






Sleuth概述
前言
在微服务架构中,众多的微服务之间互相调用,如何清晰地记录服务的调用链路是一个需要解决的问题。同时,由于各种原因,跨进程的服务调用失败时,运维人员希望能够通过查看日志和查看服务之间的调用关系来定位问题,而Spring cloud sleuth组件正是为了解决微服务跟踪的组件。
一、背景
1、微服务的现状?
随着微服务架构的流行,服务按照不同的维度进行拆分,一次请求往往需要涉及到多个服务。在复杂的微服务架构系统中,几乎每一个前端请求都会形成一个复杂的分布式服务调用链路。一个请求完整调用链可能如下图所示:

随着业务规模不断增大、服务不断增多以及频繁变更的情况下,面对复杂的调用链路就带来一系列问题:
如何快速发现问题?
如何判断故障影响范围?
如何梳理服务依赖以及依赖的合理性?
如何分析链路性能问题以及实时容量规划?
而链路追踪的出现正是为了解决这种问题,它可以在复杂的服务调用中定位问题,除此之外,如果某个接口突然耗时增加,也不必再逐个服务查询耗时情况,我们可以直观地分析出服务的性能瓶颈,方便在流量激增的情况下精准合理地扩容。
2、什么是链路追踪
单纯的理解链路追踪,就是将一次分布式请求还原成调用链路,进行日志记录,性能监控并将一次分布式请求的调用情况集中展示。比如各个服务节点上的耗时、请求具体到达哪台机器上、每个服务节点的请求状态等等。
3、链路追踪相关产品
常见的链路追踪技术有下面这些:
cat:由大众点评开源,基于Java开发的实时应用监控平台,包括实时应用监控,业务监控 。 集成方案是通过代码埋点的方式来实现监控,比如: 拦截器,过滤器等。 对代码的侵入性很大,集成成本较高。风险较大。
zipkin:由Twitter公司开源,开放源代码分布式的跟踪系统,用于收集服务的定时数据,以解决微服务架构中的延迟问题,包括:数据的收集、存储、查找和展现。该产品结合spring-cloud-sleuth使用较为简单, 集成很方便, 但是功能较简单。
pinpoint:Pinpoint是韩国人开源的基于字节码注入的调用链分析,以及应用监控分析工具。特点是支持多种插件, UI功能强大,接入端无代码侵入。
skywalking:本土开源的基于字节码注入的调用链分析,以及应用监控分析工具。特点是支持多种插件, UI功能较强,接入端无代码侵入。目前已加入Apache孵化器。
Sleuth:SpringCloud 提供的分布式系统中链路追踪解决方案。
注意: SpringCloud alibaba技术栈中并没有提供自己的链路追踪技术的,我们可以采用Sleuth +Zinkin来做链路追踪解决方案
二、Sleuth概述
1、什么是Sleuth
Spring Cloud Sleuth 为 Spring Cloud 实现了分布式跟踪解决方案。兼容 Zipkin,HTrace 和其他基于日志的追踪系统,例如 ELK(Elasticsearch 、Logstash、 Kibana)。
Spring Cloud Sleuth 提供了以下功能:
链路追踪:通过 Sleuth 可以很清楚的看出一个请求都经过了那些服务,可以很方便的理清服务间的调用关系等。
性能分析:通过 Sleuth 可以很方便的看出每个采样请求的耗时,分析哪些服务调用耗时,当服务调用的耗时随着请求量的增大而增大时, 可以对服务的扩容提供一定的提醒。
数据分析,优化链路:对于频繁调用一个服务,或并行调用等,可以针对业务做一些优化措施。
可视化错误:对于程序未捕获的异常,可以配合 Zipkin 查看。
2、Sleuth基本概念
Sleuth基本概念涉及到三个专业术语: span、Trace、Annotations。
span
基本工作单位,每次发送一个远程调用服务就会产生一个 Span。Span 是一个 64 位的唯一 ID。通过计算 Span 的开始和结束时间,就可以统计每个服务调用所花费的时间。。
Trace
一系列 Span 组成的树状结构,一个 Trace 认为是一次完整的链路,内部包含 n 多个 Span。Trace 和 Span 存在一对多的关系,Span 与 Span 之间存在父子关系。
Annotations
用来及时记录一个事件的存在,一些核心 annotations 用来定义一个请求的开始和结束。
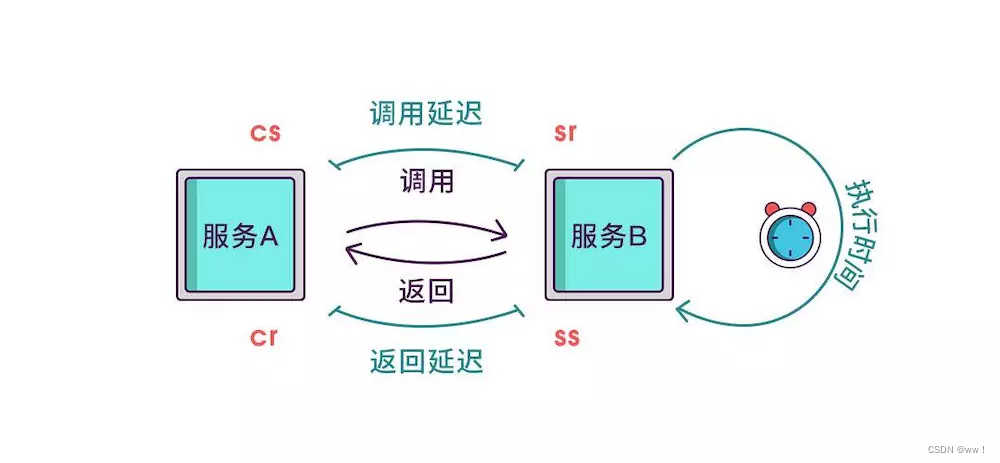
cs - Client Sent:客户端发起一个请求,这个 annotation 描述了这个 span 的开始;
sr - Server Received:服务端获得请求并准备开始处理它,如果 sr 减去 cs 时间戳便可得到网络延迟;
ss - Server Sent:请求处理完成(当请求返回客户端),如果 ss 减去 sr 时间戳便可得到服务端处理请求需要的时间;
cr - Client Received:表示 span 结束,客户端成功接收到服务端的回复,如果 cr 减去 cs 时间戳便可得到客户端从服务端获取回复的所有所需时间。
核心 为什么能够进行整条链路的追踪? 其实就是一个 Trace ID 将 一连串的 Span 信息连起来了。根据 Span 记录的信息再进行整合就可以获取整条链路的信息。
3、举例理解Sleuth基本概念
上面这样写可能有点抽象,这里通过实际例子来解释

1)这个图中 从1->6 是一个完整的请求,所以这个完整的请求中有一个相同的TraceId。
2)server1->server2 可以理解是一个接口的请求,所以他们有着相同的SpanId。同样道理 server2->server3,server2->server4 也有着相同的SpanId。同时parentid,就是上一级的SpanId。
3)server1中的 cs cr - 分别代表请求server2的开始时间,和server1接收响应时间。(cr – cs)时间戳便可以得到整个请求所消耗的时间
4)server2中的 sr ss - 分别代表server2获取请求并准备开始处理它的开始时间,ss (服务端发送响应)– 代表server2服务结束执行时间。
二、实现原理
这里通过图片来循序渐进的理解Sleuth基本概念
如果想知道一个接口在哪个环节出现了问题,就必须清楚该接口调用了哪些服务,以及调用的顺序,如果把这些服务串起来,看起来就像链条一样,我们称其为调用链。
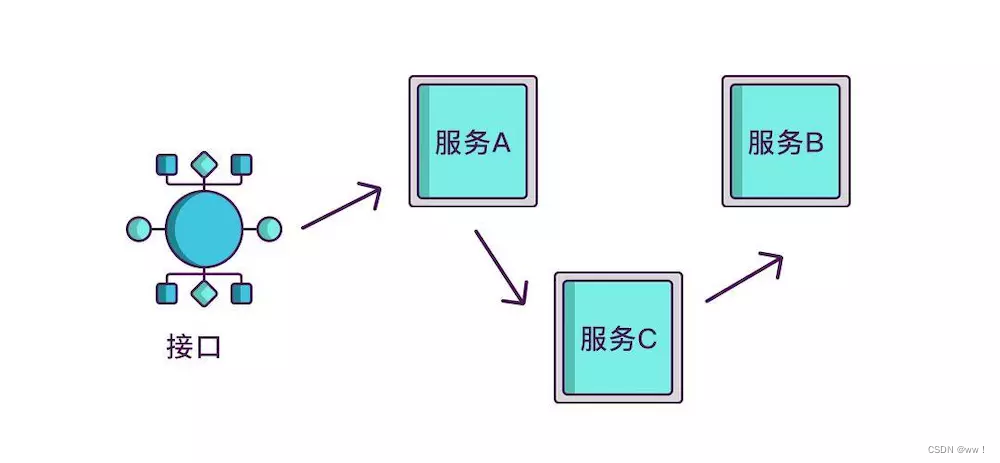
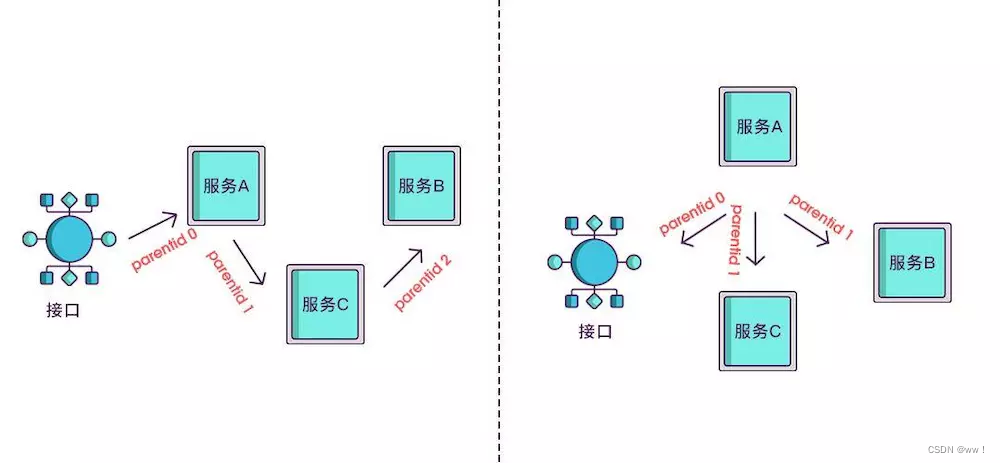
想要实现调用链,就要为每次调用做个标识,然后将服务按标识大小排列,可以更清晰地看出调用顺序,我们暂且将该标识命名为 spanid。
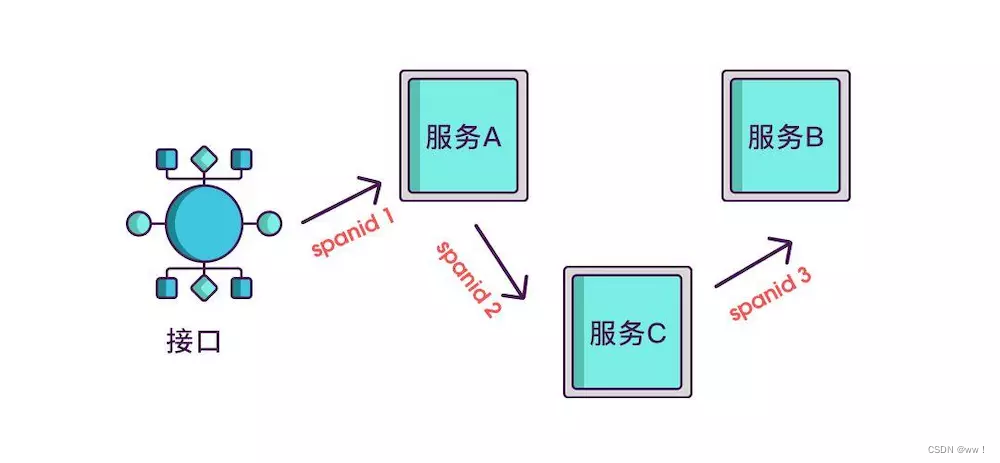
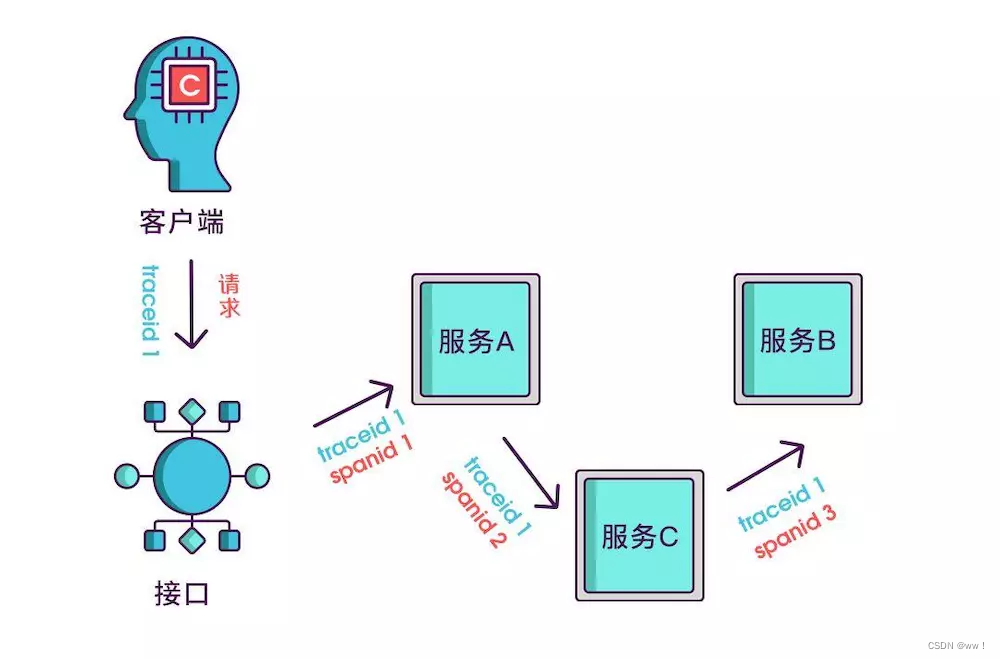
实际场景中,我们需要知道某次请求调用的情况,所以只有 spanid 还不够,得为每次请求做个唯一标识,这样才能根据标识查出本次请求调用的所有服务,而这个标识我们命名为 traceid。
现在根据 spanid 可以轻易地知道被调用服务的先后顺序,但无法体现调用的层级关系,正如下图所示,多个服务可能是逐级调用的链条,也可能是同时被同一个服务调用。
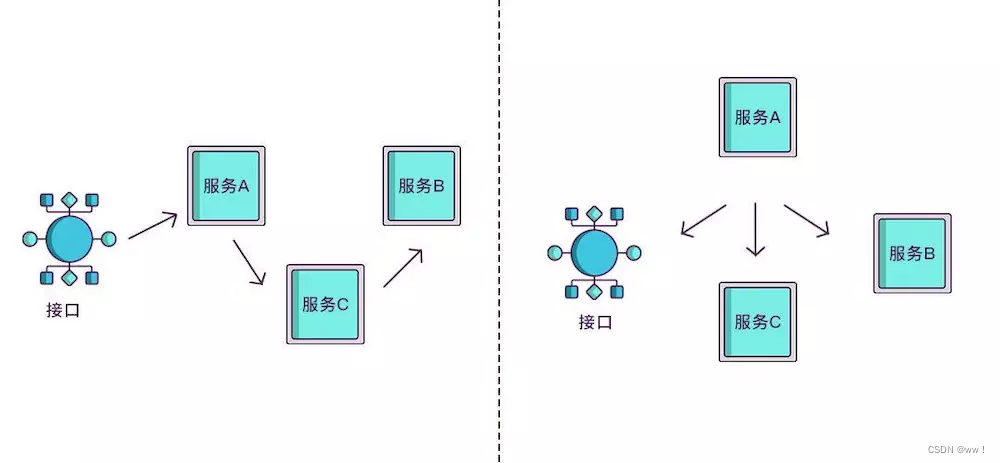
所以应该每次都记录下是谁调用的,我们用 parentid 作为这个标识的名字。
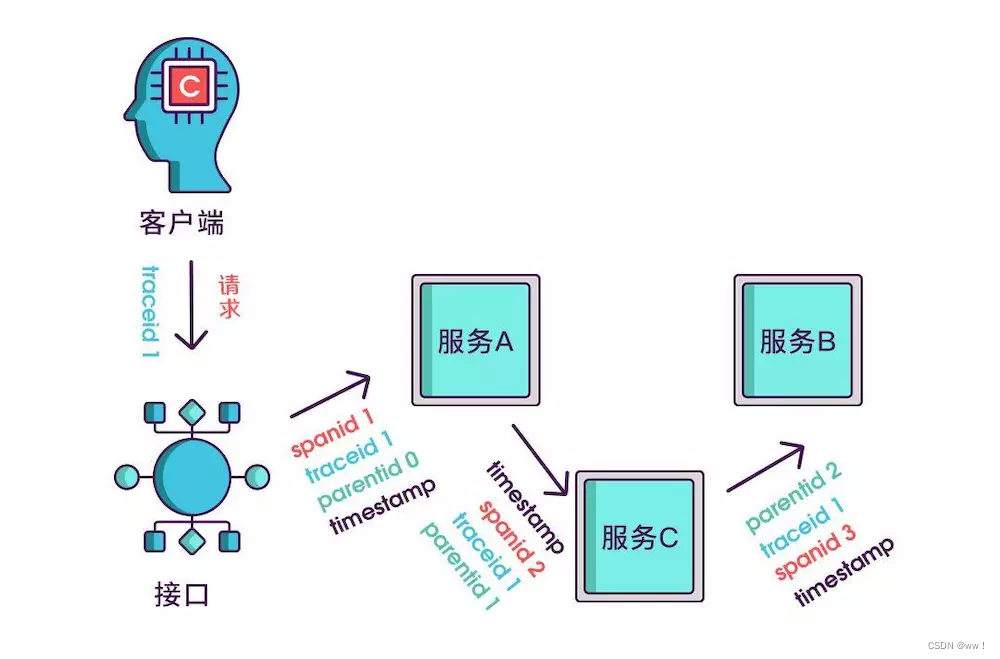
到现在,已经知道调用顺序和层级关系了,但是接口出现问题后,还是不能找到出问题的环节,如果某个服务有问题,那个被调用执行的服务一定耗时很长,要想计算出耗时,上述的三个标识还不够,还需要加上时间戳,时间戳可以更精细一点,精确到微秒级。
只记录发起调用时的时间戳还算不出耗时,要记录下服务返回时的时间戳,有始有终才能算出时间差,既然返回的也记了,就把上述的三个标识都记一下吧,不然区分不出是谁的时间戳。
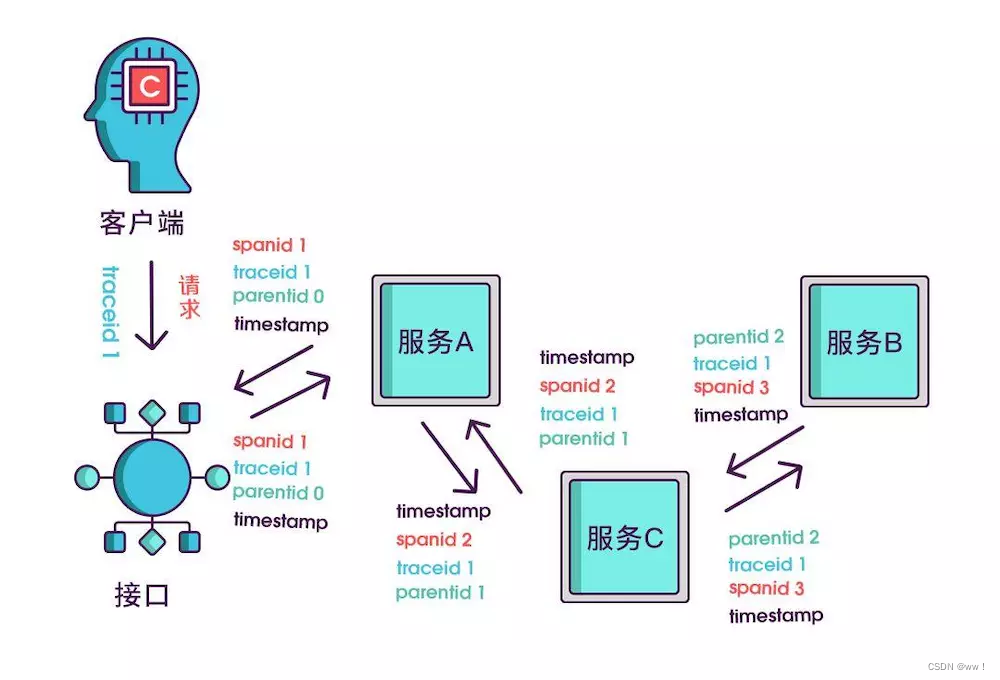
虽然能计算出从服务调用到服务返回的总耗时,但是这个时间包含了服务的执行时间和网络延迟,有时候我们需要区分出这两类时间以方便做针对性优化。那如何计算网络延迟呢?我们可以把调用和返回的过程分为以下四个事件。
Client Sent 简称 cs,客户端发起调用请求到服务端。
Server Received 简称 sr,指服务端接收到了客户端的调用请求。
Server Sent 简称 ss,指服务端完成了处理,准备将信息返给客户端。
Client Received 简称 cr,指客户端接收到了服务端的返回信息。
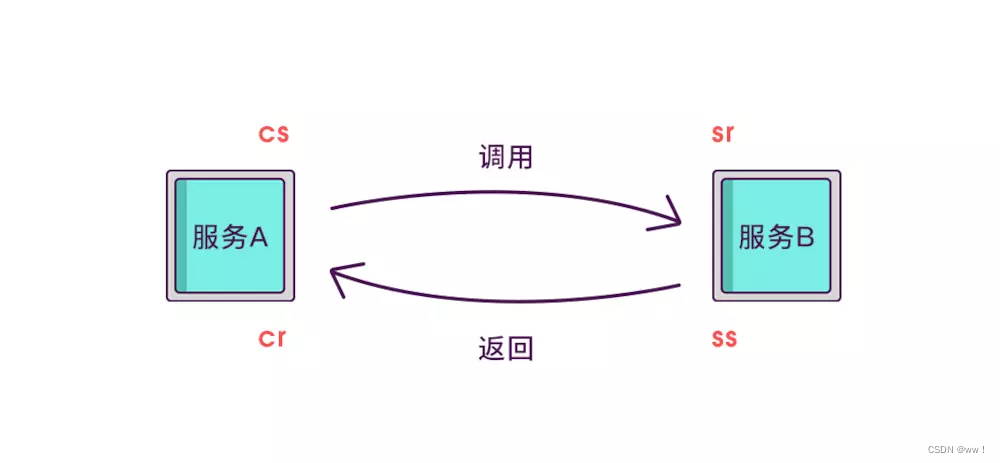
假如在这四个事件发生时记录下时间戳,就可以轻松计算出耗时,比如
sr 减去 cs 就是调用时的网络延迟
ss 减去 sr 就是服务执行时间
cr 减去 ss 就是服务响应的延迟
cr 减 cs 就是整个服务调用执行的时间
其实 span 内除了记录这几个参数之外,还可以记录一些其他信息,比如发起调用服务名称、被调服务名称、返回结果、IP、调用服务的名称等,最后,我们再把相同 parentid的 span 信息合成一个大的 span 块,就完成了一个完整的调用链。














 7201
7201











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









