






召回率(Recall)和置信度(Confidence)是衡量分类和目标检测模型性能的两个重要指标,它们之间存在着密切的关系。在二分类任务中,召回率通常定义为真实为正类样本中,正确被模型预测为正类的比例。换句话说,召回率反映了模型在所有实际为正类的样本中,成功识别出来的比例。
召回率的计算公式为:
Recall=TP/(TP+FN)
其中,TP(True Positive)表示真正例数,FN(False Negative)表示假负例数。召回率的高低反映了模型的检测全面性,即能够识别出多少正样本。高召回率意味着较少的正样本被漏检,模型的“召回能力”较强。
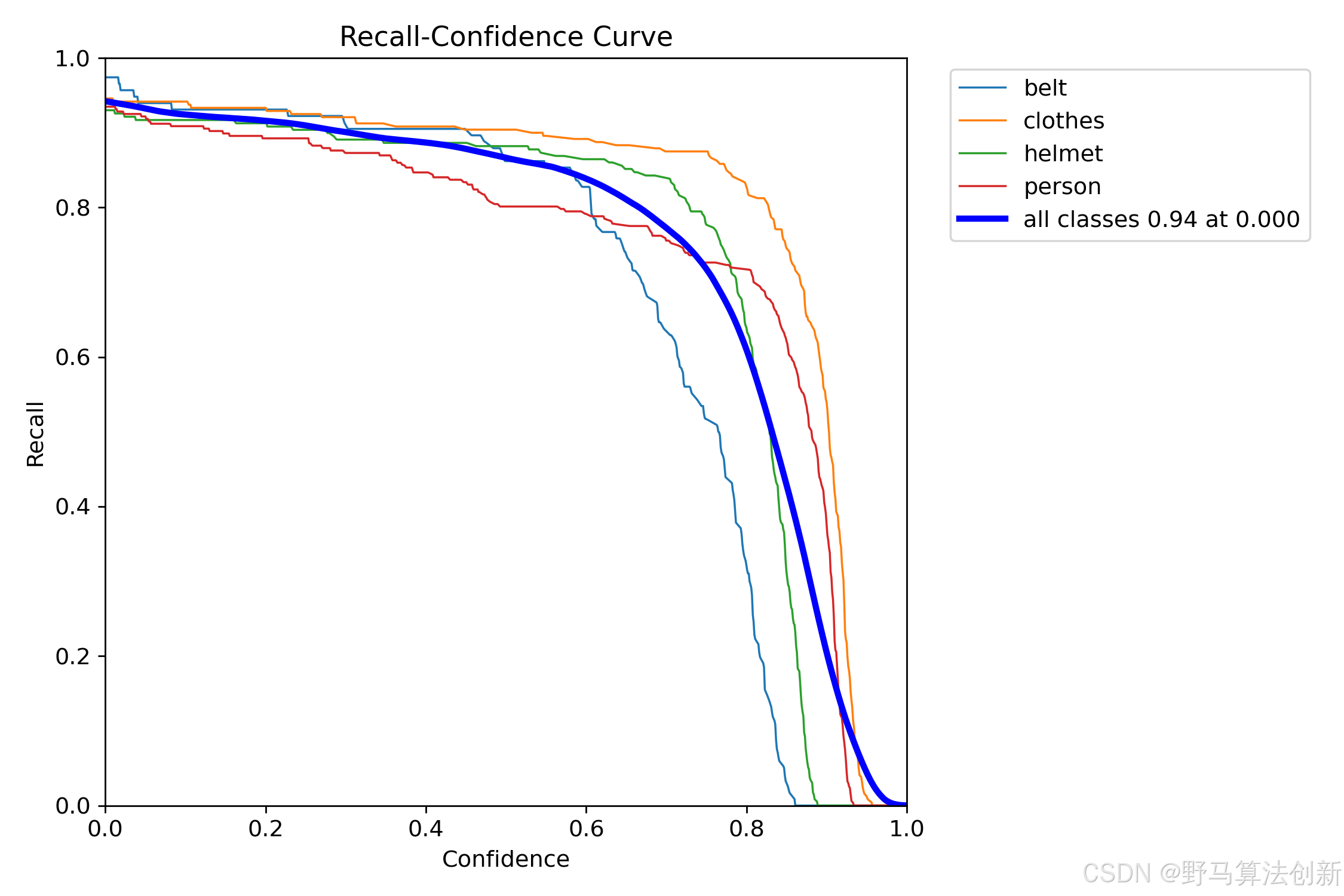
置信度则是模型对某个预测结果的信心程度,通常以概率值的形式输出。在目标检测中,模型会为每个预测结果赋予一个置信度值,表示该预测结果属于某一类别的可信度。当模型预测的置信度高于设定的阈值时,该预测结果被认为是有效的。然而,随着置信度阈值的调整,召回率和精确率之间的平衡会发生变化。
置信度阈值-召回率曲线展示了在不同置信度阈值下,召回率的变化情况。当置信度阈值较低时,模型会判断出更多的预测结果,尽管许多低置信度的预测结果可能是误判。此时,召回率较高,因为更多的正样本被检测出,但这也可能带来较多的假正例(False Positive)。随着置信度阈值的增大,模型只会保留那些置信度较高的预测,虽然召回率会有所下降,但模型的误判率(即假正例)也会减少。
因此,召回率和置信度之间呈现出反向关系。较低的置信度阈值有助于提高召回率,因为更多的正样本被检测出;然而,这也会导致更多的误判。相反,提高置信度阈值则会减少误判,但可能导致一些真实的正样本被漏检,从而降低召回率。
在实际应用中,选择合适的置信度阈值对于实现理想的召回率至关重要。根据不同的应用需求,可能需要在召回率和精确率之间进行权衡,以实现模型性能的最佳平衡。

















 1340
1340

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









