







HDFS可以支持海量的数据存储
但是,无法支持海量数据的随机读写!!
2006年12月,Google发布了其云计算技术的第三篇著名论文《Bigtable: A Distributed Storage System for Structured Data》
是Bigtable的开源实现,第一个可用版本于2007诞生
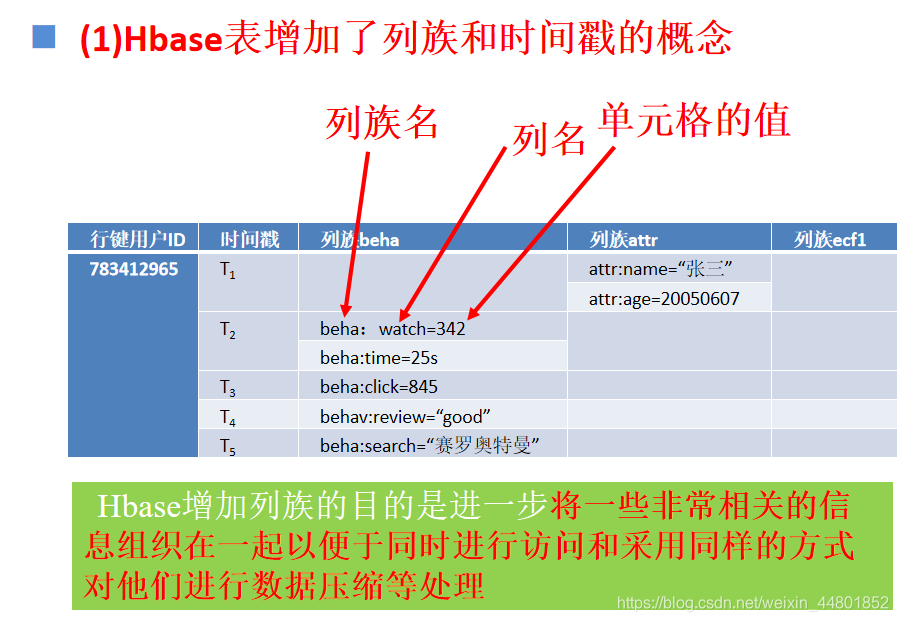
Hadoop的重要分支,是建立在HDFS之上的一个分布式、面向列的开源数据库系统
具有高可靠性、高性能、列存储、可伸缩、实时读写等重要特征
文件系统
最常见的数据存储方式
文件都是由某个具体的应用所产生和修改,不同文件存储信息的格式还可能不同,造成文件系统所存储的信息的共享性比较差
数据库
长期存储在计算机内、有组织可共享的数据集合
数据库系统
建立在文件系统之上,包含了数据库以及对数据库进行科学组织、高效访问和维护的数据库管理系统在内的软件系统
数据库中的数据按统一的数学模型组织、描述和存储,具有较小的冗余,并且通过在应用程序和数据库之间加入数据库管理系统,实现了数据与应用程序的分离
数据库系统中的数据具有较高的独立性和易扩展性,可为各种用户共享,并能够提供高安全的并发访问
关系数据库系统
支持关系模型的数据库系统,通过集合、代数等数学运算来对数据库中的数据进行处理
关系模型
是指用二维表的形式表示实体和实体间联系的数据模型。
SQL语言
常见关系型数据库系统均使用SQL用于创建和删除数据库、增加修改更新和删除数据库中的数据
供结构化查询语言,非过程化编程语言
使得具有完全不同底层结构的不同数据库系统,可以使用相同的结构化查询语言作为数据输入与管理的接口
关系数据库系统处理海量数据存在的问题
可扩展性差,无法较好的支持海量数据的存储
难以支持海量数据的高并发读写访问
NoSQL数据库系统
NoSQL数据库系统是对非关系型数据库系统的统称
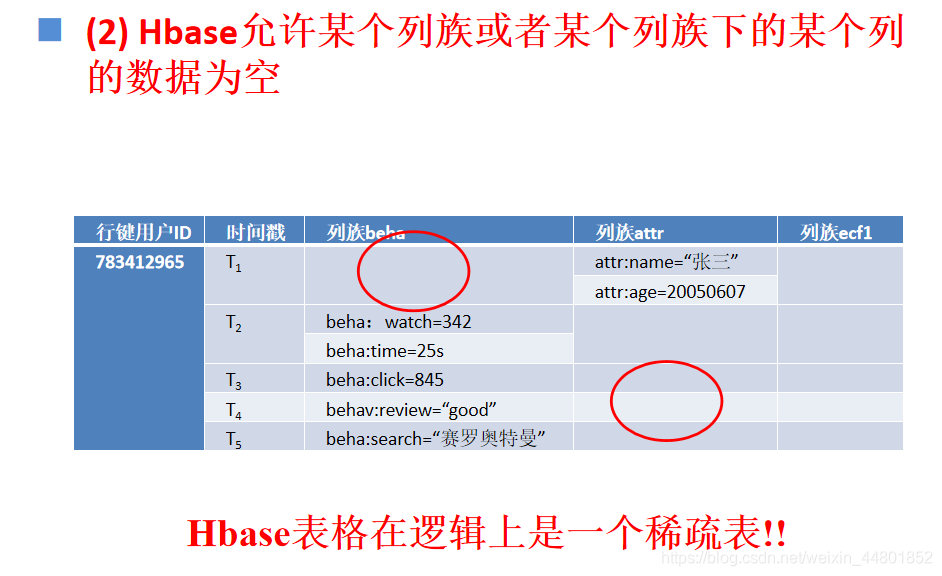
不支持关系模型,而是以键值对、文档等非关系型模型来组织和管理数据
没有固定的表结构,放松了对数据库事务具有原子性、一致性、隔离性和持续性的约束
普遍具有较好的扩展性,从而能够支持海量数据的存储管理
mongdb、Hbase等均是NoSQL数据库系统
Hbase数据库系统
一种NoSQL数据库系统
不支持SQL查询语言,也缺乏了传统关系型数据库所具有的特性和遵循的机制
借鉴了谷歌的BigTable的设计,并通过Java语言进行开发,是BigTable的开源实现
提供面向列、可伸缩的分布式存储
运行于HDFS之上,是Hadoop的重要组件
解决了HDFS只适合于批量访问不能随机访问的问题
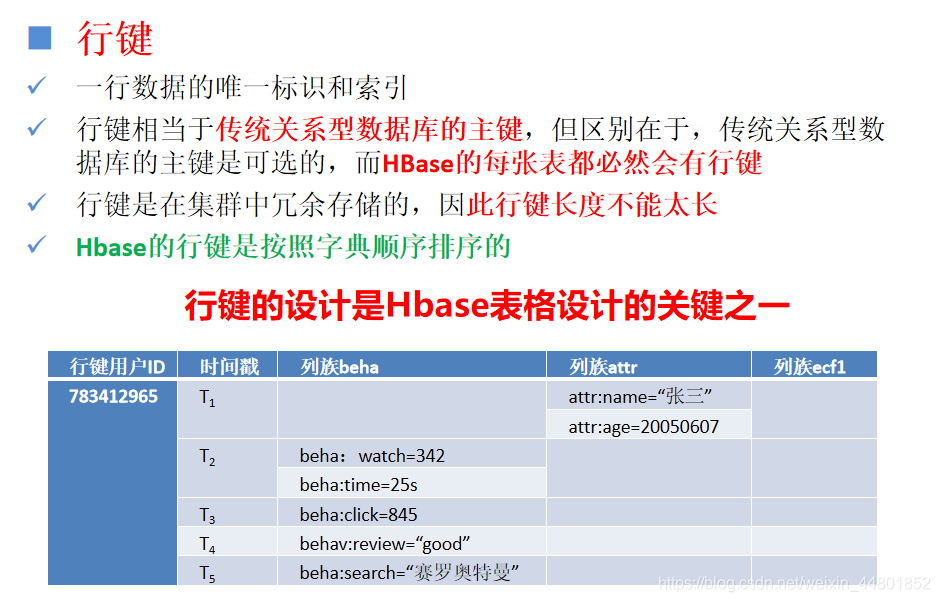
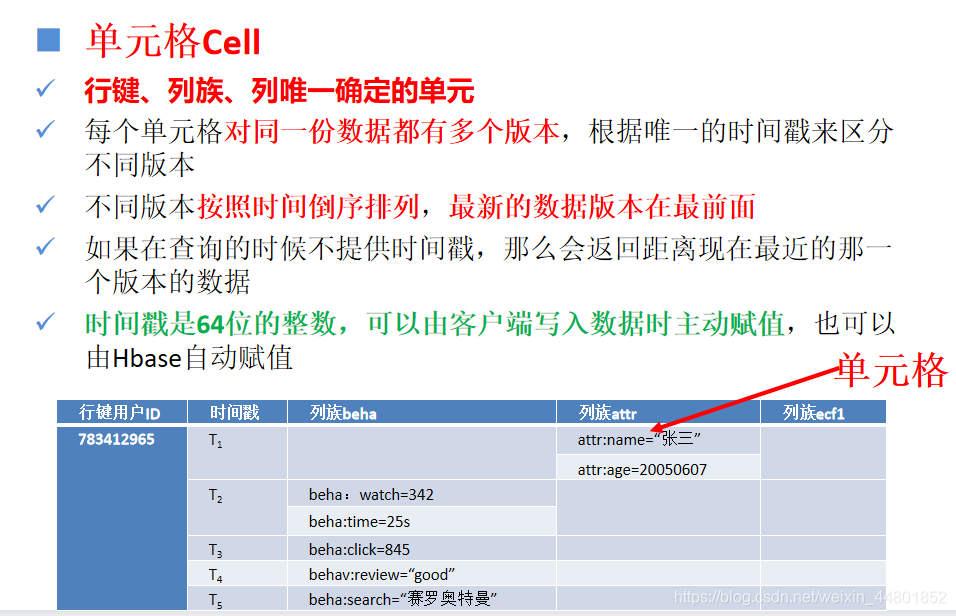
逻辑视图
反映数据逻辑上的组织结构
逻辑结构便于人们理解
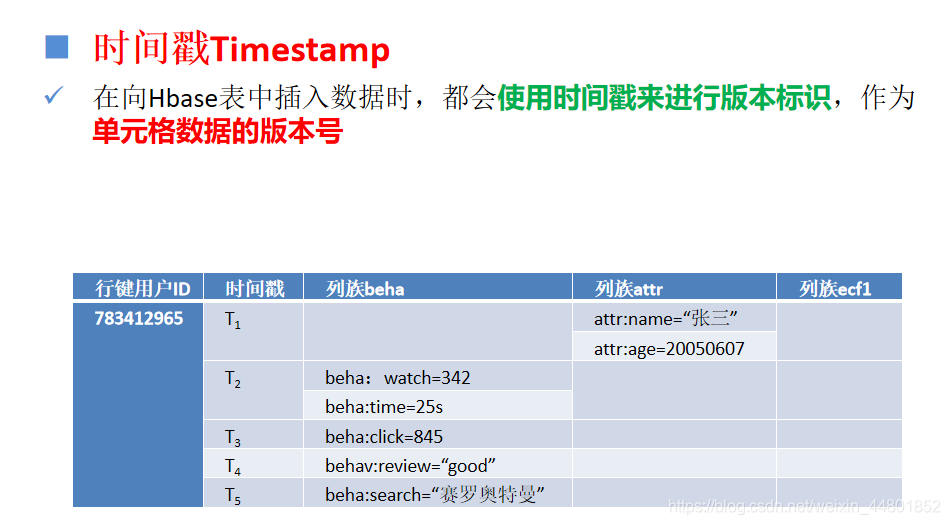
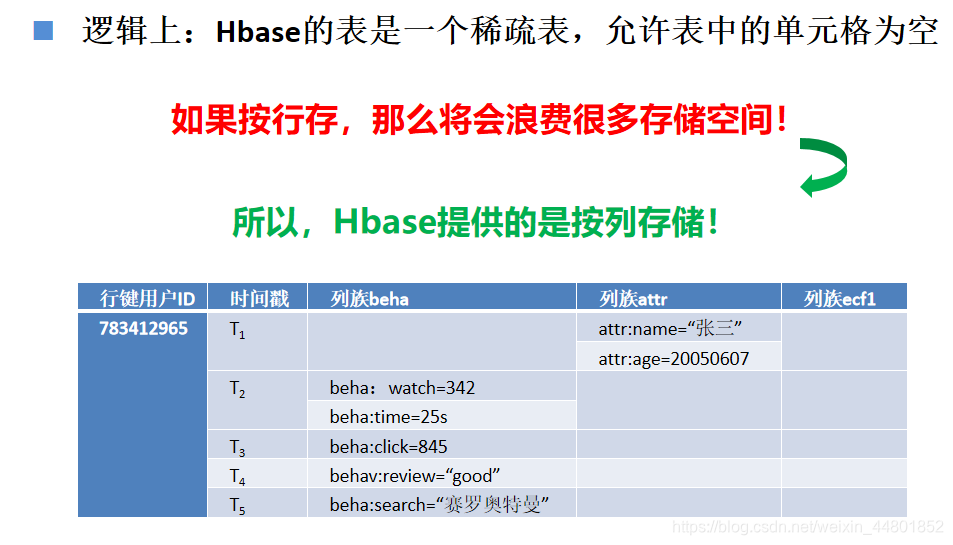
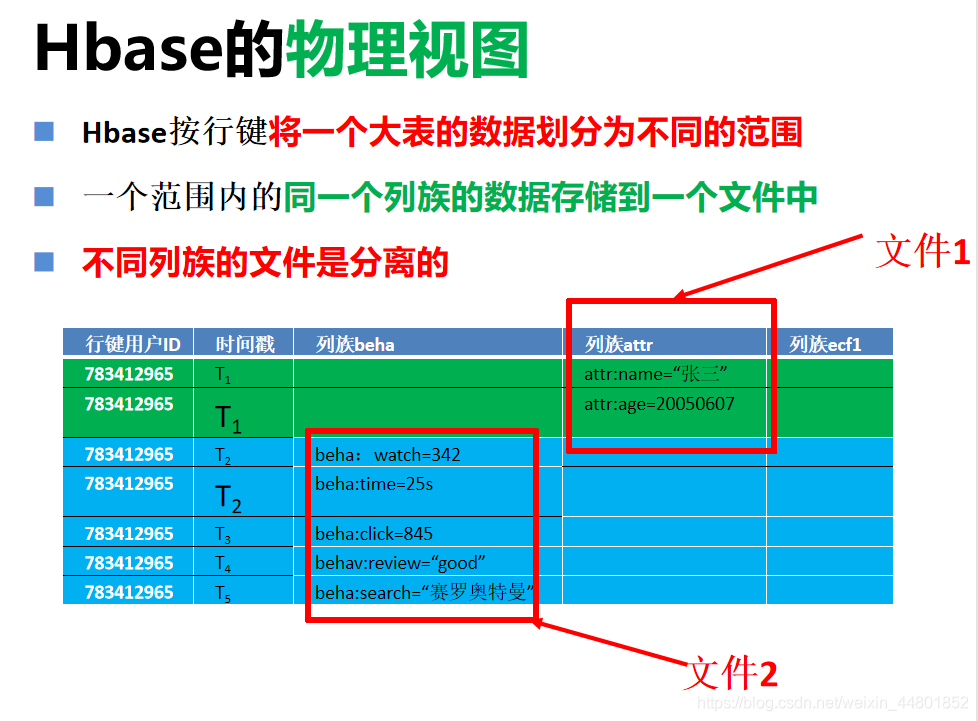
物理视图
反映数据的存储结构



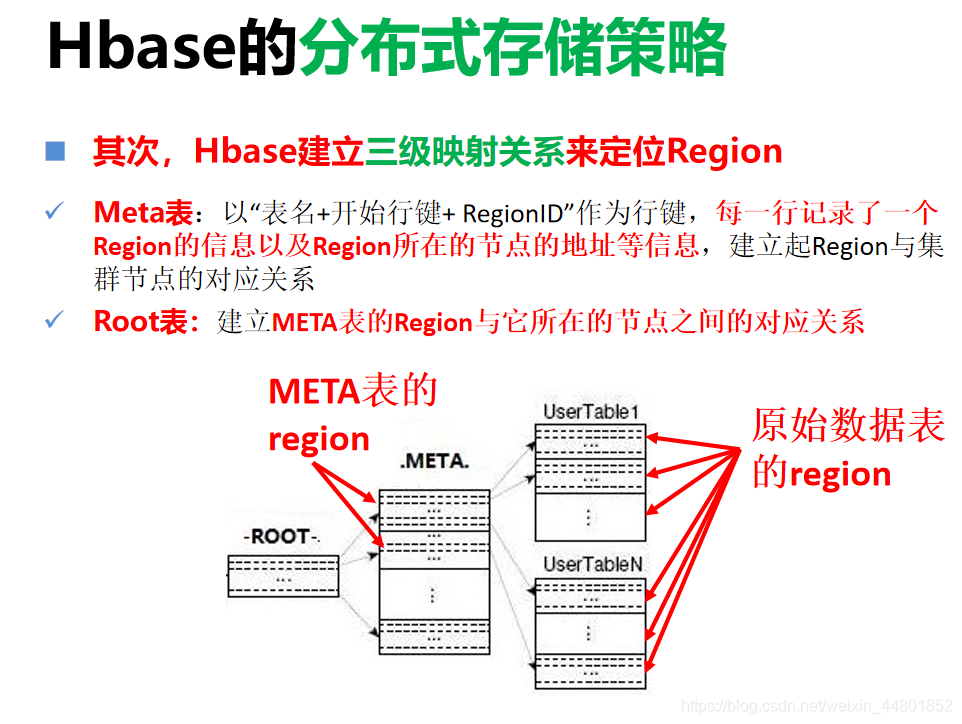
最后,基于META表与root表的数据访问
首先,获取ROOT表的位置,从ROOT表中获取对应的META表的Region以及该Region所在节点
然后,从相应节点上访问META表,获取要访问的Region所在的节点
在获得Region所在的节点位置之后,用户通过客户端直接与数据所在的节点连接来读写数据,整个过程不需要连接集群的主节点,减少了主节点的负载压力。
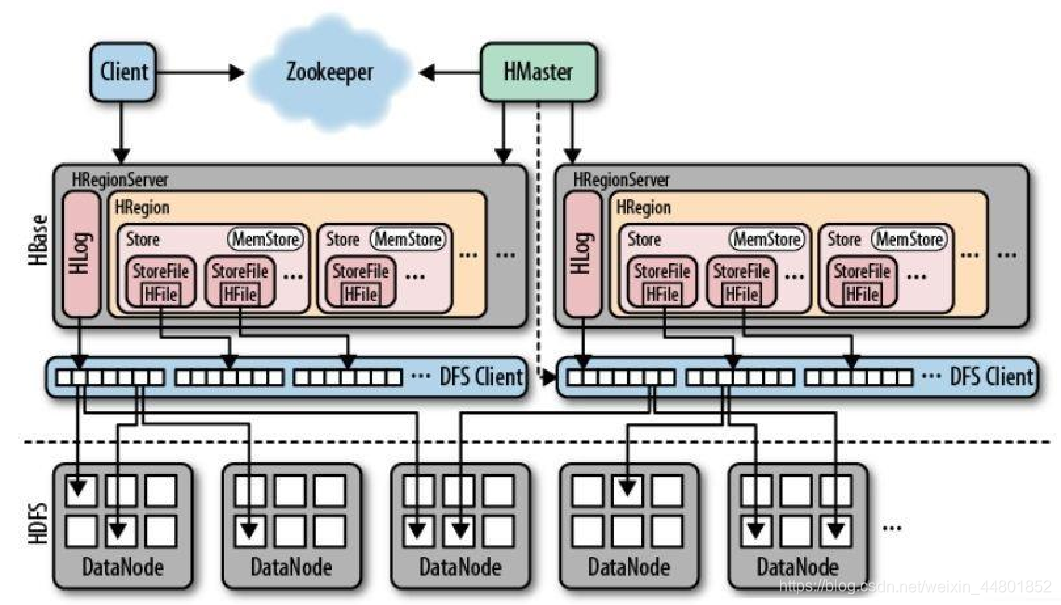
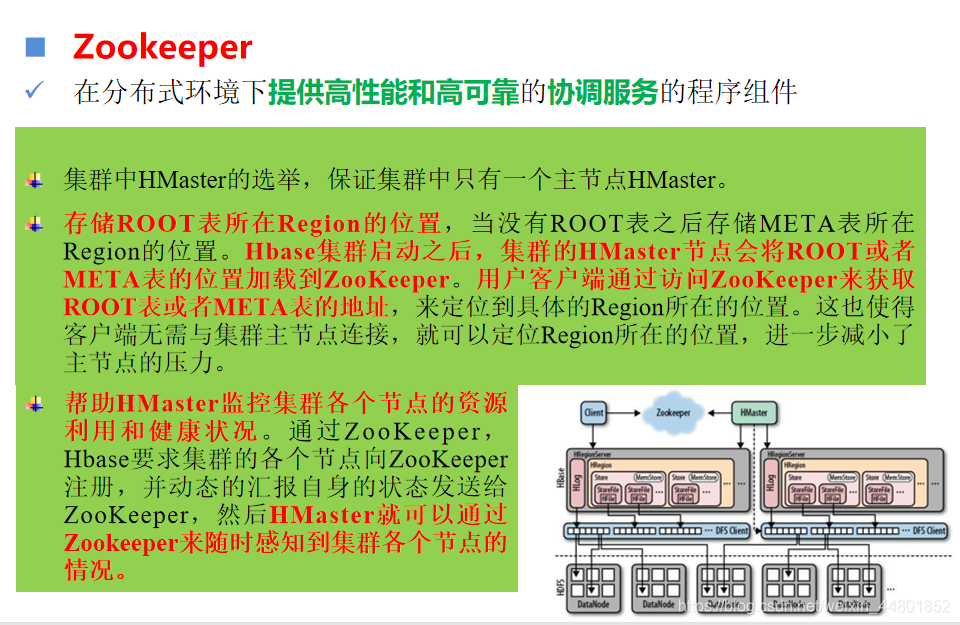
Hmaster
分配Region到集群的各个HRegionServer
监控各个HRegionServer的状况,调整Region的分布实现负载均衡,发现失效的HRegionServer并重新分配其上的Region
维护ROOT表和META表,记录各个HRegionServer上Region的变化信息
管理用户对建表和对表进行变更的操作
HRegionServer
分布式集群中单个计算节点上负责管理本地存储的Region的进程
HRegionServer与Zookeeper交互,定期上传节点的负载状况,比如节点的内存使用状态、在线状态的Region等信息。
当用户定位到HRegionServer所管理的Region时,HRegionServer负责与用户客户端连接来提供对数据的读写访问。
—————————————————————————————
1)数据在节点的写入和存储
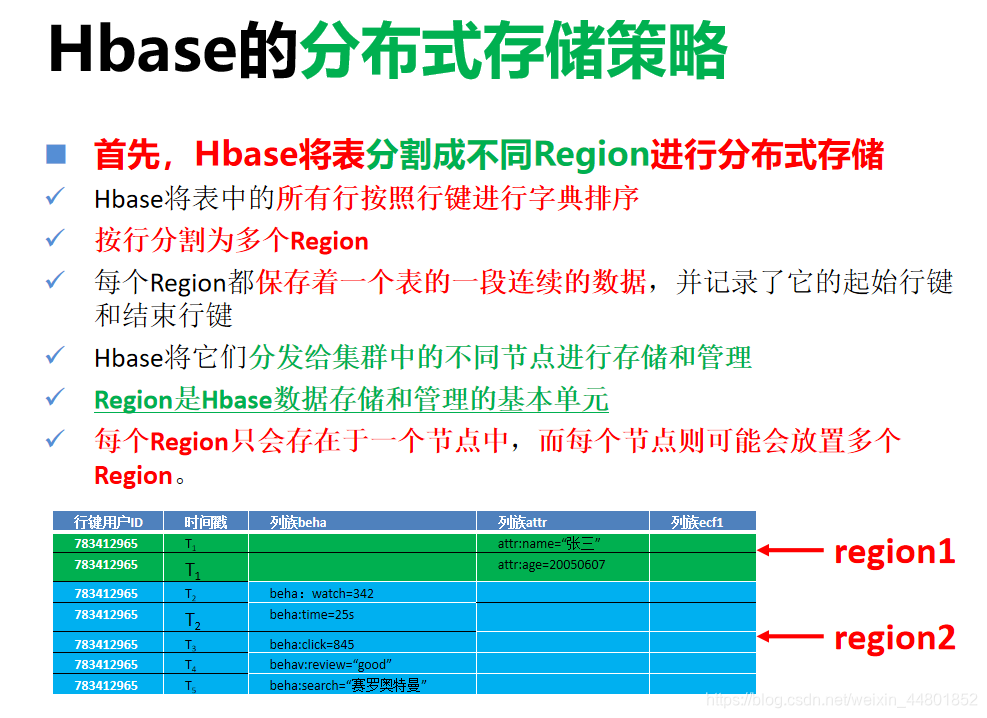
虽然Region是Hbase中分布式存储和负载均衡的最小单元,但是Region却不是存储的最小单元
在进行存储时,每个Region由一个或者多个Store组成,每个Store存储该Region一个列族的所有键值对数据
每个Strore又由一个memStore和0至多个StoreFile组成
memStore是内存缓存中的文件,StoreFile是磁盘中的文件
用户写入数据时数据首先会放在缓存的memStore中,当memStore满了以后会写入磁盘形成一个StoreFile进行持久化
因为写入缓存,所以Hbase写入数据的速度会非常快!

(3)Region的分裂
StoreFile的不断合并最终会形成一个非常大的StoreFile。
当StoreFile大到一定程度便会触发其所在的Region的分裂成两个新的Region
新的Region会被HMaster重新分配到相应的节点上,而老的Region就会下线
(4)写操作的日志记录
每个HRegionServer有一个日志记录对象Hlog
一个HRegionServer下的所有Region共享一个Hlog对象
写入memStore的数据必须首先写入到Hlog的文件
Hlog文件会定期的更新,删除已经写入磁盘的数据
当一个HRegionServer意外终止之后:
HMaster会将相应节点上的Hlog数据进行拆分
提取属于不同Region的数据
然后再将失效的Region的进行重新分配,并把属于失效Region的Hlog数据也发送给新节点的HRegionServer
(5)数据的查找与读取
每个HRegionServer存在一个缓存区域供数据的读取操作
当客户端定位到HRegionServer下的某个Region并发起数据读取请求时,HRegionServer首先根据行键查询读缓存中是否有需要读取的数据,如果没有则进入磁盘到的Hfile中进行查找















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









