







基于逻辑回归和xgboost算法的信用卡欺诈检测
认识数据
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import sklearn as sklearn
import xgboost as xgb #xgboost
from imblearn.over_sampling import SMOTE
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import confusion_matrix
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier ##随机森林
data = pd.read_csv("E:/creditcard.csv")
data.head()
本文数据样本来源于2013年9月欧洲持卡人在两天内进行的284808笔信用卡交易,其中有493笔欺诈交易。由于保密问题,只包含作为PCA转化结果的数字输入变量,特征V1,V2,… V28是使用PCA获得的主要组件,交易金额是常量,是否欺诈(class)是分类变量。


data.groupby('Class').size()
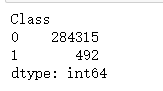
count_classess = pd.value_counts(data['Class'],sort=True)
count_classess.plot(kind = 'bar')
plt.title('Fraud class histogram')
plt.xlabel('Class')
plt.ylabel('Frequency')

分类为1 的数据量非常少,可以看出数据量非常不平衡。
数据规范化
观察数据可知,由于数据除交易金额(Amount)和是否欺诈(class)外,其他变量已经过PAC处理,由于交易金额过于分散,对amount进行数据规范化处理后得到列nomAmount。
from sklearn.preprocessing import StandardScaler
#StandardScaler作用:去均值和方差归一化。且是针对每一个特征维度来做的,而不是针对样本。
data['normAmount'] = StandardScaler().fit_transform(data['Amount'].values.reshape(-1, 1))
data = data.drop(['Time','Amount'],axis=1)
data.head()

数据分组
在开始建模前对数据集进行划分,将数据集的80%作为训练集,20%作为测试集。即227454条数据为训练集,其他为测试集数据。利用训练集来训练模型,用测试集来验证构建的模型。同下方解决数据不平衡问题时一起分组,
SMOTE过采样算法
解决样本数据不平衡的问题
SMOTE(Synthetic Minority Oversampling Technique)即合成少数类过采样技术,它是基于随机过采样算法的一种改进方案,由于随机过采样简单复制样本的策略来增加少数类样本,这样容易产生模型过拟合的问题,使得模型学习的信息过于特别而不够泛化,SMOTE算法的基本思想是对少数类样本进行分析并根据少数类样本人工合成新样本添加到数据集中。
1、对于少数类中每一个样本x,以欧氏距离为标准计算它到少数类样本集中所有样本的距离,得到其k近邻。
2、根据样本不平衡比例设置一个采样比例以确定采样倍率N,对于每一个少数类样本x,从其k近邻中随机选择若干个样本,假设选择的近邻为xn。
3、对于每一个随机选出的近邻xn,分别与原样本按照如下的公式构建新的样本
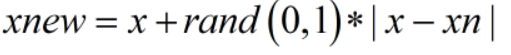

SMOTE算法的缺陷:该算法主要存在两方面的问题:一是在近邻选择时,存在一定的盲目性。从上面的算法流程可以看出,在算法执行过程中,需要确定K值,即选择多少个近邻样本,这需要用户自行解决。从K值的定义可以看出,K值的下限是M值(M值为从K个近邻中随机挑选出的近邻样本的个数,且有M< K),M的大小可以根据负类样本数量、正类样本数量和数据集最后需要达到的平衡率决定。但K值的上限没有办法确定,只能根据具体的数据集去反复测试。因此如何确定K值,才能使算法达到最优这是未知的。另外,该算法无法克服非平衡数据集的数据分布问题,容易产生分布边缘化问题。由于负类样本的分布决定了其可选择的近邻,如果一个负类样本处在负类样本集的分布边缘,则由此负类样本和相邻样本产生的“人造”样本也会处在这个边缘,且会越来越边缘化,从而模糊了正类样本和负类样本的边界,而且使边界变得越来越模糊。这种边界模糊性,虽然使数据集的平衡性得到了改善,但加大了分类算法进行分类的难度。
columns=data.columns
# 为了获得特征列,移除最后一列标签列
features_columns=columns.drop(['Class'])
features = data[features_columns]
labels=data['Class']
features_train, features_test, labels_train, labels_test = train_test_split(features, labels, test_size=0.2, random_state=0)
oversampler = SMOTE(random_state=0)
x_train,y_train = oversampler.fit_sample(features_train,labels_train)
print('SMOTE过采样后,训练集中1的样本的个数为:',len(y_train[y_train==1]))
print('SMOTE过采样后,训练集中0的样本的个数为:',len(y_train[y_train==0]))
x_test,y_test = oversampler.fit_sample(features_test,labels_test)
print('SMOTE过采样后,测试集1的样本的个数为:',len(y_test[y_test==1]))
print('SMOTE过采样后,测试集0的样本的个数为:',len(y_test[y_test==0]))
通过SMOTE过采样后,欺诈交易(class=1)和正常交易的数据量相等,解决了数据不平衡的问题

混淆矩阵
import itertools as itt
def plot_confusion_matrix(cm, classes,title='Confusion matrix',cmap=plt 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5419
5419











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









