







今天刷了下leetcode146:LRU缓存机制,基于LinkedHashMap实现很简单,看下基于LinkedHashMao的题解,以下源码基于jdk1.8copy
public class LRUCache extends LinkedHashMap<Integer, Integer>{s
private int capacity;
public LRUCache(int capacity) {
super(capacity, 0.75F, true);
this.capacity = capacity;
}
public int get(int key) {
return super.getOrDefault(key, -1);
}
public void put(int key, int value) {
super.put(key, value);
}
@Override
protected boolean removeEldestEntry(Map.Entry<Integer, Integer> eldest) {
return size() > capacity;
}
}
代码来源:https://leetcode-cn.com/problems/lru-cache/solution/lruhuan-cun-ji-zhi-by-leetcode-solution/
为啥继承LinkedHashMap就可以实现LRU(冷数据淘汰优先策略),来看看它的结构:
- LinkedHashMap可以看作是HahsMap(k,v) + LinkedList(链表),它的数据类型是k-v的形式,保证数据的插入顺序基于链表实现
LinkendHashMap.Entry<>结构:
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
- LinkendHashMap.Entry跟HashMap.Entry的区别在于多了before、after,他们的作用是维护Entry插入的先后顺序,这个可以看后面的put,get操作;
LinkedHashMap的put操作其实就是HashMap的put:
LikendHashMap.put()–>HashMap.put()–>HashMap.putVal()
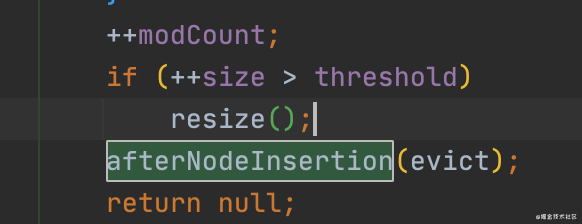
图片是HashMap.putVal()方法的部分截图,主要关注下afterNodeInsertion()这个方法,LinkedHashMap基于多态重写的afterNodeInsertion()方法:
/**
* put操作之后,是否移除最老的那个数据
**/
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);//删除链表的head节点
}
}
LinkedHashMap.removeEldestEntry()方法:
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
可以看到LinkedHashMap的removeEldestEntry()默认返回的false,也就是说在put的时候无论元素的个数都不会删除,即LinkedHashMap不限制长度;
也就是上面的LRU解法为啥要重写removeEldestEntry()方法,即size的数量超过设置的容量执行removeNode()
LinkedHashMap的removeNode还是使用的HashMap的方法,注意这里又使用了多态大法
HashMap.removeNode()部分源码:
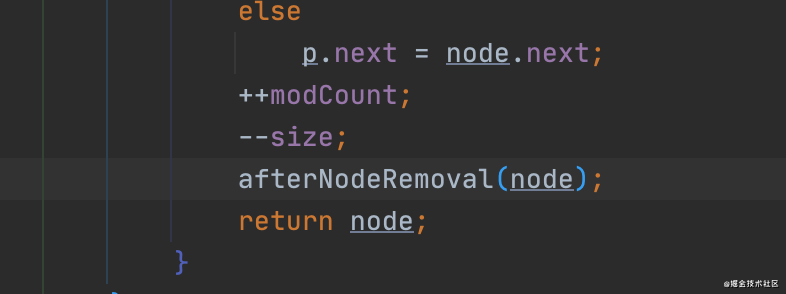
再来看下LinkedhashMap重写的afterNodeRemoval()方法
/**
*删除head节点之后,更新head节点,以及head、tail节点的引用
**/
void afterNodeRemoval(Node<K,V> e) { // unlink
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.before = p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a == null)
tail = b;
else
a.before = b;
}
上述讲的是LinkedHashMap的put是否删除最老的数据,put的时候数据是怎样放到链表尾部的昵,put的时候,LinkedHashMap还重写了afterNodeAccess()方法
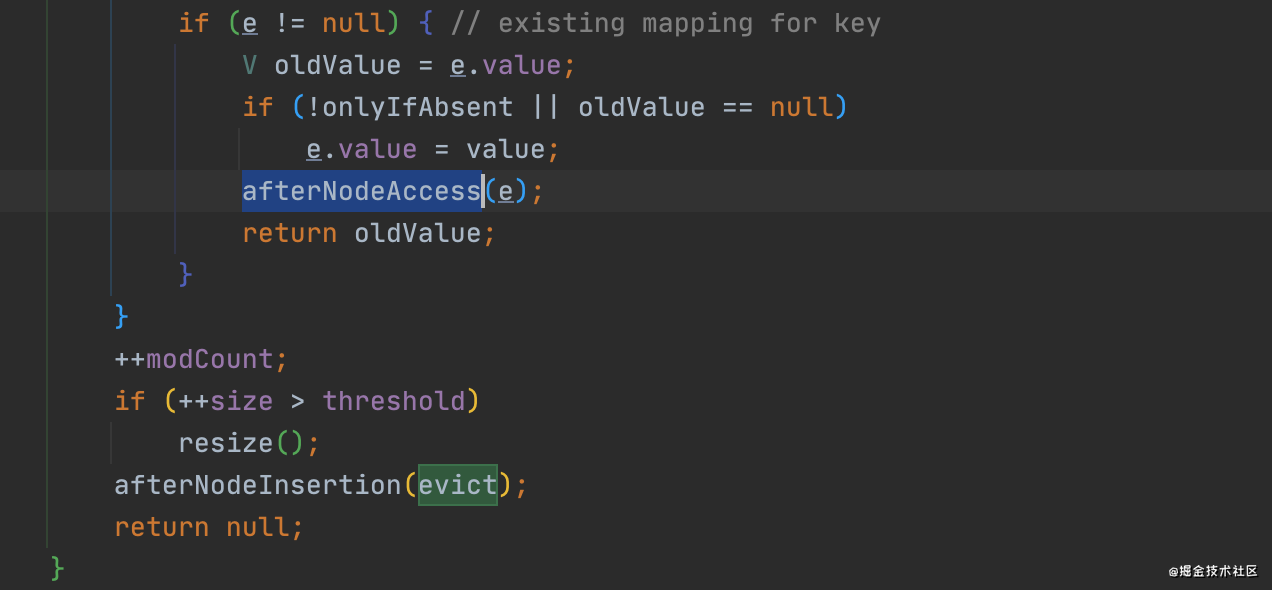
看下LikendHashMapafterNodeAccess()的源码:
/**
*移动node到链表尾部
**/
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
if (accessOrder=true是进入第一个if体的前提条件
&& (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
这个方法很简单,但是要注意第一个if语句里面的accessOrder=true是进入第一个if体的前提条件
看下LinkedHashMap的两个构造方法:
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
accessOrder在构造方法不指定的是否默认是false,afterNodeAccess()方法默认是不执行的,即LinkedHashMap的LRU功能默认是关闭的
再看下LinkedHashMap的get操作怎样实现LRU的:
LinkedHashMap重写了get()方法
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
这个就比较简单了,accessOrder如果打开使用的afterNodeAccess()方法将查询的节点移到链表的尾部
以上代码是基于jdk1.8的LinkedHashMap,跟jdk1.7的还是有点不同,文章的末尾贴个基于自定义的链表实现LRU:
class LRUCache {
private Node head;
private Node tail;
private int capacity;
private Map<Integer, Node> cache = new HashMap<>();
private int size = 0;
//自定义的双向链表
class Node{
int key;
int value;
Node pre;
Node next;
public Node(){
}
public Node(int key, int value){
this.key = key;
this.value = value;
}
}
public LRUCache(int capacity) {
this.capacity = capacity;
head = new Node(1, 1);
tail = new Node(-1, -1);
head.next = tail; //构造伪头部节点
tail.pre = head; //构造伪尾部节点 (构造的好处,操作真正的head、tail不用判断空)
}
public int get(int key) {
Node node = cache.get(key);
if(node == null){
return -1;
} else {
removeNode(node); //删除原位置的节点
moveNodeToTail(node); //根据LRU添加到尾部
}
return node.value;
}
public void put(int key, int value) {
Node node = cache.get(key);
if(node == null){
node = new Node(key, value);
moveNodeToTail(node); //根据LRU添加到尾部
cache.put(key, node); //成功put进的数据保存到缓存
if(++size > capacity){ //当前size超出了容量,移除最老的数据(head)
Node rehead = removeHead();
cache.remove(rehead.key);
--size;
}
} else { //put的key已存在,更新value并移到尾部
node.value = value;
removeNode(node);
moveNodeToTail(node);
}
}
/**
* 移动node到链表尾部
**/
public void moveNodeToTail(Node node){
if(node != null && node != tail.pre){//如果node已经是tail.pre节点不用移动
tail.pre.next = node;
node.pre = tail.pre;
node.next = tail;
tail.pre = node;
}
}
/**
* 删除node
**/
public void removeNode(Node node){
node.pre.next = node.next;
node.next.pre = node.pre;
}
/**
* 删除最老的节点(head)
**/
public Node removeHead(){
Node rehead = head.next;
removeNode(rehead);
return rehead;
}
}














 218
218











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









