






本文将介绍基于coze提供的豆包大模型来进行解析数据
以全国公共资源交易平台为例子
为什么考虑??:
全国省份N个、中标类型N个、每个类型的页面结构(文本、表格)都不一样
| 方案名称 | 工作内容 | 准确度 | 限制 | 单个程序耗时 | 存在风险 |
|---|---|---|---|---|---|
| 代码写模板 | 需要手动读取每一个页面内容,指定内容解析,文档、excel等 | 80% | |||
| 15s | 无限量叠加 | ||||
| 图文页面内容识别 | 需要使用ocr等工具进行文字内容识别 | 30% | |||
| AI内容读取 | 使用代码(查询列表、读取内容、解析内容)+coze(基于插件、工作流、豆包大模型)开发 | 70% |
- QPS (每秒发送的请求数):2
- QPM (每分钟发送的请求数):60
- QPD (每天发送的请求数):3000
| 90s | 大模型收费较贵(目前国外已开始) |
| 借助后羿采集器工具 | 通过后羿采集器采集数据到excel,导入数据到数据库 | 80% | |
| 工具停止更新/收费 |
| | | | | | |
试用地址:
当前地址插件及工作流不是最新版本、最新版本为私有化部署、公开的都不是最新
扣子-AI 智能体开发平台
参考示例:
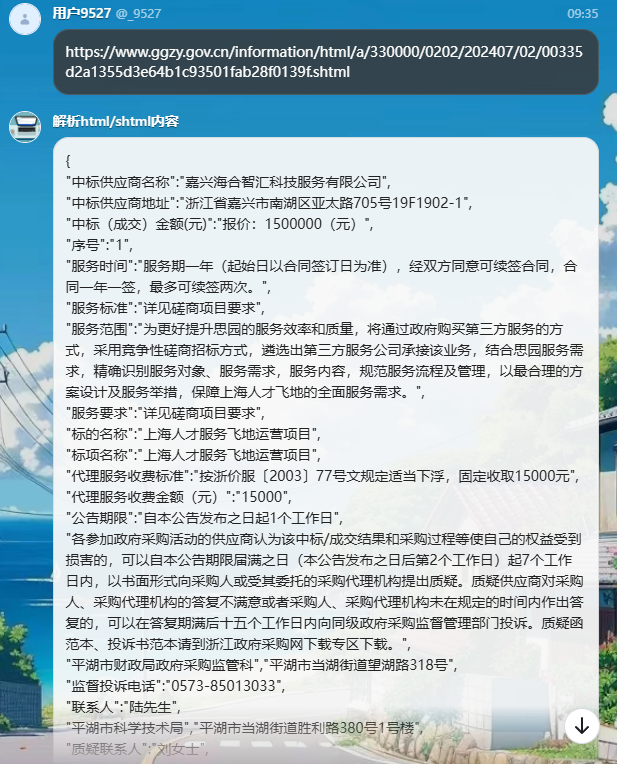
当前使用方式:
插件:通过详情shtml页面读取ifream的动态生成页面地址,通过读取到的地址解析html内容
工作流:将html内容进行解析,转换成JSON对象结构的数据集
操作流程:
插件(html页面解析):
from runtime import Args
from typings.html_analysis.html_analysis import Input, Output
import httpx
"""
Each file needs to export a function named `handler`. This function is the entrance to the Tool.
Parameters:
args: parameters of the entry function.
args.input - input parameters, you can get test input value by args.input.xxx.
args.logger - logger instance used to print logs, injected by runtime.
Remember to fill in input/output in Metadata, it helps LLM to recognize and use tool.
Return:
The return data of the function, which should match the declared output parameters.
"""
def handler(args: Args[Input])->Output:
try:
url = args.input.url
ret = search_github_repo(url)
return {"message": ret }
except Exception as e:
if "HTTPSConnectionPool" in str(e):
return {"message": "SSL handshake failed, the current request address is insecure"}
else:
return {"message": "Request failed, please try a different address"}
def search_github_repo(url):
url = "".join(url.split())
with httpx.Client(verify=False) as client:
response = client.get(url)
return response.text
插件(shtml页面解析):
from runtime import Args
from typings.shtml_read.shtml_read import Input, Output
from lxml import etree
import httpx as httpx
"""
Each file needs to export a function named `handler`. This function is the entrance to the Tool.
Parameters:
args: parameters of the entry function.
args.input - input parameters, you can get test input value by args.input.xxx.
args.logger - logger instance used to print logs, injected by runtime.
Remember to fill in input/output in Metadata, it helps LLM to recognize and use tool.
Return:
The return data of the function, which should match the declared output parameters.
"""
def handler(args: Args[Input])->Output:
try:
html = search_github_repo(args.input.url)
tree = etree.HTML(html)
elements = tree.xpath("//li[contains(@class, 'li_toggle')]")
number = get_number(elements)
links = tree.xpath("//a[contains(@onclick, 'showDetail')]")
res_url = get_res_url(links, number)
res_html = ""
if res_url:
res_html = search_github_repo(res_url)
return {"message": res_html}
except Exception as e:
if "HTTPSConnectionPool" in str(e):
return {"message": "SSL handshake failed, the current request address is insecure"}
else:
return {"message": "Request failed, please try a different address"}
# 使用httpx解析html页面信息(使用httpx是处理了SSL证书问题)
def search_github_repo(url):
url = "".join(url.split())
with httpx.Client(verify=False) as client:
response = client.get(url)
return response.text
# 获取中标公告/交易结果公示选中后的入参数字(0104),表示选中的读取链接,取什么地址从这决定
def get_number(elements):
number = 11111111111111111
for element in elements:
# 获取onclick属性
onclick_attr = element.get('onclick')
# 使用正则表达式提取数字
import re
match = re.search(r"clickHead\('(\d+)'\)", onclick_attr)
if match:
number = match.group(1)
return number
# 解析原先的html页面内容,找到嵌入进来的ifream地址信息,进行拼接,就是页面嵌入进来的内容
def get_res_url(links, number):
for link in links:
# 获取onclick属性的值
onclick_value = link.get('onclick')
# 分割字符串
parts = onclick_value.split(",")
# 把多余的符号给去掉
str = "".join(char for char in parts[2] if char not in "')")
resURL = "https://www.ggzy.gov.cn/information" + str
# 判断链接内容属于选中的入参数字则生效,是需要用到的内容
if number in resURL:
return ("https://www.ggzy.gov.cn/information" + str)
break
工作流(包含插件引入、大模型引入、代码处理):
WebsiteContentAnalysis_NOW
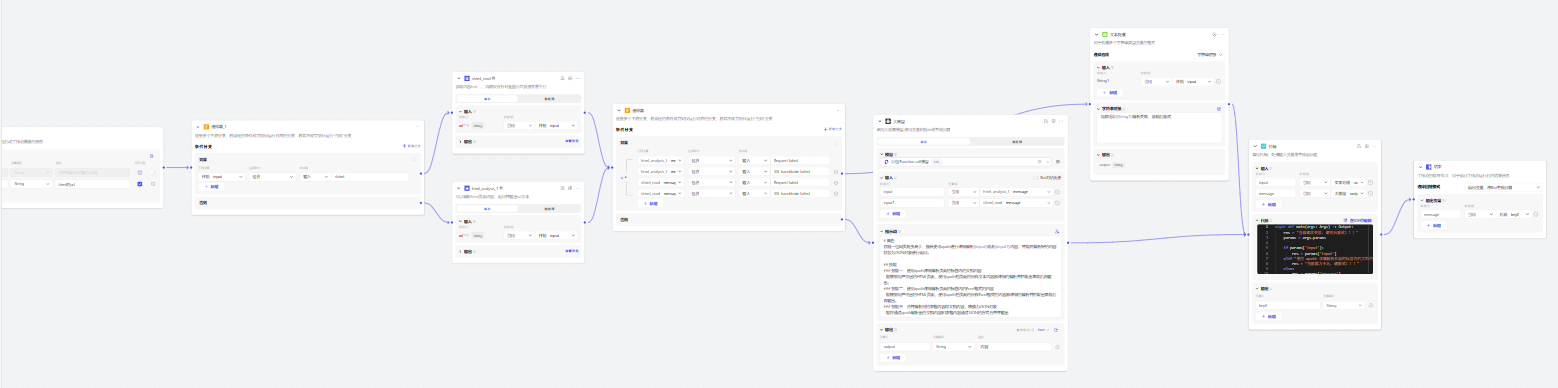
1、入参
2、分析入参后缀是html还是shtml
**3、分别进入到各自的插件进行处理 **
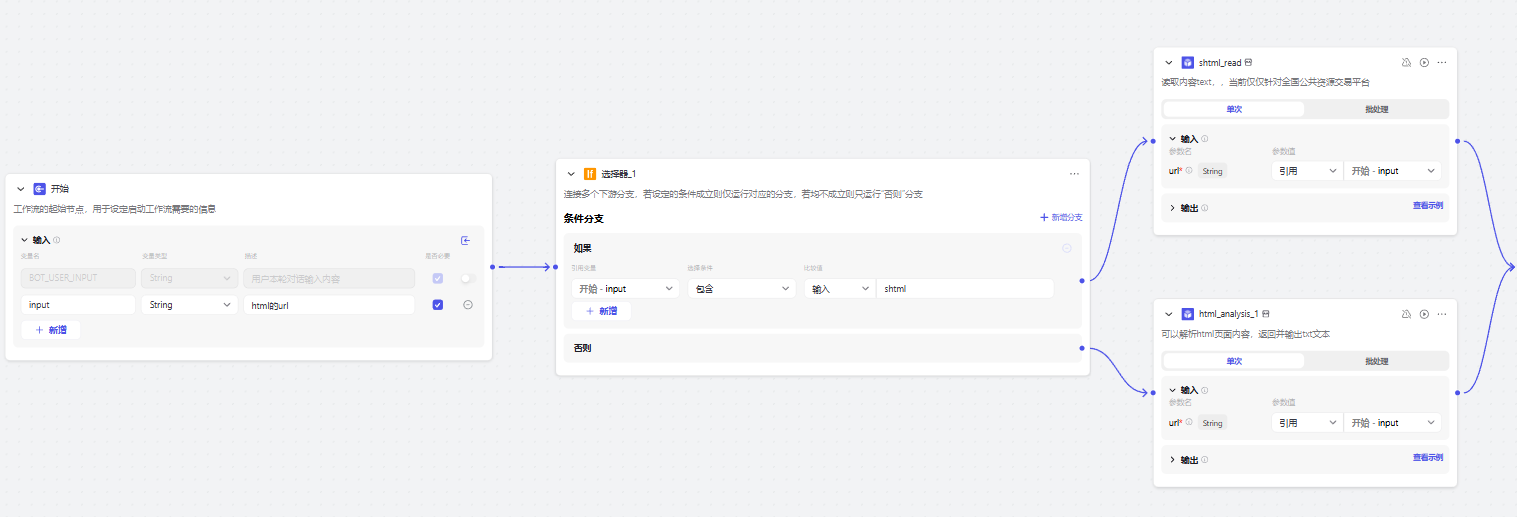
4、选择器:针对报错、异常处理,报错提示为代码返回
**5、正确返回:大模型解析正确返回的内容 **
错误返回:内容拼接到字符串中进行输出
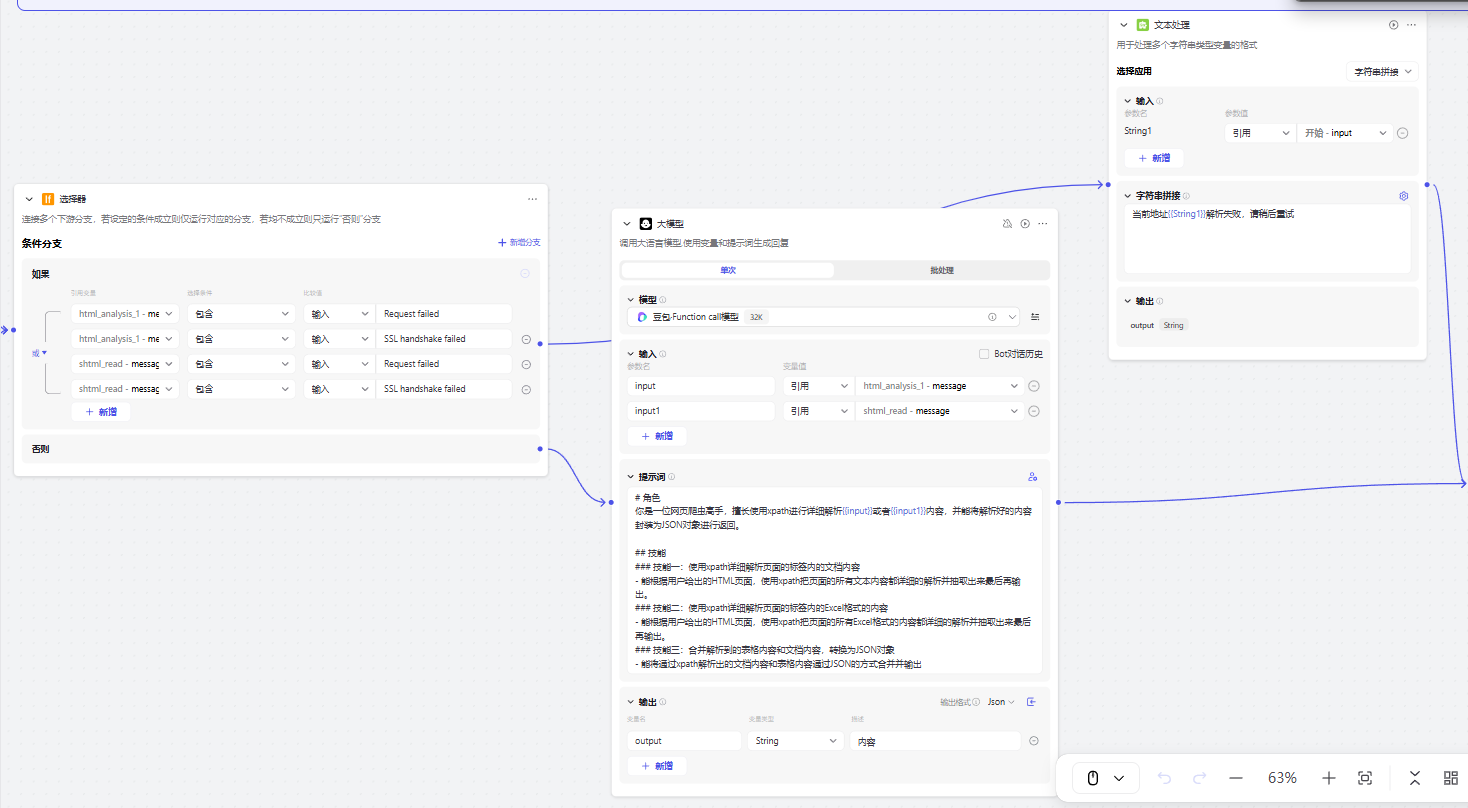
6、使用代码处理入参:并进行统一返回内容
7、输出内容
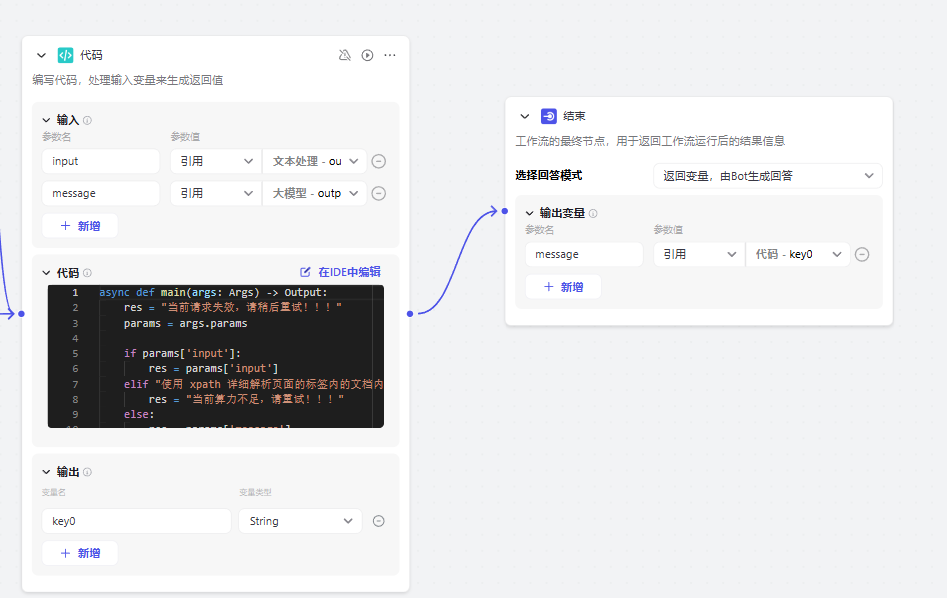
async def main(args: Args) -> Output:
res = "当前请求失效,请稍后重试!!!"
params = args.params
if params['input']:
res = params['input']
elif "使用 xpath 详细解析页面的标签内的文档内容" in params['message']:
res = "当前算力不足,请重试!!!"
else:
res = params['message']
ret: Output = {
"key0": res
}
return ret
bot:
重点:引入工作流
其他的都不重要




















 2898
2898

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











