







ES 既有基本的搜索功能、又有字段类型的精确搜索、分词匹配、范围搜索、坐标搜索、分页查询等等。
4.1 搜索辅助功能
俗话说“工欲善其事,必先利其器”。在介绍ES提供的各种搜索匹配功能之前,我们先介绍ES提供的各种搜索辅助功能。例如,为优化搜索性能,需要指定搜索结果返回一部分字段内容。为了更好地呈现结果,需要用到结果计数和分页功能;当遇到性能瓶颈时,需要剖析搜索各个环节的耗时;面对不符合预期的搜索结果时,需要分析各个文档的评分细节
4.1.1指定返回的字段
考虑性能问题,需要对搜索进行瘦身。所以需要返回指定的字段。
示例:
- 创建索引
PUT /hoteld
{
"mappings": {
"properties": {
"title": {
"type": "text"
},
"city": {
"type": "keyword"
},
"price": {
"type": "double"
},
"create_time": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss"
},
"amenities": {
"type": "text"
},
"full_room": {
"type": "boolean"
},
"location": {
"type": "geo_point"
},
"praise": {
"type": "integer"
}
}
}
}
- 插入文档
POST /_bulk
{"index":{"_index":"hoteld","_id":"001"}}
{"title":"文雅酒店","city":"青岛","price":556,"create_time":"2020-04-18 12:00:00","amenities":"浴池,普通停车场/充电停车场","full_room":false,"location":{"lat":36.083078,"lon":120.37566},"praise":10}
{"index":{"_index":"hoteld","_id":"002"}}
{"title":"金都嘉怡假日酒店","city":"北京","price":337.00,"create_time":"2021-03-15 20:00:00","amenities":"wifi,充电停车场/可升降停车场","full_room":false,"location":{"lat":39.915153,"lon":116.4030},"praise":60}
{"index":{"_index":"hoteld","_id":"003"}}
{"title":"金都欣欣酒店","city":"天津","price":200.00,"create_time":"2021-05-09 16:00:00","amenities":"提供假日party,免费早餐,可充电停车场","full_room":true,"location":{"lat":39.186555,"lon":117.162007},"praise":30}
{"index":{"_index":"hoteld","_id":"004"}}
{"title":"金都酒店","city":"北京","price":500,"create_time":"2021-02-18 08:00:00","amenities":"浴池(假日需预定),室内游泳池,普通停车场","full_room":true,"location":{"lat":39.915343,"lon":116.4239},"praise":20}
{"index":{"_index":"hoteld","_id":"005"}}
{"title":"文雅精选酒店","city":"北京","price":800.00,"create_time":"2021-01-01 08:00:00","amenities":"浴池(假日需预定),wifi,室内游泳池,普通停车场","full_room":true,"location":{"lat":39.918229,"lon":116.422011},"praise":20}
DSL
GET /hoteld/_search
{
"_source": ["title","city"],
"query": {
"term": {
"city": {
"value": "天津"
}
}
}
}
- 请求方式:GET
- “_source”:数组。元素里面是想要展示的字段
JAVA API分两种形式
1 spring-boot-starter-data-elasticsearch
/**
* 获取特定字段的查询
* @return
*/
public Hotel1 findByQuerySource(){
FetchSourceFilter fetchSourceFilter = new FetchSourceFilter(new String[]{"city"}, null);
NativeSearchQuery nativeSearchQuery = new NativeSearchQueryBuilder()
.withSourceFilter(fetchSourceFilter).withQuery(QueryBuilders.termsQuery("city", "天津")).build();
SearchHits<Hotel1> search = elasticsearchRestTemplate.search(nativeSearchQuery, Hotel1.class);
for (SearchHit<Hotel1> hotel1SearchHit : search) {
Hotel1 content = hotel1SearchHit.getContent();
System.out.println(content);
}
return null;
}
2. elasticsearch-rest-high-level-client
/**
* 特定字段返回
*/
public void findByQuerySource(){
SearchRequest searchRequest = new SearchRequest("hoteld");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.fetchSource(new String[]{"city"},null);
searchSourceBuilder.query(QueryBuilders.termQuery("city","天津"));
searchRequest.source(searchSourceBuilder);
try {
SearchResponse search = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
for (SearchHit hit : search.getHits()) {
Map<String, Object> sourceAsMap = hit.getSourceAsMap();
String city = (String)sourceAsMap.get("city");
System.out.println(city);
}
} catch (IOException e) {
e.printStackTrace();
}
}
4.1.2 计数
为了提升搜索体验,返回符合筛选条件的总条数。
DSL
GET /${index_name}/_count
{
"query":{
....
}
}
- 请求方式:GET
- index_name:索引名称
- _count:计数路径
- query:可以传过滤条件、
JAVA API分两种形式
1 spring-boot-starter-data-elasticsearch
/**
* 获取符合的条数
* @return
*/
public Long getDataCount(){
NativeSearchQuery nativeSearchQuery = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.termQuery("city", "天津"))
.build();
long hoteld = elasticsearchRestTemplate.count(nativeSearchQuery, IndexCoordinates.of("hoteld"));
System.out.println(hoteld);
return hoteld;
}
2. elasticsearch-rest-high-level-client
/**
* 获取符合条件的文档条数
* @return
*/
public Long getDataCount(){
CountRequest countRequest = new CountRequest("hoteld");
countRequest.query(QueryBuilders.termQuery("city","天津"));
try {
CountResponse countResponse = restHighLevelClient.count(countRequest, RequestOptions.DEFAULT);
long count = countResponse.getCount();
return count;
} catch (IOException e) {
e.printStackTrace();
}
return 0L;
}
4.1.3 结果分页
Es 的分页和关系型数据库分页不太一样。Es分页默认是开始是from默认是0,size默认是10。Es分页和关系型数据分页不一样的原因是。他不是真正的分页。比如查询from=10 size=10这页的数据时。假设有三个分片一个协调节点。每个分片需要查询出100条数据。三个节点就是300条数据。然后再在协调节点给进行排序找到第10页展示的数据并且返回。
也就是说Es并不适合大的分页查询。而且每个分片最大查询条数是10000。如果想要改变这个值可以设置改索引下的max_result_window这个字段参数。
如:
PUT /hotel/_settings
{ “index”: { “max_result_window”: 20000 } }
DSL
GET /${index_name}/_search
{
"from":0,
"size":10,
"query":{
...
}
}
- 请求方式:GET
- index_name:索引名称
- from:第几页以0开始
- size:每页条数默认10
java API分两种方式
1. spring-boot-starter-data-elasticsearch
/**
* 结果分页查询
*/
public void getPageQueryData(){
PageRequest of = PageRequest.of(0, 2);
NativeSearchQuery build = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.matchAllQuery()).withPageable(of)
.build();
SearchHits<Hotel1> search = elasticsearchRestTemplate.search(build, Hotel1.class);
for (SearchHit<Hotel1> hotel1SearchHit : search) {
Hotel1 content = hotel1SearchHit.getContent();
System.out.println(content);
}
}
2. elasticsearch-rest-high-level-client
/**
* 分页查询
*/
public void getPageQuery(){
SearchRequest searchRequest = new SearchRequest("hoteld");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder().from(0).size(2).query(QueryBuilders.matchAllQuery());
searchRequest.source(searchSourceBuilder);
try {
SearchResponse search = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
for (SearchHit hit : search.getHits()) {
Map<String, Object> sourceAsMap = hit.getSourceAsMap();
System.out.println(sourceAsMap);
}
} catch (IOException e) {
e.printStackTrace();
}
}
4.1.4 性能分析
在使用es的时候,可能会遇到搜索结果慢的问题。如果执行的DSL脚步比较长。就需要通过profile = true 来查看哪部分比较慢了。
DSL
POST /${index_name}/_search
{
"profile" = true,
"query":{
...
}
}
-- 结果
{
"took" : 5,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
... 命中数据
},
"profile" : {
"shards" : [
{
"id" : "[3YHg2n4cRlquBb6iSBtkXQ][hoteld][0]", -- 分片数据
"searches" : [
{
"query" : [
{
"type" : "TermQuery",
"description" : "city:天津",
"time_in_nanos" : 439700,
"breakdown" : {
"set_min_competitive_score_count" : 0,
"match_count" : 0,
"shallow_advance_count" : 0,
"set_min_competitive_score" : 0,
"next_doc" : 6500,
"match" : 0,
"next_doc_count" : 1,
"score_count" : 1,
"compute_max_score_count" : 0,
"compute_max_score" : 0,
"advance" : 1000,
"advance_count" : 1,
"score" : 3200,
"build_scorer_count" : 2,
"create_weight" : 375200,
"shallow_advance" : 0,
"create_weight_count" : 1,
"build_scorer" : 53800
}
}
],
"rewrite_time" : 1500,
"collector" : [
{
"name" : "SimpleTopScoreDocCollector",
"reason" : "search_top_hits",
"time_in_nanos" : 10900
}
]
}
],
"aggregations" : [ ]
}
]
}
}
- profile : 新能分析的关键字。
因为新能分析比较消耗性能。所以在线上环境是不推荐使用的。
还可以在Kibana的Dev Tools界面中单击Search Profiler链接

4.1.5 评分分析
查询某个文档在某次查询条件时的评分。可以方便线上问题查询。
DSL
GET /${index_name}/_explain/${doc_id}
{
"query":{
....
}
}
- _explain:评分分析关键字
{
"_index" : "hoteld",
"_type" : "_doc",
"_id" : "002",
"matched" : true,
"explanation" : { // 被拆分为两个子查询
"value" : 0.91718745,
"description" : "sum of:",
"details" : [
{
"value" : 0.45859373, // 子查询分值
"description" : "weight(title:金 in 1) [PerFieldSimilarity], result of:",
"details" : [
{
"value" : 0.45859373, // 子查询分值
"description" : "score(freq=1.0), computed as boost * idf * tf from:",
"details" : [
{
"value" : 2.2,
"description" : "boost",
"details" : [ ]
},
{
"value" : 0.5389965,
"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details" : [
{
"value" : 3,
"description" : "n, number of documents containing term",
"details" : [ ]
},
{
"value" : 5,
"description" : "N, total number of documents with field",
"details" : [ ]
}
]
},
{
"value" : 0.38674033,
"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details" : [
{
"value" : 1.0,
"description" : "freq, occurrences of term within document",
"details" : [ ]
},
{
"value" : 1.2,
"description" : "k1, term saturation parameter",
"details" : [ ]
},
{
"value" : 0.75,
"description" : "b, length normalization parameter",
"details" : [ ]
},
{
"value" : 8.0,
"description" : "dl, length of field",
"details" : [ ]
},
{
"value" : 5.6,
"description" : "avgdl, average length of field",
"details" : [ ]
}
]
}
]
}
]
},
{
"value" : 0.45859373, / 子查询分值
"description" : "weight(title:都 in 1) [PerFieldSimilarity], result of:",
"details" : [
{
"value" : 0.45859373, // 子查询分值
"description" : "score(freq=1.0), computed as boost * idf * tf from:",
"details" : [
{
"value" : 2.2,
"description" : "boost",
"details" : [ ]
},
{
"value" : 0.5389965,
"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details" : [
{
"value" : 3,
"description" : "n, number of documents containing term",
"details" : [ ]
},
{
"value" : 5,
"description" : "N, total number of documents with field",
"details" : [ ]
}
]
},
{
"value" : 0.38674033,
"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details" : [
{
"value" : 1.0,
"description" : "freq, occurrences of term within document",
"details" : [ ]
},
{
"value" : 1.2,
"description" : "k1, term saturation parameter",
"details" : [ ]
},
{
"value" : 0.75,
"description" : "b, length normalization parameter",
"details" : [ ]
},
{
"value" : 8.0,
"description" : "dl, length of field",
"details" : [ ]
},
{
"value" : 5.6,
"description" : "avgdl, average length of field",
"details" : [ ]
}
]
}
]
}
]
}
]
}
}
4.2 丰富的搜索匹配功能
针对不同的数据类型,ES提供了多种搜索方式。keyword使用的trem text使用的match 数值类型的取值区间range,前缀匹配suggest等等。
4.2.1 查询所有文档
类似关系型数据库中的select * from table。ES中也提供了查询关键字 match_all字段。这个时候就不会给所有文档进行评分了。默认boost为1
DSL
GET /${index_name}/_search
{
"query": {
"match_all": {
"boost": 2
}
}
}
{
"took" : 16,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 5,
"relation" : "eq"
},
"max_score" : 2.0,
"hits" : [
{
"_index" : "hoteld",
"_type" : "_doc",
"_id" : "001",
"_score" : 2.0,
"_source" : {
"title" : "文雅酒店",
"city" : "青岛",
"price" : 556,
"create_time" : "2020-04-18 12:00:00",
"amenities" : "浴池,普通停车场/充电停车场",
"full_room" : false,
"location" : {
"lat" : 36.083078,
"lon" : 120.37566
},
"praise" : 10
}
}
]
}
}
java API分两种方式
1. spring-boot-starter-data-elasticsearch
/**
* 查询全部数据
*/
public void getMatchlAllList(){
NativeSearchQuery nativeSearchQuery = new NativeSearchQueryBuilder().withQuery(QueryBuilders.matchAllQuery().boost(2.0f)).build();
SearchHits<Hotel1> search = elasticsearchRestTemplate.search(nativeSearchQuery, Hotel1.class);
for (SearchHit<Hotel1> hotel1SearchHit : search) {
Hotel1 content = hotel1SearchHit.getContent();
System.out.println(content);
}
}
2. elasticsearch-rest-high-level-client
/**
* 查询全部字段
*/
public void getMatchAllList(){
SearchRequest searchRequest = new SearchRequest("hoteld");
SearchSourceBuilder query = new SearchSourceBuilder().query(QueryBuilders.matchAllQuery());
searchRequest.source(query);
try {
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
for (SearchHit hit : searchResponse.getHits()) {
Map<String, Object> sourceAsMap = hit.getSourceAsMap();
String id = hit.getId();
System.out.println(sourceAsMap + "id: " + id);
}
} catch (IOException e) {
e.printStackTrace();
}
}
4.2.2 term级别查询
term级别查询就相当于java中的equals。能使用term查询的数据类型有:keyword、数值类型、日期类型、布尔类型、数组类型(是数值类型的)。text类型是有倒排索引进行分词的所以不能使用。
DSL
GET /${index_name}/_search
{
"query":{
"term":{
filed:{
"key":"value"
}
}
}
}
- trem:关键字
- filed:字段名称
- value:需要查询的value值。
GET /hoteld/_search
{
"query": {
"term": {
"city": {
"value": "天津" // keyword
}
}
}
}
{
"query": {
"term": {
"price": {
"value": "200" // double
}
}
}
}
{
"query": {
"term": {
"create_time": {
"value": "2021-05-09 16:00:00" // date 日期类型
}
}
}
}
{
"query": {
"term": {
"full_room": {
"value": true // boolean
}
}
}
}
java API分两种方式
1. spring-boot-starter-data-elasticsearch
/**
* term 查询
*/
public void findTermQuery(){
NativeSearchQuery query = new NativeSearchQueryBuilder().withQuery(QueryBuilders.termQuery("city", "天津")).build();
SearchHits<Hotel1> search = elasticsearchRestTemplate.search(query, Hotel1.class);
if (search.hasSearchHits()) {
for (SearchHit<Hotel1> hotel1SearchHit : search) {
Hotel1 content = hotel1SearchHit.getContent();
System.out.println(content);
}
}
}
2. elasticsearch-rest-high-level-client
/**
* term 查询
*/
public void findTermQuery(){
SearchRequest searchRequest = new SearchRequest("hoteld");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder().query(QueryBuilders.termQuery("city","天津"));
searchRequest.source(searchSourceBuilder);
try {
SearchResponse search = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
for (SearchHit hit : search.getHits()) {
Map<String, Object> sourceAsMap = hit.getSourceAsMap();
String id = hit.getId();
System.out.println(sourceAsMap + "id: " + id);
}
} catch (IOException e) {
e.printStackTrace();
}
}
4.2.3terms级别查询
terms就是term的升级版。term只能查询匹配一个数据就相当于数据型sql中的=号terms相当于in().
DSL
GET /${index_name}/_search
{
"query":{
"terms":{
"filed":[
"value",
"value"...
]
}
}
}
- terms:关键字
- filed:字段名称
GET /hoteld/_search
{
"query": {
"terms": {
"city":["北京","天津"]
}
}
}
java API分两种方式
1. spring-boot-starter-data-elasticsearch
/**
* term 查询
*/
public void findTermQuery(){
NativeSearchQuery query = new NativeSearchQueryBuilder().withQuery(QueryBuilders.termsQuery("city", "天津","北京")).build();
SearchHits<Hotel1> search = elasticsearchRestTemplate.search(query, Hotel1.class);
if (search.hasSearchHits()) {
for (SearchHit<Hotel1> hotel1SearchHit : search) {
Hotel1 content = hotel1SearchHit.getContent();
System.out.println(content);
}
}
}
2. elasticsearch-rest-high-level-client
/**
* term 查询
*/
public void findTermQuery(){
SearchRequest searchRequest = new SearchRequest("hoteld");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder().query(QueryBuilders.termsQuery("city","天津","北京"));
searchRequest.source(searchSourceBuilder);
try {
SearchResponse search = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
for (SearchHit hit : search.getHits()) {
Map<String, Object> sourceAsMap = hit.getSourceAsMap();
String id = hit.getId();
System.out.println(sourceAsMap + "id: " + id);
}
} catch (IOException e) {
e.printStackTrace();
}
}
4.2.4 range查询
返回查询 一般是数据类型和日期类型。可以查询范围内符合的数据。
- gt 大于
- lt 小于
- gte 大于等于
- lte 小于等于
DSL
GET /${index_name}/_search
{
"query":{
"range":{
"filed":{
"gt":"",
"lt":"".....
}
}
}
}
GET /hoteld/_search
{
"query": {
"range": {
"price": {
"gte": 700,
"lte": 800
}
}
}
}
// 时间查询 必须按照时间格式进行查询
GET /hoteld/_search
{
"query": {
"range": {
"create_time": {
"gte": "2021-01-01 08:00:00",
"lte": "2021-03-01 08:00:00"
}
}
}
}
java API分两种方式
1. spring-boot-starter-data-elasticsearch
/**
* range 查询
*/
public void findRangeQuery(){
NativeSearchQuery query = new NativeSearchQueryBuilder().withQuery(QueryBuilders.rangeQuery("price").gte(700).lte(800)).build();
SearchHits<Hotel1> search = elasticsearchRestTemplate.search(query, Hotel1.class);
if (search.hasSearchHits()) {
for (SearchHit<Hotel1> hotel1SearchHit : search) {
Hotel1 content = hotel1SearchHit.getContent();
System.out.println(content);
}
}
}
2. elasticsearch-rest-high-level-client
/**
* range范围查询
*/
public void findRangeQuery(){
SearchRequest searchRequest = new SearchRequest("hoteld");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder().query(QueryBuilders.rangeQuery("price").gte(700).lte("800"));
searchRequest.source(sourceBuilder);
try {
SearchResponse search = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
for (SearchHit hit : search.getHits()) {
Map<String, Object> sourceAsMap = hit.getSourceAsMap();
String id = hit.getId();
System.out.println(sourceAsMap + "id: " + id);
}
} catch (IOException e) {
e.printStackTrace();
}
}
4.2.5 exists查询
判断某个字段不为null。不为空的依据为不为null、数组不为空数组、数组不为[null].
DSL
GET /${index_name}/_search
{
"query":{
"exists":{
"field":"key"
}
}
}
- exists:关键字
- key:字段名称
测试:
PUT /hotel_1
{
"mappings": {
"properties":{
"title":{
"type":"text"
},
"tag":{
"type":"keyword"
}
}
}
}
POST /hotel_1/_doc/001
{
"title":"环球酒店",
"tag":null
}
POST /hotel_1/_doc/002
{
"title":"环球酒店",
"tag":[]
}
POST /hotel_1/_doc/003
{
"title":"环球酒店",
"tag":[null]
}
三个文档tag字段分别为null、[]、[null]。查询tag字段存在值的文档这三个文档不会命中。
GET /hotel_1/_search
{
"query":{
"exists":{
"field":"tag"
}
}
}
结果:
{
"took" : 12,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 0,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
}
}
java API分两种方式
1. spring-boot-starter-data-elasticsearch
/**
* exists查询
*/
public void findExistsQuery(){
NativeSearchQuery query = new NativeSearchQueryBuilder().withQuery(QueryBuilders.existsQuery("tag")).build();
SearchHits<Map> search = elasticsearchRestTemplate.search(query, Map.class, IndexCoordinates.of("hotel_1"));
if (search.hasSearchHits()) {
for (SearchHit<Map> hotel1SearchHit : search) {
Map content = hotel1SearchHit.getContent();
System.out.println(content);
}
}
}
2. elasticsearch-rest-high-level-client
/**
* exists 查询
*/
public void findExistsQuery(){
SearchRequest searchRequest = new SearchRequest("hotel_1");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.existsQuery("tag"));
searchRequest.source(searchSourceBuilder);
try {
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
for (SearchHit hit : searchResponse.getHits()) {
Map<String, Object> sourceAsMap = hit.getSourceAsMap();
String id = hit.getId();
System.out.println(sourceAsMap + "id: " + id);
}
} catch (IOException e) {
e.printStackTrace();
}
}
4.2.6 布尔查询
复合查询就是需要多个条件过滤出符合的结果集。布尔查询是常见的复合查询方式。布尔查询返回的结果会根据每个子查询匹配度来排分。
布尔查询支持四种子查询方式。
| 子查询名称 | 功能 |
|---|---|
| must | 必须匹配该查询条件 可以理解为&& |
| should | 可以匹配该查询条件 可以理解为 || |
| must not | 必须不匹配该查询条件 ! |
| filter | 必须匹配过滤条件,不进行打分计算 |
4.2.6.1 must查询
must查询相当于与查询。并且把子查询的分数添加到文档分数计算中。
DSL
GET /hoteld/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"city": {
"value": "北京"
}
}
},
{
"range": {
"price": {
"gte": 350,
"lte": 500
}
}
}
]
}
}
}
- bool:关键字
- must:关键字 数组 可以传多个条件
java API分两种方式
1. spring-boot-starter-data-elasticsearch
/**
* must查询
*/
public void findMustQuery(){
TermsQueryBuilder termsQueryBuilder = QueryBuilders.termsQuery("city", "北京");
RangeQueryBuilder price = QueryBuilders.rangeQuery("price").gte(350).lte(500);
BoolQueryBuilder queryBuilder = QueryBuilders.boolQuery().must(termsQueryBuilder).must(price);
NativeSearchQuery build = new NativeSearchQueryBuilder().withQuery(queryBuilder).build();
SearchHits<Hotel1> search = elasticsearchRestTemplate.search(build, Hotel1.class);
if (search.hasSearchHits()) {
for (SearchHit<Hotel1> hotel1SearchHit : search) {
Hotel1 content = hotel1SearchHit.getContent();
System.out.println(content);
}
}
}
2. elasticsearch-rest-high-level-client
/**
* must 查询
*/
public void findMustQuery(){
SearchRequest searchRequest = new SearchRequest("hoteld");
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("city", "北京");
boolQueryBuilder.must(termQueryBuilder);
RangeQueryBuilder rangeQueryBuilder = QueryBuilders.rangeQuery("price").gte(350).lte(500);
boolQueryBuilder.must(rangeQueryBuilder);
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder().query(boolQueryBuilder);
searchRequest.source(searchSourceBuilder);
try {
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
for (SearchHit hit : searchResponse.getHits()) {
Map<String, Object> sourceAsMap = hit.getSourceAsMap();
String id = hit.getId();
System.out.println(sourceAsMap + "id: " + id);
}
} catch (IOException e) {
e.printStackTrace();
}
}
4.2.6.2 should查询
should查询就相当于||条件。每个条件的匹配分数也会用于计算总分数
DSL
GET /${index_name}/_search
{
"query":{
"bool":{
"should":[
{
"match":{}
},
{
"term":{}
}
]
}
}
}
- bool:关键字。表示布尔查询
- should:表示或查询。里面的语句只要有一个符合就为true。
示例:
GET /hoteld/_search
{
"query": {
"bool": {
"should": [
{"term": {
"city": {
"value": "天津"
}
}},
{
"range": {
"price": {
"gte": 350,
"lte": 500
}
}
}
]
}
}
}
java API分两种方式
1. spring-boot-starter-data-elasticsearch
/**
* should查询 又称或查询
*/
public void findShouldQuery(){
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("city", "天津");
RangeQueryBuilder price = QueryBuilders.rangeQuery("price").gte(350).lte(500);
BoolQueryBuilder should = QueryBuilders.boolQuery().should(termQueryBuilder).should(price);
NativeSearchQuery build = new NativeSearchQueryBuilder().withQuery(should).build();
SearchHits<Hotel1> search = elasticsearchRestTemplate.search(build, Hotel1.class);
if (search.hasSearchHits()) {
for (SearchHit<Hotel1> hotel1SearchHit : search) {
Hotel1 content = hotel1SearchHit.getContent();
System.out.println(content);
}
}
}
2. elasticsearch-rest-high-level-client
/**
* should 查询 又称或查询
*/
public void findShouldQuery(){
SearchRequest searchRequest = new SearchRequest("hoteld");
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("city", "天津");
RangeQueryBuilder price = QueryBuilders.rangeQuery("price").gte(350).lte(500);
boolQueryBuilder.should(termQueryBuilder).should(price);
SearchSourceBuilder query = new SearchSourceBuilder().query(boolQueryBuilder);
searchRequest.source(query);
try {
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
for (SearchHit hit : searchResponse.getHits()) {
Map<String, Object> sourceAsMap = hit.getSourceAsMap();
String id = hit.getId();
System.out.println(sourceAsMap + "id: " + id);
}
} catch (IOException e) {
e.printStackTrace();
}
}
4.2.6.3 must_not查询
must_not 查询代表是非查询。命中文档不能匹配当中的一个或多个子查询接口。ES会将改查询与文档匹配度加入到总分里去计算。
DSL
GET /hoteld/_search
{
"query": {
"bool": {
"must_not": [
{"term": {
"city": {
"value": "天津"
}
}},
{
"range": {
"price": {
"gte": 350,
"lte": 500
}
}
}
]
}
}
}
java API分两种方式
1. spring-boot-starter-data-elasticsearch
/**
* must_not查询
*/
public void findMustNotQuery(){
TermsQueryBuilder termsQueryBuilder = QueryBuilders.termsQuery("city", "北京");
RangeQueryBuilder price = QueryBuilders.rangeQuery("price").gte(350).lte(500);
BoolQueryBuilder queryBuilder = QueryBuilders.boolQuery().mustNot(termsQueryBuilder).mustNot(price);
NativeSearchQuery build = new NativeSearchQueryBuilder().withQuery(queryBuilder).build();
SearchHits<Hotel1> search = elasticsearchRestTemplate.search(build, Hotel1.class);
if (search.hasSearchHits()) {
for (SearchHit<Hotel1> hotel1SearchHit : search) {
Hotel1 content = hotel1SearchHit.getContent();
System.out.println(content);
}
}
}
2. elasticsearch-rest-high-level-client
/**
* must_not查询 也叫且查询
*/
public void findMustNotQuery(){
SearchRequest searchRequest = new SearchRequest("hoteld");
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("city", "北京");
boolQueryBuilder.mustNot(termQueryBuilder);
RangeQueryBuilder rangeQueryBuilder = QueryBuilders.rangeQuery("price").gte(350).lte(500);
boolQueryBuilder.mustNot(rangeQueryBuilder);
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder().query(boolQueryBuilder);
searchRequest.source(searchSourceBuilder);
try {
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
for (SearchHit hit : searchResponse.getHits()) {
Map<String, Object> sourceAsMap = hit.getSourceAsMap();
String id = hit.getId();
System.out.println(sourceAsMap + "id: " + id);
}
} catch (IOException e) {
e.printStackTrace();
}
}
4.2.6.4 filter查询
filter查询和其他布尔查询不太一样。其他布尔查询会关注子查询分数情。filter不关注分数。并且还会缓存部分子查询结果。
Filter查询原理
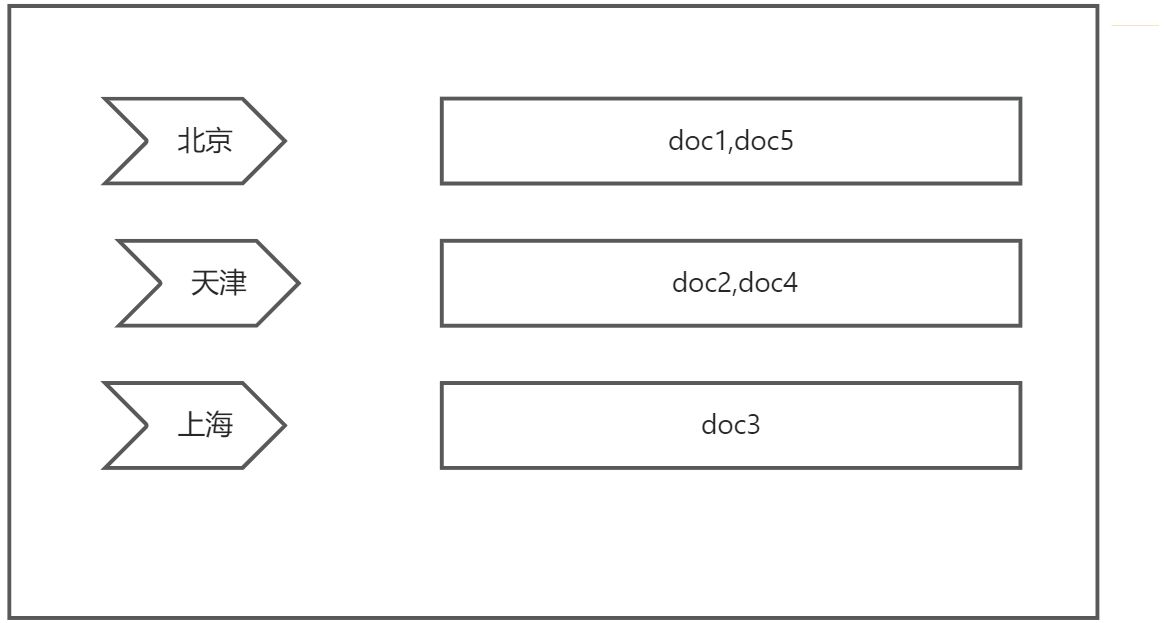
- 假设当前有五个文档。这五个文档对应城市的倒排索引为:
- 假设当前有五个文档。这五个文档对应满房字段的倒排索引为:

- 已查询城市为北京。没有满房的酒店为例
- 当ES执行过滤条件时。回显查询city为北京的bitset(位图)数据是否存在。bitset可以用最紧凑的数据来表示给定范围内的连续数据。如果查询中有bitset数据,则直接取出。如果没有则es查询数据后根据查询接口来组装bitset数据,并将其放入缓存中。同时es也会考察满房字段为false是否有bitset数据。如果有则取出,否则就查询出接口并生成bitset数据放到缓存中。
- 假设城市值为北京时没有bitset数据。则bitset生成的方式为:
- 首先es会先搜索为北京的文档,这里符合条件的文档为doc1,doc5。然后为所有文件构建bitset数组。数组中每个元素的值用来表示对应位置的文档是否和查询条件匹配,0表示未匹配,1表示匹配。在本例中,doc1和doc5匹配“北京”,对应位置的值为1;doc2、doc3、doc4不匹配,对应位置的值为0。最终,本例的bitset数组为[1,0,0,0,1]。之所以用bitset表示文档和query的匹配结果,是因为该结构不仅节省空间而且后续进行操作时也能节省时间。如果满房字段缓存中没有对应的bitset数据,ES构建满房字段为false对应bitset的过程也是类似的。
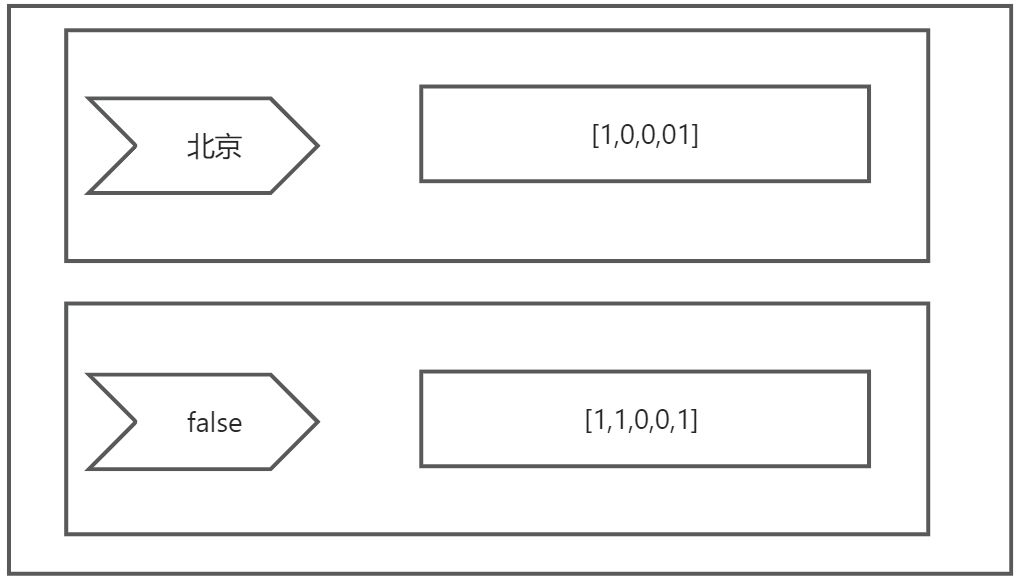
4. 接下来es会遍历查询条件的bitset数组。按照命中与否进行文档过滤。当一个请求有多个filter过滤条件时,会先从最稀疏的数组进行遍历,因为稀疏的数组可以过滤掉更多的文档。上述请求城市数组最稀疏,所以就像从城市过滤,然后再从是否满房字段过滤。连个数组都过滤好后就只剩先doc1,doc5了。
5. 如果缓存中有的话就直接使用缓存中数组进行过滤。也就是说bitset是可重用的。这种重用机制叫做filter cache(过滤器缓存)。
6. filter cache会跟踪每一个filter查询,ES筛选一部分filter查询的bitset进行缓存。首先,这些过滤条件要在最近256个查询中出现过;其次,这些过滤条件的次数必须超过某个阈值
7. 另外filter cache还有自动更新的功能。如果某个文档中的城市被修改了。则bitset中的数组也会相对应的修改。
8. filter查询是不计入分数计算的。这更加减少了开销。
9. 如果在自己的业务中有不需要分数计算的字段进行过滤的时候可以用filter查询。
DSL
GET /hoteld/_search
{
"query": {
"bool": {
"filter": [
{"term": {
"city": {
"value": "北京"
}
}},
{
"range": {
"price": {
"gte": 350,
"lte": 500
}
}
}
]
}
}
}
java API分两种方式
1. spring-boot-starter-data-elasticsearch
/**
* filter查询
*/
public void findFilterQuery(){
TermsQueryBuilder termsQueryBuilder = QueryBuilders.termsQuery("city", "北京");
RangeQueryBuilder price = QueryBuilders.rangeQuery("price").gte(350).lte(500);
BoolQueryBuilder queryBuilder = QueryBuilders.boolQuery().filter(termsQueryBuilder).filter(price);
NativeSearchQuery build = new NativeSearchQueryBuilder().withQuery(queryBuilder).build();
SearchHits<Hotel1> search = elasticsearchRestTemplate.search(build, Hotel1.class);
if (search.hasSearchHits()) {
for (SearchHit<Hotel1> hotel1SearchHit : search) {
Hotel1 content = hotel1SearchHit.getContent();
System.out.println(content);
}
}
}
2. elasticsearch-rest-high-level-client
/**
* filter查询
*/
public void findFilterQuery(){
SearchRequest searchRequest = new SearchRequest("hoteld");
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("city", "北京");
boolQueryBuilder.filter(termQueryBuilder);
RangeQueryBuilder rangeQueryBuilder = QueryBuilders.rangeQuery("price").gte(350).lte(500);
boolQueryBuilder.filter(rangeQueryBuilder);
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder().query(boolQueryBuilder);
searchRequest.source(searchSourceBuilder);
try {
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
for (SearchHit hit : searchResponse.getHits()) {
Map<String, Object> sourceAsMap = hit.getSourceAsMap();
String id = hit.getId();
System.out.println(sourceAsMap + "id: " + id);
}
} catch (IOException e) {
e.printStackTrace();
}
}
4.2.6.4 Constant Score查询
如果不想让检索词频率对搜索结果排序有影响,只想过滤某个文本字段是否包含有某个词,可以使用Constant score查询。假设需要查询amenities字段是否包含停车场字段。
DSL
GET /hoteld/_search
{
"_source":["amenities"],
"query":{
"constant_score":{
"filter":{
"match":{
"amenities":"停车场"
}
},
"boost":1.2
}
}
}
查询结果:
{
"took" : 1,
"timed_out" : false,
"_shards" : { //分片
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 5,
"relation" : "eq"
},
"max_score" : 1.2, // 最大分数
"hits" : [
{
"_index" : "hoteld",
"_type" : "_doc",
"_id" : "001",
"_score" : 1.2, // 分数结果 并没有影响到排名
"_source" : {
"amenities" : "浴池,普通停车场/充电停车场"
}
},
{
"_index" : "hoteld",
"_type" : "_doc",
"_id" : "002",
"_score" : 1.2,
"_source" : {
"amenities" : "wifi,充电停车场/可升降停车场"
}
},
{
"_index" : "hoteld",
"_type" : "_doc",
"_id" : "003",
"_score" : 1.2,
"_source" : {
"amenities" : "提供假日party,免费早餐,可充电停车场"
}
},
{
"_index" : "hoteld",
"_type" : "_doc",
"_id" : "004",
"_score" : 1.2,
"_source" : {
"amenities" : "浴池(假日需预定),室内游泳池,普通停车场"
}
},
{
"_index" : "hoteld",
"_type" : "_doc",
"_id" : "005",
"_score" : 1.2,
"_source" : {
"amenities" : "浴池(假日需预定),wifi,室内游泳池,普通停车场"
}
}
]
}
}















 1744
1744











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









