










 本文介绍了Linux中的协程概念,包括对称和非对称协程的区别,以及不同类型的协程栈(静态、分段、共享、虚拟内存栈)和调度策略(栈式、星切、环切)。还探讨了常见的协程库如boost.context、boost.coroutine、ucontext、fiber和libco/libgolibgo的特点和适用场景。
本文介绍了Linux中的协程概念,包括对称和非对称协程的区别,以及不同类型的协程栈(静态、分段、共享、虚拟内存栈)和调度策略(栈式、星切、环切)。还探讨了常见的协程库如boost.context、boost.coroutine、ucontext、fiber和libco/libgolibgo的特点和适用场景。
【Linux】协程简介
一、什么是协程?
首先回忆一下线程的概念:
线程是操作系统能够进行运算调度的最小单位。被包含在进程之中,是进程的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程可以并发执行多个线程,每个线程会执行不同的任务。
简介
- 协程可以理解为一种用户态的轻量级线程,切换由用户定义,各任务之间可以控制执行、暂停、恢复函数,来达到多任务协作的目的;
- 协程上下文切换速度快, 且不会陷入内核态;
- 协程拥有独立的寄存器上下文和栈,协程调度切换时,将寄存器上下文和栈,在来回切换时,恢复先前保存的寄存器上下文和栈。
- 一个线程中可以有多个协程,协程是运行在线程之中的逻辑处理单元。协程在线程里的运行是串行的。
- 协程之间的调度通过调度器或者自己主动放开对CPU的占有,让给其他协程。
优点
- 协程具有极高的执行效率,由于子程序切换不是线程切换,是由程序自身控制,故协程没有线程切换的开销;
- 多线程的线程数越多,协程的性能越显著;
- 访问共享资源不需要使用多线程的锁机制和变量冲突,由于只有一个线程,故在协程只需要判断状态即可,降低了编码难度;
- 以同步代码的方式写异步逻辑;
二、为什么使用协程?
为什么使用协程,我们先从server框架的实现说起,对于client-server的架构,server最简单的实现如下。即串行地接收连接、读取请求、处理、应答。该实现弊端显而易见,server同一时间只能为一个客户端服务。
while(1) {
accept();
recv();
do();
send();
}
为充分利用好多核cpu进行任务处理,我们有了多进程/多线程的server框架,这也是server最常用的实现方式:
accept进程 - n个epoll进程 - n个worker进程
- accpet进程处理到来的连接,并将fd交给各个epoll进程
- epoll进程对各fd设置监控事件,当事件触发时通过共享内存等方式,将请求传给各个worker进程
- worker进程负责具体的业务逻辑处理并回包应答
以上框架以事件监听、进程池的方式,解决了多任务处理问题,但我们还可以对其作进一步的优化。
进程/线程是Linux内核最小的调度单位,一个进程在进行io操作时 (常见于分布式系统中RPC远程调用),其所在的cpu也处于iowait状态。直到后端svr返回,或者该进程的时间片用完、进程被切换到就绪态。是否可以把原本用于iowait的cpu时间片利用起来,发生io操作时让cpu处理新的请求,以提高单核cpu的使用率?
协程在用户态下完成切换,由程序员/调度器完成调度,结合对socket类/io操作类函数挂钩子、添加事件监听,为以上问题提供了解决方法。
三、协程的种类
协程目前分两种,一种是go语言采用的对称协程;一种是libco采用的非对称协程。
yield: 协程执行到⼀半就退出,暂时让出CPU执行权。
resume: 协程重新恢复运行。
1、对称协程
这里借用知乎博主tx征服者的图来向大家说明:
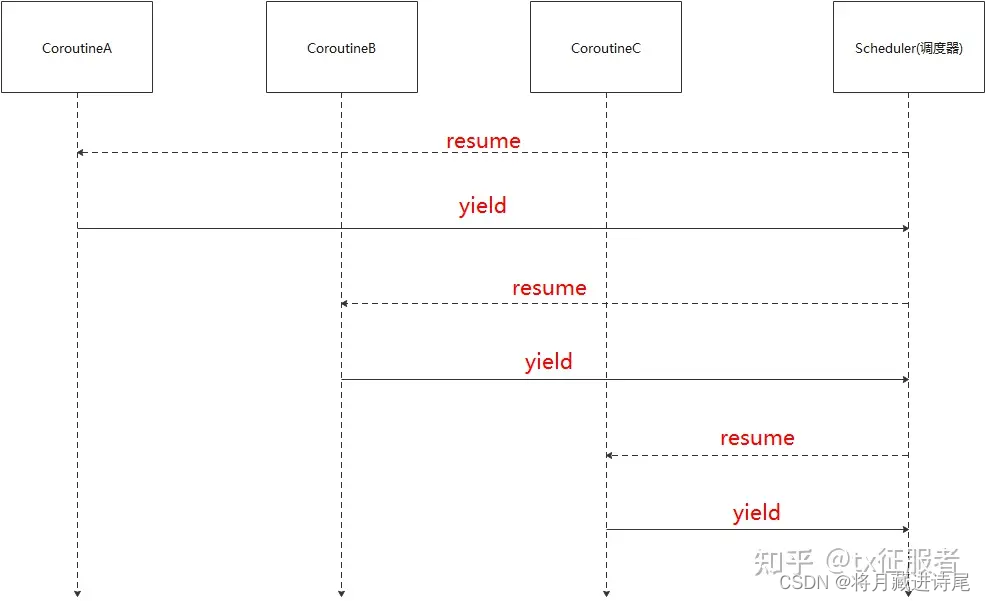
对称协程其实就是由协程调度器来负责,协程不允许调度其他协程。 调度器resume协程A,那么协程A会yeild回调度器,再由调度器去执行其他的协程。如果我们把resume的虚线都放在左边,yeild的实线都放在右边。以调度器为中心,那么他是不是就是一个对称的图形呢?
2、非对称协程
我们再来看一下非对称协程:
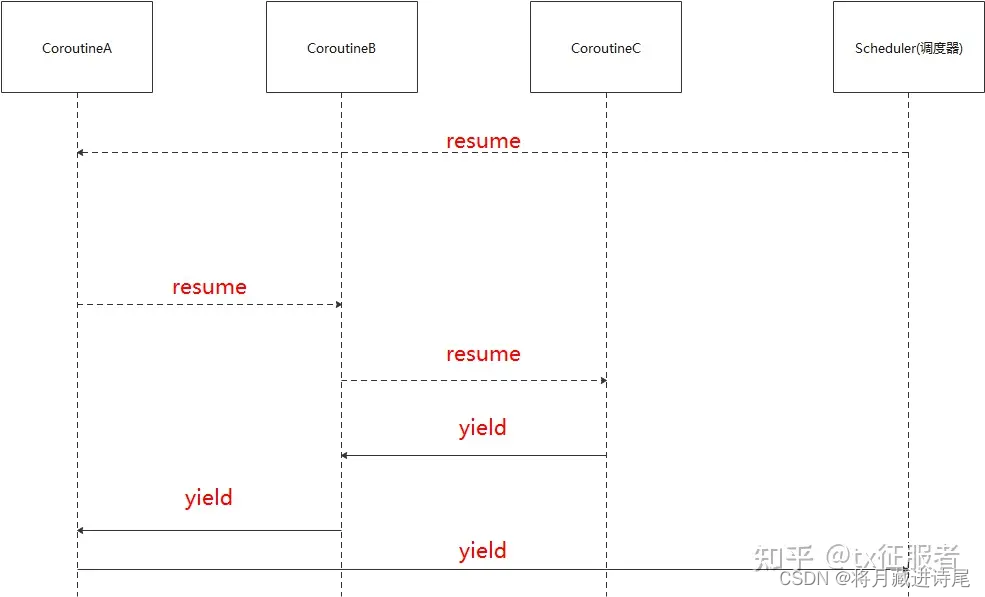
非对称调度由调度器来调度协程A,然后协程A再调动协程B。 那么Byeild让出CPU使用权就不是让给调度器了,而是协程A。简而言之就是从哪儿来,回哪儿去。同样,将此展开也不是一个对称的图形了。
四、协程栈
1、静态栈
固定大小的栈,容易造成溢出等现象。
2、分段栈
插入栈内存检测代码,若栈不够用,则申请新内存扩展;但该方法难以在第三方库中进行使用。
3、共享栈
申请一块大内存作为共享栈,在运行前,先把协程栈的内存copy到共享栈中,运行结束后再计算协程栈真正使用的内存,copy出来保存起来,这样每次只需保存真正使用到的栈内存量即可。
优点:该方案极大程度上避免了内存的浪费,做到了用多少占多少,同等内存条件下,可以启动的协程数量更多。
缺点:但该方案在copy上花费了时间,降低速度,导致协程切换慢。
4、虚拟内存栈
机制:进程申请的内存并不会立即被映射成物理内存,而是仅管理于虚拟内存中,真正对其读写时会触发缺页中断,此时才会映射为物理内存;
可以做到用多少占多少,冗余不超过一个内存页大小。
五、协程调度
1、栈式调度
协程队列是一个栈式结构,创建的协程都置于栈顶,并且会立即暂停当前协程并切换至子协程中运行,子协程运行结束后,继续切换回来执行父协程;越是栈底部的协程,被调度到的机会将越少,甚至出现只有栈顶的协程在互相切换。
2、星切调度
调度线程 -> 协程A -> 调度线程 -> 协程B -> 调度线程 -> …
将当前可调度的协程组织成队列,按顺序从头部取出协程调度;新协程则从尾部入队,调度后再将协程从尾部入队。
3、环切调度
调度线程 -> 协程A -> 协程B -> 协程C -> 协程D -> 调度线程 -> …
从调度顺序上可知,环切的切换次数仅为星切的一半,可以提高整体切换速度;但在多线程调度、WorkSteal方面会带来一定的挑战。
六、常见协程库
boost.context
提供了上下文的抽象,并给了两种方式,fiber和call/cc的方式保留和执行上下文切换;
性能佳,推荐使用,切换性能可达到1.25亿次/秒。
boost.coroutine
提供的协程只能单向传递数据,数据只能单向的从一个代码块流向另一个代码块。流入流出分别对应着push_type和pull_type类型,由这两个类型组成协程间跳转的通道,同时也是数据传递的通道。
ucontext
该库是在unix下提供的,使用是最安全可靠,但性能较差,大概200万次/秒。
fiber
该库是在window下提供的,与ucontext类似。
libco
腾讯开源的c++协程库。
libgo
libgo为了有更广阔的适用性,支持了多线程调度、HookSyscall、Worksteal等,同时突破了传统协程库仅用来处理网络io密集型业务的局限,也能适用于cpu密集型业务,充当并行编程库来使用。
参考文献
协程 及 libco 介绍
ucontext-人人都可以实现的简单协程库
协程学习(对称和非对称)
Linux【协程】 | 常见协程库简介
















 496
496

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











