







文章目录
导入Pandas包,
import pandas as pd
DataFrame数据是Pandas数据中的多维数据
1.创建DataFrame数据
有两种创建方法:
DataFrame是多维数据所以要使用字典Dict进行创建
默认索引创建:字典中 {'列索引': [list]}
带索引的创建:字典中{'列索引': {'行索引1': 数据, '行索引2': 数据}}
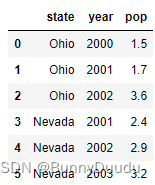
默认索引创建:行索引从0开始
data = {'state': ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada', 'Nevada'],
'year': [2000, 2001, 2002, 2001, 2002, 2003],
'pop': [1.5, 1.7, 3.6, 2.4, 2.9, 3.2]}
frame1 = pd.DataFrame(data)
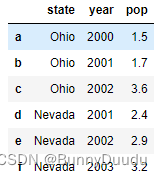
带索引的创建:
data = {'state':{'a': 'Ohio', 'b': 'Ohio','c': 'Ohio', 'd':'Nevada', 'e':'Nevada', 'f':'Nevada'},
'year':{'a': 2000, 'b':2001,'c': 2002, 'd':2001, 'e':2002, 'f':2003},
'pop':{'a': 1.5, 'b':1.7,'c': 3.6, 'd':2.4, 'e':2.9, 'f':3.2}
}
frame2 = pd.DataFrame(data)
默认索引也可以更改索引,达到同样的效果
frame1.index = ['a', 'b', 'c', 'd', 'e', 'f']
1.1 给DataFrame添加数据
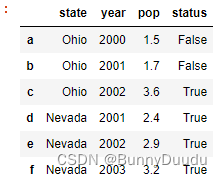
如下添加一个’status’列索引,并往索引里赋值;数据需要时一个与原DataFrame行索引长度相同的[list]
举例:
frame['status'] = frame['pop']>2
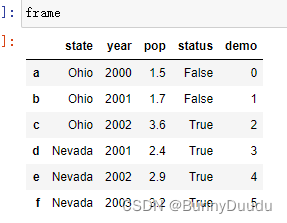
再用列表添加一个行索引:
frame['demo'] = [0, 1, 2, 3, 4, 5]
所需要删除列索引,则使用语句:del frame['列索引名字']
1.3 给行索引和列索引起名
行索引起名:DataFrame.index.name = 'index_name'
列索引起名:DataFrame.columns.name = 'columns_name'
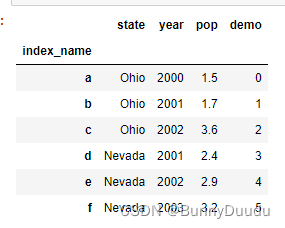
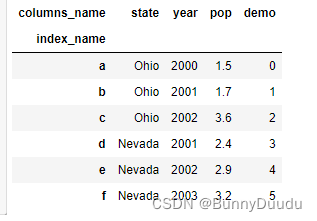
1.4 判断数据是否在DataFrame中
行索引判断:‘name’ in frame.index
列索引判断:‘name’ in frame.columns
数据值判断:‘name’ in frame.values
若在则返回True,不在返回False
2.DataFrame数据处理
- 删除数据但不改变原DataFrame,使用语句drop
举例:
-
删除列:
frame.drop('state', axis=1)
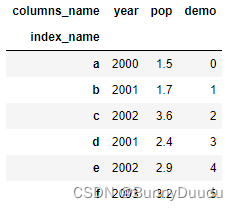
-
删除行:
frame.drop('a')
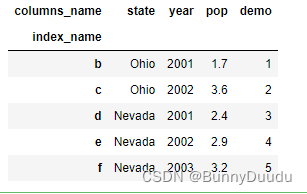
2.1 DataFrame数据切片
有两种取数据的方法:loc[]和iloc[]
frame:
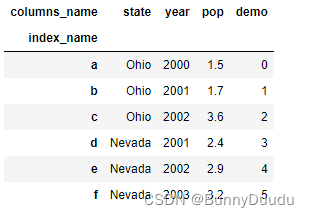
loc[]的取值方法是按DataFrame中行索引和列索引的名来进行取值,在数据量小时很好用
frame.loc['e':'f', 'state':'year']
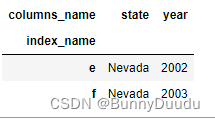
iloc[]的取值方法是按DataFrame中数据的具体位置进行索引;
frame.iloc[4:, :2]

2.2 DataFrame数据运算
DataFrame与DataFrame之间的运算:
df1 = pd.DataFrame(np.arange(12.).reshape((3, 4)),columns=list('abcd'))
df2 = pd.DataFrame(np.arange(20.).reshape((4, 5)),columns=list('abcde'))
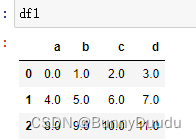
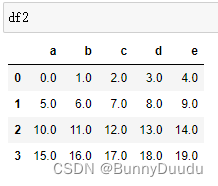
如果直接进行相加,会发现两个DataFrame所含有的行索引和列索引不一致,这会导致所相加后得到的DataFrame中会有NaN数据
df1.add(df2)
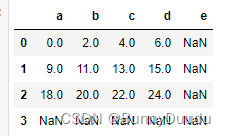
加入参数fill_value=0,0会代替df1中缺少的部分进行相加
df1.add(df2, fill_value=0)
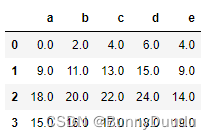
将DataFrame中的数据都+1
创建一个一维数据Series,Series里的索引要对应DataFrame中列索引
s = pd.Series([1, 1, 1, 1], index=['a', 'b', 'c', 'd'])
df1 + s















 16万+
16万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









