






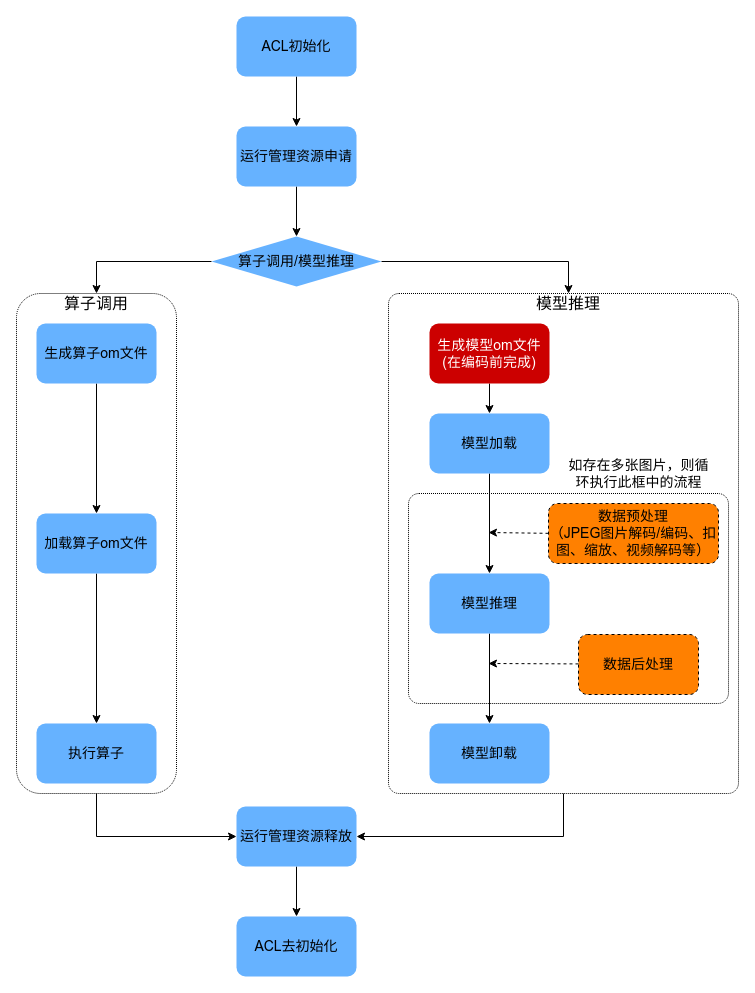
1. AscendCL主要接口调用流程
- AscendCL初始化:初始化整个AscendCL的运行时环境,这一步是不可缺少的。
- 运行管理资源申请:手动申请所需要的计算资源和运行时资源生成模型om文件(在编码前完成)
- 根据实际需求来判断是需要调用单算子进行计算还是调用模型进行推理
- 如果是调用单算子进行计算,需要走单算子调用流程
- 如果是模型推理,则需要加载模型,加载数据,按需对数据进行预处理,推理,卸载模型
- 涉及AscendCL的计算结束后,及时释放前面申请的运行管理资源
- 最终,销毁AscendCL运行时环境,即AscendCL去初始化
2. AscendCL初始化
调用 aclInit 接口,开始对AscendCL进行初始化操作。
需要注意的是,一个进程内只能调用一次 aclInit 接口。
3. 运行资源管理
在对运行管理资源进行申请时,需要按以下顺序依次申请:Device->Context->Stream。
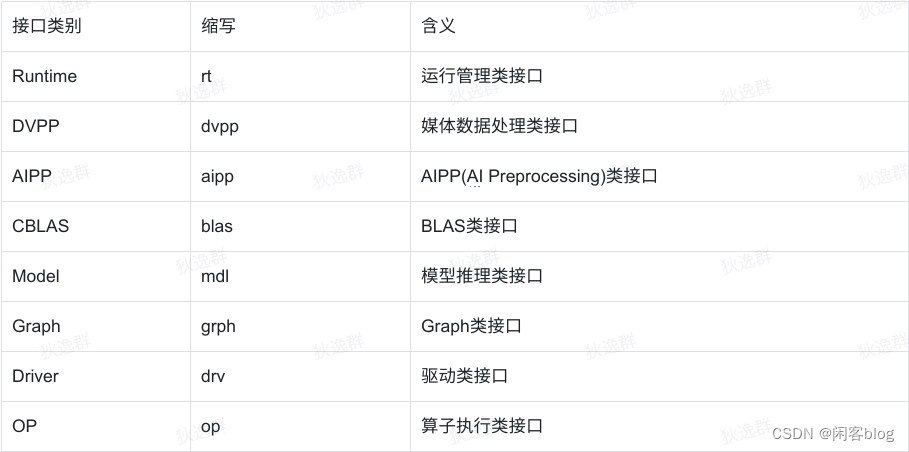
常用接口
相关函数
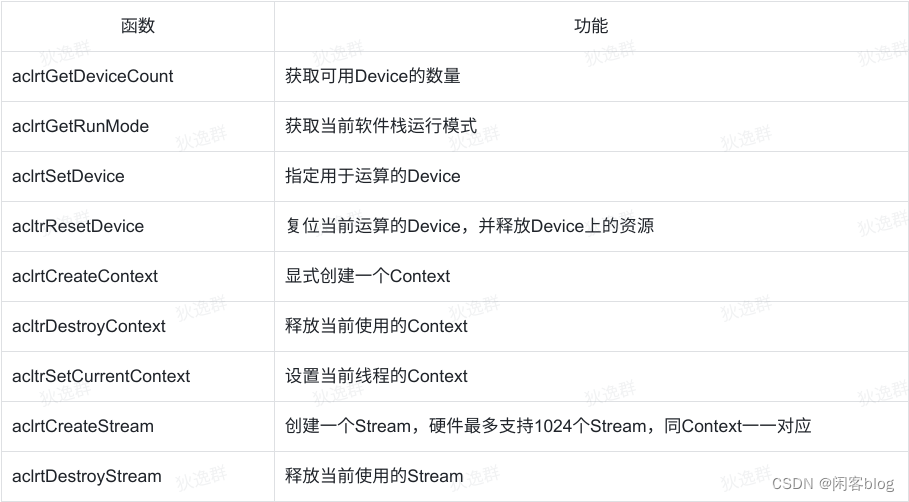
- 如不显式创建Context和Stream,系统将会使用默认Context和默认Stream,且默认Context、默认Stream作为接口入参时,会直接传NULL。
- 如果多次调用 aclrtSetDevice 指向同一Device,acltrResetDevice 仅需调用一次即可复位Device
- 在使用 acltrResetDevice 前,需按照Event、Stream、Context的顺序依次释放对应的资源
- Context的创建无数量限制,但如在某一进程中创建多个Context,该线程在同一时刻内,仅可使用一个Context,可通过 acltrSetCurrentContext 明确指定当前线程的Context,以增加可维护性。
- 如多次调用 acltrSetCurrentContext 设置线程的Context,则以最后一次为准
4. 内存管理&数据传输
相关函数接口
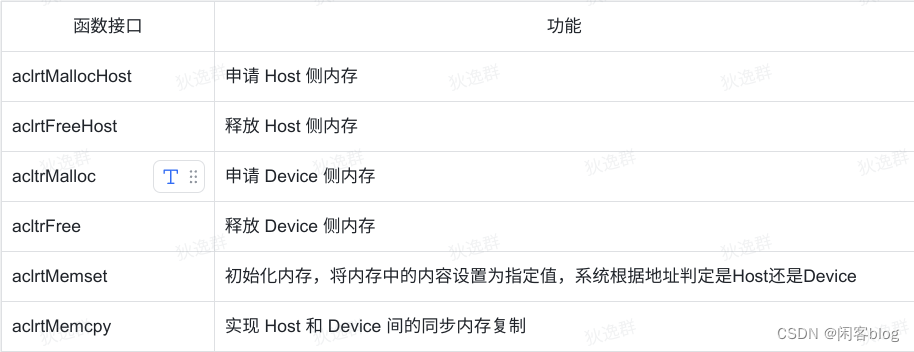
- 如应用在Host上运行,调用 aclrtMallocHost 申请的是Host内存,由系统保证内存首地址64字节对齐;如应用在Device上运行时,调用 aclrtMallocHost 申请的是Device内存,如需首地址64字节对齐,需要用户自行处理对齐
- 在调用 aclrtMalloc 申请内存时,会对用户输入的size按向上对齐为32整数倍,再多加32字节。
- 频繁调用 aclrtMalloc 申请内存、调用 aclrtFree 释放内存,会损耗性能,最理想方案为提前做内存的预先分配或二次管理
5. 数据预处理
数据预处理主要使用两大工具AIPP(AI Preprocessing)和DVPP(Digital Vision Preprocessing)。
DVPP
DVPP中主要提供了5个功能模块,包括视频编码模块(VENC)、视频解码模块(VDEC)、JPEG图片解码(JPEGE)、JPEG图片解码(JPEGD)、视觉预处理模块(VPC)
6. 模型加载与执行
模型推理流程见 msame开源压测工具学习笔记
相关函数接口
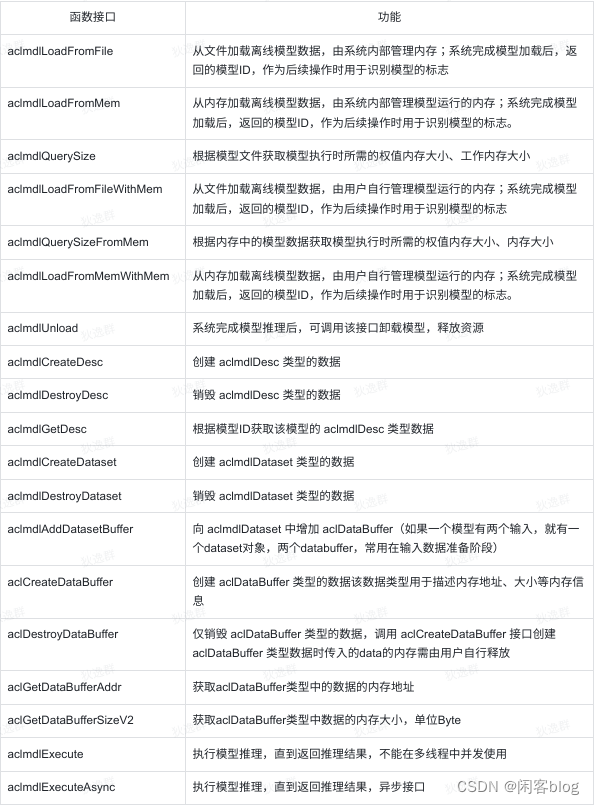
表中未加以说明的都是同步接口
7. 单算子加载与执行
相比于模型加载,单算子的加载与执行不同之处在于模型文件的加载、算子输入数据的传输和单算子的执行
- 单算子模型加载
- 调用 aclopSetModelDir ,设置加载模型文件的目录,目录下存放单算子模型文件(*.om文件)
- 调用 aclopLoad,从内存中加载单算子模型数据,由用户管理内存。单算子模型数是指“单算子编译成的*.om文件后,再将om文件读取到内存中”的数据
- 将算子输入数据从 Host 复制到 Device
- 调用 aclrtMemcpy 实现同步内存复制
- 调用 aclrtMemcpyAsync 实现异步内存复制
- 单算子的执行
- 自行构造算子描述信息(输入输出Tensor描述、算子属性等)、申请存放算子输入输出数据的内存、调用 aclopExecute 接口加载并执行算子
- 自行构造算子描述信息(输入输出Tensor描述、算子属性等)、申请存放算子输入输出数据的内存、调用aclopCreateHandle接口创建一个Handle、再调用aclopExecWithHandle接口加载并执行算子。
相关函数接口

- Host 上运行应用时,一个进程内正在执行的算子的最大个数上限是2000000
- Device 上运行应用时,一个进程内正在执行的算子的最大个数上限是480000
- 所提到的单算子模型数据,是指“单算子编译成的*.om文件后,再将om文件读取到内存中”的数据















 1893
1893











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









