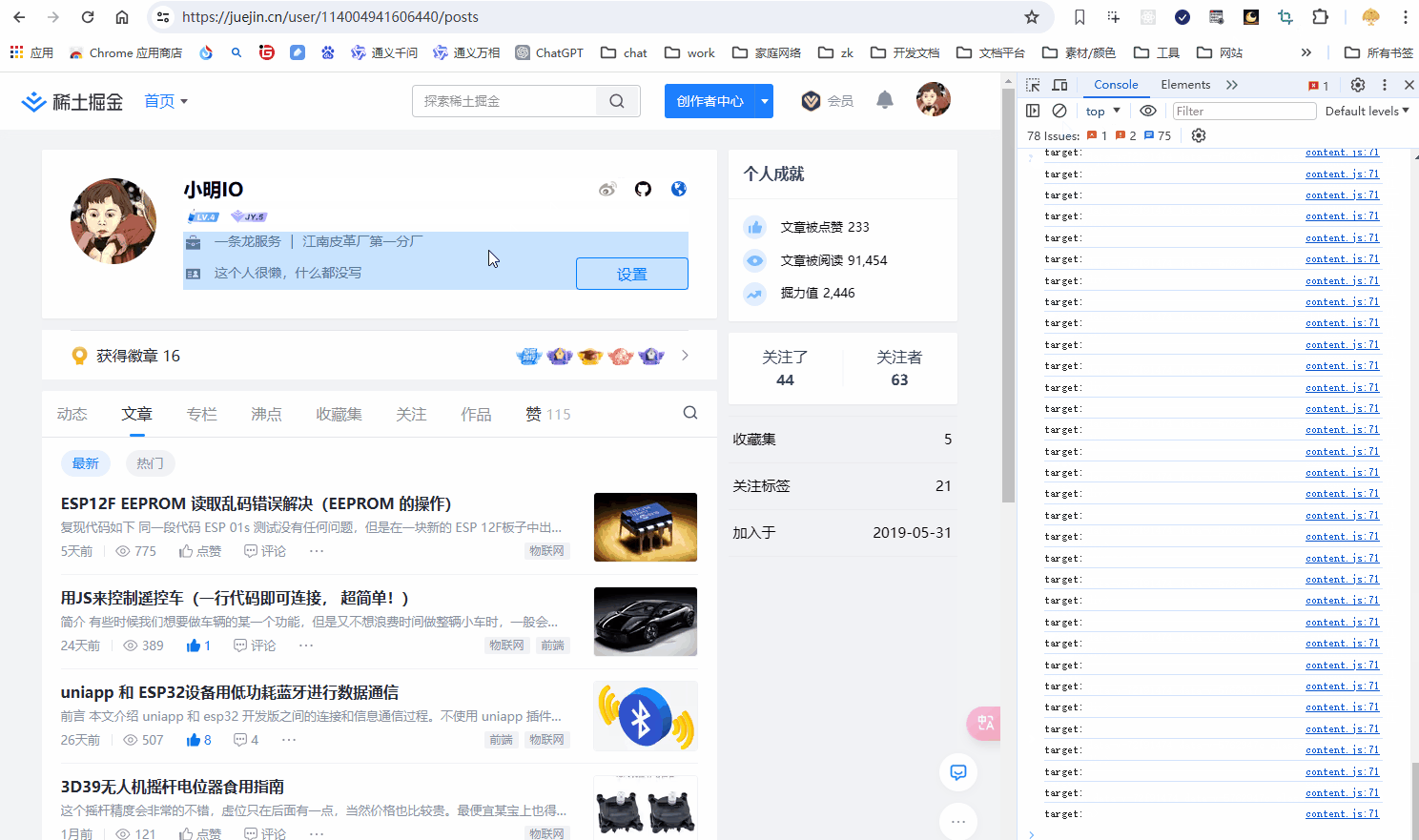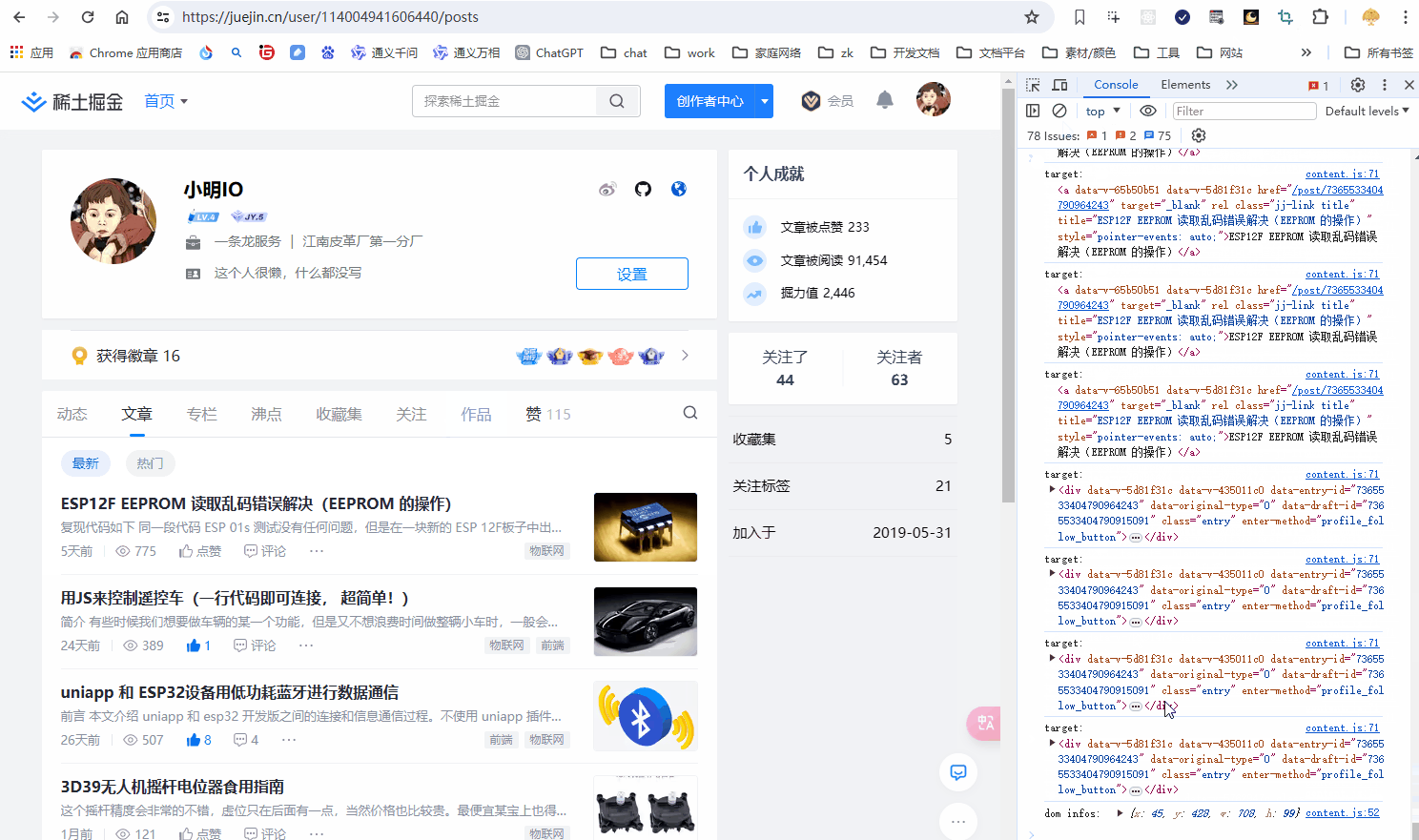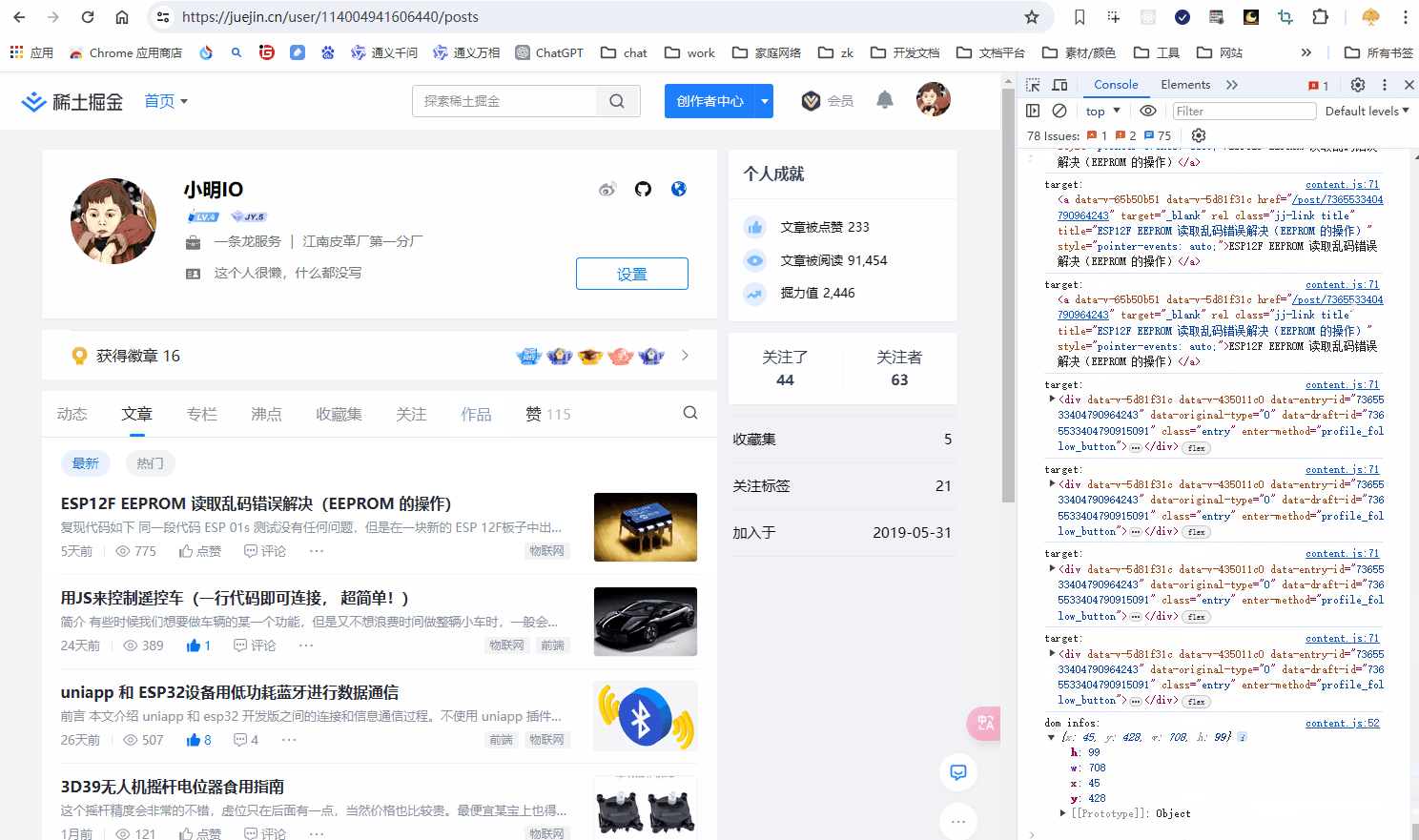
console.log("target:", target);
if (target) {
// 拿到元素的坐标信息
const targetDomInfo = target.getBoundingClientRect();
const h = targetDomInfo.height, w = targetDomInfo.width,
l = targetDomInfo.left, t = targetDomInfo.top;
maskDom.style.width = w + "px";
maskDom.style.height = h + "px";
maskDom.style.left = l + "px";
maskDom.style.top = t + "px";
maskDom.style.display = "block";
} else {
maskDom.style.display = "none";
}
}
};
/**
* 创建一个dom遮罩层
*/
function createMask() {
const mask = document.createElement("div");
// 必须让鼠标指针能够穿透 mask 元素
mask.style.pointerEvents = "none";
mask.style.background = "rgb(3, 132, 253, 0.22)";
mask.style.position = "fixed";
mask.style.zIndex = 9999999999999;
mask.style.display = "none";
document.body.appendChild(mask);
return mask;
}
/**
* 监听 service-worker.js 发来的消息
*/
chrome.runtime.onMessage.addListener((req, sender, res) => {
if (req.type === 'select-dom') {
// 开启选择dom功能
isSelectModel = true;
}
return true
})
DOM 选择效果
实现截屏功能
先来改下 content.js 中的 listenerMouseup 函数逻辑, 拿到 DOM 信息后再向 service-worker.js索要当前页面的截图。
再增加一个 crop 函数,用 canvas 来剪裁图片,context.drawImage 的几个参数可以来温习下:
- img 规定要使用的图片。
- sx(可选)开始剪切的 x 坐标位置。
- sy(可选)开始剪切的 y 坐标位置。
- swidth(可选)被剪切图像的宽度。
- sheight(可选)被剪切图像的高度。
- x 在画布上放置图像的 x 坐标位置。
- y 在画布上放置图像的 y 坐标位置。
- width(可选)要使用的图像的宽度。(伸展或缩小图像)
- height (可选)要使用的图像的高度。(伸展或缩小图像)
剪裁完毕后使用clipboard方法将数据直接写入用户粘贴板中,这个方法基本上看下面的代码就能明白,就不过多赘述了。
...
async function listenerMouseup(event) {
if (!isSelectModel) return;
isMousedown = false;
target.style.pointerEvents = "auto";
// 点击某个 dom
if (window.globalClickMouseDowned && event.which === 1) {
window.globalClickMouseDowned = false;
const now = new Date().getTime();
if (now - window.globalClickDownTime < 300) {
const infos = {
x: parseInt(maskDom.style.left),
y: parseInt(maskDom.style.top),
w: parseInt(maskDom.style.width),
h: parseInt(maskDom.style.height)
};
console.log('dom infos: ', infos);
// 返回整个屏幕截图
const screen_image = await chrome.runtime.sendMessage({ type: "screenshot" });
if (!screen_image.image) {
alert(chrome.i18n.getMessage('errorMsg'))
return;
}
// 裁剪图片
const crop_image = await crop(screen_image.image, infos);
// 复制进粘贴板
copy_img_to_clipboard(crop_image);
// 关闭 选择模式
isSelectModel = false;
maskDom.style.display = "none";
}
}
};
/**
* 图片裁剪
* @param image base64
* @param opts {x,y,w,h}
*/
function crop(image, opts) {
return new Promise((resolve, reject) => {
const x = opts.x, y = opts.y;
const w = opts.w, h = opts.h;
const format = opts.format || 'png';
const canvas = document.createElement('canvas');
canvas.width = w
canvas.height = h
document.body.append(canvas);
const img = new Image()
img.onload = () => {
const context = canvas.getContext('2d')
context.drawImage(img,
x, y, w, h,
0, 0, w, h
)
const cropped = canvas.toDataURL(`image/${format}`)
canvas.remove();
resolve(cropped)
}
img.src = image
});
}
/**
* 将图片复制进用户粘贴板
* @param image base64
*/
async function copy_img_to_clipboard(image) {
const storage_data = await chrome.storage.sync.get(["model"]);
const model = storage_data.model || "file";;
// 复制都用户粘贴板中
if (model === 'base64') {
navigator.clipboard.writeText(image);
} else if (model === 'file') {
const [header, base64] = image.split(',')
const [_, type] = /data:(.*);base64/.exec(header)
const binary = atob(base64)
const array = Array.from({ length: binary.length })
.map((_, index) => binary.charCodeAt(index))
navigator.clipboard.write([
new ClipboardItem({
// 这里只能写入 png
'image/png': new Blob([new Uint8Array(array)], { type: 'image/png' })
})
])
}
}
...
service-worker.js中代码改成下面这样。
chrome.runtime.onInstalled.addListener(() => {
// console.log("我被安装啦!")
});
// 监听消息
chrome.runtime.onMessage.addListener((request, sender, sendResponse) => {
if (request.type === "screenshot") {
chrome.tabs.query({ active: true, currentWindow: true }, (tab) => {
// 对页面截图
chrome.tabs.captureVisibleTab(tab.windowId, { format: "png", quality: 100 }, (image) => {
// 会返回 base64 图片
sendResponse({ image })
})
})
}
// 这里要返回 true 不然接收端收不到信息
return true;
});
效果
直接保存为文件
base64方式
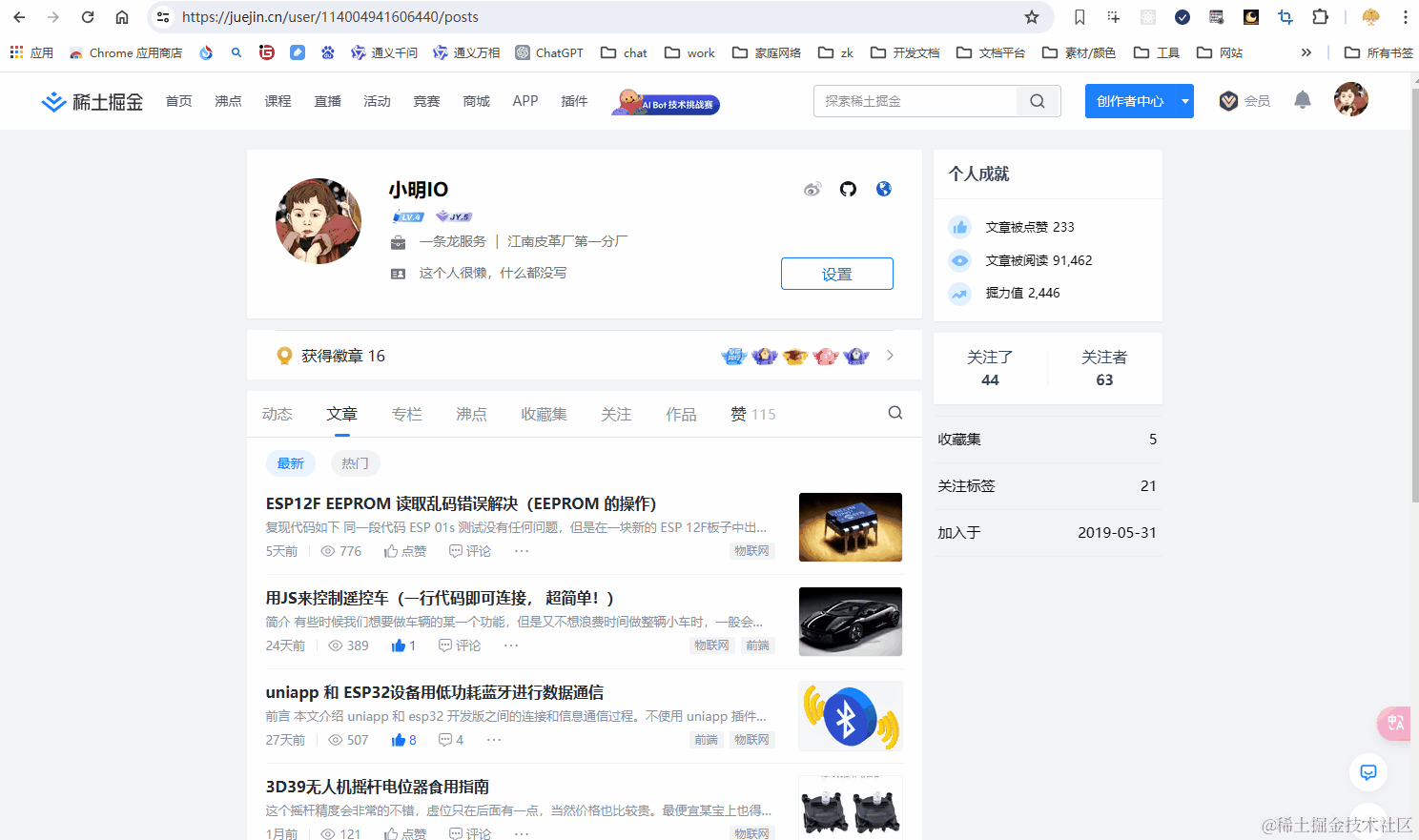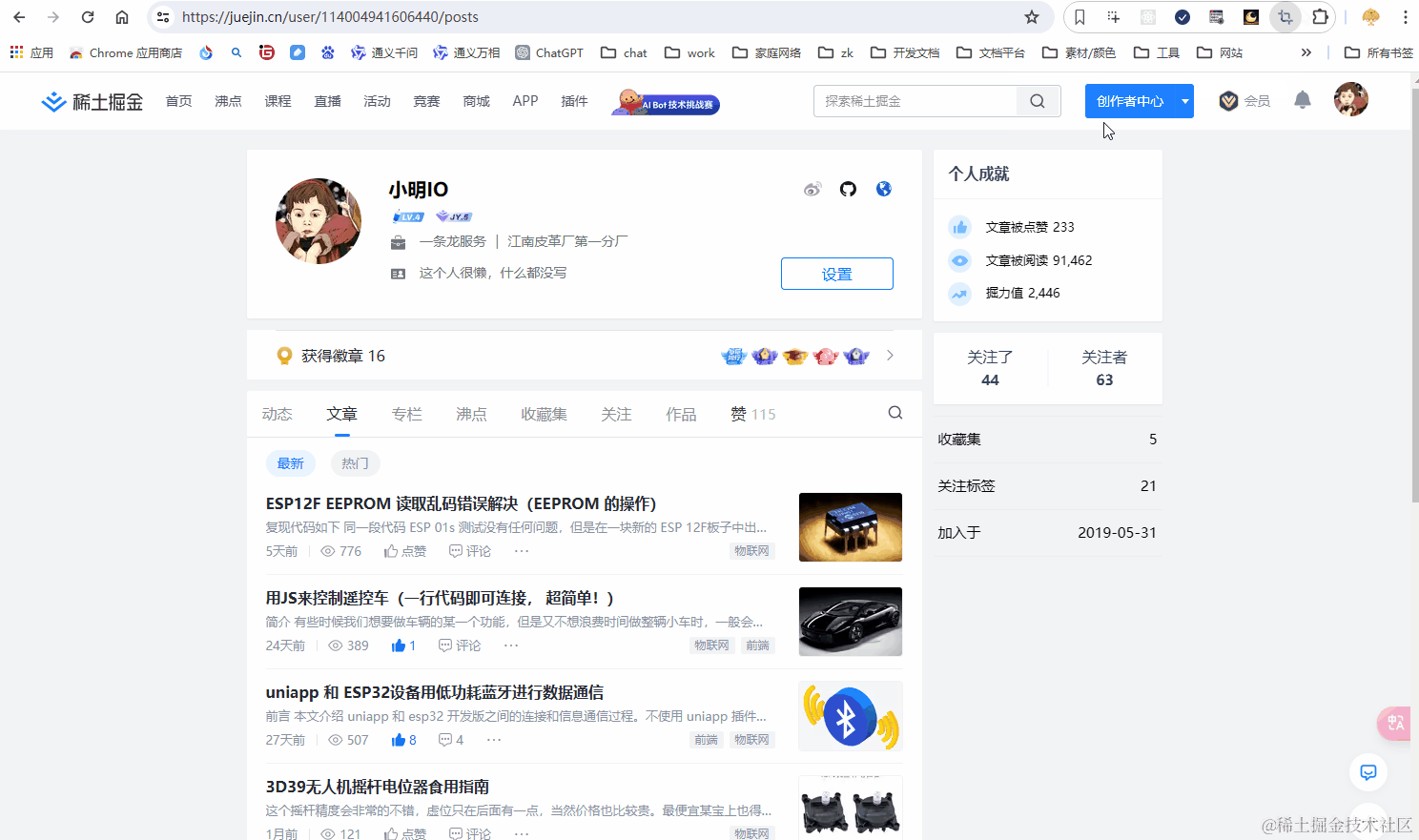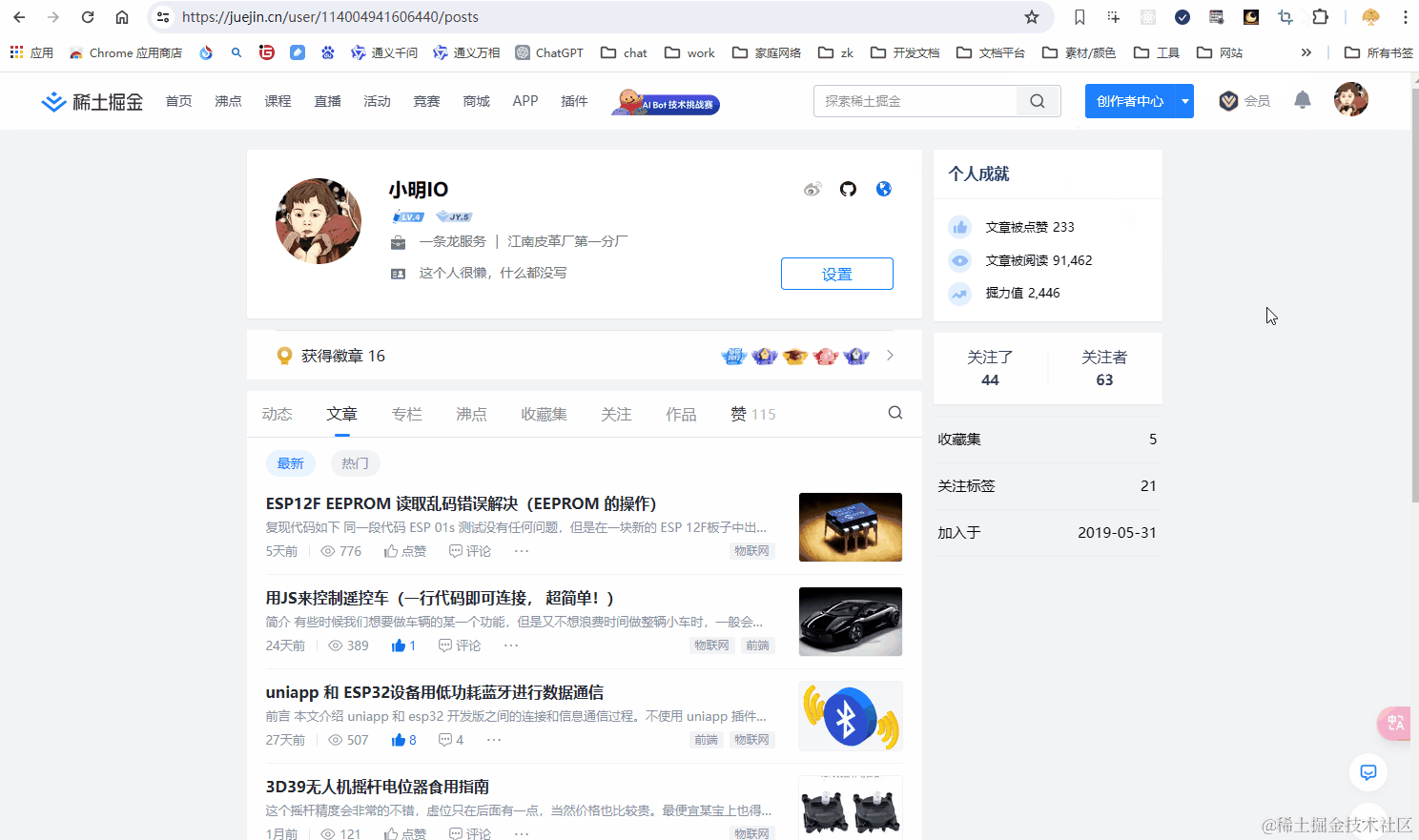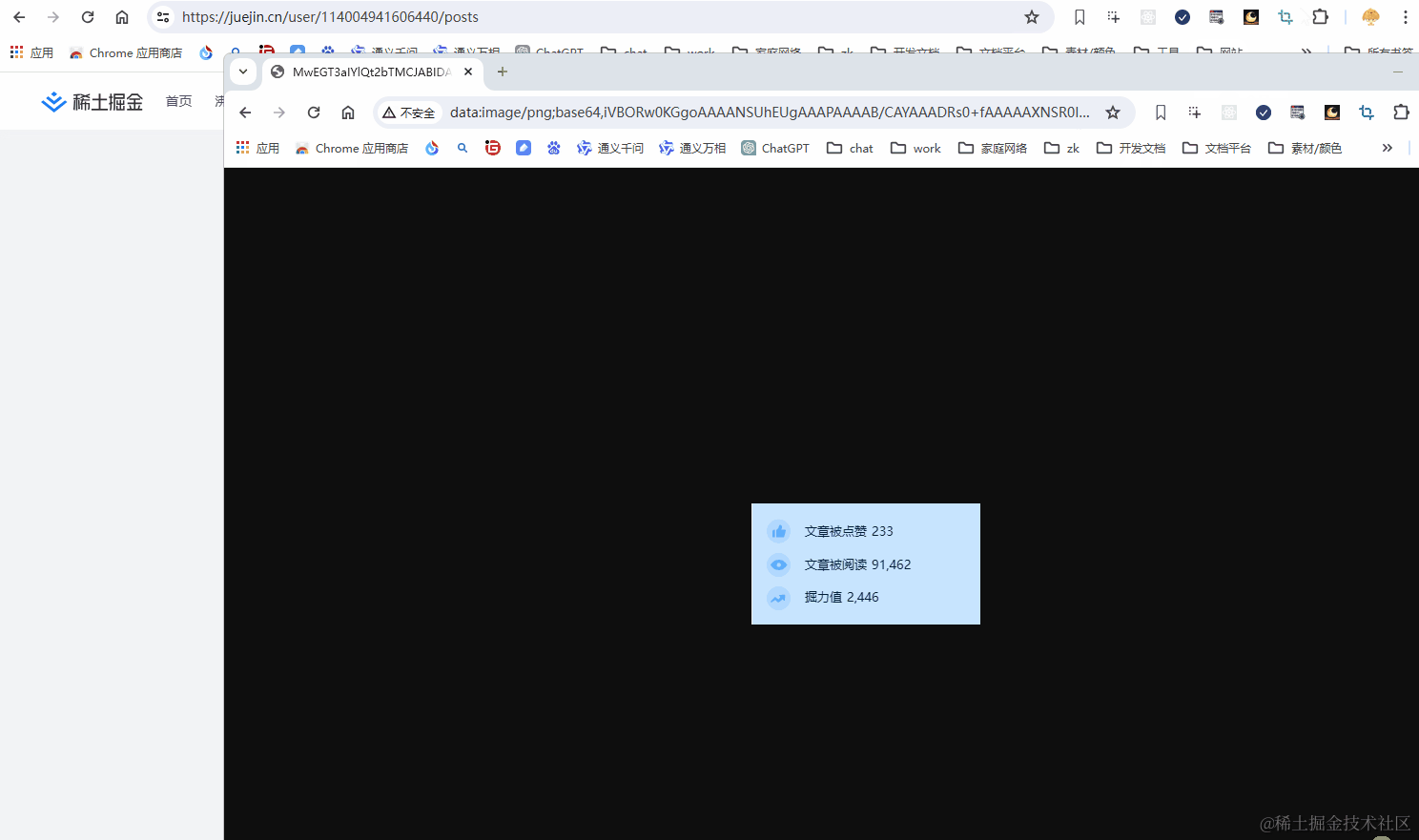
截图某个 DOM 到这里也就安全做完啦~
为什么不用现成的库来实现DOM截图
市面上有比较成熟的库可以很方便将DOM转为图片,比如 dom-to-image、html2canvas。但是这些库对于img、iframe等标签截图时,因为安全策略(浏览器同源策略),无法截取内容。
说白了,如果依靠这些库那就没法玩!只能依靠浏览器提供的API来对整个页面进行截图,然后在裁剪出我们需要的部分。
区域截图实现
区域框选实现
这个功能直接用一个库实现框选,因为有现成好用的库,就别造轮子了。库地址:https://fengyuanchen.github.io/cropperjs
将该库中的 cropper.min.css 和 cropper.min.js 下载到项目目录的 libs 中。
然后更改 manifest copy.json
{
...
"content_scripts": [
{
"css": [
"./libs/cropper.min.css"
],
"js": [
"./libs/cropper.min.js",
"content.js"
],
"matches": [
"<all_urls>"
]
}
],
...
}
然后更改 setting/index.js
...
// 区域截图
area_screenshot.addEventListener('click', () => {
chrome.tabs.query({ active: true, currentWindow: true }, function (tabs) {
// 通知 content.js 区域截图
chrome.tabs.sendMessage(tabs[0].id, { type: 'area-screenshot' });
});
// 关闭面板
window.close();
});
...
然后更改 content.js 中的 chrome.runtime.onMessage.addListener 这个监听方法。
利用 Cropper 来拉框选择一个区域,然后用老路子拿到选择的矩形坐标后进行裁剪和写入黏贴板。
/**
* 监听 service-worker、setting/index.js 发来的消息
*/
chrome.runtime.onMessage.addListener(async (req, sender, res) => {
if (req.type === 'select-dom') {
// 启动选择dom截图
isSelectModel = true;
}
if (req.type === 'area-screenshot') {
// 启动选择区域截图
area_screenshot();
}
return true
})
/**
* 进行区域截图
*/
async function area_screenshot() {
// 返回整个屏幕截图
const screen_image = await chrome.runtime.sendMessage({ type: "screenshot" });
if (!screen_image.image) {
alert(chrome.i18n.getMessage('errorMsg'))
return;
}
const image_container = document.createElement('div');
image_container.style.width = "100vw";
image_container.style.height = "100vh";
image_container.style.position = "fixed";
image_container.style.left = "0px";
image_container.style.top = "0px";
image_container.style.zIndex = 9999999999999;
document.body.append(image_container);
const image_dom = document.createElement('img');
image_dom.src = screen_image.image;
image_dom.style.maxWidth = "100%";
image_container.append(image_dom);
const infos = {};
const destroy_ins = new Cropper(image_dom, {
autoCrop: true,
autoCropArea: 0.001,
zoomOnTouch: false,
zoomOnWheel: false,
movable: false,
rotatable: false,
zoomable: false,
crop(event) {
infos.x = event.detail.x, infos.y = event.detail.y,
infos.w = event.detail.width, infos.h = event.detail.height;
},
async cropend() {
const crop_image = await crop(screen_image.image, infos);
copy_img_to_clipboard(crop_image);
// 别忘记注销掉刚刚我们产生的对象
destroy_ins.destroy();
image_container.remove();
},
});
}
效果
最后来看看效果
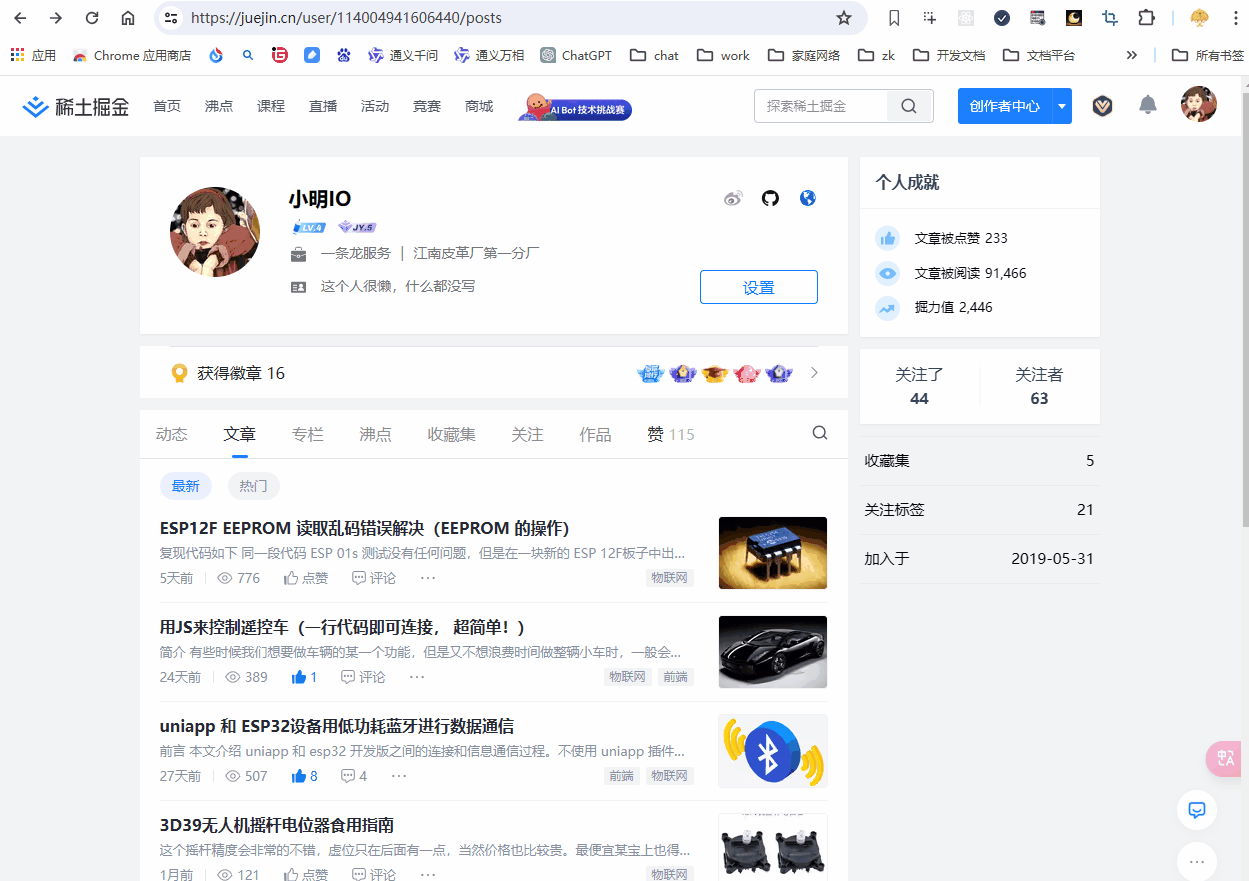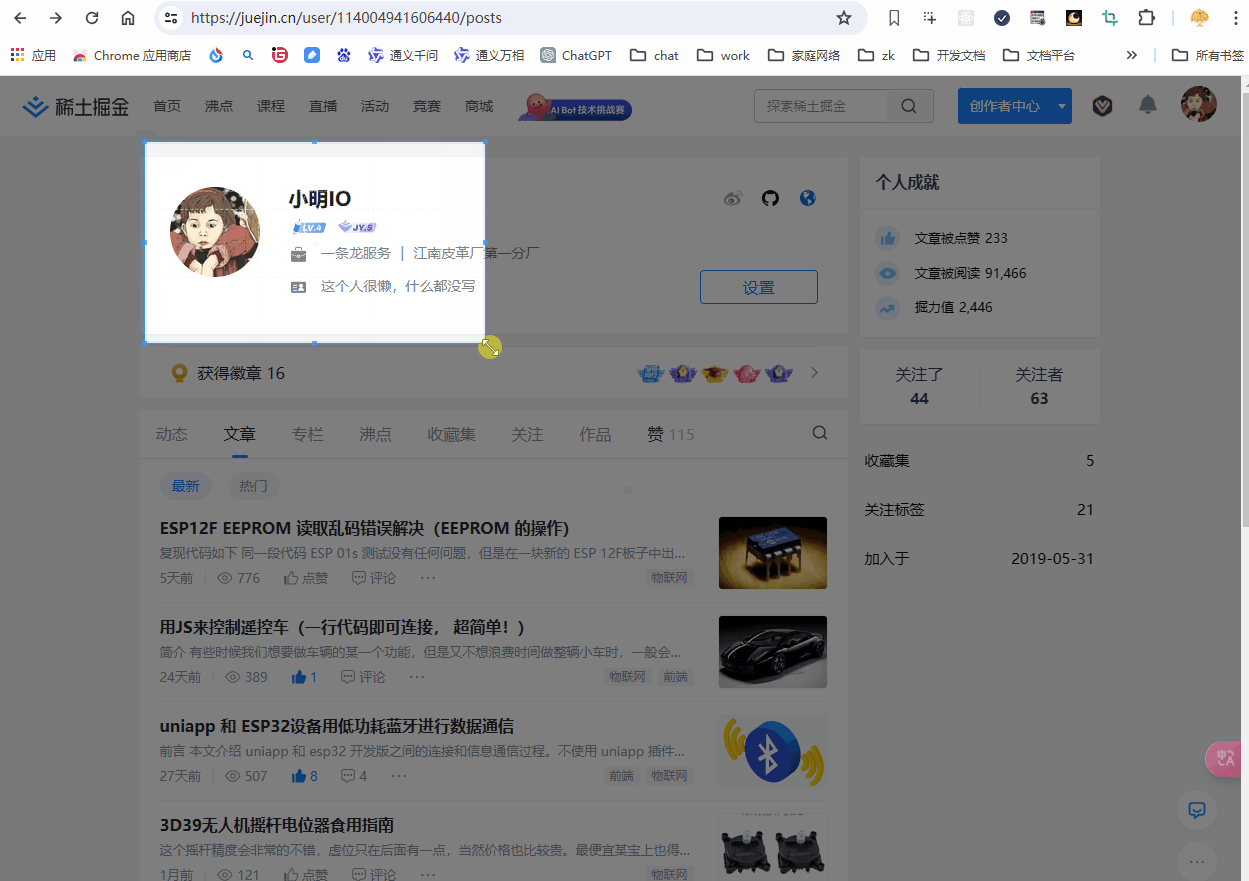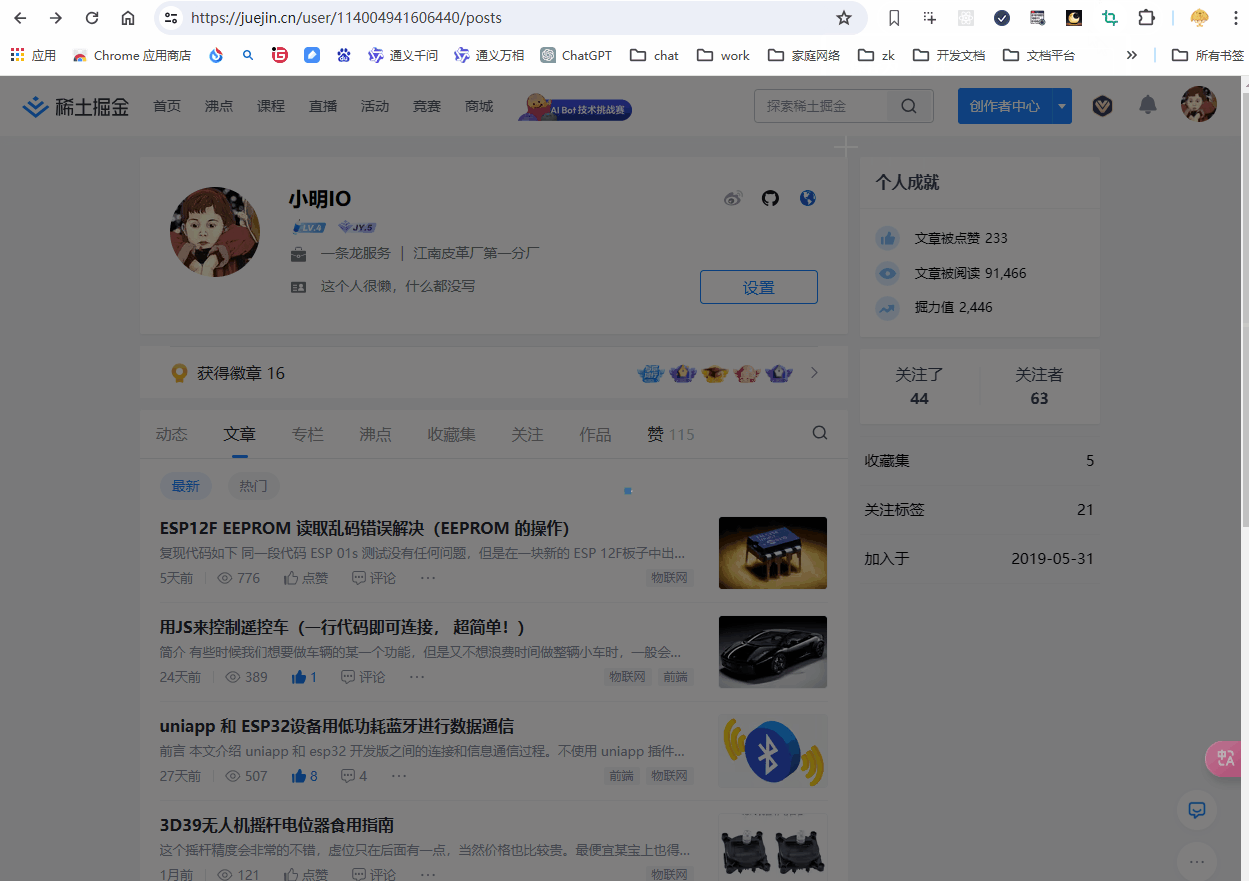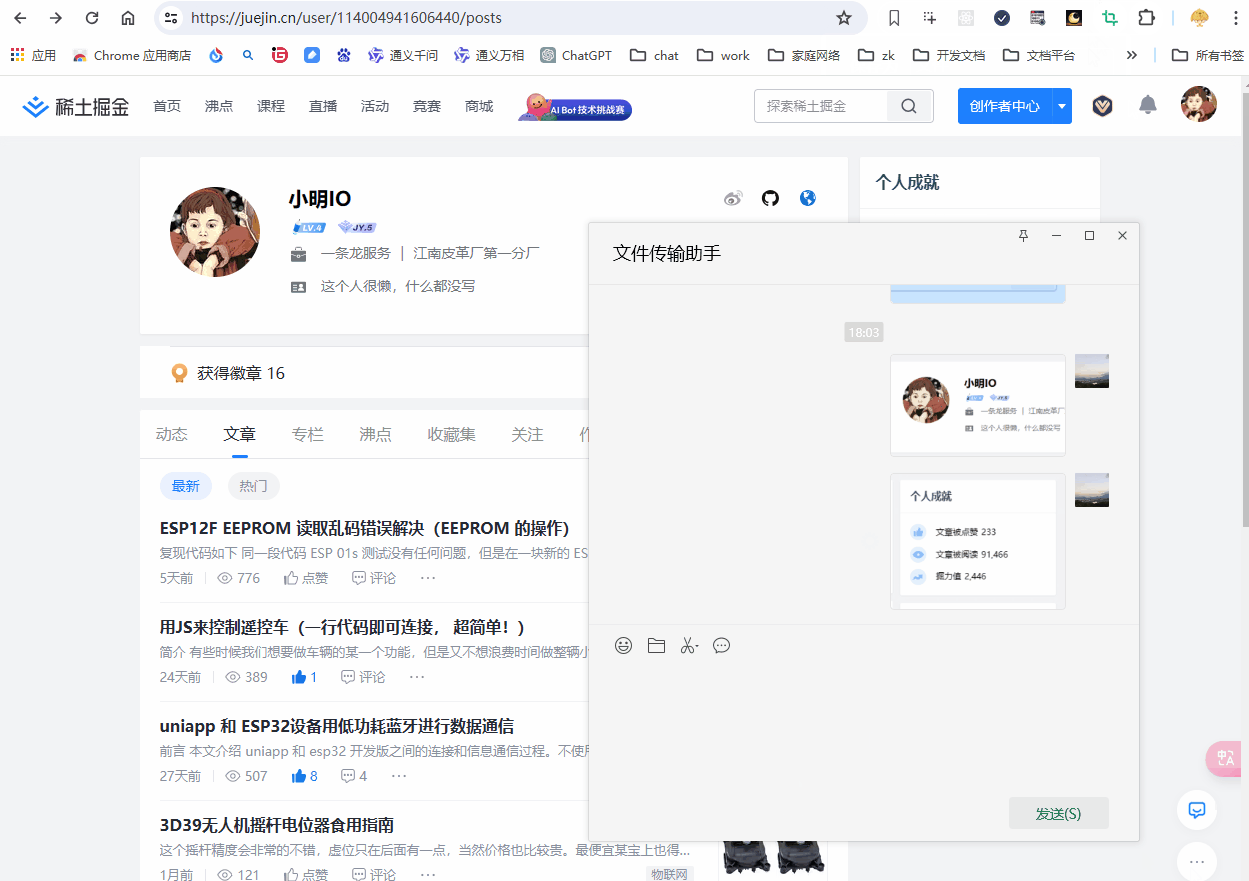
至此所有核心功能都开发完啦!
绑定快捷键
只需要在 service-worker.js 中监听快捷键即可。
// 快捷键监听
chrome.commands.onCommand.addListener((command) => {
if (command === 'areaScreenshot') {
chrome.tabs.query({ active: true, currentWindow: true }, function (tabs) {
chrome.tabs.sendMessage(tabs[0].id, { type: 'area-screenshot' });
});
}
if (command === 'domScreenshot') {
chrome.tabs.query({ active: true, currentWindow: true }, function (tabs) {
chrome.tabs.sendMessage(tabs[0].id, { type: 'select-dom' });
});
}
})
打包扩展程序
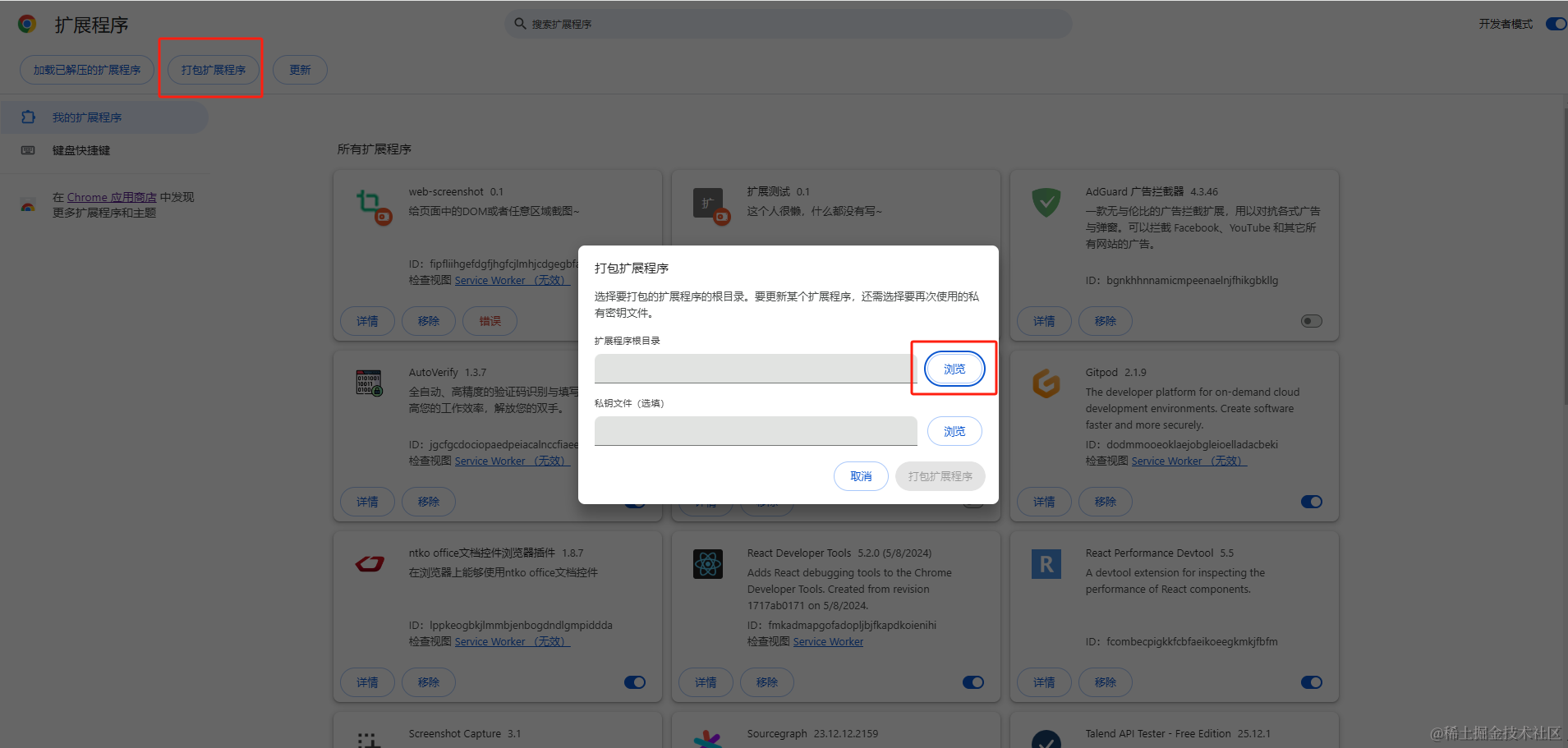
直接点击打包扩展程序按钮,然后选择插件目录就可以。
如果扩展程序没有找 Chrome 商店中上架,打包后的程序安装不了~
提交到 Chrome 应用商店
先到这里注册一个开发者账号 https://chrome.google.com/webstore/devconsole , 然后将代码文件都放到 zip 压缩包上面,填好写信息提交审核即可。
扩展程序下载
注意!注意! 发布后只能在 Chrome 商店中安装,没有其他安装地址,但是我在网上找到一个可以下载的地址:
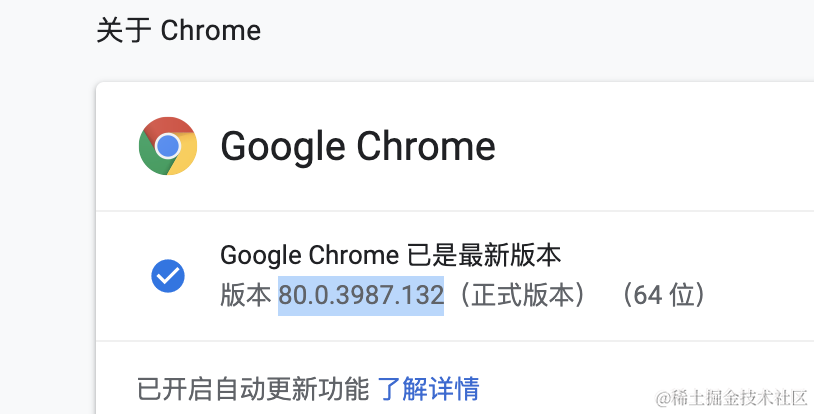
https://clients2.google.com/service/update2/crx?response=redirect&prodversion=[PRODVERSION]&acceptformat=crx2,crx3&x=id%3D[EXTENSIONID]%26uc
使用上方地址,将[PRODVERSION]换成浏览器版本,比如:
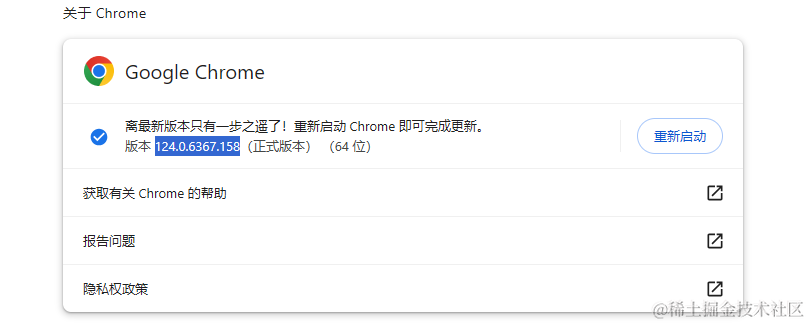
将[EXTENSIONID]换成插件 id,比如我这个插件的下载地址:
https://clients2.google.com/service/update2/crx?response=redirect&prodversion=124.0.6367.158&acceptformat=crx2,crx3&x=id%3Dpmjofmnlelohbkcclejgenpfgpfchbjo%26uc
web-screenshot 下载
- 扩展程序主页 点击直达
- Chrome 商店主页 点击直达
- github 仓库 点击直达(求 star ~)
- 码云仓库 点击直达(求 star ~)
交流群
QQ 交流群: 854445223
相关参考
- Chrome 扩展开发文档 点击直达


















 284
284

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











