







参考视频:https://www.bilibili.com/video/BV1Vh411y7s7?p=8&spm_id_from=pageDriver
一,准备:导入数据,数据库中有test表,包含300万数据
1,300万数据,导入要249.3秒
2,正常查询:select * from test;需要7.32秒。select id from test; 需要2.5秒
3,修改存储引擎后,查询的时间发生了改变
二,数据库优化的方向:
- mysql优化的方向:硬件级别,数据库级别
- 数据库的本质是一组文件集数据存储在外存,而程序运行在内存中,但我们需要查询数据时,需要从外存中读出数据,所以需要进行IO操作,IO操作花费的时间比较大
硬件级别:
- 磁盘寻找:磁盘需要一段时间才 能找到一段数据。对于现代磁盘来说,这种平均时间通常低于10ms,因此理论每秒100次寻找。这一次用新的磁盘缓慢地改进,并且对于单个表是很难优化的。优化查找时间的方法是将数据分发到一个以上的磁盘上。
- 磁盘读写:当磁盘处于正确位置时,我们需要读取或写入数据。使用现代磁盘,一个磁盘可以提供至少10到20Mb/s的吞吐量。这比磁盘寻找更容易优化,因为为可以从多个磁盘并行读取。
- CPU :当数据在主存储器中时,我们必须处理它以得到结果。与内存量相比,具有大数据库量的表是最常见的限制因素。但是对于小表来说,速度通常不是问题。
- 存储带宽:当CPU需要比CPU缓存中更多的数据时,主存储器带宽成为瓶颈。对于大多数系统来说,.这是一个不常见的瓶颈,但也是一个需要注意的点
- 总结:寻址,磁盘读写,CPU,CPU缓存四个方面的瓶颈,可以优化。
数据库级别:
- 表结构设计:特别的是列是否具有正确的类型,和表中列的个数是否正确。例如:对于执行频繁更新的应用通常设计更多表,每个表的列并不多。而对于需要进行大量分析的应用通常设计更少的表,而每个表的列更多一些。
- 索引设置:需要考虑的是什么SQL会导致索引无效,什么情况会让查询效率更高。(是低成本,效率高的调优)
- 存储引擎:包括InnoDB和MyIsm存储引擎的选择
- 行格式:主要取决于适当的存储引擎。压缩表可以占用更低的磁盘空间和更少的/O操作。压缩表适用于InnoDB和MyISM存储引擎。
- 锁策略:在具有高并发、分布式应用程序中,选择适当的锁策略以保证数据的共享性和特定的情况下独占数据。InnoDB存储引擎在不需要我们参与下能处理大部分锁问题,允许数
据库实现更好的并发性,减少代码调优量。(补充:高并发情况下出现的问题:有脏读,不可重复读,幻读。脏读:事务A读取到了事务B未提交的数据.事务A读取到的数据叫做脏数据,读取数据的过程叫做脏读,在具备缓存的情况下可能出现脏读。不可重复读:针对于表中一行数据或一-行中某列数据当事务A在修改一行数据时,没有提交,事务B读取到这行数据,事务B读取的数据就是旧数据和以后的真实数据不一致.为了防止事务B读取到未操作完成的数据的过程叫做不可重复读。幻读:针事务A向表中新增-条数据,没有提交事务,事务B查询表中全部数据事务B读取到的数据和最终真实数据少一条,等读取结束发现读取到的数据和真实数据不一样,好像出现了幻觉一样,所以叫做幻读)
- 缓存区域使用的大小:配置的原则是缓存区域大到足以容纳所有频繁访问的数据,但又不能太大,否则导致过量占用物理内存而导致分页。一般情况下需要配置InnoDB的缓冲池、MyISAM 密钥缓存和MySQL的查询缓存。
三,MYsql数据库优化的原则:
1,优化可能带来的问题:
- 优化不总是针对一个单纯的环境进行,还很可能是一个复杂的已投产的系统。
- 优化手段本来就有很大的风险,只不过你没能力意识到和预见到!
- 任何的技术可以解决一个问题,但必然存在带来--个问题的风险!
- 对于优化来说解决问题而带来的问题,控制在可接受的范围内才是有成果。
- 结论:所以优化后保持现状或者出现效率更差,都是优化失败。
2,优化的需求:
- 稳定性和业务可持续性通常比性能更重要!
- 优化不可避免涉及到变更,变更就有风险!
- 优化使性能变好,维持和变差是等概率事件!
- 切记优化,应该是各部门协同,共同参与的工作,任何单一部门都不能对数据库进行优化!
- 结论:所以优化工作,是由业务需要驱使的! ! !
3,优化参与人员:
- 在进行数据库优化时,应由数据库管理员、业务部门代表、应用程序,架构师、应用程序设计人员、应用程序开发人员、硬件及系统管理员、存储管理员等,业务相关人员共同参与
4,优化选择:
- 优化成本:硬件>系统配置>数据库表结构>SQL及索引
- 优化效果:硬件<系统配置<数据库表结构<SQL及索引
5,优化的工具:explain和slow-log
四,MYsql数据库的架构
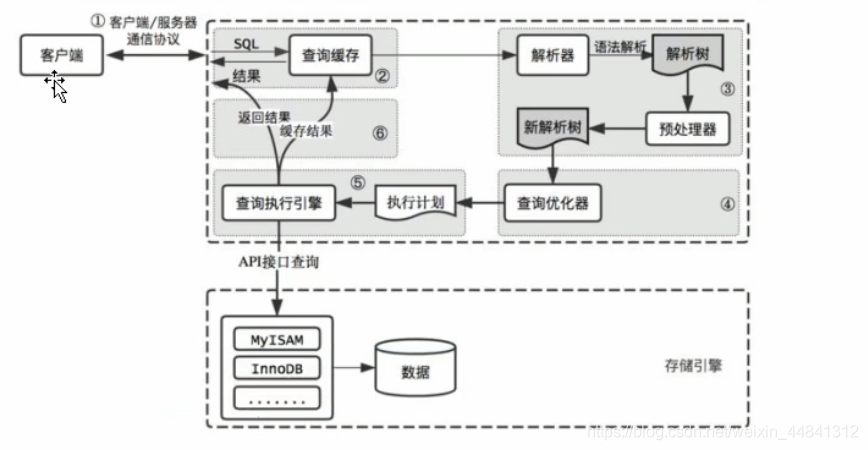
根据架构图来分析一条SQL语句的执行过程:
- 客户端上我们编写的SQL语句,在tcp协议的约束下传给数据库,mysql会计算这条SQL语句的hash值,查询缓存中,查看该hash值是否存在。
- 如果hash值存在说明这条SQL语句曾经有执行过,它的查询结果是存储在缓存中的,所以只需要更具hash值找到对应的value返回给客户端就可以了。
- 如果hash不存在于在缓存中,进入语法解析器,判断关键字地方拼写错误,如果错误直接返回错误信息,如果拼写正确就通过语法解析生成一个解析树进入预处理器,预处理器会查看该SQL语句的类名,表明等信息是否拼写正确,如果正确就生成新的解析树进入查询优化器,查询优化器会根据优化算法对SQL语句进行优化生成执行计划。
- 执行计划通过查询执行引擎的接口抵达对应的存储引擎,存储引擎执行该SQL的执行计划查询数据,把结果返回给客户端,同时查看查询缓存的存储情况,如果有空间就把查询结果和hash值存入查询缓存中,如果它的空间不够就按照一定的算法把里面的信息删除的一条,添加该SQL的hash值和查询到的值
五,查询缓存:
缓存中存储了SQL命令的HASH,直接比对SQL命令的HASH和缓存中key是否对应,如果对应,直接返回结果,不再执行其他操作。由于缓存的是SQL的HASH,所以根据Hash特性SQL中空格等内容必须完全一样。缓存里面包含婊缓存、记录缓存、权限缓存等。查询语句执行完成后会把查询结果缓存到缓存中。
- 适合大量的查询,增加删除修改数据的情况少的条件
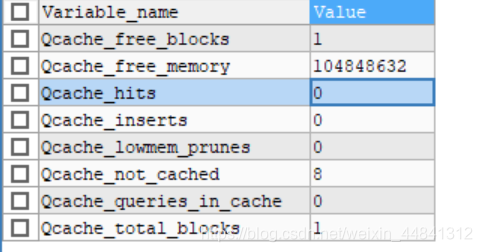
- 查询缓存开启的语句:SHOW VARIABLES LIKE '%query_cache%';
- query_cache_type的值为on时说明开启了查询缓存
- 如果想要开启它需要在mysql文件夹下的my.ini文件中修改query_cache_type的值为1或者2;
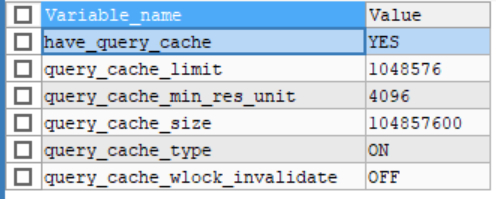
- 查看缓存的状态:SHOW STATUS LIKE '%qcache%';
六,存储引擎:
- 查看支持的存储引擎:SHOW ENGINES;

- ISAM:ISAM是-一个定义明确且历经时间考验的数据表格管理方法,它在设计之时就考虑到数据库被查询的次数要远大于更新的次数。因此,ISAM执行读取操作的速度很快,而且不占用大量的内存和存储资源。ISAM的两个主要不足之处在于,它不支持事务处理,也不能够容错。如果你的硬盘崩溃了,那么数据文件就无法恢复了。如果你正在把ISAM用在关键任务应用程序里,那就必须经常备份你所有的实时数据,通过其复制特性,MYSQL能够支持这样的备份应用程序。注意:使用ISAM注意点:必须经常备份所有实时数据。版本: MySQL 5.7不支持ISAM
- MyISAM:MyISAM是MySQL的ISAM扩展格式( MySQL5.5之前版本的缺省数据库引擎)数据库引擎。除了提供ISAM里所没有的索引和字段管理的大量功能,MyISAM 还使用一种表格锁定的机制,来优化多个并发的读写操作,其代价是你需要经常运行OPTIMIZE TABLE命令,来恢复被更新机制所浪费的空间。MyISAM还有一些有用的扩展,例如用来修复数据库文件的MyISAMCHK工具和用来恢复浪费空间的MyISAMPACK工具。MYISAM 强调了快速读取操作,这可能就是为什么MySQL受到了WEB开发如此青睐的主要原因:在WEB开发中你所进行的大量数据操作都是读取操作。所以,大多数虚拟主机提供商和INTERNET平台提供商只允许使用MYISAM格式。MyISAM格式的一个重要缺陷就是不能在表损坏后恢复数据。MyISAM引擎使用注意:必须经常使用OptimizeTable命令清理空间必须经常备份所有实时数据。工具有用来修复数据库文件的MyISAMCHK工具和用来恢复浪费空间的MyISAMPACK工具。不支持事务。数据越多,写操作效率越低。因为要维护数据和索引信息。(索引列越多,相对效率越低。)MyISM生成的三个文件:.frm:表结构信息 .MYD:数据文件 .MYI:表的索引信息
- MyISM和Innodb的区别:
1.InnoDB支持事务,MyISAM不支持,对于InnoDB每一条SQL语言都默认封装成事务,自动提交,这样会影响速度,所以最好把多条SQL语言放在biegin transaction和commit之间,组成一个事务;
2.InnoDB支持外键,而MyISAM不支持。对一个包含外键的InnoDB表转为MyISAM会失败;
3. InnoDB是聚集索引,数据文件是和索引绑在一起的,必须要有主键,通过主键索引效率很高。但是辅助索引需要两次查询,先查询到主键,然后再通过主键查询到数据。因此,主键不应该过大,因为主键太大,其他索引也都会很大。而MyISAM是非聚集索引,数据文件是分离的,索引保存的是数据文件的指针。主键索引和辅助索引是独立的。
4. InnoDB不保存表的具体行数,执行select count(*) from table时需要全表扫描。而MyISAM用-一个变量保存了整个表的行数,执行上述语句时只需要读出该变量即可,速度很快;
5. InnoDB不支持全文索引,而MyISAM支持全文索引,查询效率上MyISAM要高; 5.7 已经支持
- 如何选择
1.是否要支持事务,如果是选择InnoDB, 如果不需要可以考虑MyISAM
2.如果表中绝大多数都只是读查询,可以考虑MyISAM,如果既有读写也挺频繁,请使用InnoDB。
3.系统崩溃后,MyISAM恢复起来更困难,能否接受;
- 表存储引擎的查看与修改
SHOW CREATE TABLE food;
ALTER TABLE food ENGINE=INNODB;
七,SQL优化:
1,概述
- 1.解释:对于特定的要求,使用更优的SQL策略或索引策略,以达到让结果呈现的时间更短,从而提升操作效率的过程就是SQL优化。
- 2. SQL优化包含在数据库级别优化中。我们平常所说的SQL优化就是.指优化SQL语句和索引
- 3. SQL优化是是伴随着业务而进行优化的,并不是下面的所有操作就必须都达到才是好的优化。
2,常规调优思路
- 1、查看slow-log, 分析slow-log,分析出查询慢的语句。
- 2、按照一定优先级,进行一个一个的排查所有慢语句。
- 3、分析topsql,进行explain调试,查看语句执行时间。
- 4、调整索引或语句本身。
3,slow-log慢查询日志
- 记录所有执行时间超过long_query_time秒的所有查询或不适用于索引的查询|
- long query_ time 默认时间为10秒。即超过10秒的查询都认为是慢查询
- 慢查询日志默认名称:主机名slow.log
- 查看慢查询日志语句:SHOW VARIABLES LIKE '%quer%';
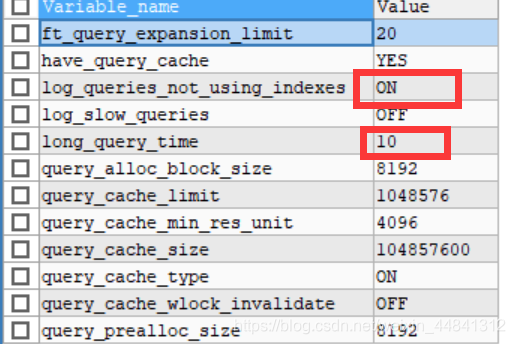
- 参数:
- slow_ query_ log 表示是否开启慢查询日志。(默认开启)
- slow_ query_ log_ fite 慢查询日志文件名
- long_ query_time 慢查询阈值,该值需要在配置文件my.ini中修改,重启mysql服务后生效
- log_ queries_not _using_indexes 是否记录不适用于索引的查询
- 去mysql.slow.log中查看哪些语句超时了
3,explain执行计划:
- 1.执行计划:在MySQL中可以通过explain关键字模拟优化器执行SQL语句,从而知道MySQL是如何处理SQL语句的。
- 2. explain: MySQL执行计划的工具,查看MySQL如何设定执行计划
- 3.老版本MySQL中explain 分为两类(在MySQL5.7中已经不在区分)
- explain extended:会在explain 的基础上额外提供一些查询优化的信息。紧随其后通过show warnings命令可以得到优化后的查询语句,从而看出优化器优化了什么。额外还有filtered列,是一个半分比的值,rows* filtered/100可以估算出将要和explain 中前一个表进行连接的行数(前-一个表指explain中的id值比当前表id值小的表)。
- explain的简单使用:
EXPLAIN SELECT * FROM food;

表中参数的介绍:
- id:值越大,执行时的优先级越高。有几个查询就有几行数据
- select_type:值有simple,primary,drived,subQuery,Union。分别是简单查询,复杂查询(外层查询),衍生查询(form后面的子查询),子查询(where后面的子查询,联合语句中前一个查询为primary后一个尾union
- type:指标从好到差:system> const > eq_ ref > ref > fulltext > ref_ or_ null > index_ merge >unique_ subquery > index_ subquery > range > index> ALL(到达fulltext 性能算很棒了)
type类型中的值:
- system:表中只有一-行数据。属于const的特例。如果物理表中就一行数据为ALL
- const: 查询结果最多有一个匹配行。因为只有一行,所以可以被视为常量。const 查询速度非常快,因为只读一次。一般情况下把主键或唯一索引作为唯一条件的查询都是const
- eq_ref:查询时查询外键表全部数据。且只能查询主键列或关联列。且外键表中外键列中数据不能有重复数据,且这些数据都必须在主键表中有对应数据(主键表中数据可以有没有用到的)
- ref: 相比eq_ _ref, 不对外键列有强制要求,里面的数据可以重复,只要出现重复的数据取值就是τef。 也可能是索引查询。
- range: 把这个列当作条件只检索其中一个范围。常见where从句中出现between、 <、in等。主要应用在具有索引的列中,具有递增属性的更好
- index: Full Index Scan,index 与ALL区别为index类型只遍历索引树。这通常为ALL块,因为索引文件通常比数据文件小。(Index与ALL虽然都是读全表,但index是从索引中读取,而ALl是从硬盘中读取)
- ALL: Full Table Scan, 遍历全表以找到匹配的行
其他字段:
- possible_ _type :查询条件 字段涉及到的索引,可能没有使用
- key:实际使用了的索引
- key_ len:表示索引中使用的字节数,查询中使用的索引的长度(最大可能长度),并非实际使用长度,理论上长度越短越好。key_ len是根据表定义计算而得的,不是通过表内检索出的
- ref;:显示索引的哪一列被使用了,如果可能,是一个常量constJ
- rows:根据表统计信息及索引选用情况,大致估算出找到所需的记录所需要读取的行数
- fitered:显示了通过条件过滤出的行数的百分比估计值。
- Extra:不适合在其他字段中显示,但是十分重要的额外信息
索引的优点:加快查询的速度
索引的缺点:修改数据时需要维护索引,耗费空间,时间
什么时候使用索引:
- 第一、在经常需要搜索的列上,可以加快搜索的速度;
- 第二、在作为主键的列上,强制该列的唯一性 和组织表中数据的排列结构;|
- 第三、在经常用在连接的列上,这些列主要是一些外键, 可以加快连接的速度;
- 第四、在经常需要根据范围进行搜索的列上创建索引,因为索引已经排序,其指定的范围是连续的;
- 第五、在经常需要排序的列上创建索引,因为索引已经排序,这样查询可以利用索引的排序,加快排序查询时间;
- 第六、在经常使用在WHERE子句中的列上面创建索引,加快条件的判断速度。
什么时候不要创建索引:
- 第一,对于那些在查询中很少使用或者参考的列不应该创建索引。这是因为,既然这些列很少使用到,因此有索引或者无索引,并不能提高查询速度。相反,由于增加了索引,反而降低了系统的维护速度和增大了空间需求。
- 第二,对于那些只有很少数据值的列也不应该增加索引。这是因为,由于这些列的取值很少,例如人事表的性别列,在查询的结果中,结果集的数据行占了表中数据行的很大比例,即需要在表中搜索的数据行的比例很大。增加索引,并不能明显加快检索速度。
- 第三,对于那些定义为text,image和bit数据类型的列不应该增加索引。这是因为,这些列的数据量要么相当大,要么取值很少。
- 第四,当修改性能远远大于检索性能时,不应该创建索引。这是因为,修改性能和检索性能是互相矛盾的。当增加索引时,会提高检索性能,但是会降低修改性能。I当减少索引时,会提高修改性能,降低检索性能。因此,当修改性能远远大于检索性能时,不应该创建索引。
总结:
- 只有主键约束时,explain分析发现类型是all
- 分析添加索引,进行explain分析发现类型值为ref。使用速度加快了
- 索引在同一个表时候不能同名,在不同的表时候可以同名
SHOW INDEX FROM [table_ name]#显示索引
SHOW KEYS FROM [table_ name]#显示key
DROP INDEX index_ name ON talbe_ name#删除索引
ALTER TABLE table name DROP INDEX index name#修改索引
ALTER TABLE table name DROP PRIMARY KEY#修改主键
补充(不用看很乱):
一,问题:
- 数据库中最常见的慢查询优化方式是什么?
- 为什么加索引能优化慢查询 ?
- MYsql中的存储引擎有:MyIsm,Innodb
- 你知道哪些数据结构可以提高查询速度
- 那这些数据结构既然都能优化查询速度,
- Mysq|为何选择使用B+树?
二,基础知识:
- 局部性原理:程序和数据的访间都有聚集成群的倾向。在一个时间段内、仅使用其中一小部分(称空间局部性),或者最近访问过的程序代码和数据,很快又被访问的可能性很大(称时间
局部性)。 - 磁盘预读(预读的长度一般为页(page) 的整数倍),页是存储器的逻辑块,操作系统往往将主存和磁盘存储区分割为连续的大小相等的块,每个存储块称为一页(在许多操作系统中,页大小通常为4k),主存和磁盘以页为单位交换数据。
- MYsql中的索引是什么?索引是帮助MySQL高效获取数据的数据结构,索引存储在文件系统中,索引的文件存储形式与存储引擎有关,索引文件的结构:hash,二叉树,B树,B+树
- B树特点:
1、所有键值分布在整颗树中
2、搜索有可能在非叶子结点结束,在关键字全集内做-次查找,性能逼近二分查找
3、每个节点最多拥有m个子树
4、根节点至少有2个子树
5、分支节点至少拥有m/2颗子树(除根节点和叶子节点外都是分支节点)
6、所有叶子节点都在同一层、每个节点最多可以有m-1个key,并且以升序排列
- B+ 树是在B树的基础之上做的一种优化,变化如下:
1、B+树每个节点可以包含更多的节点,这个做的原因有两个,第一个原因是为了降低树的高度,第二个原因是将数据范围变为多个区间,区问越多,数据检索越快
2、非叶子节点存储key,叶子节点存储key和数据
3、叶子节点两两指针相互连接(符合磁盘的预读特性),顺序查询性能更高
三,mysql索引的一些比较
1,索引结构的比较:
- 使用hash索引结构缺点:
1、利用hash存储的话需要将所有的数据文件添加到内存,比较耗费内存空间
2、如果所有的查询都是等值查询,那么hash确实很快,但是在企业或者实际工作环境中范围查找的数据更多,而不是等值查询,因此hash就不太适合了 - 二叉树索引结构缺点:无论是二又树还是红黑树,都会因为树的深度过深而造成io次数变多,影响数据读取的效率(需要减少IO的次数,减少IO的数量才能提高速率)
2,存储引擎:
InnoDB:
- InnoDB是通过B+ Tree结构对主键创建索引,然后叶子节点中存储记录,如果没有主键,那么会选择唯一键,如果没有唯一键,那么会生成一个6位的row. id来作为主键
- 如果创建索引的键是其他字段,那么在叶子节点中存储的是该记录的主键,然后再通过主键索引找到对应的记录
| MyISM | InnoDB | |
| 索引类型 | 非聚簇类型 | 聚簇类型 |
| 支持事务 | 是 | 否 |
| 支持表锁 | 是 | 是 |
| 支持行锁 | 否 | 是 |
| 支持外键 | 否 | 是 |
| 支持全文搜索 | 是 | 是 |
| 适合的操作类型 | 大量的select | 大量的Insert,delete,update |
3,mysq|索引的五种类型:添加索引可以提高数据的读取速度,提高项目的并发能力和抗压能力。
- 主键索引:主键是-种唯一性索引,但它必须指定为PRIMARY KEY,每个表只能有一个主键。
- 唯一索引:索引列的所有值都只能出现一次,即必须唯,值可以为空。
- 普通索引:基本的索引类型,值可以为空,没有唯一性的限制。
- 全文索引:全文索引的索引类型为FULLTEXT。全文索引可以在varchar、 char、 text类 型的列上创
- 组合索引:多列值组成-一个索引,专门门用于组合搜索
4,索引与约束的区别:
约束是数据完整性中的概念,索引是提升查询效率的一个手段
- 1、约束用来在表中强制某些业务规则,可以分为两大类。第一类用约束来强制行的唯一性;第二类约束通常叫做检查约束,用来指定某个列的数值范围。这种约束不通过索引来实现,他们是通过向引擎中嵌入某些规则来实现的。
- 2、键(包括主键和外键),是另外一种类型的约束,用来定义表之间的参照完整性或数据联系,通常被称作父子表联系。
- 3、唯一索引是一种实体,应当只用来提高查询的性能。
- 1、约束是在事务结束的时候执行;
- 2、索引是立即执行,而不管事务状态或引擎的日志模式。














 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









