







 本文围绕大语言模型展开,介绍了PaLM2的特点、商务场景及应用平台。阐述提示词工程,包含设计方法、基础与进阶提示词。讲解微调模型的方式,如few-shot、full-fine-tuning等,还提及基于强化学习的微调。最后展望了大语言模型在文本、代码生成等方面的创新应用。
本文围绕大语言模型展开,介绍了PaLM2的特点、商务场景及应用平台。阐述提示词工程,包含设计方法、基础与进阶提示词。讲解微调模型的方式,如few-shot、full-fine-tuning等,还提及基于强化学习的微调。最后展望了大语言模型在文本、代码生成等方面的创新应用。
📸背景
因长期在大模型相关的部门工作,每天接收到很多和AI相关的信息,但小编意识到目前理解到的一些AI知识还有些片面。
恰逢稀土掘金开发者大会有谈到大模型相关的知识,于是借此机会,对大模型相关的一些知识再了解一波~
以下文章是对 大模型与AIGC分论坛 第一部分的整理与归纳。
一、💡大语言模型及PaLM2介绍
1、大语言模型可以做什么
下面先来说说,我们在用大语言模型可以干些什么。
(1)常见使用场景
- 娱乐 —— 游戏公司用大语言模型做
NPC的输出,让NPC能够跟我们自然地对话。(NPC指的是非玩家对话) - 工作助理 —— 帮我们执行任务,通过不同的方式去搜索、去计算,去执行一些业务的交易。
- 知识库 —— 可以作为一些自有的知识库,或者结合企业内部的知识库,去海量的知识中帮助我们检索有用的信息,帮助我们去更好地完成工作。

(2)LLM → LDM
我们说大语言模型是LLM,但实际上也可以说它是LDM,也就是让语言驱使大模型去完成我们一些实际上的任务。
比如: ①类似siri,用语言控制AI做事;②描述画图场景,让AI帮我们画出想要的图形。③……

(3)加快原型设计
除此之外,大语言模型可以极大得加快我们的工作速度,让我们的工作更集中于创意和想法,而不是琐碎的重复工作。比如说:我们在写一篇文章,里面有一块内容需要用到一张柱状图。
如果是传统的方法,我们需要去打开画图软件,一线一点的画出来。而如果把这个“画柱状图”的事情,交给大语言模型来处理,只需简单几句话,就让LLM帮我们把图画出来。这样,就能让我们把精力都专注于创意和想法,减少很大一部份的机械性工作和重复工作。

2、PaLM2的纸短情长
那么用什么工具来加快原型设计呢,这里就谈到了PaLM2。
(1)PaLM 2
- LLM ——
PaLM 2是google最新的通用大语言模型,全称为Pathways Language Model。 - 540-billion —— 这意味着
PaLM2模型是一个非常大的模型,具有5400亿的参数。参数的数量通常与模型的复杂性和能力成正比。更多的参数意味着模型可以学习和存储更多的信息,但同时也需要更多的数据和计算资源来训练。 - 稠密的纯解码器Transformer结构 ——
Transformer是一种深度学习模型架构,广泛用于自然语言处理任务。"稠密的解码器"意味着Transformer架构中,解码器部分是稠密连接的,这有助于模型更好地处理和生成文本。 - 基于
Pathways系统来训练 —— Pathways系统是Google用于训练其大型模型的新系统或框架,而PaLM2,就基于这个系统来进行训练。
(2)PaLM2对外商务场景
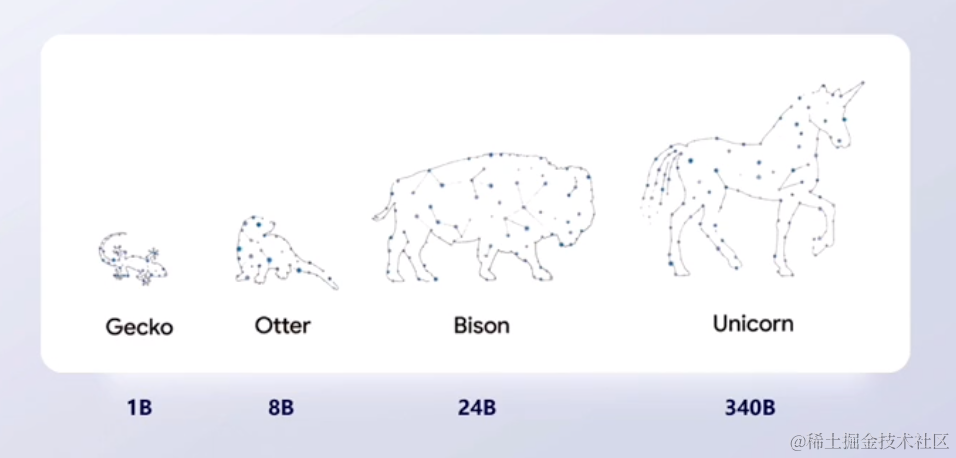
对外提供商务场景有4种不同的版本:
- Gecko —— 壁虎模型,只有
1B的参数,它更多的是在移动设备上进行应用,比如在手机上做文本的生成。 - Otter —— 水獭模型,具有
8B的参数。 - Bison —— 野牛模型,
Bison是目前google对外商用的主流模型,具有24B的参数。目前Google Cloud以及developer,都是通过Bison,来提供文本生成、对话交流等任务。 - Unicom —— 独角兽模型,具有
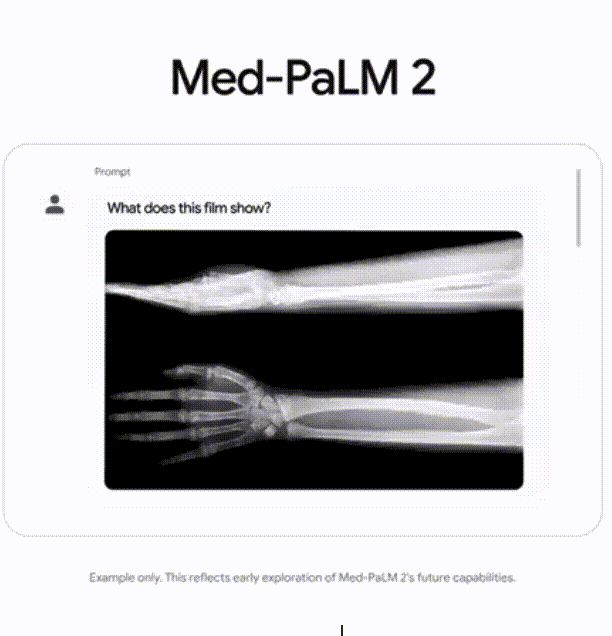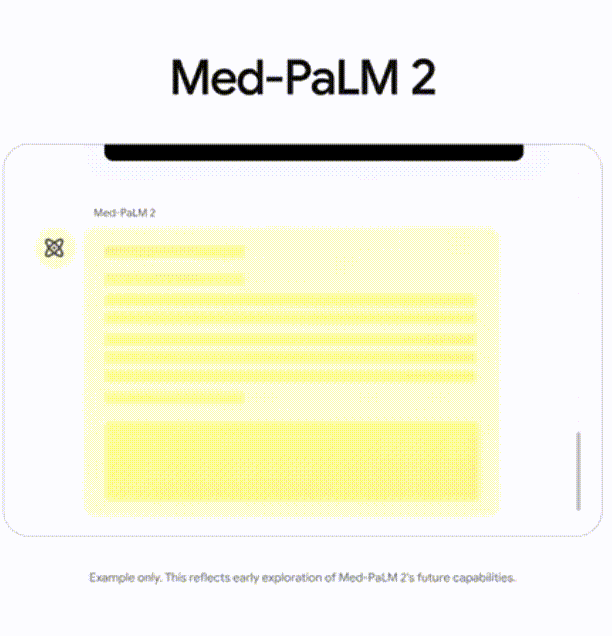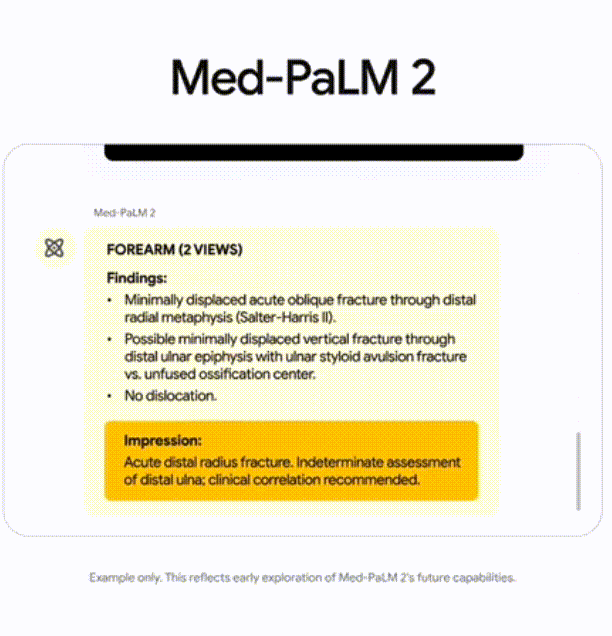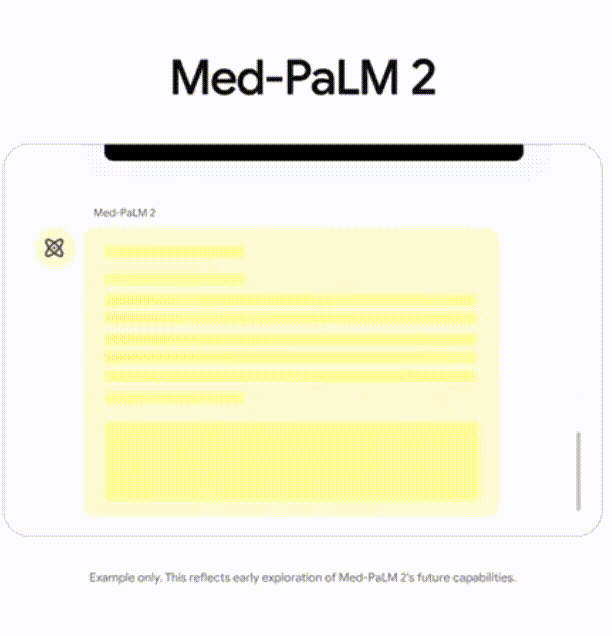
340B参数。像是一些专有领域的模型,比如下方第二张图:Med-PaLM2。它是医疗领域的一个知识问答库。像这样的专有领域的场景,就会使用最大的独角兽模型,来提供支持
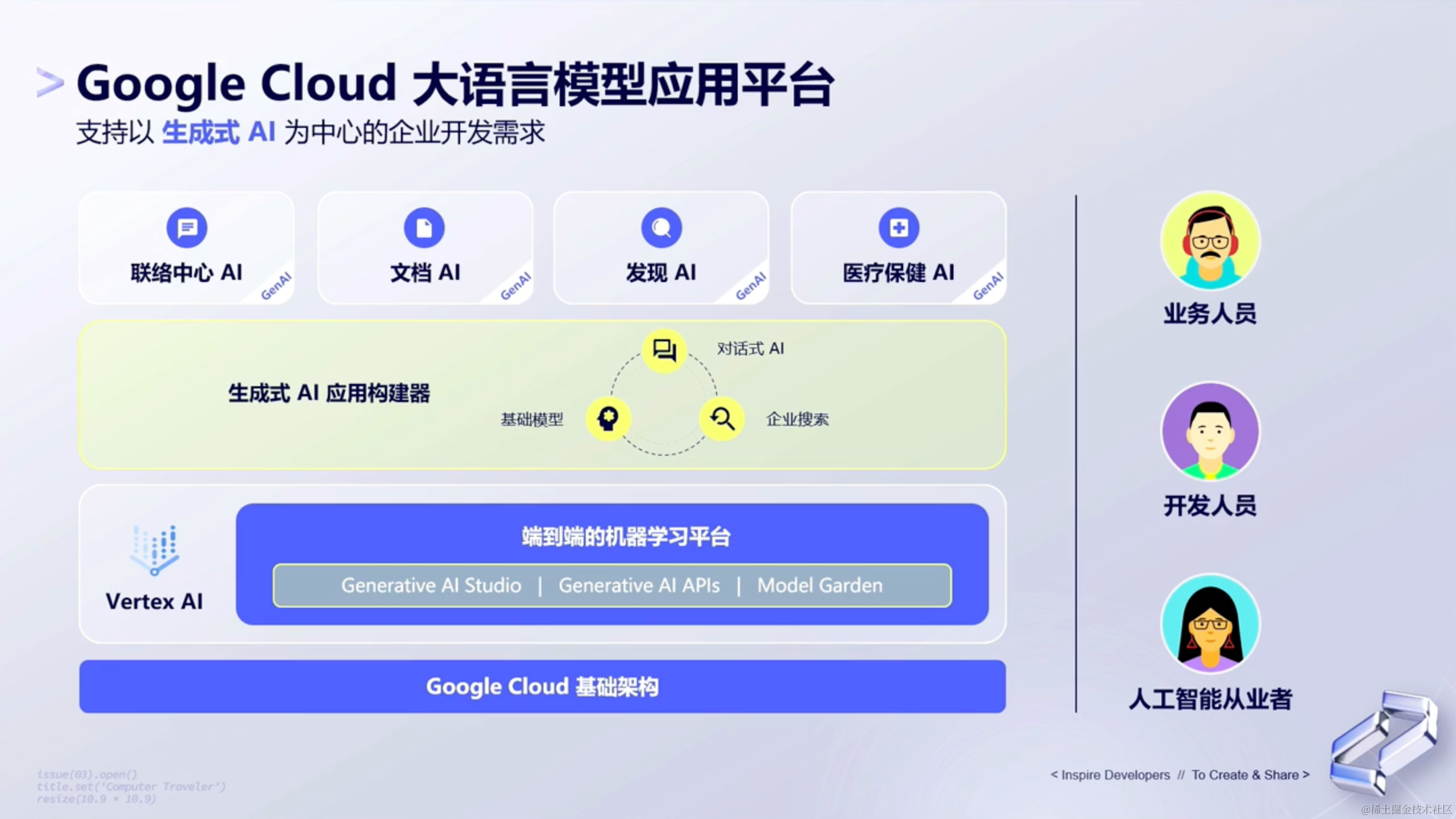
(2)Google Cloud 大语言模型应用平台
对于大语言模型来说,Google通过Google Cloud这样的一个平台,来提供大语言模型的对外商务能力。
这个平台支持从最底层的基础架构(为人工智能从业者服务)到顶层的模型应用(为业务人员服务),针对不同的人群,提供不同的服务。
(3)Generative AI Studio
而对于PaLM2来说,通过Google Cloud中的Generative AI Studio工具,来提供一些PaLM2对外的商业能力。那PaLM2都提供了哪些对外的商业能力呢?如下图所示:

二、📟提示词工程
1、模型类别
模型类别分为三种,如下图所示:

对于上面这三种模型来说,通用语言模型、指令微调模型和对话微调模型是基于相似的基础模型,但它们在微调和使用方式上有所不同,那它们之间的主要区别是什么区别呢?如下所示:
通用语言模型 (GPT):
- 这是一个预训练的模型,它可以生成连贯的文本。
- 它没有经过特定任务的微调。
- 用户可以直接输入文本,模型会返回生成的文本。
指令微调模型:
- 这个模型是在通用语言模型的基础上,经过特定任务的微调得到的。
- 用户需要给模型一个明确的指令,例如“翻译以下文本到法语”。
- 模型会根据给定的指令执行特定的任务。
对话微调模型:
- 这也是一个经过特定任务微调的模型,但它是为对话设计的。
- 用户可以与模型进行交互式对话。
- 模型会记住对话的上下文,从而更好地回应用户。
总的来说,这三种模型都是基于相同的基础模型,但它们在微调和交互方式上有所不同。指令微调模型和对话微调模型都是为了更好地完成特定任务而进行的微调,而通用语言模型则更加通用。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









