








前言
此刻正阅读推文的你,是不是经常网络沟通词不达意?
是不是经常因为不小心说错话懊悔不已?
而且,经常在想要对朋友表达关心之时,只会说:早上好,吃了吗,今天怎么样?语气生硬的像个机器人。
没关系,没什么问题是一个表情包搞不定的!

但擅长网络冲浪的你可能在运用过程中会发现:
我的表情包太多了,有时想找到想要的那张表情包要扒拉好半天才可以,严重影响我秒回!
虽然微信/QQ有表情包联想功能,但里面的图怎比得过自己精心搜集的富含个人风格的表情包呢?

因此,本文将手把手教你从0到1实现表情包的检索功能,只需要有基础的编程知识就可以学会,从此再也不用担心想要的表情包找不到了!

注:本文实现代码已开源,开源地址:https://github.com/you8023/milvus_meme_search,如果觉得还不错,希望能够点亮一颗star ☆
本文需要的环境依赖如下:
Docker
Python 3:文中使用python 3.8
Linux
科学上网
准备好以上内容,我们就可以开始我们的表情包检索之旅。
01
需求分析
(1)需求拆解
首先确定核心需求:想要从自己的表情包库中快速找到合适的表情包
如何针对需求进行分析并拆解呢?想象自己是个杠精,面对上述在你看来天方夜谭的简短的需求描述,那么,我们开启质疑模式,提出以下几个问题:
问题一:表情包库从何而来?
问题二:怎么去找特定的表情包?
-
拿什么去找?
用什么工具?
用什么方法?
问题三:怎么保证”快速“呢?
然后,转换视角,我们一一去回答上述问题:
针对问题一表情包从何而来,表情包库我们直接拿自己日常从各大平台搜集的表情包放在一起即可
针对问题二怎么找,这个问题比较大,可以从ITTO(输入、工具与技术、输出,Inputs, Tools & Techniques, and Outputs)的角度先回答小问题,然后再做归纳。这里的输出其实很明确,就是表情包图片。
-
对于上述问题a,这里即输入是什么,根据日常使用场景,这里我们可以采用文本作为表情包检索的输入
对于上述问题b,我们需要一种能够将输入的文本映射到输出的图片的工具。
对于上述问题c,我们需要一种可以实现文本语义分析,并匹配对应语义图片的检索方法。
针对问题三,如何保证快速,这就涉及到上一步的工具与技术的效率和性能了,可以对能够满足要求的工具和技术进行对比分析,挑一个又快又好的!
经过上述分析,不难发现,简短的需求描述经过扩充后,目标看起来也不是那么遥不可及。
(2)技术选型
上述分析中,我们目前的难点和关键问题在于如何确定问题2中的工具和技术。这里看起来很像魔法,而AI恰好就是一个类似魔法的工具,但AI底层是如何实现的呢?
这里针对该点进行学习和调研,发现可以通过以下路径达成我们的目标:
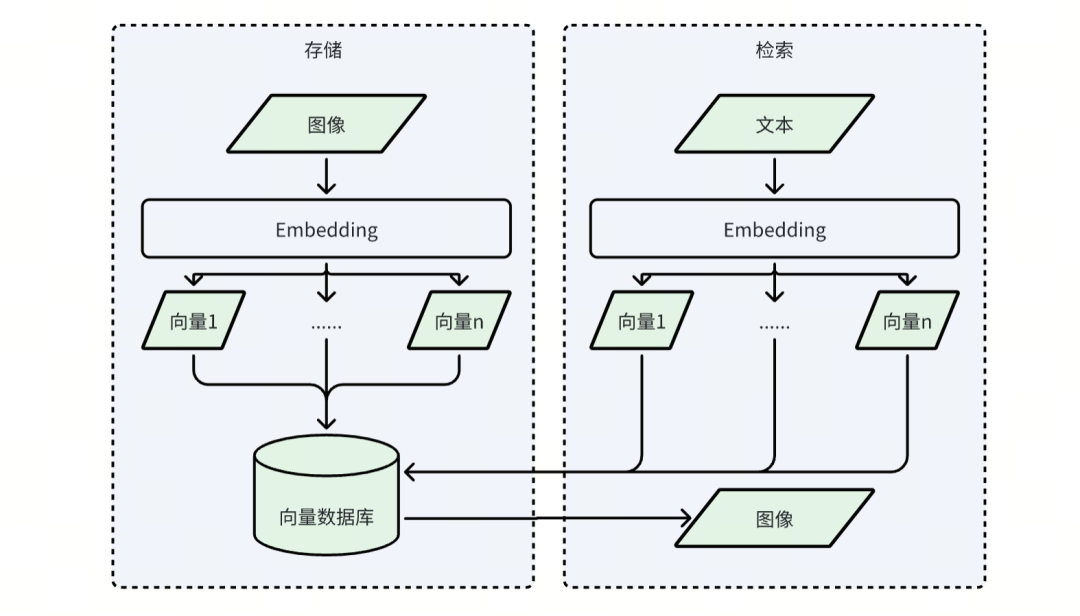
如图所示,该流程可以拆分为两个模块,分别是存储和检索。
对于存储模块来说,我们需要将图像作为输入,而在检索模块则是将文本作为输入,通过统一的Embedding程序,将其转换为抽象的向量数据,存储至向量数据库中,这样就实现了多模态数据的统一。只需要通过对文本向量数据进行相似性检索即可得到图像。
不难看出,其中的Embedding和向量数据库是关键,我们分别用一句话对其做出解释:
Embedding是一种将高维、离散数据(如词、ID等)映射到低维、连续向量空间的技术,以便计算机更好地理解和处理这些数据。
向量数据库是一种专门存储和查询高维向量数据的数据库,常用于处理图像、文本和其他复杂数据结构。
而能够满足我们需求的工具中,可以选择使用Milvus作为我们的技术方案。
先看看Milvus是什么:全球第一个向量数据库产品,也是GitHub上近3.3万 star的全球最大开源向量数据库产品,在大部分开发者心中,Milvus约等于向量数据库的代名词。
那么,为什么选择Milvus呢?
开源:Milvus是一款开源产品,可以满足定制化需求,且可以用于商业目的
社区生态良好:Milvus作为一款开源产品,拥有良好的社区生态,文档详尽,支持多种语言,且提供多种实例demo,易于上手
海量数据任意存:Milvus作为向量数据库,适用于大规模向量化后的AI数据存储,可以作为我们表情包图库的数据库
性能出色:Milvus作为一款多模态向量检索引擎,专注于实时检索和分析,在向量检索上表现出色。
部署简单:Milvus提供了多种部署方式,且提供了自动化脚本一键部署
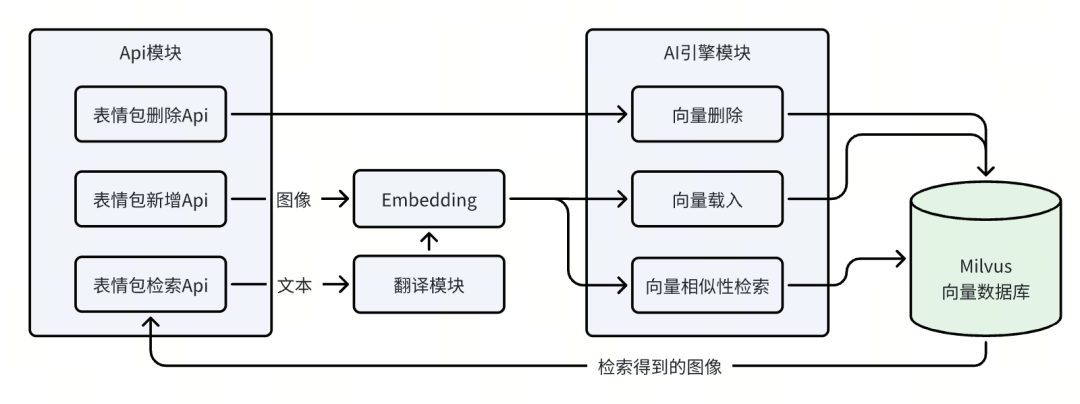
(3)架构设计
选定milvus作为技术方案后,从工程化的角度思考,考虑到各项功能的实现和组合,设计整体架构如下:
02
项目实现
按照需求分析中得到的项目架构图,分模块实现。
(1)安装依赖
首先安装项目基础依赖,执行以下命令:
pip install towhee gradio opencv-python
pip install pymilvus==2.2.11(2)AI引擎模块
AI引擎模块分为milvus服务搭建、milvus数据库初始化、表情包导入和表情包检索等步骤,后文依次讲解。
milvus服务搭建
首先,需要搭建milvus向量数据库服务,该步骤可以类比为在机器上安装一个mysql数据库服务。有了数据库,才能开展后续操作,这里使用docker进行搭建。
milvus官网提供了便捷的脚本一键启动服务,只需要执行以下命令即可:
curl -sfL https://raw.githubusercontent.com/milvus-io/milvus/master/scripts/standalone_embed.sh -o standalone_embed.sh
bash standalone_embed.sh start出现以下信息即表示启动成功:

milvus数据库初始化
编写脚本,通过以下代码初始化milvus数据库:
from pymilvus import connections, FieldSchema, CollectionSchema, DataType, Collection, utility
def create_milvus_collection(collection_name, dim):
# 连接milvus服务,其中的ip地址为milvus服务所在地址
connections.connect(host='192.168.2.134', port='19530')
# 如果collection存在就销毁,类似mysql中的if table exists,drop xxx
if utility.has_collection(collection_name):
utility.drop_collection(collection_name)
# 设定字段/列
fields = [
FieldSchema(name='id', dtype=DataType.INT64, descrition='ids', is_primary=True, auto_id=False),
FieldSchema(name='embedding', dtype=DataType.FLOAT_VECTOR, descrition='embedding vectors', dim=dim)
]
schema = CollectionSchema(fields=fields, description='text image search')
collection = Collection(name=collection_name, schema=schema)
# 对embedding建立索引
# create IVF_FLAT index for collection.
index_params = {
'metric_type':'L2',
'index_type':"IVF_FLAT",
'params':{"nlist":512}
}
collection.create_index(field_name="embedding", index_params=index_params)
return collection
collection = create_milvus_collection('meme_search', 512)其中的ip地址为刚刚搭建的milvus服务所在地址,这里使用本地linux虚拟机搭建,在虚拟机中输入ifconfig即可查看虚拟机ip
表情包导入
将搜集到的表情包放到目录meme中,使用以下代码生成id和图像路径的映射文件
meme_images.csv:
import csv
import os
def generate_csv(folder_path, save_path):
index = 0
with open(save_path, 'w', encoding='utf-8', newline='') as f:
csv_writer = csv.writer(f)
# 写入csv标题
csv_writer.writerow(['id', 'path', 'label'])
# 遍历目录,将id和图片路径添加到csv文件中
for filepath, _, files in os.walk(folder_path):
for file_name in files:
file_all_path = os.path.join(filepath, file_name)
csv_writer.writerow([index, file_all_path,''])
index += 1
if __name__ == '__main__':
# 表情包存放路径
img_folder = './meme'
# csv文件生成路径
save_csv = './meme_images.csv'
generate_csv(img_folder, save_csv)添加以下函数代码,批量导入表情包:
# 定义csv文件的数据处理方式
def read_csv(csv_path, encoding='utf-8-sig'):
import csv
with open(csv_path, 'r', encoding=encoding) as f:
data = csv.DictReader(f)
for line in data:
yield int(line['id']), line['path']
# 定义数据处理流水线:
# 1. 输入csv文件
# 2. 通过上述定义的read_csv函数处理csv数据,拿到其中的id和path
# 3. 通过ops.image_decode.cv2读取路径中的image图像
# 4. 通过ops.image_text_embedding.clip指定clip_vit_base_patch16作为处理模型,将图像转换为向量数据
# 5. 通过lambda x: x / np.linalg.norm(x)对向量数据进行线性处理
# 6. 通过ops.ann_insert.milvus_client将处理后的向量数据及id存储到milvus数据库中,其中的collection_name参数需和上述建立的collection名称一致
p_csv_load = (
pipe.input('csv_file')
.flat_map('csv_file', ('id', 'path'), read_csv)
.map('path', 'img', ops.image_decode.cv2('rgb'))
.map('img', 'vec', ops.image_text_embedding.clip(model_name='clip_vit_base_patch16', modality='image', device=0))
.map('vec', 'vec', lambda x: x / np.linalg.norm(x))
.map(('id', 'vec'), (), ops.ann_insert.milvus_client(host='192.168.2.134', port='19530', collection_name='meme_search'))
.output()
)
ret = p_csv_load('meme_images.csv')
# 载入数据
collection.load()在导入图像时,部分图像会报错:
RuntimeError: Node-image-decode/cv2-1 runs failed, error msg: Read image ./meme\img-1721552589754b27f5c97bcec58d8e51c7652f5bfd006.jpg failed, Traceback (most recent call last):
File "C:\Users\Dubito\AppData\Local\Programs\Python\Python310\lib\site-packages\towhee\runtime\nodes\node.py", line 158, in _call
return True, self._op(*inputs), None
File "C:\Users\Dubito\.towhee\operators\image-decode\cv2\versions\main\image_decode_cv2.py", line 69, in __call__
raise RuntimeError(err)
RuntimeError: Read image ./meme\img-1721552589754b27f5c97bcec58d8e51c7652f5bfd006.jpg failed
, Traceback (most recent call last):
File "C:\Users\Dubito\AppData\Local\Programs\Python\Python310\lib\site-packages\towhee\runtime\nodes\node.py", line 171, in process
self.process_step()
File "C:\Users\Dubito\AppData\Local\Programs\Python\Python310\lib\site-packages\towhee\runtime\nodes\_map.py", line 63, in process_step
assert succ, msg
AssertionError: Read image ./meme\img-1721552589754b27f5c97bcec58d8e51c7652f5bfd006.jpg failed, Traceback (most recent call last):
File "C:\Users\Dubito\AppData\Local\Programs\Python\Python310\lib\site-packages\towhee\runtime\nodes\node.py", line 158, in _call
return True, self._op(*inputs), None
File "C:\Users\Dubito\.towhee\operators\image-decode\cv2\versions\main\image_decode_cv2.py", line 69, in __call__
raise RuntimeError(err)
RuntimeError: Read image ./meme\img-1721552589754b27f5c97bcec58d8e51c7652f5bfd006.jpg failed这里经过排查发现,以下图片会导入失败,去掉即可:Gif图片
水平分辨率、垂直分辨率均为72dpi,位深度为32的图片(点开图片属性中的详细信息即可查看)
为了便于后续api上传,因此参考上述代码,增设单个表情包导入流水线p_image_insert:
p_image_insert = (
pipe.input("id", "path")
.map("path", "img", ops.image_decode.cv2("rgb"))
.map("img", "vec", ops.image_text_embedding.clip(model_name='clip_vit_base_patch16', modality="image"))
.map("vec", "vec", lambda x: x / np.linalg.norm(x))
.map(("id", "vec"), "result", ops.ann_insert.milvus_client(host='192.168.2.134', port='19530', collection_name='meme_search'))
.output("result")
)表情包检索
使用以下代码实现表情包检索:
import pandas as pd
import cv2
# 定义读取图像的函数,根据图像id从csv文件中获取其对应路径再读取
def read_image(image_ids):
df = pd.read_csv('meme_images.csv')
id_img = df.set_index('id')['path'].to_dict()
imgs = []
decode = ops.image_decode.cv2('rgb')
for image_id in image_ids:
path = id_img[image_id]
imgs.append(decode(path))
return imgs
# 定义数据处理流水线:
# 1. 输入text文本
# 2. 通过ops.image_text_embedding.clip指定clip_vit_base_patch16作为模型处理文本,得到向量数据
# 3. 通过lambda x: x / np.linalg.norm(x)将向量数据进行线性转换
# 4. 通过ops.ann_search.milvus_client检索数据库中的相似向量,其中的collection_name参数需和上述建立的collection名称一致
# 5. 对检索结果进行处理,获取图像id
# 6. 通过上述定义的read_image函数,读取图像内容
p_search = (
pipe.input('text')
.map('text', 'vec', ops.image_text_embedding.clip(model_name='clip_vit_base_patch16', modality='text'))
.map('vec', 'vec', lambda x: x / np.linalg.norm(x))
.map('vec', 'result', ops.ann_search.milvus_client(host='192.168.2.134', port='19530', collection_name='meme_search', limit=5))
.map('result', 'image_ids', lambda x: [item[0] for item in x])
.map('image_ids', 'images', read_image)
.output('text', 'images')
)
# 针对文本,执行流水线检索图像
DataCollection(p_search("white cat")).show()
DataCollection(p_search("black dog")).show()
DataCollection(p_search("smile")).show()
DataCollection(p_search("angry")).show()运行代码,结果如下:

(3)翻译模块
由于模型对于中文的支持效果不佳,因此,这里需要增设一个翻译模块,以便模型更好地理解。
这里使用的是腾讯翻译api,每个月有500w免费翻译额度,一般情况下够用了。
第一步,进入控制台,开通翻译服务
第二步,进入密钥管理页面,点击新建密钥按钮生成密钥:
第三步,编写脚本,封装翻译接口(参考官方文档):# -*- coding: utf-8 -*-import hashlib
import hmac
import json
import sys
import time
from datetime import datetime
from http.client import HTTPSConnection
def sign(key, msg):
return hmac.new(key, msg.encode("utf-8"), hashlib.sha256).digest()
global_config = {
"tx_sid": "xxx",
"tx_skey": "xxx"
}
def tx_translate(msg, s="zh", t="en"):
secret_id = global_config["tx_sid"]
secret_key = global_config["tx_skey"]
token = ""
service = "tmt"
host = "tmt.tencentcloudapi.com"
region = "ap-beijing"
version = "2018-03-21"
action = "TextTranslate"
params = {
"SourceText": msg,
"Source": s,
"Target": t,
"ProjectId": 0
}
payload = json.dumps(params)
endpoint = "https://tmt.tencentcloudapi.com"
algorithm = "TC3-HMAC-SHA256"
timestamp = int(time.time())
date = datetime.utcfromtimestamp(timestamp).strftime("%Y-%m-%d")
# ************* 步骤 1:拼接规范请求串 *************
http_request_method = "POST"
canonical_uri = "/"
canonical_querystring = ""
ct = "application/json; charset=utf-8"
canonical_headers = "content-type:%s\nhost:%s\nx-tc-action:%s\n" % (ct, host, action.lower())
signed_headers = "content-type;host;x-tc-action"
hashed_request_payload = hashlib.sha256(payload.encode("utf-8")).hexdigest()
canonical_request = (http_request_method + "\n" +
canonical_uri + "\n" +
canonical_querystring + "\n" +
canonical_headers + "\n" +
signed_headers + "\n" +
hashed_request_payload)
# ************* 步骤 2:拼接待签名字符串 *************
credential_scope = date + "/" + service + "/" + "tc3_request"
hashed_canonical_request = hashlib.sha256(canonical_request.encode("utf-8")).hexdigest()
string_to_sign = (algorithm + "\n" +
str(timestamp) + "\n" +
credential_scope + "\n" +
hashed_canonical_request)
# ************* 步骤 3:计算签名 *************
secret_date = sign(("TC3" + secret_key).encode("utf-8"), date)
secret_service = sign(secret_date, service)
secret_signing = sign(secret_service, "tc3_request")
signature = hmac.new(secret_signing, string_to_sign.encode("utf-8"), hashlib.sha256).hexdigest()
# ************* 步骤 4:拼接 Authorization *************
authorization = (algorithm + " " +
"Credential=" + secret_id + "/" + credential_scope + ", " +
"SignedHeaders=" + signed_headers + ", " +
"Signature=" + signature)
# ************* 步骤 5:构造并发起请求 *************
headers = {
"Authorization": authorization,
"Content-Type": "application/json; charset=utf-8",
"Host": host,
"X-TC-Action": action,
"X-TC-Timestamp": timestamp,
"X-TC-Version": version
}
if region:
headers["X-TC-Region"] = region
if token:
headers["X-TC-Token"] = token
try:
req = HTTPSConnection(host)
req.request("POST", "/", headers=headers, body=payload.encode("utf-8"))
resp = req.getresponse()
return json.loads(resp.read())['Response']['TargetText']
except Exception as err:
print(f"[tx_translate] translate [{msg}] from {s} to {t} failed: {err}")
return msg(4)Api模块
为了便于将该程序集成到其他平台中,需要对上述demo进行api封装。
第一步,表情包新增
这里基于上述表情包导入的流水线,添加接口函数:
def insert_image(image_id, image_path):
p_image_insert(image_id, image_path)
collection.load()
# 检查图片后缀是否合法
def check_image_suffix(filename):
valid_suffixes = {"png", "jpg", "jpeg"}
return "." in filename and filename.rsplit(".", 1)[1].lower() in valid_suffixes
# 检查图片位深度是否为32
def check_bit_depth(image):
return image.mode == "RGBA" and image.info.get("bitdepth") == 32
# 检查图片分辨率是否为72dpi
def check_resolution(image):
return image.info.get("dpi") == (72, 72)
@bp.route("/image_upload", methods=["POST"])
def image_upload():
if "image" not in request.files:
return jsonify({"error": "No image part"}), 400
file = request.files["image"]
logger.debug("start upload image <{}>".format(file.filename))
if file.filename == "":
return jsonify({"error": "No selected image"}), 400
if not check_image_suffix(file.filename):
return jsonify({"error": "Invalid image suffix"}), 400
try:
file_data = file.read()
file_io_data = io.BytesIO(file_data)
image = Image.open(file_io_data)
except IOError:
return jsonify({"error": "Invalid image file"}), 400
if check_bit_depth(image):
return jsonify({"error": "32-bit images are not supported"}), 400
if check_resolution(image):
return jsonify({"error": "72dpi resolution is not supported"}), 400
file_path = os.path.join("meme", file.filename)
image_id = get_imgs_id_max() + 1
set_imgs_id_max(image_id)
save_image(image, file_path)
insert_image(image_id, file_path)
return jsonify({"message": "Image uploaded successfully"})第二步,表情包删除由于towhee库没有提供删除的方法,因此这里采用MilvusClient添加函数定义表情包删除接口:
from pymilvus import MilvusClient
client = MilvusClient(
uri=f"http://192.168.2.134:19530",
)
def delete_image(image_ids):
res = client.delete(collection_name='meme_search', ids=image_ids)
collection.load()
return res
@bp.route("/image_delete", methods=["POST"])
def image_delete():
image_ids = request.get_json().get("image_id")
if not image_ids:
return jsonify({"error": "Image ID is required"}), 400
# 调用函数删除图片
res = delete_image(image_ids)
return jsonify({"message": "Image deleted successfully: {}".format(res)})第三步,表情包检索
这里基于上述表情包检索的流水线p_search,添加接口函数:
p_search = (
pipe.input('text')
.map('text', 'vec', ops.image_text_embedding.clip(model_name='clip_vit_base_patch16', modality='text'))
.map('vec', 'vec', lambda x: x / np.linalg.norm(x))
.map('vec', 'result', ops.ann_search.milvus_client(host='192.168.2.134', port='19530', collection_name='meme_search', limit=5))
.map("result", "image_ids", lambda x: [item[0] for item in x])
.output("image_ids")
)
def search_image(text):
return p_search(text).get()
@bp.route("/image_search", methods=["POST"])
def image_search():
text = request.get_json().get("text")
if not text:
return jsonify({"error": "text is required"}), 400
# 判断是否含有中文字符,是的话调用翻译接口
if any('\u4e00' <= char <= '\u9fff' for char in text):
text = tx_translate(text)
# 调用函数进行搜索
img_ids = search_image(text)
img_paths = get_image_paths(img_ids)
return jsonify({"results": img_paths})最后一步,项目打包
将以上模块都实现之后,就可以将各模块封装,按照设计的架构打包为项目。这里项目化的代码已开源,可供参考。

03
参考链接
milvus docker安装:https://milvus.io/docs/zh/install_standalone-docker.md
Quickstart with Milvus Lite:https://milvus.io/docs/zh/quickstart.md#Quickstart-with-Milvus-Lite
文本到图像搜索引擎 | Milvus 文档:https://milvus.io/docs/zh/text_image_search.md#Text-to-Image-Search-Engine
Towhee Docs:https://docs.towhee.io/
Milvus 文档:https://milvus.io/docs/zh/delete-entities.md
作者介绍

Dubito
Zilliz黄金写手


















 568
568

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









