








1、什么是分词:
分词就是指将一个文本转化成一系列单词的过程,也叫文本分析,在Elasticsearch中称之为Analysis。 举例:我是好学生 --> 我/是/好学生
2、分词API
2.1、指定分词器进行分词
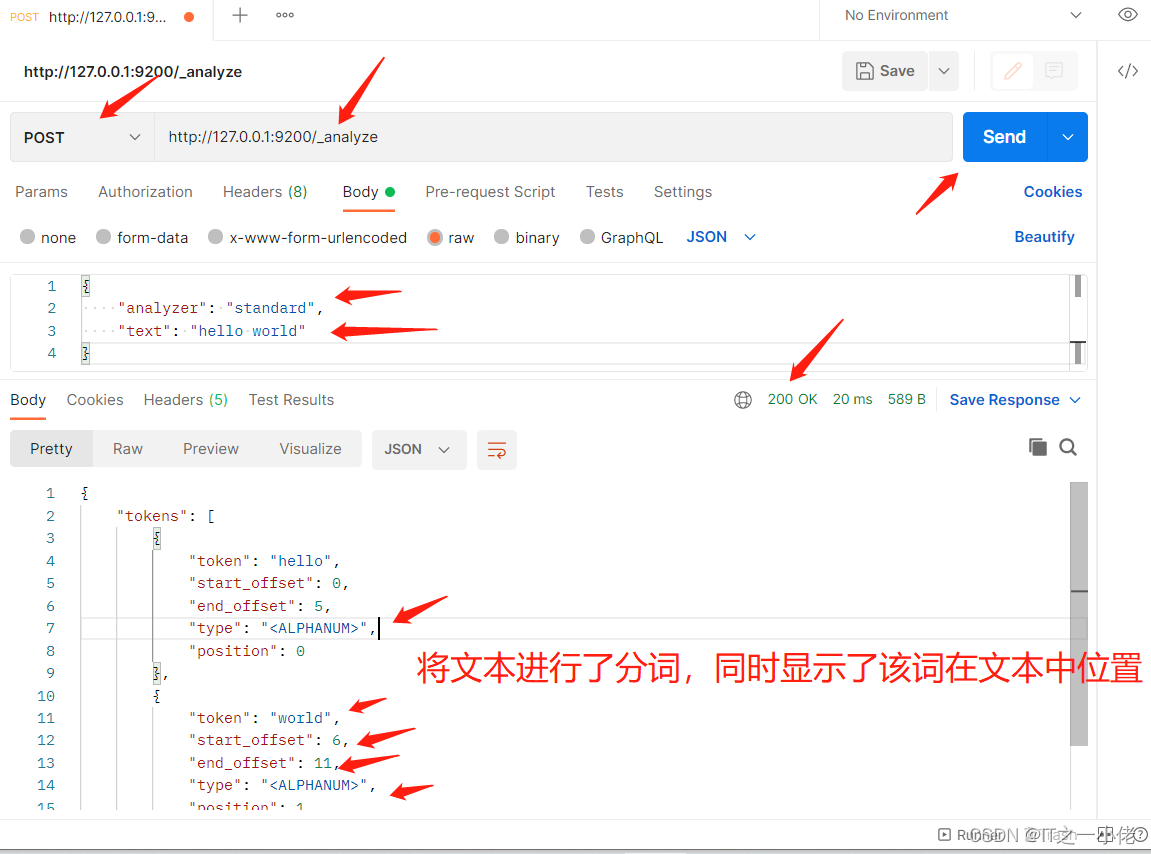
POST http://127.0.0.1:9200/_analyze
# 请求数据
{
"analyzer": "standard",
"text": "hello world"
}
# 响应数据
{
"tokens": [
{
"token": "hello",
"start_offset": 0,
"end_offset": 5,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "world",
"start_offset": 6,
"end_offset": 11,
"type": "<ALPHANUM>",
"position": 1
}
]
}
2.2、指定索引分词
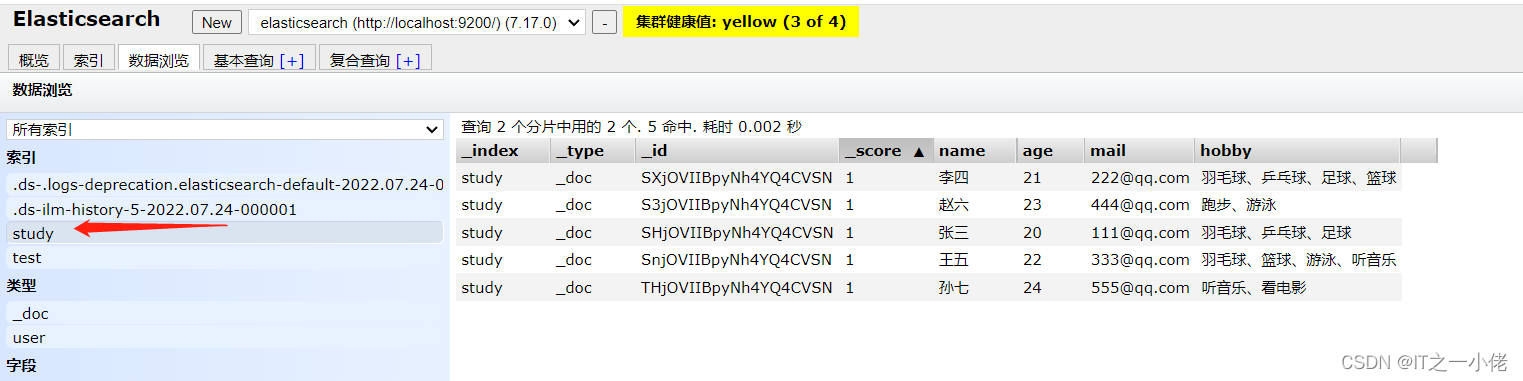
数据库中数据:
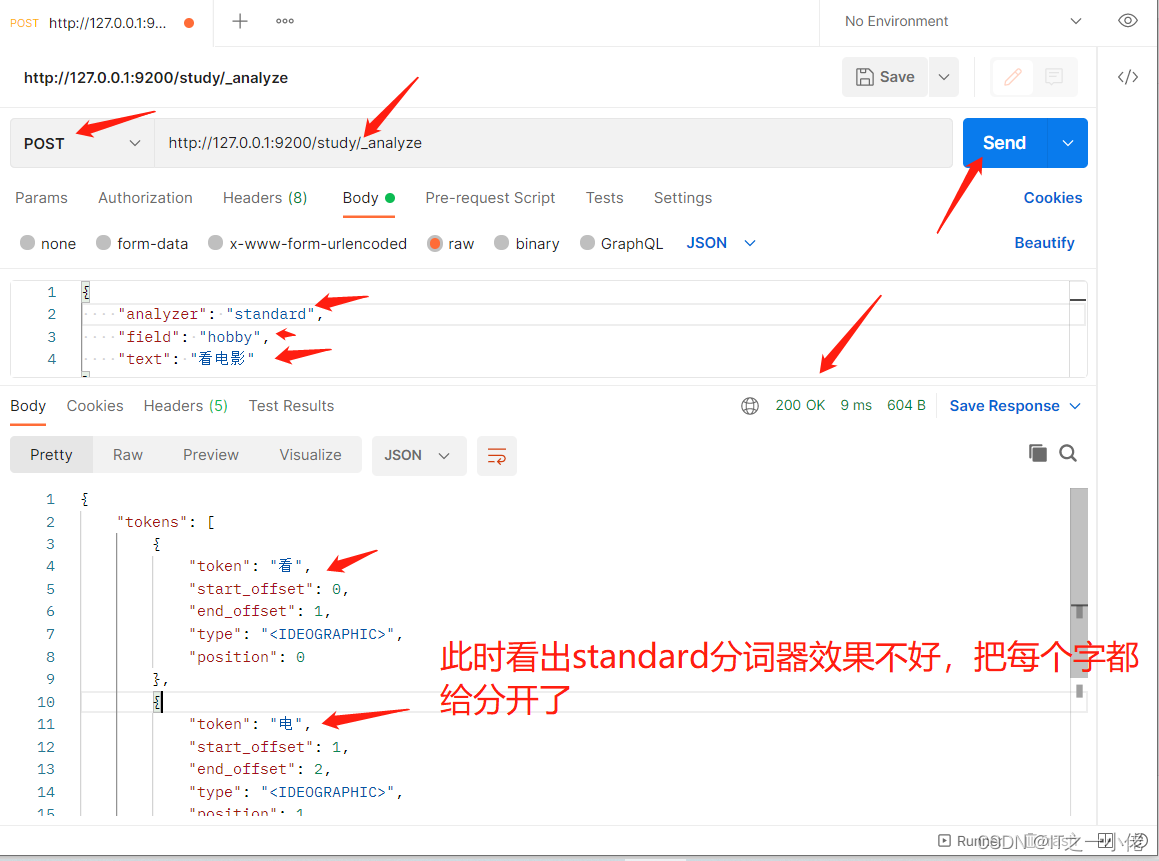
POST http://127.0.0.1:9200/study/_analyze
# 请求数据
{
"analyzer": "standard",
"field": "hobby",
"text": "看电影"
}
# 响应数据
{
"tokens": [
{
"token": "看",
"start_offset": 0,
"end_offset": 1,
"type": "<IDEOGRAPHIC>",
"position": 0
},
{
"token": "电",
"start_offset": 1,
"end_offset": 2,
"type": "<IDEOGRAPHIC>",
"position": 1
},
{
"token": "影",
"start_offset": 2,
"end_offset": 3,
"type": "<IDEOGRAPHIC>",
"position": 2
}
]
}
2.3、中文分词
英语以空格作为分隔符,中文分词没有明显的词汇分界点,如果分隔不正确就会造成歧义。
如: 我/爱/炖排骨 我/爱/炖/排骨
常用中文分词器,IK、jieba、THULAC等。
IK Analyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。IK采用了特有的“正向迭代最细粒度切分算法“,具有80万字/秒的高速处理能力,采用了多子处理器分析模式,支持:英文字母(IP地址、Email、URL)、数字(日期,常用中文数量词,罗马数字,科学计数法),中文词汇 (姓名、地名处理)等分词处理。 优化的词典存储,更小的内存占用。
IK分词器 Elasticsearch插件地址:GitHub - medcl/elasticsearch-analysis-ik: The IK Analysis plugin integrates Lucene IK analyzer into elasticsearch, support customized dictionary.
IK中文分词器的安装方法:
注意:IK分词器插件要与ES版本保持一致:Releases · medcl/elasticsearch-analysis-ik · GitHub
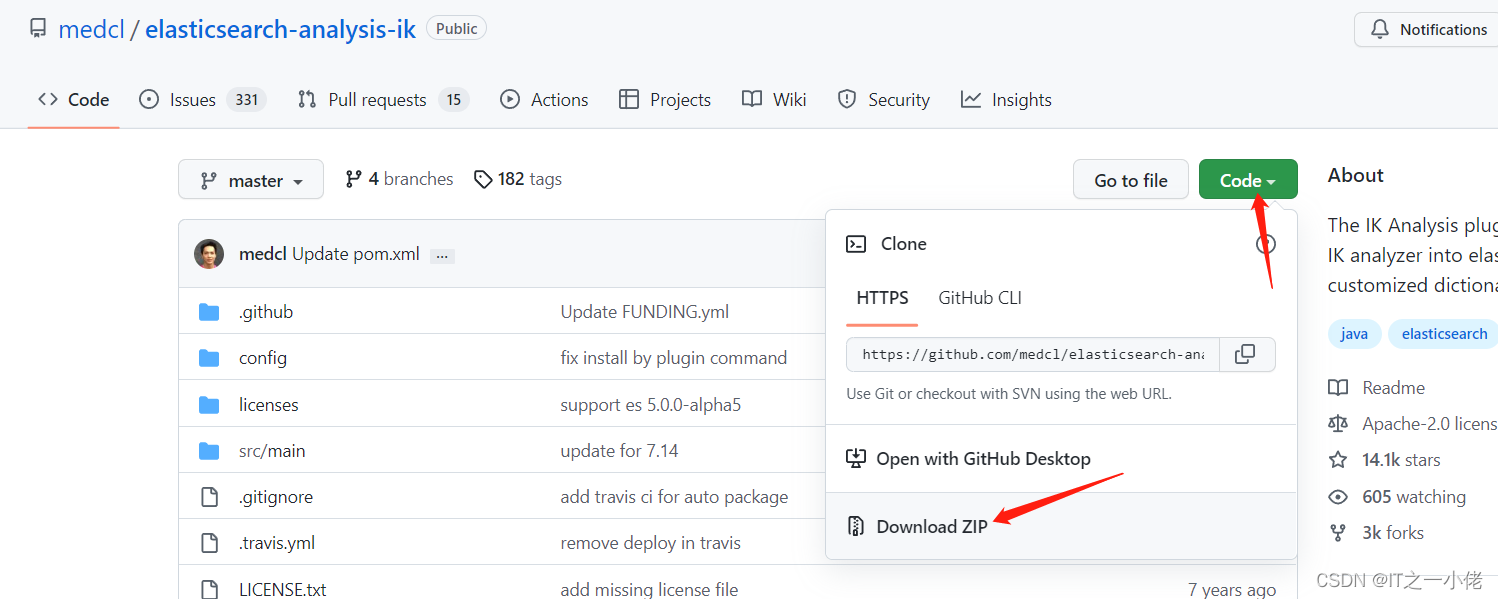
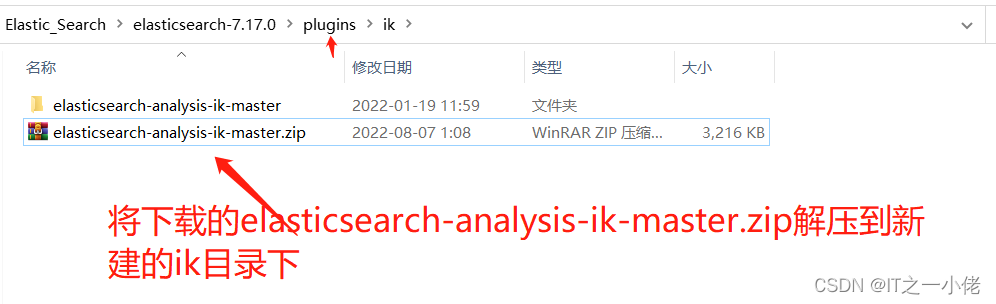
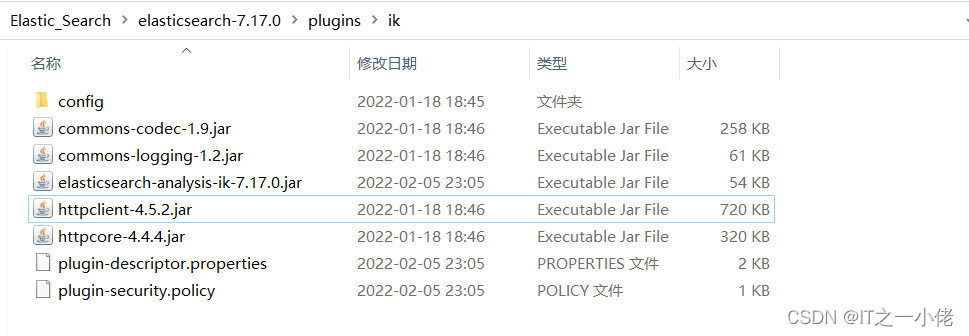
然后重新启动elasticsearch程序服务。

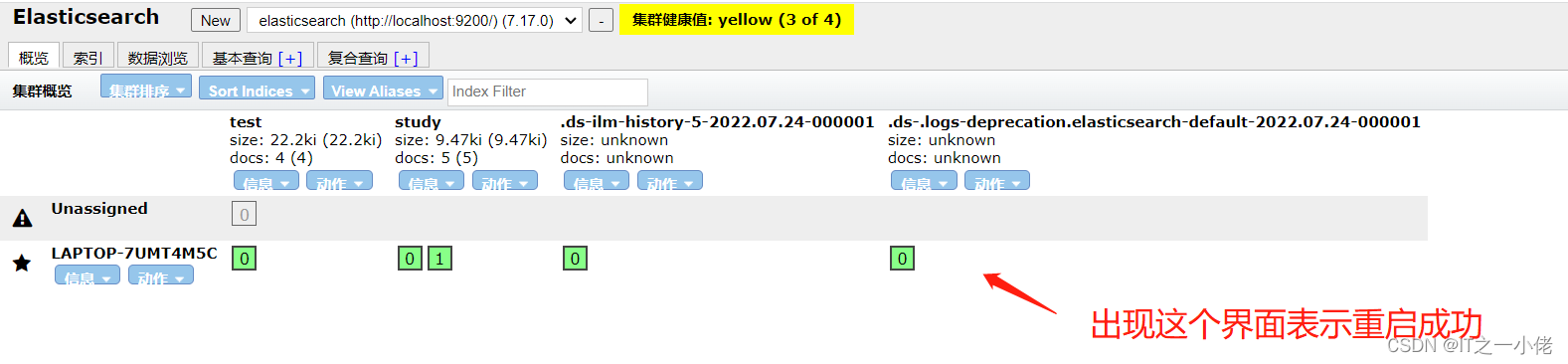 此时安装完成IK中文分词器后,再次重新分词上面代码中的数据:
此时安装完成IK中文分词器后,再次重新分词上面代码中的数据:
POST http://127.0.0.1:9200/_analyze
# 请求数据
{
"analyzer": "ik_max_word",
"text": "我是好学生"
}
# 响应数据
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "是",
"start_offset": 1,
"end_offset": 2,
"type": "CN_CHAR",
"position": 1
},
{
"token": "好学生",
"start_offset": 2,
"end_offset": 5,
"type": "CN_WORD",
"position": 2
},
{
"token": "好学",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 3
},
{
"token": "学生",
"start_offset": 3,
"end_offset": 5,
"type": "CN_WORD",
"position": 4
}
]
}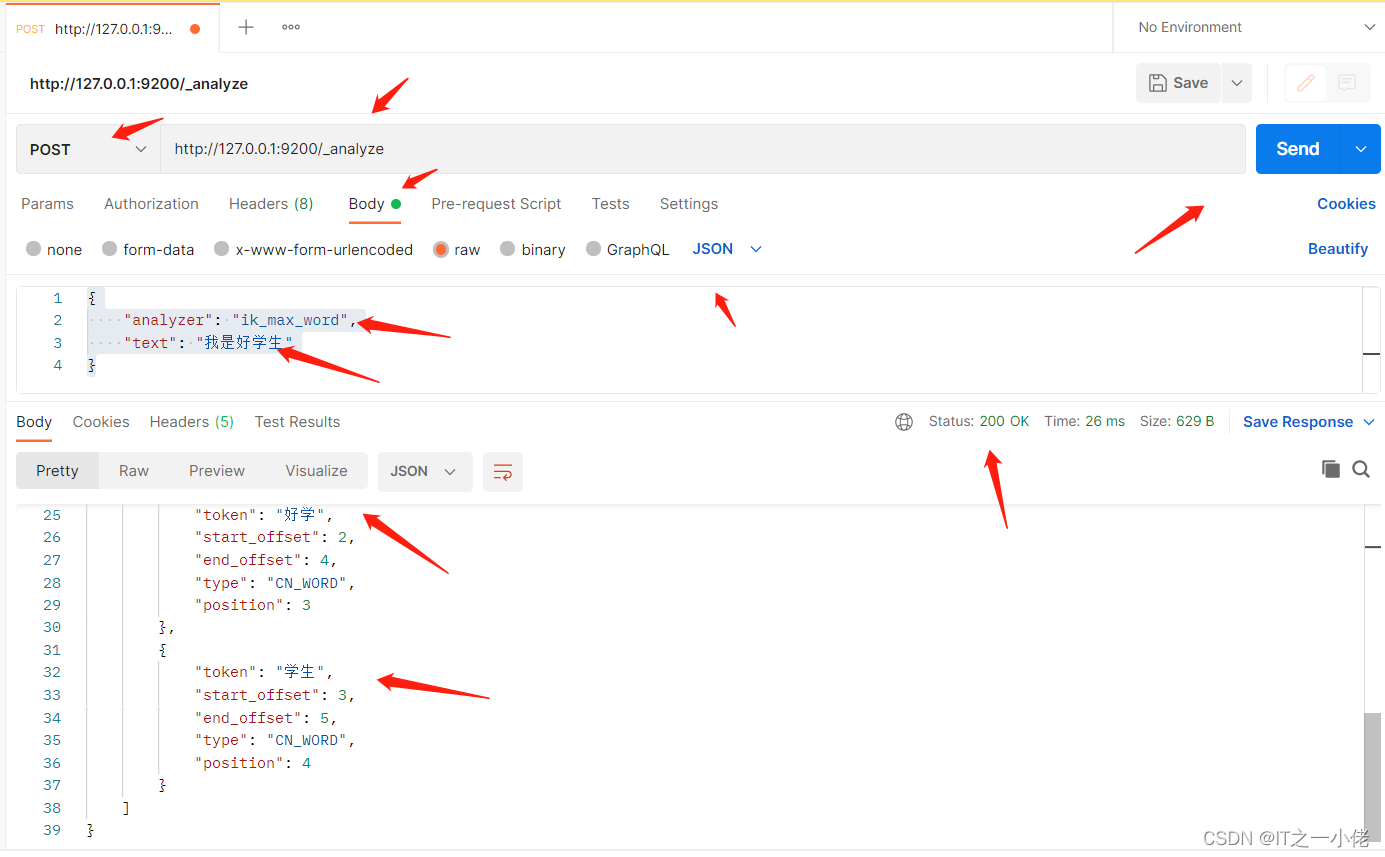
通过上面测试结果可以看出,对中文进行了较好的分词。
参考博文:















 1577
1577











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









