







#x.y 表示的是 第x个孩子中的第y列。
建议看完TASK1的第一个需求后就去看 ADDITIONAL INFORMATION部分。
一.Task 1
1.1. 上手的问题
(1)table 的 oid 是代表着什么?怎么使用?
注意到:Catalog中有GetTable方法可以获得TableInfo,而其中包含了std::unique_ptr<TableHeap> table_
// 基类AbstractExecutor中,可以得到上下文
auto GetExecutorContext() -> ExecutorContext * { return exec_ctx_; }
// 在ExecutorContext 中又包含下述方法
auto GetCatalog() -> Catalog * { return catalog_; }
Insert等操作还需要更新影响到的index
(2)如何改变索引?
注意到IndexInfo结构体中有std::unique_ptr<Index> index_;
而在Index类中有插入InsertEntry、删除、扫描等方法;这些方法都是虚函数实现,最终应该会调用B+树的相关方法。
(3)模式
模式其实就是,tuple中各列对应的名称和类型。
需要注意的是GetOutputSchema()表达的是其操作输出的模式。
child_executor_->GetOutputSchema()表达的才是其输入的模式。
以Update操作为例,
schema = (__bustub_internal.update_rows:INTEGER)
child_schema = (test_1.colA:INTEGER, test_1.colB:INTEGER, test_1.colC:INTEGER, test_1.colD:INTEGER)
(4)AbstractExpression
代表的是表达式,很多情况下表示的为是Tuple中的哪一列,例如
aggregates=[#0.0, #0.1]
(5)Null值
Value的空值,是指len_为一特定值BUSTUB_VALUE_NULL
1.2. 测试中遇到的问题
(1)注意Insert等操作即使插入数量为0,也要强制输出一次。即确保第一次调用Next时返回True。
(2)测试index-scan时出现了*** buffer overflow detected ***: terminated
这个问题是,在表上创建一系列索引后,再插入新的tuple引发的。
注意到:Index中的InsertEntry第一个参数也为Tuple类型,但并非原始的包含完整信息的tuple,而是索引用到的新的tuple。
virtual auto InsertEntry(const Tuple &key, RID rid, Transaction *transaction) -> bool = 0;
// 需要结合Index类的下述方法生成新的Tuple
/** @return The index key schema */
auto GetKeySchema() const -> Schema * { return metadata_->GetKeySchema(); }
/** @return The index key attributes */
auto GetKeyAttrs() const -> const std::vector<uint32_t> & { return metadata_->GetKeyAttrs(); }
// 再调用Tuple类提供的下述方法即可
// Generates a key tuple given schemas and attributes
auto KeyFromTuple(const Schema &schema, const Schema &key_schema, const std::vector<uint32_t> &key_attrs) -> Tuple;
(3)IndexScan处理索引为空的情况
发现其陷入了死循环
这是因为,此时B+树也为空,但之前代码在获取Begin()和End()时, 未考虑root_page_id_为空的情况,仍然去获取INVALID_PAGE_ID页面,从而造成错误。还是之前的代码不够鲁棒。
ReadPageGuard header_page = bpm_->FetchPageRead(header_page_id_);
auto head_page = header_page.As<BPlusTreeHeaderPage>();
page_id_t cur_pid = head_page->root_page_id_;
if( cur_pid == INVALID_PAGE_ID) { // 需要加上此句,之前代码未考虑root_page_id_为空的情况
return INDEXITERATOR_TYPE(bpm_, INVALID_PAGE_ID, 0);
}
ReadPageGuard guard_parent = bpm_->FetchPageRead(cur_pid);
header_page.Drop();
二.Task 2
2.1 Aggregation
(1)Agg中的Count的实现问题
Agg在Init函数中建立好哈希表,上层调用Next时,根据迭代器不断向上返回信息即可。
类似Sum,Max,Min等操作,正常情况下其操作的都是同一类型的数据,因此为支持各种类型的比较或者相加等操作,使用下述第一种方式。
但对于Count操作,统计时,count的初值或者相加值也使用第一种方式的话,但实际上我们可能对各种类型进行计数,例如字符串类型。最好直接写为INT类型,防止出现错误。
// Sum、Min、Max方式
Value(input.aggregates_[i].GetTypeId(), 1);
// Count方式
Value(INTEGER, 1)
2.2 Join
2.3 优化
(1)BusTub优化器是基于规则的,自下向上方式
原理:实际上是采用递归的方式,自下向上进行匹配,如果当前plan满足一定条件,则用期望的结点对原结点进行替代。
(2)在Join操作中,如果右孩子节点为Sort、HashJoin、Aggregation等pipeline breaker操作。以Sort为例,那么因为Sort可能作为Join操作的inner部分,需要调用多次的Init,这样就需要多次执行相同的Sort排序。其实最好只有第一次执行排序,后续的Init操作都只是把offset重新设置为0。
(3)TopN实现中,若使用优先队列,那么首先无法节省内存,因为C++中不支持设置其大小,若想节省则需自己写,而且每次调用Init都需要重新构建优先队列。
(4) Join操作条件下移,即只有设计到两个孩子的表达式才保留,只涉及一方的表达式下移到其孩子节点作为Filter。假设所有的比较表达式都是通过And连接的,具体实现方式为,首先对Join条件进行提取,划分为三部分:涉及两个孩子的,只需左孩子的,只需右孩子的。然后重新创建左右孩子节点和Join节点即可。如果左右孩子节点也为Join操作的话,则递归调用这个过程。
这里主要想提一下对表达式的操作,最好也采用递归的方式实现想要的功能。
(5) 对多个Project的优化。多个Project连接,那么以最后一个为准。凭借次即可进行优化。(正常情况下,父投影操作应该是子投影的子集)。这里需要注意的是,并非直接把子投影删掉就行,因为子投影中可能有一些相加等操作,需要对父投影的expressions更改为相应子投影的表达式。
为简单起见,这里做了一个限制,就是假设父投影操作中的表达式都为ColumnValueExpression类型,否则不进行优化。
(6) 对Projection和Aggregation串联的优化。对这部分的局限性比较大,基本上是针对q3对应优化的。
这部分的优化分为两步:
- 首先是对Aggregation中重复计算的去除。这部分需要建立一个映射关系,将其位于
std::vector<AbstractExpressionRef>中的实际索引映射为之前重复的表达式的索引。 - 对Projection中未用到的相应项的去除。为简单起见,这里假设的是group by后面的表达式均为
ColumnValueExpression类型,不参与聚合操作,并且必须位于最前面。此部分的具体做法为:建立一个bitmap,依次解析Projection中的表达式,如果用到了某个聚合操作,bitmap中的相应位置1(经过上述映射的索引位置设为1,这样找到的才是实际使用的且不重复的Agg操作,并且注意要更改Projection操作中的col_idx)。最终根据bitmap来建立新的Aggregation和Projection。
最终成绩如下图所示:

(7)B+树索引对部分Key的支持。索引由两个整数组成,Q1中是要求的是第二个整数等于某一值。
而B+树比较函数是先比较第一个,再比较第二个,如果想限定第二个等于某一个值,如何查找在B+树中进行查找。
- 一个简单的方法是枚举满足要求的第一个值,再结合给定的第二个值,开始进行查找。
如果找到的第一个Tuple不满足要求,则结束;若满足要求,则返回,接着枚举第一个值,直到找到第一个不满足该值的地方。即不断的调用Begin(const KeyType &key)
采用这种方法后,出现了一个奇怪的Bug,提示出现了负数。本地测试都没有问题,又感觉不太可能在Q1中出现负数。也不太可能出现空集合的情况。
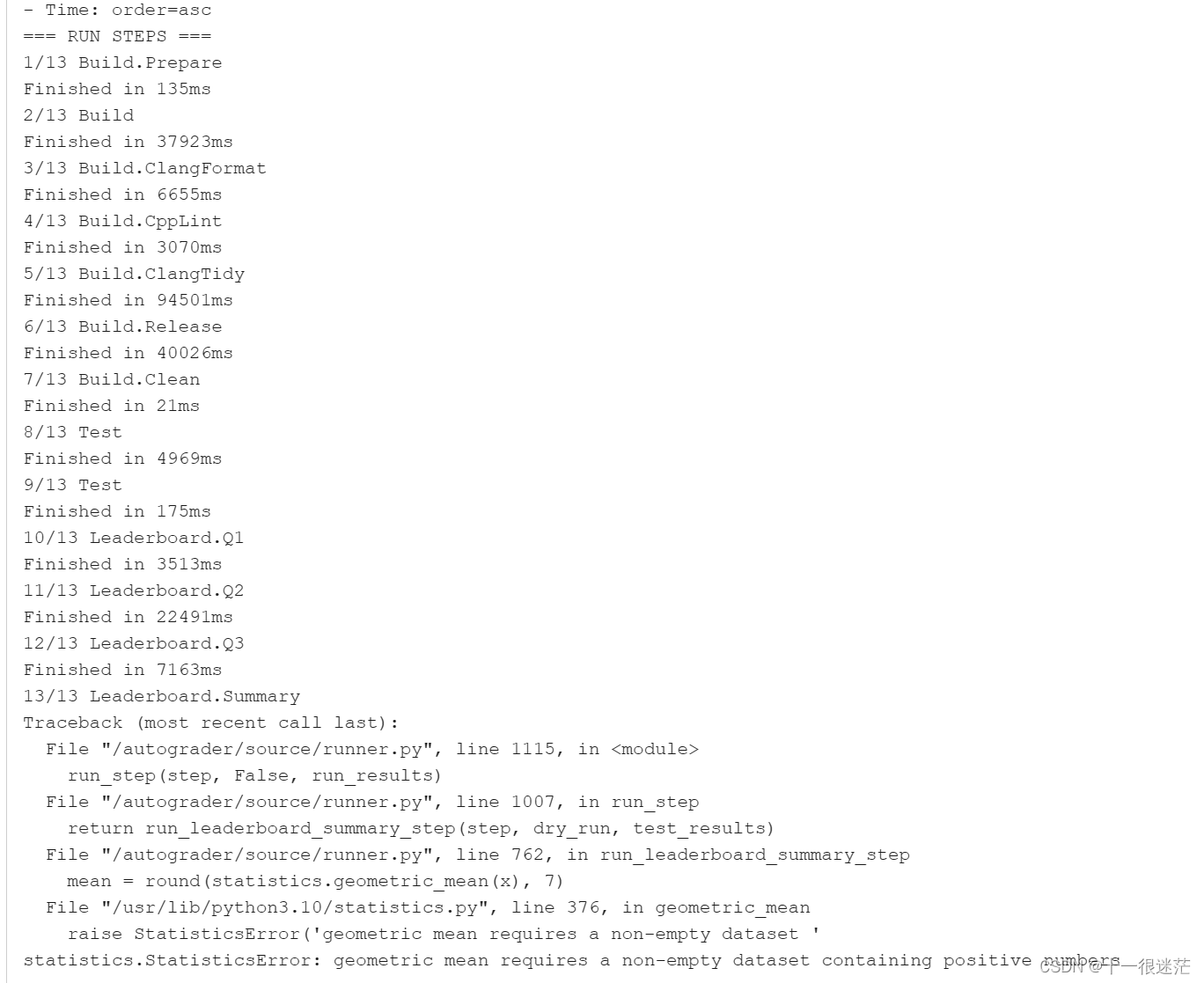
- 感觉若要实现部分关键字查询的话,需要支持从第二个值开始比较的比较函数。可以在本地完成,但无法上传进行验证。
- 第三种想法是,由于有
Begin(const KeyType &key)的接口,可以凭借此接口找到第一个满足值的地方。而且叶子节点中的值是升序排列的,我们可以只比较第一个和最后一个元素即可,这里可以加自定义的比较函数(只比较第二个值),如果两个值都大于或都小于,则说明本页没有,跳到下一页,只有第一个小于等于,第二个大于等于才会有需要的值。
(8)本地测试结果
本地测试结果Q1平均为5左右(可能是太针对了?)
本地测试结果Q2为4万左右,评分系统上为2千,相差20倍。
Q3为2万8左右,系统为650左右
2.4 移动语义总结
当一个函数返回一个对象的拷贝时,如果使用移动语义进行复制,会阻碍编译器的copy elision优化。
(1)强制情况,一定会触发copy elision的两种情况:(此时如果使用移动语义就会造成不必要的麻烦)
当return语句返回的对象是一个纯右值,且该对象类型与函数返回值类型相同时
初始化对象时,使用相同类型的纯右值初始化表达式
A f() {
return A();
}
B = std::move(f()); // prevents copy elision














 1236
1236











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









