







- 正则表达式入门练习网站:https://www.codejiaonang.com/#/course/regex_chapter1/0/0
- 正则表达式进阶练习网站:https://www.codejiaonang.com/#/course/regex_chapter2/0/0
1.初级进阶知识
- 匹配特殊字符
正则表达式用-表达区间,但有时我们需要在正则表达式中使用符号-这时就该使用转义字符\,完整\-
\也适用于其他符号
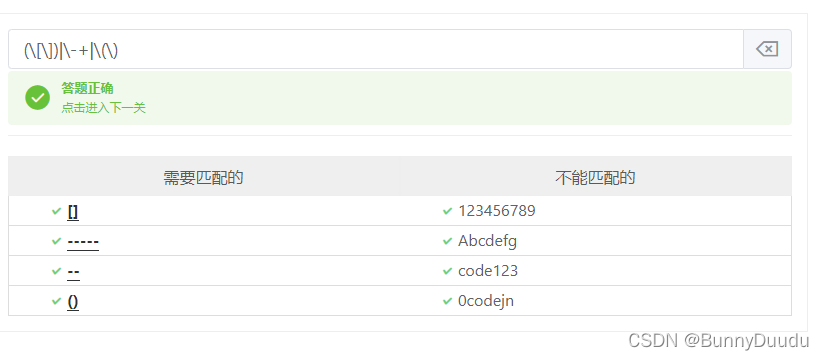
-
单词边界——
\b
单词边界:单词与符号之间的边界;这里的单词可以指“中文字符,英文字符,数字”;符号可以是“中文符号,英文符号,空格,制表符,换行符”
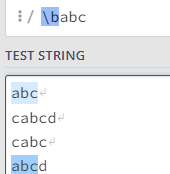
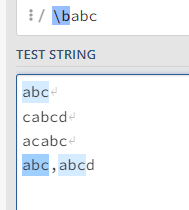
\b 在所需单词两端的情况:\babc\b

确保只选中单独出现的abc
\b在字符串前:\babc,只有在abc字符串前没有字符时才可选中
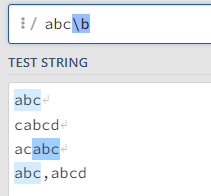
\b在字符串后:abc\b,只有在abc字符串后没有字符才可选中
-
区间的非贪婪模式
重复区间,例如身份证有15位也有18位,这时就该使用重复区间匹配
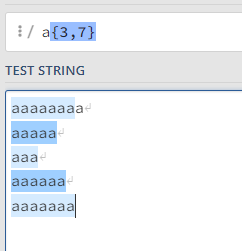
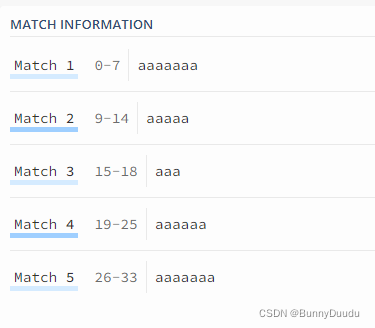
语法:{N,M},M是上界,N是下届
例如:{15,18},匹配15到18次
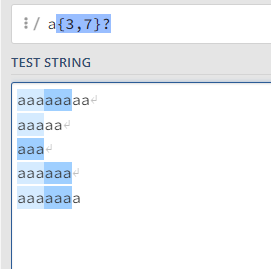
正则表达式默认是贪婪模式,若要改为非贪婪模式则在{N,M}?即可,这时会以最少的匹配次数来进行匹配

2.阶段进阶知识
非捕获分组:非捕获分组只匹配结果,但是不会捕获结果,也不会分配组号
语法:(?:表达式)
正常使用分组:
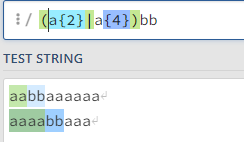
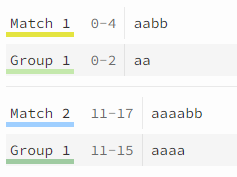
非捕获分组:
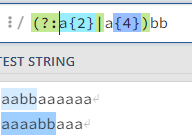
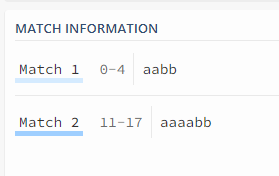
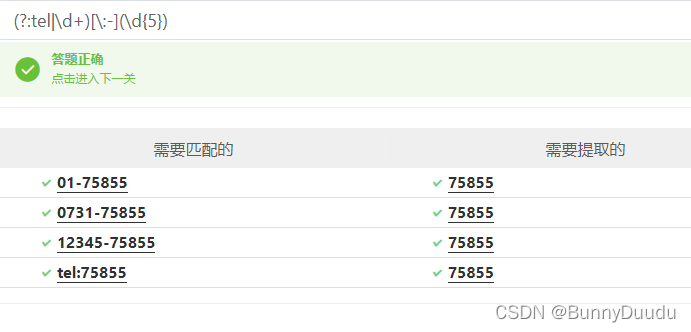
举例:例如提取目标数据中的电话号码
分组提取:(tel|\d+)[\:-](\d{5}),会将电话号码前的数据也提取进来
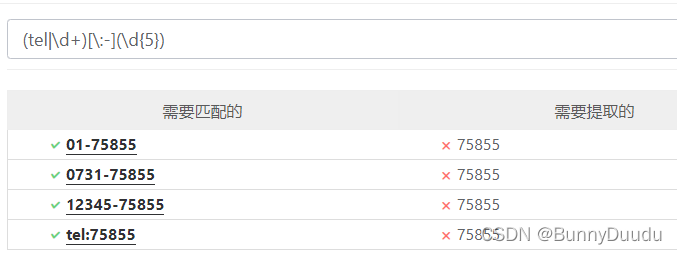
非捕获分组:可以舍弃掉前面的字符匹配,只保留需要的
2.1 分组的回溯引用
若要匹配一段HTML代码,例如0123<font>提示</font>abcd,这时我们就可以寻找一个子匹配,若接下来该匹配会挨次出现,可以使用\N引用编号为N的分组
语法:<\(w+)>.*?</\1>
用来匹配一段正确的HTML标签
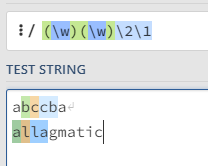
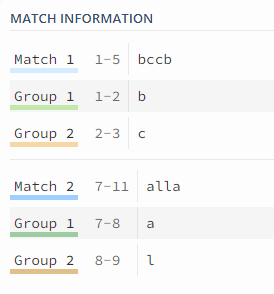
若要匹配abba类型的
语法:(\w)(\w)\2\1
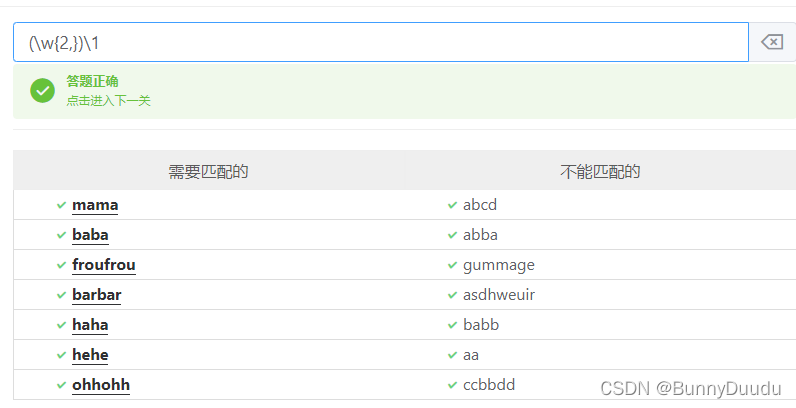
若要匹配abab类型的
语法:(\w{2,})\1
2.2 先行断言(预搜索)—— 从左往右看
- 正向先行断言:
(?=表达式),表示从某个位置向右看,表示所在位置右侧必须能匹配表达式,判断字符串是否符合特定规则
正向先行断言可以说就是制定规则
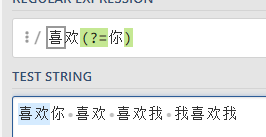
举例1:喜欢你 喜欢 喜欢我 我喜欢我
如果要提取出喜欢二字,并要求这个喜欢后面有你
语法:喜欢(?=你),这便是正向先行断言
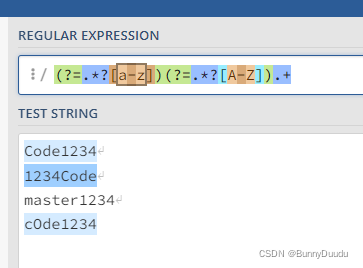
举例2:提取至少含有一个大小写的字符串
语法:(?=.*?[a-z])(?=.*?[A-Z]).+
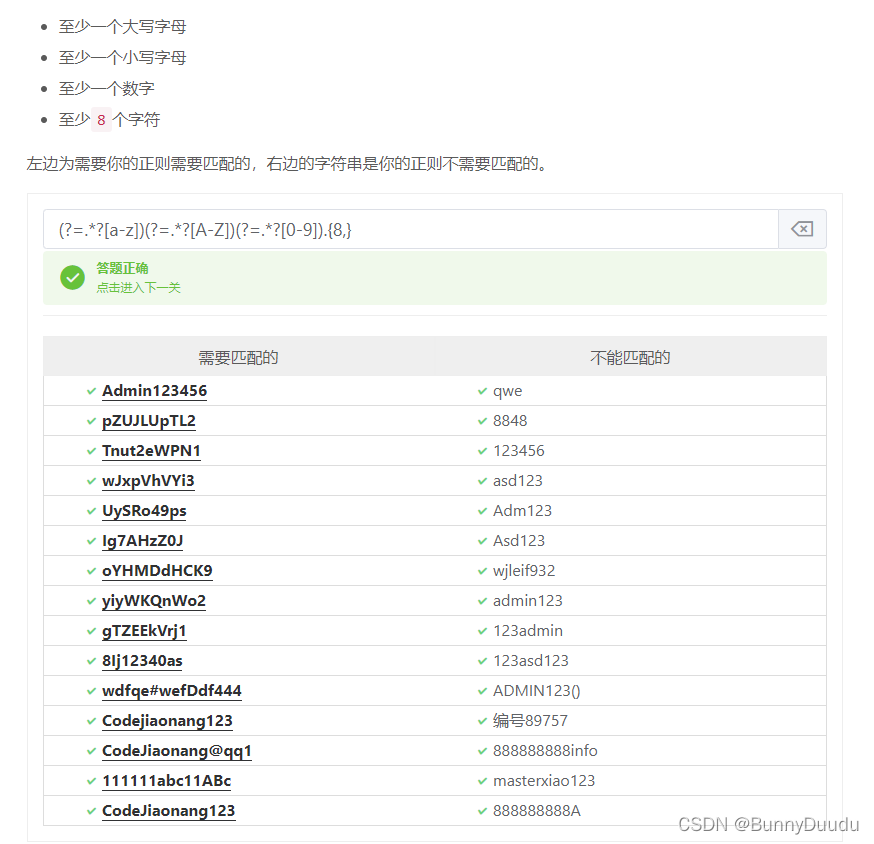
举例3:
语法:(?=.*?[a-z])(?=.*?[A-Z])(?=.*?[0-9]).{8,}
- 反向先行断言:
(?!表达式),保证该式子右边不能出现某字符
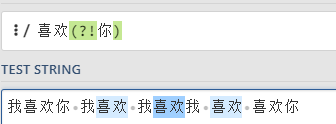
举例1:我喜欢你 我喜欢 我喜欢我 喜欢 喜欢你
如果要提取喜欢二字,要求这个喜欢后面没有你
语法:喜欢(?!你)
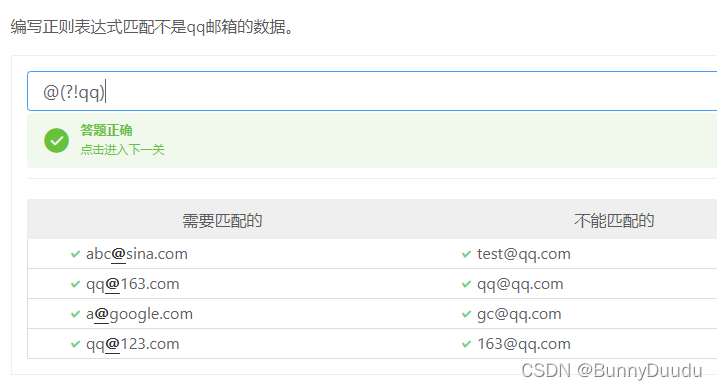
举例2:匹配不是qq邮箱的数据:
语法:@(?!qq)
举例3:匹配标签不是的HTML

2.3 后行断言——从右往左看
-
正向后行断言:
(?<=表达式)从某个位置往左看,表示所在位置左侧必须能比配
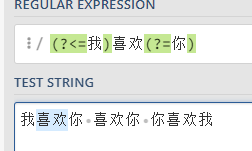
举例1:如果要取出喜欢两字,要求喜欢的前面有我,后面有你
语法:(?<=我)喜欢(?=你)
举例2:匹配王姓同学名字
语法:.(?<=王).+

-
反向后行断言:
(?<!表达式),指某个位置向坐看,表示所在位置左侧不能匹配表达式
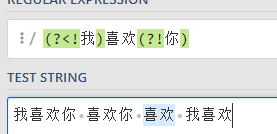
举例:要提取出喜欢二字,前面没有我,后面没有你
语法:(?<!我)喜欢(?!你)
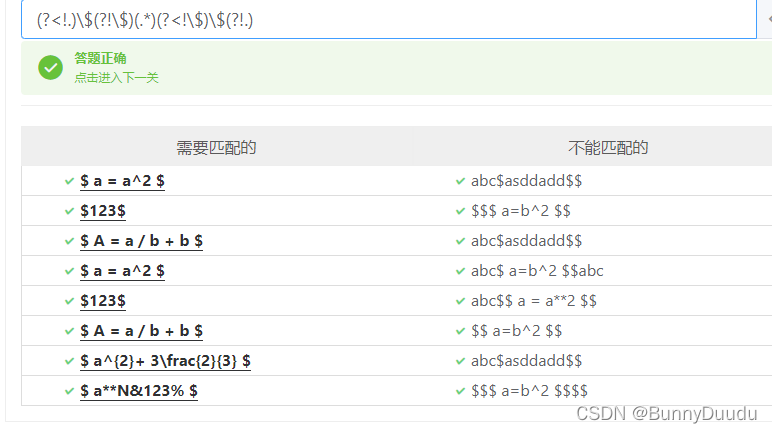
举例2:使用正则表达式提取$中的数据
语法:(?<!.)\$(?!\$)(.*)(?<!\$)\$(?!.)
把表达式拆分开来看:
(?<!.)\$: 使用反向后行断言,代表\$之前不可跟任何字符;
\$(?!\$):使用正向后行断言,代表\$后不可跟$字符;
(.*):代表了$$之间的所有字符;
(?<!\$)\$:使用反向后行断言,代表\$之前不可跟$字符;
\$(?!.):使用正向后行断言,代表\$后不可跟任何字符。














 875
875











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









