







目录
1机器学习(分类简介)
基本原始准备:Big O 符号;队列queues,堆栈stacks,二叉树binary trees; 概率(random variable,the expected value of a random variable,方差);线性代数(matrix,vector,矩阵相乘,矩阵与向量相乘,特征向量eigenvector)
1.监督学习:已知X和Y(人工标注)同时输入,将输入数据映射到输出,再输入另一个X时,可以预测Y。回归(输出是连续变化的),分类(输出是离散的)
| 回归 | 分类 |
|
|
|


2.无监督学习:不输入Y,自己寻找输入数据的有趣变化。方法(降维,聚类)。data clustering,anomaly detection异常监测
3.自监督学习:已知X和Y(没有人工标注的标签)=没有人工参与的监督学习
4.强化学习:学会奖励最大化的行动。类似训练狗,并不知道怎么是最终模型,但是狗表现好时说‘good dog’,表现不好时说‘bad dog’,慢慢就训练好了。有和环境交互反馈的过程。自动驾驶,AlphaGo,智能控制系统


下面讲的部分是:————机器学习(下的)→监督学习(下的)→线性回归
2线性回归(linear regression)

2.1 如何根据样本数据估计模型参数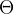 ?
?
| 两种 |
A:ordinary least square 几何法 |
B:maximum likelihood estimation 概率法(也可以 贝叶斯估计) |
| 估计模型参数 的方法 |
 |
 |
|
|
假设误差项服从高斯分布 |


 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1078
1078

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









