






前言
自定义pytorch中动态图的算子(operator),也就是动态图的“边”,需要继承torch.autograd.Function类,并实现forward与backward方法。在使用自定义的算子时,需要使用apply方法。下面结合官网资料的两个例子加以说明。
实例一
class MyExp(torch.autograd.Function):
""" 前向:y = exp(x), 微分:dydx = exp(x) """
@staticmethod
def forward(ctx, inputs):
""" 实现前向传播逻辑 """
outputs = inputs.exp()
ctx.save_for_backward(outputs)
return outputs
@staticmethod
def backward(ctx, grad_outputs):
""" 实现反向传播, grad_outputs为损失对前向传播中输出的梯度,但需要计算的是损失对输入的梯度 """
outputs, = ctx.saved_tensors
return grad_outputs * outputs
inputs = torch.tensor([1.0, 2.0, 3.0], device='cpu', requires_grad=True)
outputs = MyExp.apply(inputs)
outputs.backward(torch.ones(outputs.shape)) # torch.ones(outputs.shape)为对自己的梯度
grad1 = inputs.grad
inputs.grad = None # 梯度清零
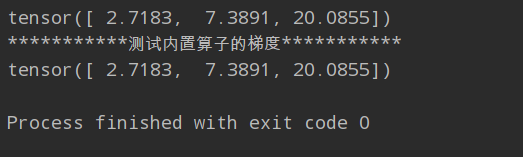
print(grad1)
print("***********测试内置算子的梯度***********")
outputs = inputs.exp()
outputs.sum().backward()
grad2 = inputs.grad
print(grad2)
结果如下:
注意事项:
- forward与backward方法的第一个参数为ctx,该对象为上下文管理器,ctx对象、forward与backward方法的详细信息参考补充资料。
- 自定义Function类调用时需要使用apply方法,apply方法的详细说明信息暂时未知。
实例二
class LegendrePolynomial3(torch.autograd.Function):
@staticmethod
def forward(ctx, inputs):
ctx.save_for_backward(inputs)
return 0.5 * (5 * inputs ** 3 - 3 * inputs)
@staticmethod
def backward(ctx, grad_outputs):
inputs, = ctx.saved_tensors
return grad_outputs * 1.5 * (5 * inputs ** 2 - 1)
start = time.time()
dtype = torch.float
device = torch.device('cpu')
# device = torch.device('cuda:0') # uncommet this line to run on GPU
x = torch.linspace(-math.pi, math.pi, 2000, dtype=dtype, device=device)
y = torch.sin(x)
a = torch.full((), 0.0, dtype=dtype, device=device, requires_grad=True)
b = torch.full((), -1.0, dtype=dtype, device=device, requires_grad=True)
c = torch.full((), 0.0, dtype=dtype, device=device, requires_grad=True)
d = torch.full((), 0.3, dtype=dtype, device=device, requires_grad=True)
learning_rate = 5e-6
P3 = LegendrePolynomial3.apply
for i in range(2000):
y_pred = a + b * P3(c + d * x)
loss = (y_pred - y).pow(2).sum()
loss.backward()
with torch.no_grad():
a -= a.grad * learning_rate
b -= b.grad * learning_rate
c -= c.grad * learning_rate
d -= d.grad * learning_rate
a.grad, b.grad, c.grad, d.grad = None, None, None, None
if i % 100 == 0:
print("id: %s, loss: %s" % (i, loss.item()))
print(f"{a.item()} + {b.item()} * P3({c.item()} + {d.item()} * x )")
print(f" totally costs {time.time() - start} seconds.")
结果如下:

补充材料:
ctx.save_for_backward()
ctx.save_for_backward(*tensors)
ctx是context上下文管理对象的缩写,该方法主要是用于存储反向传播计算所需的数据。反向传播计算梯度时,需要什么就存储什么。例如实例一,y = exp(x),在定义forward方法时需要存储forward方法的输出——因为dydx= exp(x),梯度正好是forward的结果。 而实例二中, y = 0.5 * (5 * x ** 3 - 3 * x),存储的是x——因为dydx = 1.5 * (5 * x ** 2 - 1),计算梯度需要的是x。
save_for_backward方法可以存储任意多个张量,在反向传播时,可通过上下文对象的saved_tensors属性获取,该属性值为元组。 注意ctx是定义forward方法必须且第一个参数,一般情况下在farward定义中调用ctx.save_for_backward()也是必须的,且存储的张量最多只能获取一次。
Function类的farward方法
STATIC forward(ctx: Any, *args: Any, **kwargs: Any) → Any
第一个参数必须为context上下文管理对象,该对象的作用是存储反向传播计算梯度所需的数据。
Function类的backward方法
STATIC backward(ctx: Any, *grad_outputs: Any) → Any
第一个参数必须为ctx对象,该对象在方向传播过程中,主要用于取出存储在其saved_tensors属性中的数据。后接任意个参数,这些输入参数是对前向传播中输出的梯度值,backward方法的返回值为对前向传播中输入的梯度。注意反向传播得到的对输入的梯度,需要与对前向传播中输出的梯度相匹配。















 2579
2579











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









