







 本文介绍了Python数据分析的基础,通过NumPy和Pandas库进行数据探索。NumPy提供数学函数和优化的数组操作,Pandas则提供DataFrame结构便于数据处理。在Jupyter Notebook中,使用Pandas进行数据过滤、切片、缺失值处理和聚合分析,展示了数据分析的流程和方法。
本文介绍了Python数据分析的基础,通过NumPy和Pandas库进行数据探索。NumPy提供数学函数和优化的数组操作,Pandas则提供DataFrame结构便于数据处理。在Jupyter Notebook中,使用Pandas进行数据过滤、切片、缺失值处理和聚合分析,展示了数据分析的流程和方法。
在几十年的开源开发后,Python 通过强大的统计和数值库提供丰富的功能:
- NumPy 和 Pandas 简化了数据分析和操作
- Matplotlib 提供引人注目的数据可视化效果
- Scikit-learn 提供简单有效的预测性数据分析
- TensorFlow 和 PyTorch 提供机器学习和深度学习功能
利用 NumPy 和 Pandas 浏览数据
数据科学家可以使用各种工具和技术来浏览、直观呈现和操作数据。 数据科学家处理数据最常用的方法之一是使用 Python 语言和一些特定的数据处理包。
什么是 NumPy
NumPy 是一个 Python 库,提供与 MATLAB 和 R 等数学工具相当的功能。尽管 NumPy 大大简化了用户体验,但它还提供了全面的数学函数。
什么是 Pandas
Pandas 是一个极其热门的 Python 库,用于数据分析和操作。 Pandas 对于 Python 而言就像 excel,提供适用于数据表的易于使用的功能。
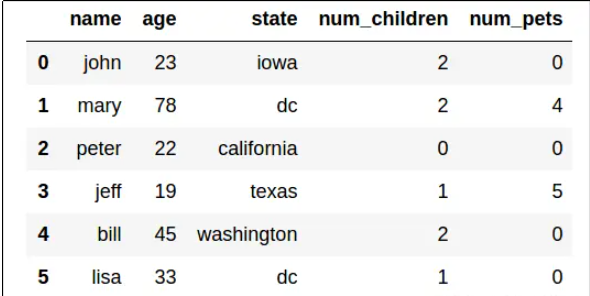
探索 Jupyter 笔记本中的数据
Jupyter Notebook 是使用 Web 浏览器运行基本脚本的一种常用方式。 通常,这些笔记本都是单个网页,分解为在服务器上(而不是本地计算机)上执行的文本部分和代码部分。 这意味着你可以快速开始,而无需安装 Python 或其他工具。
测试假设
数据探索和分析通常是一个迭代过程,数据科学家在其中进行数据采样,并执行以下任务来分析数据和检验假设:
- 清理数据以处理错误、缺失值和其他问题。
- 应用统计技术来更好地理解数据,更好地了解样本如何预期地代表真实世界的总体数据(允许随机变化)。
- 直观呈现数据来确定变量之间的关系,在机器学习项目中,识别可能预测标签的特征。
- 修正假设并重复这个过程。
使用NumPy探索数据数组
让我们先看一些简单的数据。
假设一所大学收集了一门数据科学课程的学生成绩样本。
data = [50,50,47,97,49,3,53,42,26,74,82,62,37,15,70,27,36,35,48,52,63,64]
print(data)
数据已加载到Python列表结构中,这是用于一般数据操作的良好数据类型,但对于数值分析没有进行优化。为此,我们将使用NumPy包,它包括在Python中使用Numbers的特定数据类型和函数。
import numpy as np
grades = np.array(data)
print(grades)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 953
953











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









