







概述
本文与后文OPC【5】1是一组关系紧密的文章,共同记录OPC中的物理包与抽象包。物理包本质是一个特定的格式文件,如docx格式文件;抽象包是一个逻辑对象|内存对象,由关系边与包节点组成。对物理包进行 解包(unmarshal) 形成抽象包,对抽象包进行 打包(marshal) 创建物理包。
其中解包过程最为复杂与重要,该过程大致分为两大阶段——序列化与编排,打包过程相对更为容易。另外在实际业务中,总是需要先解包、再打包——word编辑器基于一个空白模版开始,因此先介绍解包过程、再介绍打包过程。本文与后文基于python-docx==1.1.0源码,以加深对OPC物理包与抽象包的认知。
ZIP规范
解包与打包均需遵循zip标准,并且是二者的基础,因此首先介绍zip规范。在docx中,使用python标准库zipfile对docx格式文件进行读写。
ZIP读取
ZIP读取的逻辑定义在docx.opc.phys_pkg模块中:
class _ZipPkgReader(PhysPkgReader):
"""Implements |PhysPkgReader| interface for a zip file OPC package."""
def __init__(self, pkg_file):
super(_ZipPkgReader, self).__init__()
self._zipf = ZipFile(pkg_file, "r")
def blob_for(self, pack_uri):
"""Return blob corresponding to `pack_uri`.
Raises |ValueError| if no matching member is present in zip archive.
"""
return self._zipf.read(pack_uri.membername)
def close(self):
"""Close the zip archive, releasing any resources it is using."""
self._zipf.close()
def rels_xml_for(self, source_uri):
"""Return rels item XML for source with `source_uri` or None if no rels item is
present."""
try:
rels_xml = self.blob_for(source_uri.rels_uri)
except KeyError:
rels_xml = None
return rels_xml
- 从初始化方法中,可以看出本质是使用zipfile标准库打开一个包文件
- close方法本质是调用zipfile.ZipFile的close方法
- 获取包内某一子文件的数据,就是使用zipfile.ZipFile.read(membername),membername命名规范中,子文件夹内的文件名使用“slash”分隔
- 注意rels_xml_for方法,该方法返回给定packuri下包含关系边集合的xml字符串。即如果实参为“/”,则
source_uri.rels_uri="_rels/.rels";如果实参为“/word/document.xml”, 则source_uri.rels_uri="word/_rels/document.xml.rels"
ZIP写入
源码如下:
class _ZipPkgWriter(PhysPkgWriter):
"""Implements |PhysPkgWriter| interface for a zip file OPC package."""
def __init__(self, pkg_file):
super(_ZipPkgWriter, self).__init__()
self._zipf = ZipFile(pkg_file, "w", compression=ZIP_DEFLATED)
def close(self):
"""Close the zip archive, flushing any pending physical writes and releasing any
resources it's using."""
self._zipf.close()
def write(self, pack_uri, blob):
"""Write `blob` to this zip package with the membername corresponding to
`pack_uri`."""
self._zipf.writestr(pack_uri.membername, blob)
- 可以看到_ZipPkgWriter本质使用的是标准库zipfile内置的功能。
解包
解包涉及两大阶段,序列化与编排,其中序列化是指创建序列化的关系边与包内节点。编排是指:1.根据PartFactory解析序列化包内节点,创建Part或者其子类的实例对象;2.处理序列化关系,为Part或者其子类的实例对象添加关系边集合。
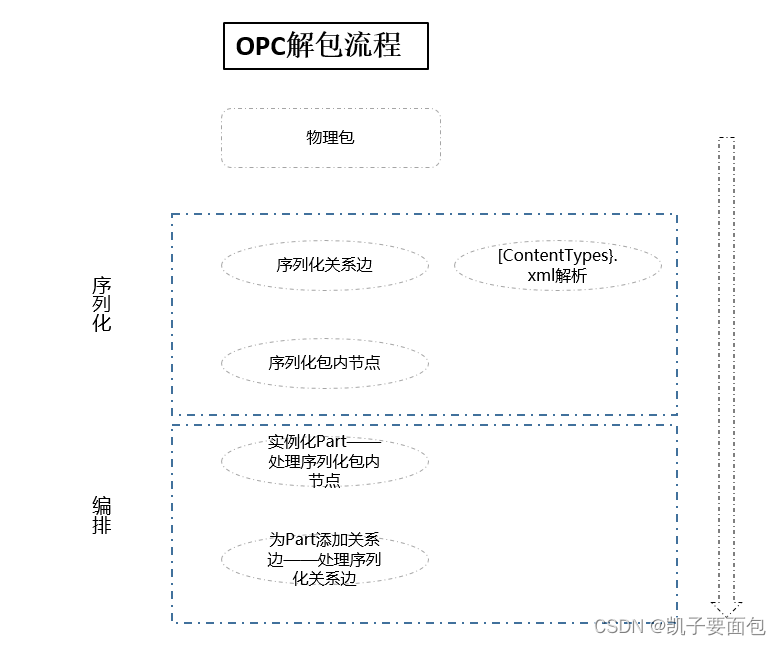
序列化
[Content_Types].xml解析
“[Content_Types].xml”定义了包内节点的content_type类型。由于创建包内节点必须指明节点的类型,因此必须首先解析“[Content_Types].xml”文件。docx.opc.pkgreader模块中定义的[Content_Types].xml处理逻辑如下:
class _ContentTypeMap:
"""Value type providing dictionary semantics for looking up content type by part
name, e.g. ``content_type = cti['/ppt/presentation.xml']``."""
def __init__(self):
super(_ContentTypeMap, self).__init__()
self._overrides = CaseInsensitiveDict()
self._defaults = CaseInsensitiveDict()
@staticmethod
def from_xml(content_types_xml):
"""Return a new |_ContentTypeMap| instance populated with the contents of
`content_types_xml`."""
types_elm = parse_xml(content_types_xml)
ct_map = _ContentTypeMap()
for o in types_elm.overrides:
ct_map._add_override(o.partname, o.content_type)
for d in types_elm.defaults:
ct_map._add_default(d.extension, d.content_type)
return ct_map
- _ContentTypeMap的实例属性_overrides是一个类似字典对象,key为partname,值为part_content_type。实例属性_defaults也是一个类似字典的对象,key为partname后缀,如xml、rels、jpg等,值为part_content_type。
- from_xml实例方法中,content_type_xmls本质是“[Content_Types].xml”文件的内容——通过ZipFile打开docx物理文件,然后读取[Content_Types].xml内容。 parse_xml用于将xml字符串解析成元素树,注意parser_xml方法中使用的是docx自定义的解析器——该解析器设置并注册了xml命名空间。后续的逻辑则是迭代CT_Override与CT_Default元素。
序列化关系边
创建包内节点需要指明其包含的关系边信息,因此需要先解析关系边。单条的序列化关系边定义,注意:
Serialized relationship means any target part is referred to via its partname rather than a direct link to an in-memory |Part| object.
序列化的关系边引用的是partname,而不是一个Part或者子类的实例对象——因为该对象还未被创建。
class _SerializedRelationship:
"""Value object representing a serialized relationship in an OPC package.
Serialized, in this case, means any target part is referred to via its partname
rather than a direct link to an in-memory |Part| object.
"""
def __init__(self, baseURI, rel_elm):
super(_SerializedRelationship, self).__init__()
self._baseURI = baseURI
self._rId = rel_elm.rId
self._reltype = rel_elm.reltype
self._target_mode = rel_elm.target_mode
self._target_ref = rel_elm.target_ref
@property
def target_partname(self):
"""|PackURI| instance containing partname targeted by this relationship.
Raises ``ValueError`` on reference if target_mode is ``'External'``. Use
:attr:`target_mode` to check before referencing.
"""
if self.is_external:
msg = (
"target_partname attribute on Relationship is undefined w"
'here TargetMode == "External"'
)
raise ValueError(msg)
# lazy-load _target_partname attribute
if not hasattr(self, "_target_partname"):
self._target_partname = PackURI.from_rel_ref(self._baseURI, self.target_ref)
return self._target_partname
- 实例化方法中的baseURI用于target_partname特性。rel_ele是一个CT_Relationship元素。
- 单条关系边只是rels格式文件中的一条记录,rels格式文件一般包含多条关系边。
- baseURI一般是指包含rels格式文件的文件夹。
- CT_Relationship中的target_ref特性存储的是“CT_Relationship元素Target属性值”。
序列化关系边集合定义如下:
class _SerializedRelationships:
"""Read-only sequence of |_SerializedRelationship| instances corresponding to the
relationships item XML passed to constructor."""
def __init__(self):
super(_SerializedRelationships, self).__init__()
self._srels = []
@staticmethod
def load_from_xml(baseURI, rels_item_xml):
"""Return |_SerializedRelationships| instance loaded with the relationships
contained in `rels_item_xml`.
Returns an empty collection if `rels_item_xml` is |None|.
"""
srels = _SerializedRelationships()
if rels_item_xml is not None:
rels_elm = parse_xml(rels_item_xml)
for rel_elm in rels_elm.Relationship_lst:
srels._srels.append(_SerializedRelationship(baseURI, rel_elm))
return srels
- rels_item_xml是指存储关系边集合的rels格式文件的xml字符串
- parse_xml(rels_item_xml)返回CT_Relationships元素
序列化包内节点
获取了包内节点的content_type、partname、序列化关系边,就可以创建序列化的包内节点对象。序列化包内节点定义如下,注意:
Serialized part provides access to the partname, content type, blob, and serialized relationships for the part.
序列化包内节点此时还是一个容器节点,只包含partname、content_type、reltype、blob、srels属性。注意此时仅有blob,对于XML文件,并没有解析成元素树(etree.ElementTree)。从下文可知,对于序列化的XML part节点,需要使用docx中的PartFactory,实例化成Part或者Part子类的实例对象。
class _SerializedPart:
"""Value object for an OPC package part.
Provides access to the partname, content type, blob, and serialized relationships
for the part.
"""
def __init__(self, partname, content_type, reltype, blob, srels):
super(_SerializedPart, self).__init__()
self._partname = partname
self._content_type = content_type
self._reltype = reltype
self._blob = blob
self._srels = srels
- reltype特性存储CT_Relationshp元素Type属性值——每一包内节点对象总是与包根节点或者其它p包内节点关联。
- srels是指该包内节点是否存在节点级别的关系边集合。
PackageReader封装序列化流程
PackageReader类将解包中的第一大阶段序列化整个流程封装了起来:1.处理[Content_Types].xml, 2. 从包级别关系出发,序列化关系边、序列化包节点,3.如果包内节点包含关系边,则重复第二步骤——本质是深度优先遍历,此时从节点关系边出发,创建被引用的序列化包节点。
class PackageReader:
"""Provides access to the contents of a zip-format OPC package via its
:attr:`serialized_parts` and :attr:`pkg_srels` attributes."""
def __init__(self, content_types, pkg_srels, sparts):
super(PackageReader, self).__init__()
self._pkg_srels = pkg_srels
self._sparts = sparts
@staticmethod
def from_file(pkg_file):
"""Return a |PackageReader| instance loaded with contents of `pkg_file`."""
phys_reader = PhysPkgReader(pkg_file)
content_types = _ContentTypeMap.from_xml(phys_reader.content_types_xml)
pkg_srels = PackageReader._srels_for(phys_reader, PACKAGE_URI)
sparts = PackageReader._load_serialized_parts(
phys_reader, pkg_srels, content_types
)
phys_reader.close()
return PackageReader(content_types, pkg_srels, sparts)
......
-
实例属性_pkg_srels表示包级别的关系边集合,实例属性_sparts表示序列化的包内节点集合。一般不直接创建PackageReader实例,而是通过from_file类方法创建实例。
-
from_file方法中,第一句本质是实例化_ZipPkgReader。
-
第二句是解析[Content_Types].xml
-
类方法_srels_for定义如下:
@staticmethod def _srels_for(phys_reader, source_uri): """Return |_SerializedRelationships| instance populated with relationships for source identified by `source_uri`.""" rels_xml = phys_reader.rels_xml_for(source_uri) return _SerializedRelationships.load_from_xml(source_uri.baseURI, rels_xml)- 结合定义,在第三句中,传入的第一个实参就是实例化的_ZipPkgReader;传入的第二个实参就是PACKAGR_URI——包级别的关系边集合source对象就是package根节点。
- phys_reader.rels_xml_for(source_uri)就是获取"/_rel/.rels.xml"文件的xml字符串。
- 当“packuri”取值为“/”时,其baseURI依然为“/”——这是个特例,一般baseURI是packuri的目录部分。
-
类方法_load_serialized_parts的定义如下:
@staticmethod def _load_serialized_parts(phys_reader, pkg_srels, content_types): """Return a list of |_SerializedPart| instances corresponding to the parts in `phys_reader` accessible by walking the relationship graph starting with `pkg_srels`.""" sparts = [] part_walker = PackageReader._walk_phys_parts(phys_reader, pkg_srels) for partname, blob, reltype, srels in part_walker: content_type = content_types[partname] spart = _SerializedPart(partname, content_type, reltype, blob, srels) sparts.append(spart) return tuple(sparts)-
该方法从包级别的关系出发,根据深度优先的策略,返回序列化包内节点列表。
-
深度优先的实现定义在类方法_walk_phys_parts:
@staticmethod def _walk_phys_parts(phys_reader, srels, visited_partnames=None): """Generate a 4-tuple `(partname, blob, reltype, srels)` for each of the parts in `phys_reader` by walking the relationship graph rooted at srels.""" if visited_partnames is None: visited_partnames = [] for srel in srels: if srel.is_external: continue partname = srel.target_partname if partname in visited_partnames: continue visited_partnames.append(partname) reltype = srel.reltype part_srels = PackageReader._srels_for(phys_reader, partname) blob = phys_reader.blob_for(partname) yield (partname, blob, reltype, part_srels) next_walker = PackageReader._walk_phys_parts( phys_reader, part_srels, visited_partnames ) for partname, blob, reltype, srels in next_walker: yield (partname, blob, reltype, srels)其中最核心的部分在:1)part_srels = PackageReader._srels_for(phys_reader, partname),用于加载节点级别的关系边集合;2)next_walker = PackageReader._walk_phys_parts(phys_reader, part_srels, visited_partnames),如果节点级别的关系边集合不为空,则将该包内节点作为一个根节点,创建与其关联的其它序列化包内节点。
-
数据编排
在解包的第一大阶段序列化中,解析了包内的“[Content_Types].xml”文件,创建了序列化的关系边与包内节点。但是docx文档的主体word/document.xml、文档属性、style、media等xml文件或者非xml文件中包含的字节流并未被解析,比如文档属性并未被解析成元素树。因此还需要数据编排第二大阶段。OPC中的数据编排定义在docx.opc.package.Unmarshaller,抽象包定义于docx.opc.package.OpcPackage。
Unmarshaller定义
Unmarshaller类封装了完整的数据编排逻辑:
class Unmarshaller:
"""Hosts static methods for unmarshalling a package from a |PackageReader|."""
@staticmethod
def unmarshal(pkg_reader, package, part_factory):
"""Construct graph of parts and realized relationships based on the contents of
`pkg_reader`, delegating construction of each part to `part_factory`.
Package relationships are added to `pkg`.
"""
parts = Unmarshaller._unmarshal_parts(pkg_reader, package, part_factory)
Unmarshaller._unmarshal_relationships(pkg_reader, package, parts)
for part in parts.values():
part.after_unmarshal()
package.after_unmarshal()
-
类方法unmarshal将进一步处理序列化的包内节点与关系边,位置参数pkg_reader本质是一个封装序列化的包内节点与关系边的集合,package是抽象包,part_factory用于创建Part或其子类的实例——后续会介绍该部分。
-
类方法_unmarshal_parts用于编排包内节点,类方法定义如下:
@staticmethod def _unmarshal_parts(pkg_reader, package, part_factory): """Return a dictionary of |Part| instances unmarshalled from `pkg_reader`, keyed by partname. Side-effect is that each part in `pkg_reader` is constructed using `part_factory`. """ parts = {} for partname, content_type, reltype, blob in pkg_reader.iter_sparts(): parts[partname] = part_factory( partname, content_type, reltype, blob, package ) return parts- 本质是迭代序列化包内节点集合,并根据节点的content_type,实例化成Part或者其子类的实例对象。
-
类方法_unmarshal_relationships本质是迭代序列化关系边,并建立package与part,或者part与part之间的连接关系。
@staticmethod
def _unmarshal_relationships(pkg_reader, package, parts):
"""Add a relationship to the source object corresponding to each of the
relationships in `pkg_reader` with its target_part set to the actual target part
in `parts`."""
for source_uri, srel in pkg_reader.iter_srels():
source = package if source_uri == "/" else parts[source_uri]
target = (
srel.target_ref if srel.is_external else parts[srel.target_partname]
)
source.load_rel(srel.reltype, target, srel.rId, srel.is_external)
- 注意OpcPackage与Part类都定义了load_rel方法。
PartFactory
序列化包内节点集合转换为各种类型——Part、XmlPart的实例,的过程由PartFactory管理。PartFactory完整定义如下所示:
class PartFactory:
"""Provides a way for client code to specify a subclass of |Part| to be constructed
by |Unmarshaller| based on its content type and/or a custom callable.
Setting ``PartFactory.part_class_selector`` to a callable object will cause that
object to be called with the parameters ``content_type, reltype``, once for each
part in the package. If the callable returns an object, it is used as the class for
that part. If it returns |None|, part class selection falls back to the content type
map defined in ``PartFactory.part_type_for``. If no class is returned from either of
these, the class contained in ``PartFactory.default_part_type`` is used to construct
the part, which is by default ``opc.package.Part``.
"""
part_class_selector: Callable[[str, str], Type[Part] | None] | None
part_type_for: Dict[str, Type[Part]] = {}
default_part_type = Part
def __new__(
cls,
partname: str,
content_type: str,
reltype: str,
blob: bytes,
package: Package,
):
PartClass: Type[Part] | None = None
if cls.part_class_selector is not None:
part_class_selector = cls_method_fn(cls, "part_class_selector")
PartClass = part_class_selector(content_type, reltype)
if PartClass is None:
PartClass = cls._part_cls_for(content_type)
return PartClass.load(partname, content_type, blob, package)
@classmethod
def _part_cls_for(cls, content_type: str):
"""Return the custom part class registered for `content_type`, or the default
part class if no custom class is registered for `content_type`."""
if content_type in cls.part_type_for:
return cls.part_type_for[content_type]
return cls.default_part_type
-
如果PartFactory.part_class_selector是一个可调用对象,则将content_type与reltype作为实参传入,返回类型为Part或者None。
-
如果PartFactory.part_class_selector未定义、或者返回None,则在类属性part_type_for——字典对象,key为content_type,检查当前序列化包内节点的content_type是否在字典内,如果存在,则返回对应的Part类,使用返回的Part类来解析序列化包内节点包含的blob字节流。如果不存在,则使用默认的docx.opc.part.Part类。
-
在docx库初始化模块(docx.__init__.py)中,对PartFactory进行了配置, 指明了不同类型的 part,采用不同的 Part 类来实例化。
def part_class_selector(content_type, reltype): if reltype == RT.IMAGE: return ImagePart return None PartFactory.part_class_selector = part_class_selector PartFactory.part_type_for[CT.OPC_CORE_PROPERTIES] = CorePropertiesPart PartFactory.part_type_for[CT.WML_DOCUMENT_MAIN] = DocumentPart PartFactory.part_type_for[CT.WML_FOOTER] = FooterPart PartFactory.part_type_for[CT.WML_HEADER] = HeaderPart PartFactory.part_type_for[CT.WML_NUMBERING] = NumberingPart PartFactory.part_type_for[CT.WML_SETTINGS] = SettingsPart PartFactory.part_type_for[CT.WML_STYLES] = StylesPart
以编排 “/docProps/core.xml” 为例,该序列化的节点中包含 “/docProps/core.xml” partname、content_type、reltype、blob 值,其content_type值为CT.OPC_CORE_PROPERTIES,因此选择CorePropertiesPart 类来解析对应的blob值,最终将blob解析成CT_CoreProperties。
OpcPackage封装完整解包流程
抽象包的逻辑定义在OpcPackage内。本部分介绍完整的解包流程、及从图数据结构来看抽象包的一个基础功能。
解包完整流程
class OpcPackage:
"""Main API class for |python-opc|.
A new instance is constructed by calling the :meth:`open` class method with a path
to a package file or file-like object containing one.
"""
def __init__(self):
super(OpcPackage, self).__init__()
@classmethod
def open(cls, pkg_file):
"""Return an |OpcPackage| instance loaded with the contents of `pkg_file`."""
pkg_reader = PackageReader.from_file(pkg_file)
package = cls()
Unmarshaller.unmarshal(pkg_reader, package, PartFactory)
return package
抽象包通过类方法open创建,在open类方法中,第一句本质是序列化,第二步创建一个空的抽象包容器,第三步是数据编排,最终返回抽象包。
图数据结构
创建了抽象包,如果对docx格式文件进行更新呢——更新word/document.xml内容?根据图数据结构的概念,其实很简单,从包的根节点出发,根据特定的package_level级别关系——RT.OFFICE_DOCUMENT就可以找到word/document.xml对应的DocumentPart,然后获取CT_Document元素,对该元素进行修改即可。
@property
def main_document_part(self):
"""Return a reference to the main document part for this package.
Examples include a document part for a WordprocessingML package, a presentation
part for a PresentationML package, or a workbook part for a SpreadsheetML
package.
"""
return self.part_related_by(RT.OFFICE_DOCUMENT)
def part_related_by(self, reltype):
"""Return part to which this package has a relationship of `reltype`.
Raises |KeyError| if no such relationship is found and |ValueError| if more than
one such relationship is found.
"""
return self.rels.part_with_reltype(reltype)
@lazyproperty
def rels(self):
"""Return a reference to the |Relationships| instance holding the collection of
relationships for this package."""
return Relationships(PACKAGE_URI.baseURI)
- 实例方法part_related_by返回包级别,reltype为传入实参值对应的Part实例对象。
- rels特性是指包级别关系边集合。
基于解包优化"There is no item named ‘word/NULL’ in the archive"异常
在执行docx.api.Document(filepath)时,如果抛出以上异常,通常原因是因为’word/_rels/document.xml.rels’文件中,某一CT_Relationship的Target属性值为“NULL”,因此可以重定义_SerializedRelationships的类方法load_from_xml,解决方案如下:
from docx.opc.oxml import parse_xml
from docx.opc.pkgreader import _SerializedRelationships, _SerializedRelationship
def load_from_xml(baseURI, rels_item_xml):
"""Return |_SerializedRelationships| instance loaded with the relationships
contained in `rels_item_xml`.
Returns an empty collection if `rels_item_xml` is |None|.
"""
srels = _SerializedRelationships()
if rels_item_xml is not None:
rels_elm = parse_xml(rels_item_xml)
for rel_elm in rels_elm.Relationship_lst:
if rel_elm.get("Target") == "NULL":
continue # 忽略此类part节点
srels._srels.append(_SerializedRelationship(baseURI, rel_elm))
return srels
# 覆盖原定义
setattr(_SerializedRelationships, "load_from_xml", load_from_xml)
小结
本文结合OPC标准与docx三方库源码,对解包流程——从物理包创建抽象包,进行了详细的介绍,解包大致分为两大阶段,其一是序列化,及创建序列化的关系边与包内节点,该过程是一个深度优先遍历的过程,需注意此时的虚拟化包内节点并未将其blob字节流解析成元素树。对于XML类型的包内节点,解析字节流由PartFactory控制。真个解包流程相对比较复杂,需仔细理解。最后基于解包流程,对’word/NULL’ 异常进行了优化。















 2285
2285











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









