







1.Oracle利用DataX工具导出数据到Mysql。Oracle利用DataX工具导出数据到HDFS。
只是根据导入导出的目的地不同,DataX的Json文件书写内容有所不同。万变不离其宗。
书写的Json格式的导入导出规则文件存放再Job目录下的。
2.Spark概念
Apache Spark是用于大规模数据处理的统一分析引擎。
Spark对任意的数据类型都能进行自定义的计算,Spark可以计算结构化,半结构化,非结构化等各种类型的数据结构,同时,还支持Python,Java,Scala,R以及SQL语言去开发应用程序计算数据。
3.Spark和Hadoop比较
Spark,是分布式计算平台,是一个用scala语言编写的计算框架,基于内存的快速、通用、可扩展的大数据分析引擎。
Hadoop,是分布式管理、存储、计算的生态系统;包括HDFS(存储)、MapReduce(计算)、Yarn(资源调度)。
Spark是由于Hadoop中MR效率低下而产生的高效率快速计算引擎

尽管Spark相对于Hadoop而言具有较大的优势,但是Spark并不能完全替代Hadoop
在计算层面,Spark相比较MR(MapReduce)有巨大的性能优势,但至今仍有许多计算工具基于MR架构,比如非常成熟的Hive。
Spark仅作计算,而Hadoop生态圈不仅有计算(MR)也有存储(HDFS)和资源管理调度(YARN),HDFS和YARN仍是许多大数据体系的核心架构。
4.三大分布式计算系统
Hadoop适合处理离线的静态的大数据;
Spark适合处理离线的流式的大数据;
Storm/Flink适合处理在线的实时的大数据。
5.Spark和MR处理数据相比有两个不同点
其一,Spark处理数据时,可以将中间处理数据结果存储到内存中(MR是通过磁盘来保存和读取处理数据的结果的)
其二,Spark提供了非常丰富的算子(API),可以做到复杂任务也能在一个Spark程序中完成。
6.Spark的架构角色
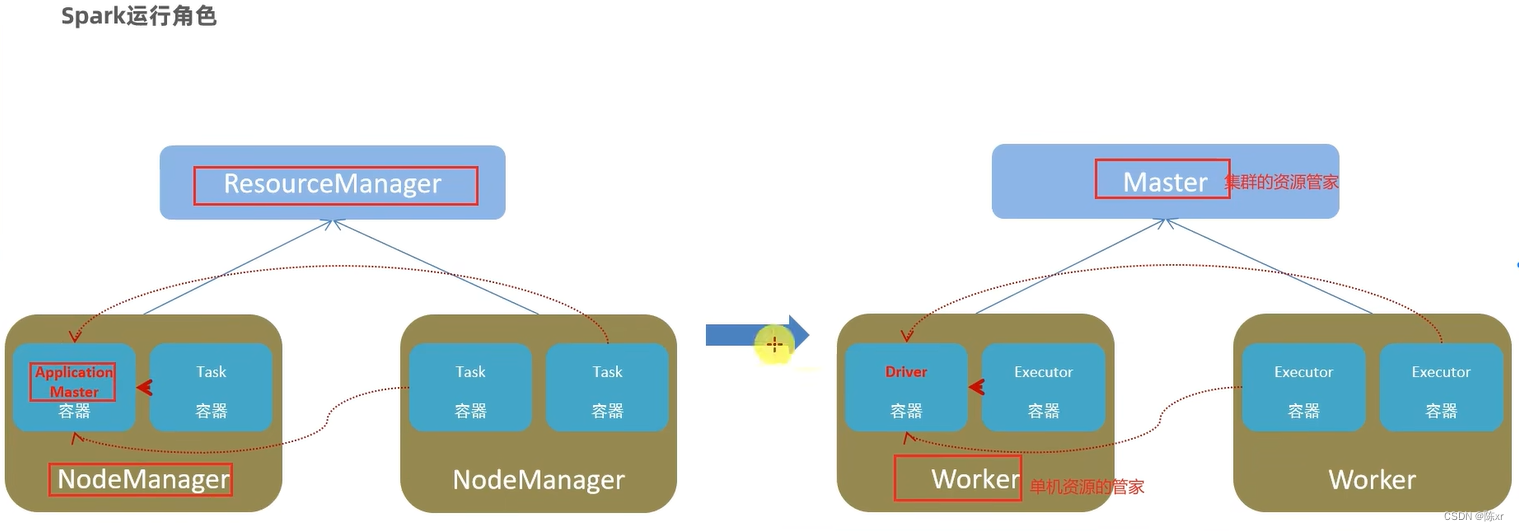
左边是YARM的架构角色,右边是Spark的架构角色
资源层面:
Master角色:集群资源管理
Worker角色:单机资源管理
任务运行层面:
Driver:单个任务的管理
Executor角色:单个任务的计算(给worker干活的)
7.Spark解决什么问题
海量数据的计算,可以进行离线批处理以及实时流计算
8.Spark有哪些模块
核心SparkCore,SQL计算(SparkSQL),流计算(SparkStreaming),图计算(GraphX),机器学习(MLlib)
9.Spark特点有哪些
速度快,使用简单,通用性强,多种模式运行
10.Spark的运行模式
本地模式
集群模式(StandAlone,YARN,K8S)
云模式
11.Spark的运行角色(对比YARN)
Master:集群资源管理(类比ResourceManager)
Worker:单机资源管理(类比NodeManager)
Driver:单任务管理者(类比ApplicationMaster)
Executor:单任务执行者(类比YARN容器内的Task)
12.Spark中Local模式的运行原理
Local模式原理就是以一个独立进程配合其内部的线程们来提供完成Spark运行时的环境,Local模式可以通过spark-shell/pyspark/spark-submit等来开启
13.bin目录下的pyspark是什么程序
是一个交互式的解释器执行环境,环境启动后就得到了一个Local Spark环境,可以运行python代码去进行spark计算
14.Spark的4040端口是什么
Spark的任务在运行后,会在Driver所在的机器绑定到4040端口,提供当前任务的监控页面以供查看。
15.Spark的StandAlone架构
StandAlone模式是Spark自带的一种集群模式,不同于Local本地模式启动多个进程来模拟集群环境,StandAlone模式真实的在多个机器之间搭建Spark集群的环境,完全可以利用该模式搭建多机器集群,用于真实的大数据处理。
StandAlone是完整的Spark运行环境,其中:
Master角色是以Master进程存在,Worker角色是以Worker进程存在。
Driver角色在运行时存在于Master进程内,Executor运行与Worker进程内。
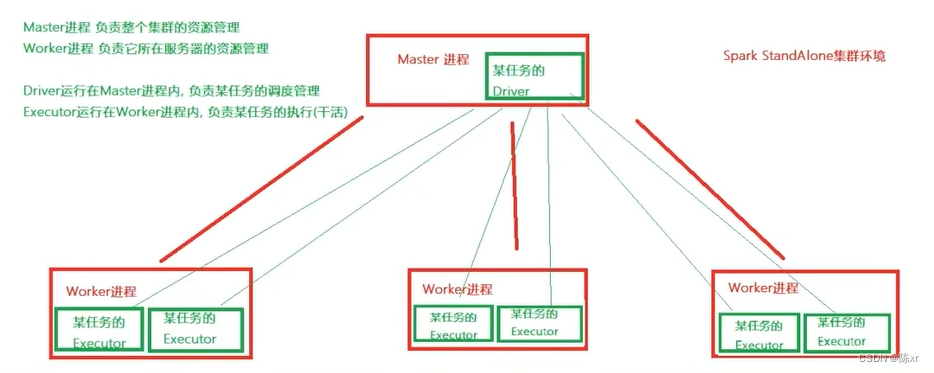
进一步阐述:
StandAlone集群上主要有三类进程:
1.主节点Master进程:
Master角色,管理整个集群资源,并托管运行各个任务的Driver
2.从节点Workers:
Worker角色,管理每个机器的资源,分配对应的资源来运行Executor(Task).。
每个从节点分配资源信息给Worker管理,资源信息包含内存Memory和CPU Cores核心数
3.历史服务器HistoryServer(可选):
Spark Application运行完成后,保存事件日志数据至HDFS,启动HistoryServer可以查看应用运行相关信息。














 3373
3373











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









