






 文章详细介绍了如何准备Cityscapes数据集,包括加载训练和验证数据,将灰度图转换为彩色分割图,以及数据预处理步骤。接着,构建了一个SegNet模型,包括多个卷积、池化和上采样层,并进行了权重初始化。最后,文章提到了训练过程和模型在训练、验证和测试集上的性能,以及展示了预测结果。
文章详细介绍了如何准备Cityscapes数据集,包括加载训练和验证数据,将灰度图转换为彩色分割图,以及数据预处理步骤。接着,构建了一个SegNet模型,包括多个卷积、池化和上采样层,并进行了权重初始化。最后,文章提到了训练过程和模型在训练、验证和测试集上的性能,以及展示了预测结果。
Part 1 数据准备
从Cityscapes官网下载Groundtruth: leftImg8bit_trainvaltest.zip与Label:gtFine_trainvaltest.zip(图1)
图1 从官网下载数据集
leftImg8bit:放置训练街景图,按城市分子文件夹,存放png图片(命名格式:城市名称_6位数字_6位数字_leftImg8bit.png)(图2)

图2 leftImg8bit中的街景原图
gtFine:放置精细标注文件,分train(18个城市)/val(3个城市)/test(6个城市)三个文件夹,每个城市文件夹下针对每张街景图png文件对应了4个标注文件(图3):
- xxx_gtFine_color.png 代表可视化的分割图
- xxx_gtFine_instanceIds.png 代表实例分割标注文件
- xxx_gtFine_labelIds.png 代表每个实例的标签id标注
- xxx_gtFine_polygons.json

图3 gtFine中的标注文件
2.导入所需的库和模块
import os
import cv2
import glob
import torch
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from tqdm import tqdm,trange
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import torch.nn as nn
import torch.nn.functional as F
from torch import optim
# Make numpy printouts easier to read.
np.set_printoptions(precision=3, suppress=True)3.加载训练和验证数据集,测试数据集没有标注,所以我们将把训练数据分割成训练和测试数据
train_label_data_path = '/home/luyx/zk/Cityscapes/gtFine/train'
valid_label_data_path = '/home/luyx/zk/Cityscapes/gtFine/val'
train_img_path = '/home/luyx/zk/Cityscapes/leftImg8bit/train'
valid_img_path = '/home/luyx/zk/Cityscapes/leftImg8bit/val
train_labels = sorted(glob.glob(train_label_data_path+"/*/*_labelIds.png"))
valid_labels = sorted(glob.glob(valid_label_data_path+"/*/*_labelIds.png"))
train_inp = sorted(glob.glob(train_img_path+"/*/*.png"))
valid_inp = sorted(glob.glob(valid_img_path+"/*/*.png"))
#每张图片的大小:cv2.imread(train_labels[0]).shape:(1024,2048,3)from collections import namedtuple
labels = [
# name id trainId category catId hasInstances ignoreInEval color
Label( 'unlabeled' , 0 , 255 , 'void' , 0 , False , True , ( 0, 0, 0) ),
Label( 'ego vehicle' , 1 , 255 , 'void' , 0 , False , True , ( 0, 0, 0) ),
Label( 'rectification border' , 2 , 255 , 'void' , 0 , False , True , ( 0, 0, 0) ),
Label( 'out of roi' , 3 , 255 , 'void' , 0 , False , True , ( 0, 0, 0) ),
Label( 'static' , 4 , 255 , 'void' , 0 , False , True , ( 0, 0, 0) ),
Label( 'dynamic' , 5 , 255 , 'void' , 0 , False , True , (111, 74, 0) ),
Label( 'ground' , 6 , 255 , 'void' , 0 , False , True , ( 81, 0, 81) ),
Label( 'road' , 7 , 0 , 'flat' , 1 , False , False , (128, 64,128) ),
Label( 'sidewalk' , 8 , 1 , 'flat' , 1 , False , False , (244, 35,232) ),
Label( 'parking' , 9 , 255 , 'flat' , 1 , False , True , (250,170,160) ),
Label( 'rail track' , 10 , 255 , 'flat' , 1 , False , True , (230,150,140) ),
Label( 'building' , 11 , 2 , 'construction' , 2 , False , False , ( 70, 70, 70) ),
Label( 'wall' , 12 , 3 , 'construction' , 2 , False , False , (102,102,156) ),
Label( 'fence' , 13 , 4 , 'construction' , 2 , False , False , (190,153,153) ),
Label( 'guard rail' , 14 , 255 , 'construction' , 2 , False , True , (180,165,180) ),
Label( 'bridge' , 15 , 255 , 'construction' , 2 , False , True , (150,100,100) ),
Label( 'tunnel' , 16 , 255 , 'construction' , 2 , False , True , (150,120, 90) ),
Label( 'pole' , 17 , 5 , 'object' , 3 , False , False , (153,153,153) ),
Label( 'polegroup' , 18 , 255 , 'object' , 3 , False , True , (153,153,153) ),
Label( 'traffic light' , 19 , 6 , 'object' , 3 , False , False , (250,170, 30) ),
Label( 'traffic sign' , 20 , 7 , 'object' , 3 , False , False , (220,220, 0) ),
Label( 'vegetation' , 21 , 8 , 'nature' , 4 , False , False , (107,142, 35) ),
Label( 'terrain' , 22 , 9 , 'nature' , 4 , False , False , (152,251,152) ),
Label( 'sky' , 23 , 10 , 'sky' , 5 , False , False , ( 70,130,180) ),
Label( 'person' , 24 , 11 , 'human' , 6 , True , False , (220, 20, 60) ),
Label( 'rider' , 25 , 12 , 'human' , 6 , True , False , (255, 0, 0) ),
Label( 'car' , 26 , 13 , 'vehicle' , 7 , True , False , ( 0, 0,142) ),
Label( 'truck' , 27 , 14 , 'vehicle' , 7 , True , False , ( 0, 0, 70) ),
Label( 'bus' , 28 , 15 , 'vehicle' , 7 , True , False , ( 0, 60,100) ),
Label( 'caravan' , 29 , 255 , 'vehicle' , 7 , True , True , ( 0, 0, 90) ),
Label( 'trailer' , 30 , 255 , 'vehicle' , 7 , True , True , ( 0, 0,110) ),
Label( 'train' , 31 , 16 , 'vehicle' , 7 , True , False , ( 0, 80,100) ),
Label( 'motorcycle' , 32 , 17 , 'vehicle' , 7 , True , False , ( 0, 0,230) ),
Label( 'bicycle' , 33 , 18 , 'vehicle' , 7 , True , False , (119, 11, 32) ),
Label( 'license plate' , -1 , -1 , 'vehicle' , 7 , False , True , ( 0, 0,142) ),
]4.将_gtFine_labelIds灰度图图像转换为彩色分割图(图4)
#需要显示为彩色的标签(即labels_used,ignoreinEval == False)的那一列将被筛选出来形成新的列表,
#其trainID将被重新编码为0,1,2……,其余未被筛选出来的trainId的为255,显示为黑色
labels_used = []
ids = []
for i in range(len(labels)):
if(labels[i].ignoreInEval == False):
labels_used.append(labels[i])
ids.append(labels[i].id)
#以其中一张标签图为例:
label_in = cv2.imread(train_labels[0])[:,:,0]
#create a dictionary with label_id as key & train_id as value
label_dic = {}
for i in range(len(labels)-1):
label_dic[labels[i].id] = labels[i].trainId
#将labelids转换为trainids
def createtrainID(label_in,label_dic):
mask = np.zeros((label_in.shape[0],label_in.shape[1])) # 1024,2048
l_un = np.unique(label_in) #找出label_in中所有的id
for i in range(len(l_un)):
mask[label_in==l_un[i]] = label_dic[l_un[i]] #将id转换为trainid
return mask
#展示灰度图转换后的彩色图
def visual_label(mask,labels_used,plot = False):
label_img = np.zeros((mask.shape[0],mask.shape[1],3))
r = np.zeros((mask.shape[0],mask.shape[1]))
g = np.zeros((mask.shape[0],mask.shape[1]))
b = np.zeros((mask.shape[0],mask.shape[1]))
l_un = np.unique(mask)
for i in range(len(l_un)):
if l_un[i]<19:
r[mask==int(l_un[i])] = labels_used[int(l_un[i])].color[0]
g[mask==int(l_un[i])] = labels_used[int(l_un[i])].color[1]
b[mask==int(l_un[i])] = labels_used[int(l_un[i])].color[2]
label_img[:,:,0] = r/255
label_img[:,:,1] = g/255
label_img[:,:,2] = b/255
if plot:
plt.imshow(label_img)
return label_img
label_img = visual_label(createtrainID(label_in,label_dic),labels_used,plot = True)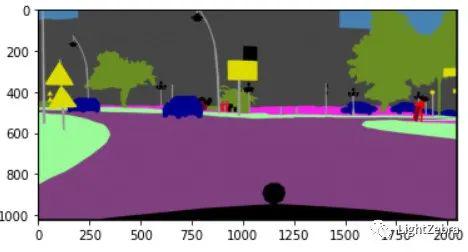
图4 将灰度图转换为彩色分割图
5.展示不同色块代表的物体(图5)
fig = plt.figure(figsize = (10,10))
for i in range(len(labels_used)):
temp = np.zeros((5,5,3))
temp[:,:,0] = labels_used[i].color[0]/255
temp[:,:,1] = labels_used[i].color[1]/255
temp[:,:,2] = labels_used[i].color[2]/255
ax = fig.add_subplot(5, 4, i+1)
ax.imshow(temp)
ax.set_title(labels_used[i].name)
ax.axis('off')
图5 展示不同色块代表的物体
6.数据预处理
#1.resize为(96,96) 2.将数据转换为(通道数,宽,高)
def gen_images(x,s1=96,s2=96):
_,_,s3 = cv2.imread(x).shape
img = np.zeros((s1,s2,s3))
image= cv2.resize(cv2.imread(x),(s1,s2),interpolation = cv2.INTER_NEAREST)
image = image/255
img[:,:,:] = image
return torch.tensor(img).permute(2,0,1)
def gen_mask_train(x,label_dic,s1=96,s2=96):
#s1,s2,_ = cv2.imread(x[0]).shape
mask = np.zeros((s1,s2))
image = createtrainID(cv2.resize(cv2.imread(x),(s1,s2),interpolation = cv2.INTER_NEAREST)[:,:,0],label_dic)
mask[:,:] = image
mask[mask==255] = 19
return torch.tensor(mask)7.对街景图使用gen_images处理,对标签图使用gen_mask_train处理,然后抽取80%的数据作为训练集
train_images=[]
train_label=[]
valid_images=[]
valid_label=[]
for i in trange(len(train_inp)):
train_images.append(gen_images(train_inp[i]))
train_label.append(gen_mask_train(train_labels[i],label_dic))
for i in trange(len(valid_inp)):
valid_images.append(gen_images(valid_inp[i]))
valid_label.append(gen_mask_train(valid_labels[i],label_dic))
train = []
for x in zip(train_images,train_label):
train.append(x)
valid_dataset =[]
for x in zip(valid_images,valid_label):
valid_dataset.append(x)
n = len(train)
train_n = int(0.8*n)
np.random.seed(0)
perm = np.random.permutation(n)
train_dataset = []
test_dataset = []
for i in range(len(perm[0:train_n])):
train_dataset.append(train[perm[i]])
for i in range(len(perm[train_n:n])):
test_dataset.append(train[perm[i]])8.数据加载
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=64,
shuffle=True,
num_workers=0)
valid_loader = torch.utils.data.DataLoader(valid_dataset,
batch_size=64,
shuffle=True,
num_workers=0)
test_loader = torch.utils.data.DataLoader(test_dataset,
batch_size=64,
shuffle=True,
num_workers=0)Part 2 SegNet模型构建
构建4个基础模块
#模块1:convulution->batch_norm->relu
class single_conv(nn.Module):
def __init__(self, in_ch, out_ch):
super(single_conv, self).__init__() # Note: for conv, use a padding of (1,1) so that size is maintained
self.conv = nn.Conv2d(in_ch, out_ch, kernel_size=3,padding = 1)
self.bn = nn.BatchNorm2d(out_ch,momentum = 0.1)
self.relu = nn.ReLU()
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.relu(x)
return x
#模块2:maxpool
class down_layer(nn.Module):
def __init__(self):
super(down_layer, self).__init__()
self.down = nn.MaxPool2d(kernel_size=2, stride=2, return_indices=True) # use nn.MaxPool2d( )
def forward(self, x):
x1,idx = self.down(x)
return x1,idx
#模块3:unpool(双线性插值上采样,亦可以用转置卷积)
class un_pool(nn.Module):
def __init__(self):
super(un_pool, self).__init__()
self.un_pool = nn.MaxUnpool2d(kernel_size=2, stride=2) # use nn.Upsample() with mode bilinear
def forward(self, x, idx,x1):
#Take the indicies from maxpool layer
x = self.un_pool(x,idx,output_size = x1.size())
return x
#模块4:a convolution layer
class outconv(nn.Module):
def __init__(self, in_ch, out_ch):
super(outconv, self).__init__()
# 1 conv layer
self.conv = nn.Conv2d(in_ch, out_ch, kernel_size=3,padding = 1)
def forward(self, x):
# Forward conv layer
x = self.conv(x)
return x
class SegNet(nn.Module):
def __init__(self, n_channels_in, n_classes):
super(SegNet, self).__init__()
self.conv1 = single_conv(n_channels_in,64)
self.conv2 = single_conv(64,64)
self.down1 = down_layer()
self.conv3 = single_conv(64,128)
self.conv4 = single_conv(128,128)
self.down2 = down_layer()
self.conv5 = single_conv(128,256)
self.conv6 = single_conv(256,256)
self.conv7 = single_conv(256,256)
self.down3 = down_layer()
self.conv8 = single_conv(256,512)
self.conv9 = single_conv(512,512)
self.conv10 = single_conv(512,512)
self.down4 = down_layer()
self.conv11 = single_conv(512,512)
self.conv12 = single_conv(512,512)
self.conv13 = single_conv(512,512)
self.down5 = down_layer()
self.up1 = un_pool()
self.conv14 = single_conv(512,512)
self.conv15 = single_conv(512,512)
self.conv16 = single_conv(512,512)
self.up2 = un_pool()
self.conv17 = single_conv(512,512)
self.conv18 = single_conv(512,512)
self.conv19 = single_conv(512,256)
self.up3 = un_pool()
self.conv20 = single_conv(256,256)
self.conv21 = single_conv(256,256)
self.conv22 = single_conv(256,128)
self.up4 = un_pool()
self.conv23 = single_conv(128,128)
self.conv24 = single_conv(128,64)
self.up5 = un_pool()
self.conv25 = single_conv(64,64)
self.outconv1 = outconv(64,n_classes)
def forward(self, x):
x1 = self.conv1(x)
x2 = self.conv2(x1)
x3,idx1 = self.down1(x2)
x4 = self.conv3(x3)
x5 = self.conv4(x4)
x6,idx2 = self.down2(x5)
x7 = self.conv5(x6)
x8 = self.conv6(x7)
x9 = self.conv7(x8)
x10,idx3 = self.down3(x9)
x11 = self.conv8(x10)
x12 = self.conv9(x11)
x13 = self.conv10(x12)
x14,idx4 = self.down4(x13)
x15 = self.conv11(x14)
x16 = self.conv12(x15)
x17 = self.conv13(x16)
x18,idx5 = self.down5(x17)
x19 = self.up1(x18,idx5,x17)
x20 = self.conv14(x19)
x21 = self.conv15(x20)
x22 = self.conv16(x21)
x23 = self.up2(x22,idx4,x13)
x24 = self.conv17(x23)
x25 = self.conv18(x24)
x26 = self.conv19(x25)
x27 = self.up3(x26,idx3,x9)
x28 = self.conv20(x27)
x29 = self.conv21(x28)
x30 = self.conv22(x29)
x31 = self.up4(x30,idx2,x5)
x32 = self.conv23(x31)
x33 = self.conv24(x32)
x34 = self.up4(x33,idx1,x2)
x35 = self.conv25(x34)
x = self.outconv1(x35)
return xPart 3 参数预设
net= SegNet(3,20)
optimizer = torch.optim.Adam(
net.parameters(),
lr=0.001,)
def initialize_parameters(m):
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight.data, nonlinearity = 'relu')
nn.init.constant_(m.bias.data, 0)
net.apply(initialize_parameters)weights = np.zeros((20))
for (_, y) in tqdm(train_loader):
# y = gen_mask_train(y,label_dic)
y = y.to(device).long()
for i in range(20):
weights[i] += torch.sum((y==i).type(torch.uint8))
weights = np.max(weights)/(weights)
# weights = weights*len(train_dataset)
weights = torch.FloatTensor(weights)net = net.to(device)
criterion = nn.CrossEntropyLoss()
criterion = criterion.to(device)Part 4 使用数据集进行训练
def mean_iou(y_pred,y,num_classes = 20,last_background = True,smooth = 0.001):
y_pred = torch.argmax(y_pred,dim=1)
mean_IoU = []
if last_background:
num_classes = num_classes - 1
for i in range(num_classes):
class_pred = (y_pred==i).type(torch.uint8)
class_truth = (y==i).type(torch.uint8)
union = torch.logical_or(class_pred,class_truth).type(torch.uint8)
intersection = torch.logical_and(class_pred,class_truth).type(torch.uint8)
IoU = torch.sum(intersection+0.001,dim=(1,2))/torch.sum(union+0.001,dim=(1,2))
# intersection = torch.sum(intersection, dim =(1,2))
# union = torch.sum(union, dim =(1,2))
# if torch.sum((union!=0).type(torch.uint8))!=0:
# IoU = intersection[union!=0]/union[union!=0]
mean_IoU.append(IoU.mean())
mean_IoU = sum(mean_IoU)/num_classes
return mean_IoU1.定义训练与评估函数
def train(model, iterator, optimizer, criterion, device,label_dic):
epoch_loss = 0
epoch_IoU = 0
model.train()
for (x, y) in tqdm(iterator):
x = x.to(device).type(torch.float)
y = y.to(device).long()
optimizer.zero_grad()
y_pred = model(x)
loss = criterion(y_pred, y)
IoU = mean_iou(y_pred, y)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
epoch_IoU += IoU.item()
return epoch_loss / len(iterator), epoch_IoU/len(iterator)
def evaluation(model, iterator, criterion, device,label_dic):
epoch_loss = 0
epoch_IoU = 0
model.eval()
with torch.no_grad():
for (x, y) in tqdm(iterator):
x = x.to(device).type(torch.float)
y = y.to(device).long()
y_pred = model(x)
loss = criterion(y_pred, y)
IoU = mean_iou(y_pred, y)
epoch_loss += loss.item()
epoch_IoU += IoU.item()
return epoch_loss / len(iterator), epoch_IoU/len(iterator)import time
def epoch_time(start_time, end_time):
elapsed_time = end_time - start_time
elapsed_mins = int(elapsed_time / 60)
elapsed_secs = int(elapsed_time - (elapsed_mins * 60))
return elapsed_mins, elapsed_sec
best_valid_loss = float('inf')
for epoch in range(100):
start_time = time.time()
train_loss,train_iou = train(net, train_loader, optimizer, criterion, device,label_dic)
valid_loss,valid_iou = evaluation(net, valid_loader, criterion, device,label_dic)
end_time = time.time()
epoch_mins, epoch_secs = epoch_time(start_time, end_time)# ...
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
torch.save(net.state_dict(), 'net.pt')
print(f'Epoch: {epoch+1:02} | Epoch Time: {epoch_mins}m {epoch_secs}s')
print(f'\tTrain Loss: {train_loss:.3f} | Train IoU: {train_iou}')
print(f'\t Val. Loss: {valid_loss:.3f} | Valid IoU: {valid_iou}')该网络结构在训练集上的结果较好,IoU可达0.82;但在测试集效果较差,IoU为0.61左右
2.展示预测结果(图6)
net.load_state_dict(torch.load('net.pt'))
test_loss,test_iou = evaluation(net, test_loader, criterion, device,label_dic)
print(f'\tTest Loss: {test_loss:.3f} | Test IoU: {test_iou}')
x,y = iter(test_loader).next()
img = x.to(device).type(torch.float)
mask = y.to(device)
net.eval()
with torch.no_grad():
y_pred = net(img)
fig = plt.figure(figsize = (10,10))
for i in range(11,15):
ax = fig.add_subplot(2, 4, i-10)
visualization = visual_label(mask[i,:,:].cpu().numpy(),labels_used)
ax.imshow(visualization)
ax.set_title('Ground Truth')
ax.axis('off')
ax = fig.add_subplot(2, 4, i-6)
y_test = y_pred.permute(0,2,3,1)[i,:,:,:].cpu().numpy()
visual_test = visual_label(np.argmax(y_test,axis=2),labels_used)
ax.imshow(visual_test)
ax.set_title('Predicted')
ax.axis('off')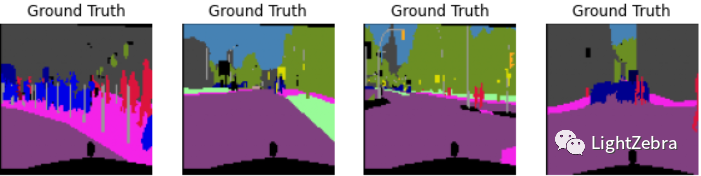
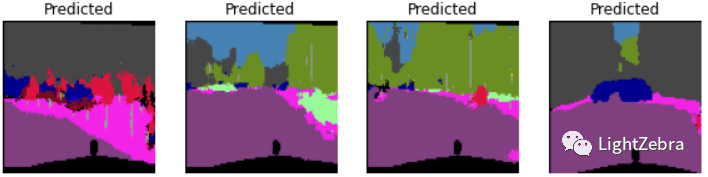
图6 展示预测结果
2015年,Segnet模型由Vijay Badrinarayanan, Alex Kendall, Roberto Cipolla发表, 在FCN的语义分割任务基础上,搭建编码器-解码器对称结构,实现端到端的像素级别图像分割,其模型框架和思路都比较简单,后续我们将逐渐增加难度,探索更新的网络架构。
Segnet原文链接:https://arxiv.org/abs/1511.00561
·END·


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









