







定点补码加法器设计
先行进位加法器
(1)一位全加器:
1)引脚:
- 三个输入: A, B, Cin
- 两个输出: S, Cout
2)逻辑真值关系:
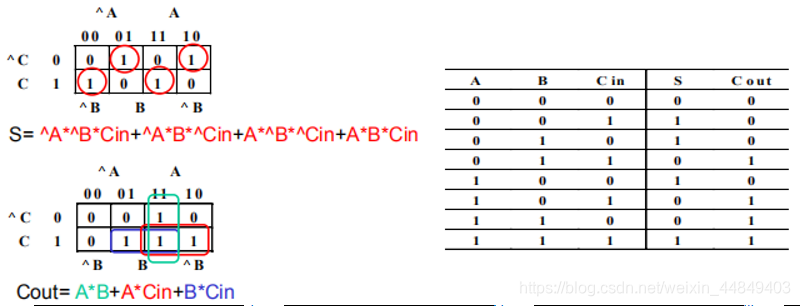
3)逻辑框图:
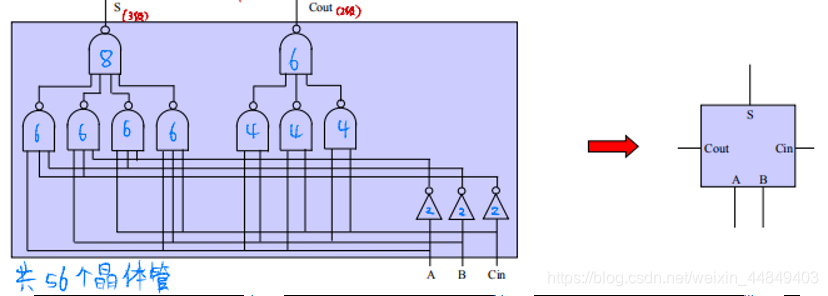
- 需要2,3级门延迟:
- 进位传递2级延迟;
- 产生结果3级延迟; - 两级与非相当于与或:^ ( ^ ( AB ) ^ ( CD ) ) = AB+CD;
(2)串行进位加法器(以16位加法器为例):
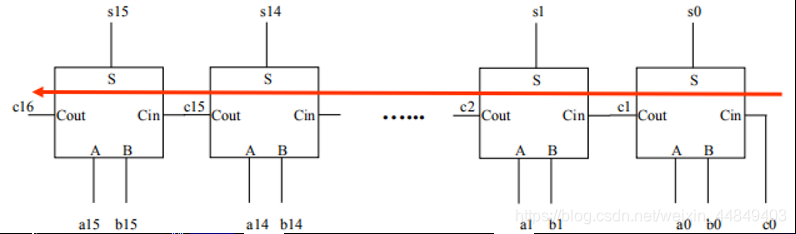
- 进位从低位到高位传送, 形成c16需要32级门延迟;
- 延迟随位数增长线性增长;
(3)并行进位逻辑:
1)进位传递:
- 推导:
c i + 1 = a i b i + a i ∗ c i + b i ∗ c i = a i ∗ b i + ( a i + b i ) ∗ c i = g i + p i ∗ c i ci+1 = aibi+ai*ci+bi*ci = ai*bi+(ai+bi)*ci = gi+pi*ci ci+1=aibi+ai∗ci+bi∗ci=ai∗bi+(ai+bi)∗ci=gi+pi∗ci
g i = a i ∗ b i gi=ai*bi gi=ai∗bi(进位生成因子): 只要gi为1, 就有进位;
p i = a i + b i pi=ai+bi pi=ai+bi(进位传递因子):只要pi为1, 就把低位进位向前传递; - 四位进位传递举例:
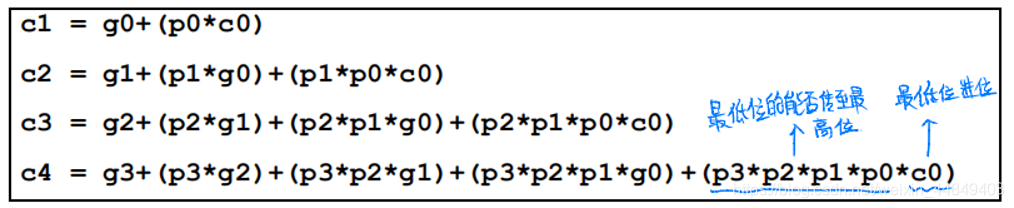
- 结论:只要低位有一个进位生成, 而且被传递, 则进位输出为1
2)4位并行进位加法器逻辑框图:
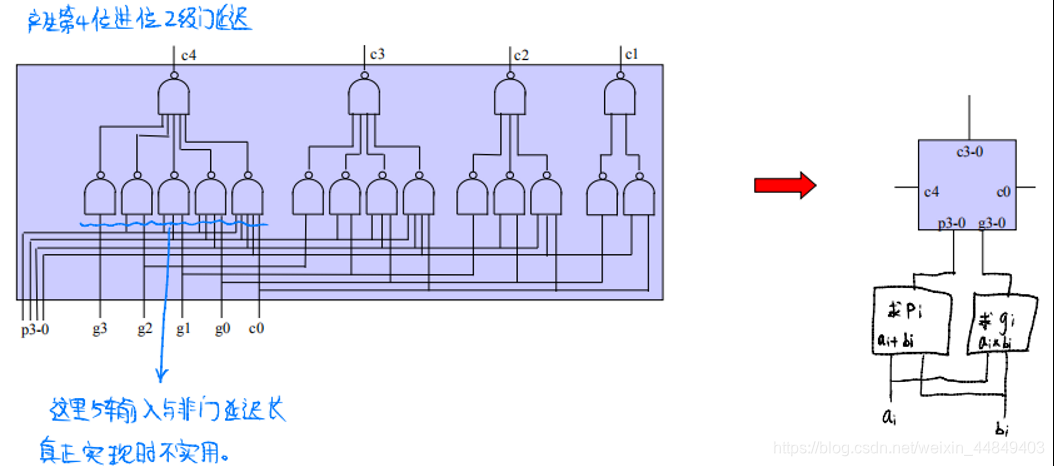
3)改进:以16位加法器为例—分块,块内并行(先行进位),块间串行
- 输入为pi、gi,输出为ci;
- 每次并行产生4位进位,从pi、gi产生c16只要4级传递,8级门延迟(产生运算结果还需要一个异或)。原来从ai、bi产生c16需要16级传递,32级门延迟;
4)进一步改进:以16位加法器为例—分块,块内并行,块间并行
① 进位推导:
- 老办法:产生每块的进位传递因子和进位产生因子
- 进位传递因子:每一位的传递因子都为1时才能传递
P = p 0 ∗ p 1 ∗ p 2 ∗ p 3 P = p0*p1*p2*p3 P=p0∗p1∗p2∗p3(本块可以传递低位进位) - 进位产生因子:块内产生进位, 不考虑进位输入
G = g 3 + ( p 3 ∗ g 2 ) + ( p 3 ∗ p 2 ∗ g 1 ) + ( p 3 ∗ p 2 ∗ p 1 ∗ g 0 ) G = g3+(p3*g2)+(p3*p2*g1)+(p3*p2*p1*g0) G=g3+(p3∗g2)+(p3∗p2∗g1)+(p3∗p2∗p1∗g0)(本块有进位生产)
c 4 = g 3 + ( p 3 ∗ g 2 ) + ( p 3 ∗ p 2 ∗ g 1 ) + ( p 3 ∗ p 2 ∗ p 1 ∗ g 0 ) + ( p 3 ∗ p 2 ∗ p 1 ∗ p 0 ∗ c 0 ) = G + ( P ∗ c 0 ) c4 = g3+(p3*g2)+(p3*p2*g1)+(p3*p2*p1*g0)+(p3*p2*p1*p0*c0)= G +(P*c0) c4=g3+(p3∗g2)+(p3∗p2∗g1)+(p3∗p2∗p1∗g0)+(p3∗p2∗p1∗p0∗c0)=G+(P∗c0)
② 逻辑电路图:(特别注意:大写P,G与小写p,g,他们求法不同)
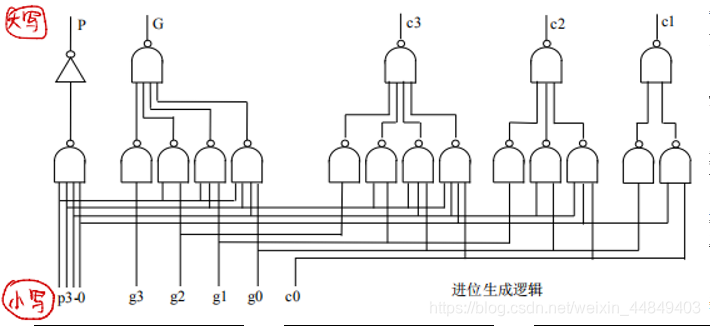
③ 进位生成与传递逻辑:
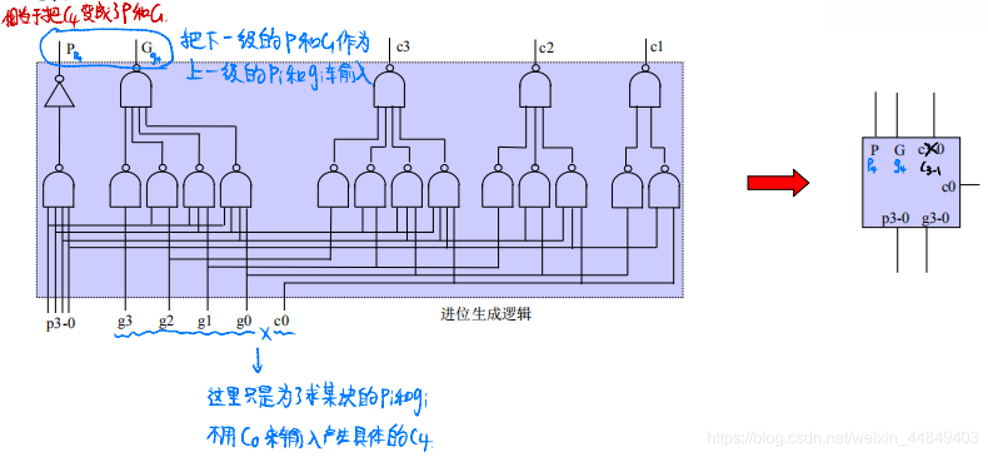
④ 16位块间并行加法器:
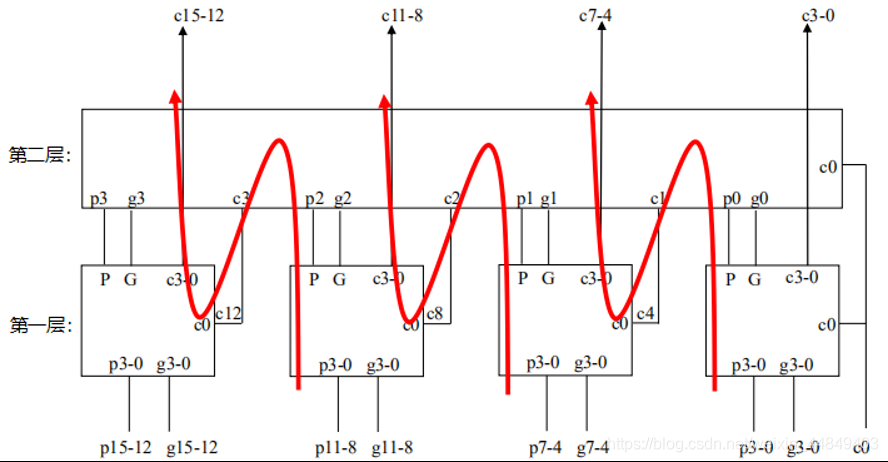
- 逻辑步骤:(自下而上形成pigi,自上而下形成ci)
- 下层的4个4位先行进位逻辑并行生成4个块间进位生成因子 G 和块间进位传递因子 P ;
- 上层的4位先行进位逻辑把下层进位逻辑生成的 P 和 G 作为本层 pi 和 gi 的输入并行生成块间的进位c0,c4,c8,c12;
- 下层的4个4位先行进位逻辑分别把c0,c4,c8,c12作为本块的进位输入c0,再结合本块的 p0-3 和 g0-3 分别计算出本块需要的每一位进位; - 优势在于能更快的生成第i位的c,而不需要依赖于第i-1位的c;
- 从 pi 和 gi 产生 c15-0 共需要 6(2*3) 级门延迟:
- 第一层pg(计算每块的 p3 ,g3)
- 第二层c(c4,c8,c12,c16)
- 第一层c(每块的c3-0,即:c3-0,c7-4,c11-8,c15-12)//这里c4,c8,c12,c16为上一步计算得来,这里为了表述方便,说成是这一步产生; - 其中,最大与非门的扇入为4;
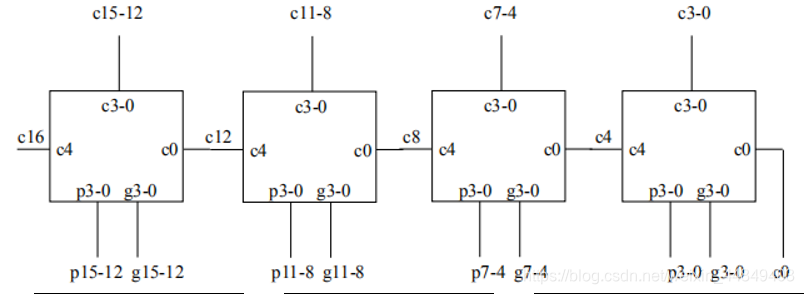
⑤ 32/64位加法器:(用的最多)
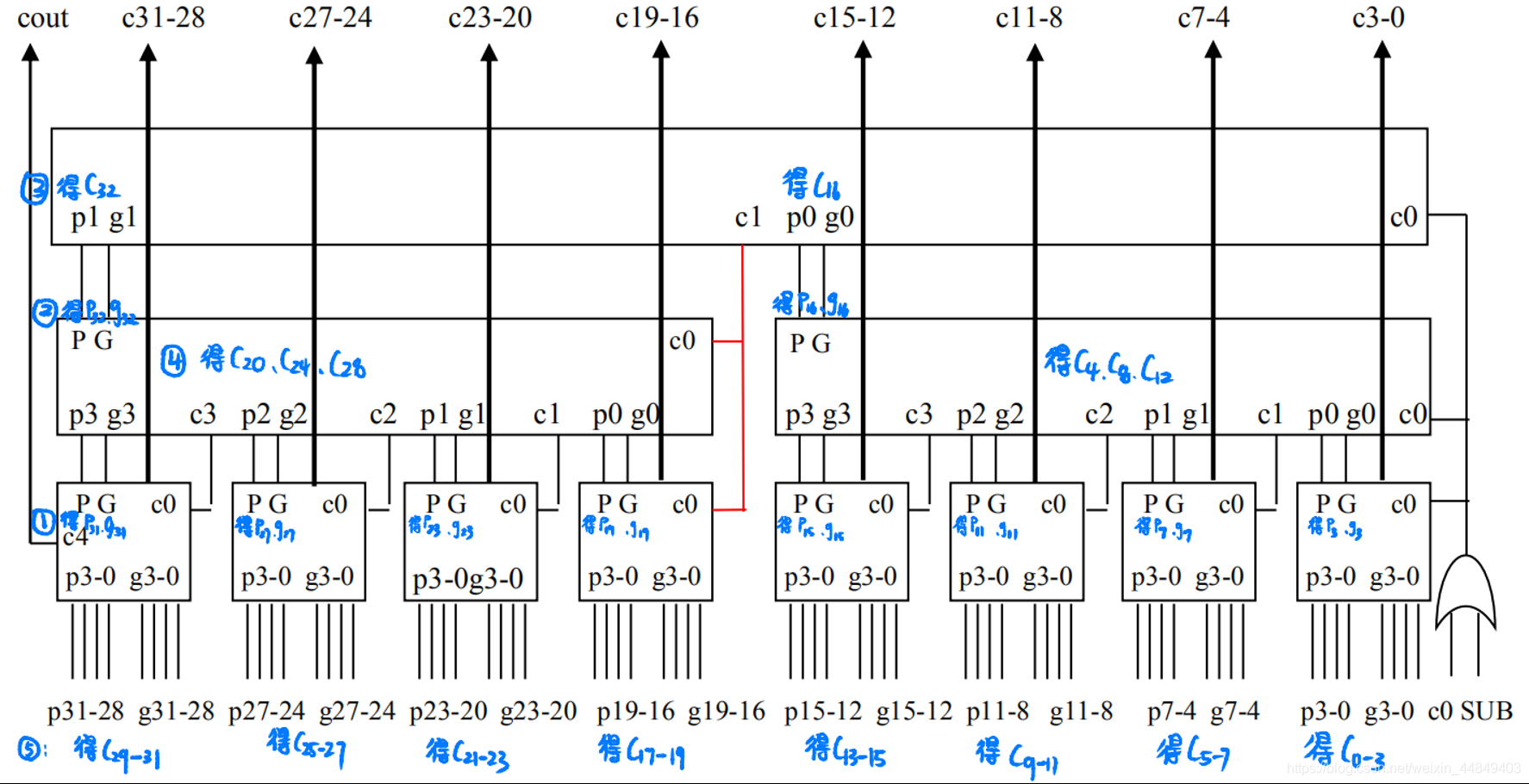 共10级门延迟;
共10级门延迟;
补码减法算法
(1)原理:
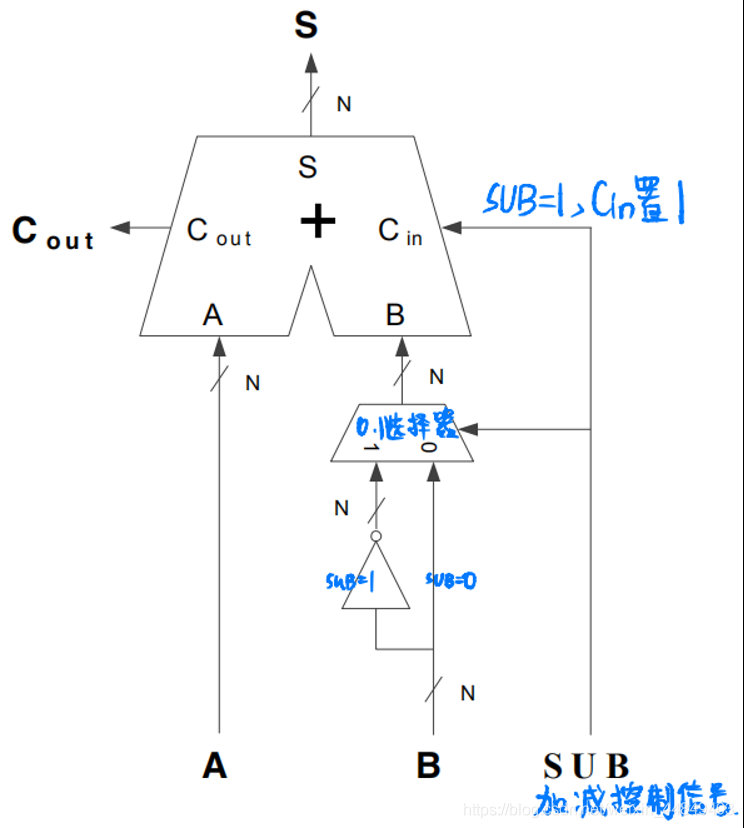
- [A]补- [B]补 = [A-B]补= [A]补 + [-B]补 ([-B]补 的计算:[B]补 “取反加1”)
- 只要在B的输入端对B进行取反并置进位为
(2)加入减法的运算器逻辑框图:
(3)溢出判断:
1)加法:A和B的符号位相同, 但结果的符号位与A和B的符号位不同, 即正数相加得负或负数相加得正
o
v
=
s
31
∗
a
31
∗
b
31
‾
+
s
31
‾
∗
a
31
∗
b
31
ov=s31*a31*\overline{b31}+\overline{s31}*a31*b31
ov=s31∗a31∗b31+s31∗a31∗b31 // s31:结果的最高位(结果符号位)
2)减法:正数减负数结果为负数或负数减正数结果为正数
o
v
=
s
31
∗
a
31
‾
∗
b
31
+
s
31
‾
∗
a
31
∗
b
31
‾
ov=s31*\overline{a31}*b31+\overline{s31}*a31*\overline{b31}
ov=s31∗a31∗b31+s31∗a31∗b31
3)运算器溢出条件:
o
v
=
A
D
D
∗
(
s
31
∗
a
31
‾
∗
b
31
‾
+
s
31
‾
∗
a
31
∗
b
31
)
+
S
U
B
∗
(
s
31
∗
a
31
‾
∗
b
31
+
s
31
‾
∗
a
31
∗
b
31
‾
)
ov=ADD*(s31*\overline{a31}*\overline{b31}+\overline{s31}*a31*b31)+SUB*(s31*\overline{a31}*b31+\overline{s31}*a31*\overline{b31})
ov=ADD∗(s31∗a31∗b31+s31∗a31∗b31)+SUB∗(s31∗a31∗b31+s31∗a31∗b31)
定点ALU设计
ALU的实现
- ALU表示算术逻辑单元:
- 实现加减法器
- 实现逻辑运算(a&b, a|b, a xor b在加法器中产生)
- 实现比较器(相等、大小)
- 实现移位器 - 最后,根据操作类型,从多个结果中选择;
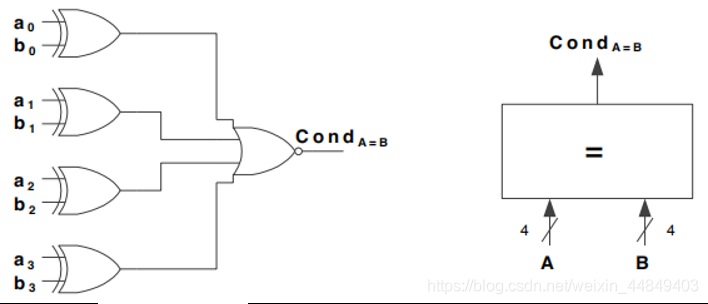
判断相等
- 判断多bit的A信号和B信号是否相等:A0-n == B0-n :
• 使用异或逻辑逐bit的判断(A0^B0 , A1^B1 , … , An^Bn) - 每个bit结果,有任何一个为1,则输出为0 :
• 多输入或非门,位数多时需要多级逻辑
判断大小
- 使用A-B来判断大小:A-B > 0 (结果符号位为0)则代表A大于B
- 小心溢出:
- 减法没有溢出时:结果符号位为1,则A<B;
- 减法有溢出时:结果符号位为0,则A<B;
▫ 正-负=正,若结果为负,则溢出;
▫ 负-正=负,若结果为正,则溢出; - C o n d A < B = O v ‾ Cond_{A<B} =\overline{Ov} CondA<B=Ov & s 63 s63 s63 | O v Ov Ov & s 63 ‾ \overline{s63} s63 = a 63 a63 a63 & s 63 s63 s63 | b 63 ‾ \overline{b63} b63 & s 63 s63 s63 | a 63 a63 a63 & b 63 ‾ \overline{b63} b63
移位操作
(1)移位操作:同时也是乘以/除以 2的幂次的运算
• 逻辑左移 (低位补0)
• 逻辑右移 (高位补0)
• 算数右移 (高位补符号位)
• 循环右移 (高位补右侧挤掉的数据)
(2)硬件实现:
- 对于移N位数的移位操作,使用N选1来实现:
• 根据要移动的位数,从N个输入中选一个
• 每个输入将输入移动特定位数,不需要延迟和逻辑 - 每种移位结果再根据移位操作类型选择

补码乘法器设计
补码乘法原理
(1)[X]补+[Y]补=[X+Y]补, 但[X]补*[Y]补!=[X*Y]补;
(2)问题: 已知[X]补和[Y]补, 求[X*Y]补.

(红色位置,方括号外的加法为补码加法,需对加数进行符号位的扩充)
- 在推导中, [X ]补符号位扩充到64位;
- 其中:[x∗2^k ]_补=[x]_补 〖∗2〗^k
补码乘法算法
(1)计算原则:
- [ X ∗ Y ] 补 = [ X ] 补 ∗ ( − y 31 ∗ 2 31 + y 30 ∗ 2 30 + … + y 1 ∗ 2 1 + y 0 ∗ 2 0 ) [X∗Y]_补=[X]_补∗(−y_{31}∗2^{31}+y_{30}∗2^{30}+…+y_1∗2^1+y_0∗2^0) [X∗Y]补=[X]补∗(−y31∗231+y30∗230+…+y1∗21+y0∗20)
- 与普通乘法类似,只是符号位乘项要变加为减;
符号位的特殊性增加了电路复杂度:
- 对y的最高位乘积项做减法,对其他乘积项做加法;
- 扩充符号位,对齐乘积项;

(2)Booth算法:
1)变换:
(
−
y
31
∗
2
31
+
y
30
∗
2
30
+
…
+
y
1
∗
2
1
+
y
0
∗
2
0
)
=
(
y
30
−
y
31
)
∗
2
31
+
(
y
29
−
y
30
)
∗
2
30
+
…
+
(
y
0
−
y
1
)
∗
2
1
+
(
y
−
1
−
y
0
)
∗
2
0
(−y_{31}∗2^{31}+y_{30}∗2^{30}+…+y_1∗2^1+y_0∗2^0 )=(y_{30}−y_{31} )∗2^{31}+(y_{29}−y_{30})∗2^{30}+…+(y_0−y_1)∗2^1+(y_{−1}−y_0)∗2^0
(−y31∗231+y30∗230+…+y1∗21+y0∗20)=(y30−y31)∗231+(y29−y30)∗230+…+(y0−y1)∗21+(y−1−y0)∗20
2)每一项都一样, 每次看两位:
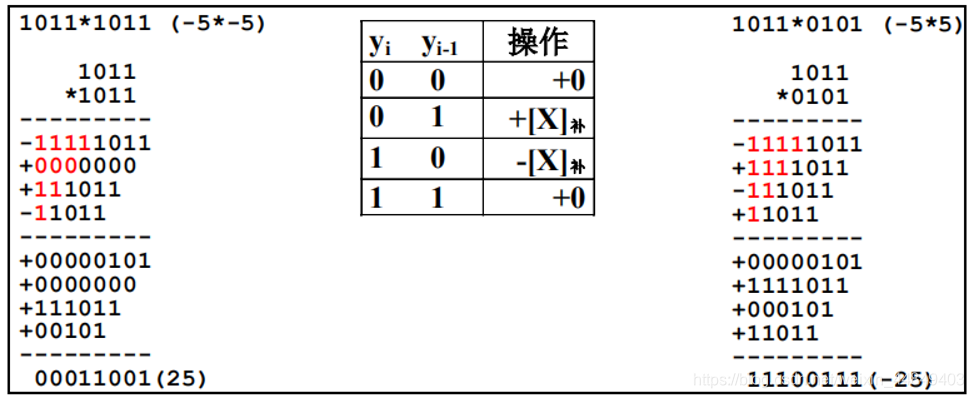
(3)Booth二位一乘算法:
1)变换:
(
−
y
31
∗
2
31
+
y
30
∗
2
30
+
…
+
y
1
∗
2
1
+
y
0
∗
2
0
)
=
(
y
29
+
y
30
−
2
∗
y
31
)
∗
2
30
+
(
y
27
+
y
28
−
2
∗
y
29
)
∗
2
28
+
…
+
(
y
1
+
y
2
−
2
∗
y
3
)
∗
2
2
+
(
y
−
1
+
y
0
−
2
∗
y
1
)
∗
2
0
(−y_{31}∗2^{31}+y_{30}∗2^{30}+…+y_1∗2^1+y_0∗2^0 )=(y_{29} +y_{30}−2∗y_{31} )∗2^{30}+(y_{27} +y_{28}−2∗y_{29} )∗2^{28}+…+(y_1 +y_2−2∗y_3 )∗2^2+(y_{−1}+y_0−2∗y_1 )∗2^0
(−y31∗231+y30∗230+…+y1∗21+y0∗20)=(y29+y30−2∗y31)∗230+(y27+y28−2∗y29)∗228+…+(y1+y2−2∗y3)∗22+(y−1+y0−2∗y1)∗20
//注意,只有偶数项:
2
0
,
2
2
,
…
,
2
28
,
2
30
2^0,2^2,…,2^{28},2^{30}
20,22,…,228,230
2)每一项都一样,每次看三位,只要16项相加:
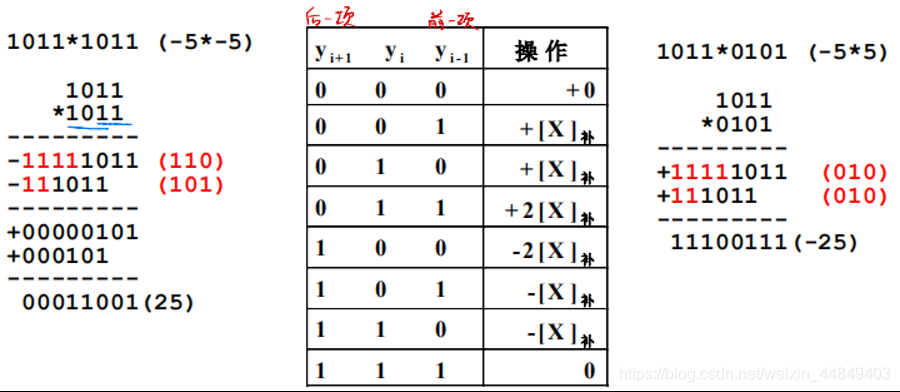
3)优势:

- 循环次数降低一倍
- 每次循环算法一样
- [X]补只有移1位和补码加减运算(两位一乘但不用乘3)
(4)Booth算法的串行实现:
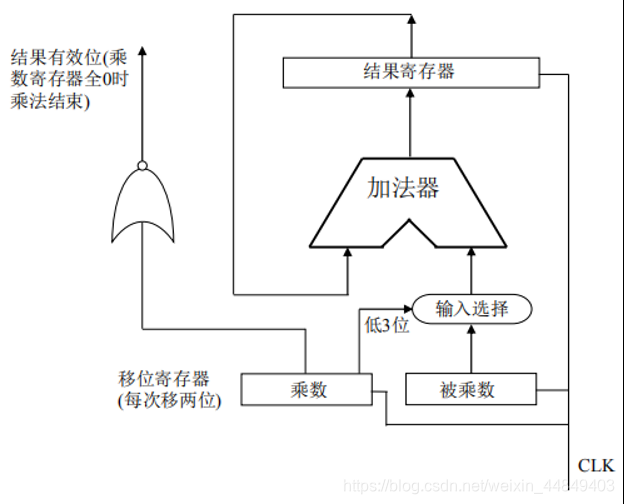
- 以二位一乘为例,32位定点乘法需要把16个数相加;
- 可以用一个加法器加15次,需要15个时钟周期;
(5)Booth二位乘的输入选择逻辑:
1)其中1位:
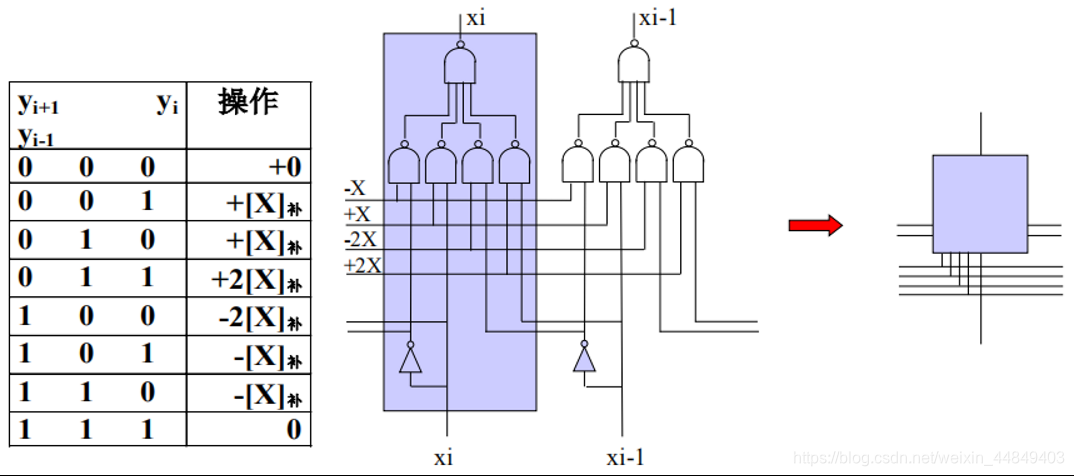
这里:
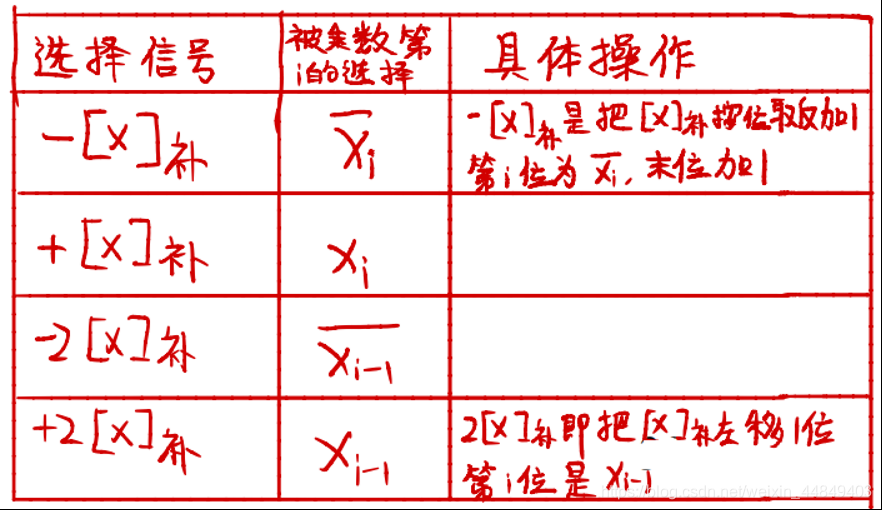
2)一组所有位:

(6)华莱士Wallace加法树:
1)来源问题:
- 串行把16个数相加, 需要15次加法时间;
- 用15个加法器组织成树状, 需要4次加法时间, 又浪费硬件;
2)Wallace树基本思想:
- n个全加器每次把三个n位的数相加转换成两个数(n+1位)相加;
- 因此, n个全加器每次可以把m个n位的数相加转换成2m/3个数相加, 再用一层全加器转换成4m/9个数相加, 直到转换成2个数; 再用加法器把最后两个数相加
3)全加器:
- 原理:
▫ 三个输入,两个输出;
▫ 进位输出在下一级相加时连到下一位;
▫ 两级门延迟;
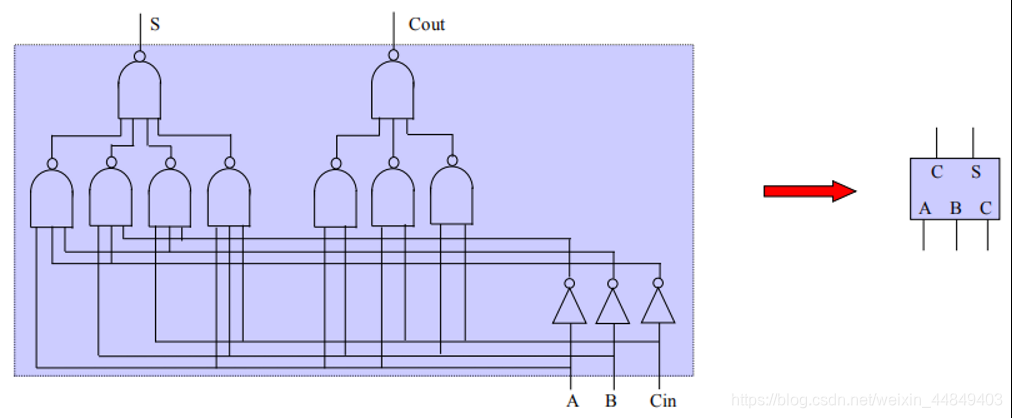
- 全加器把三个加数变成两个加数:
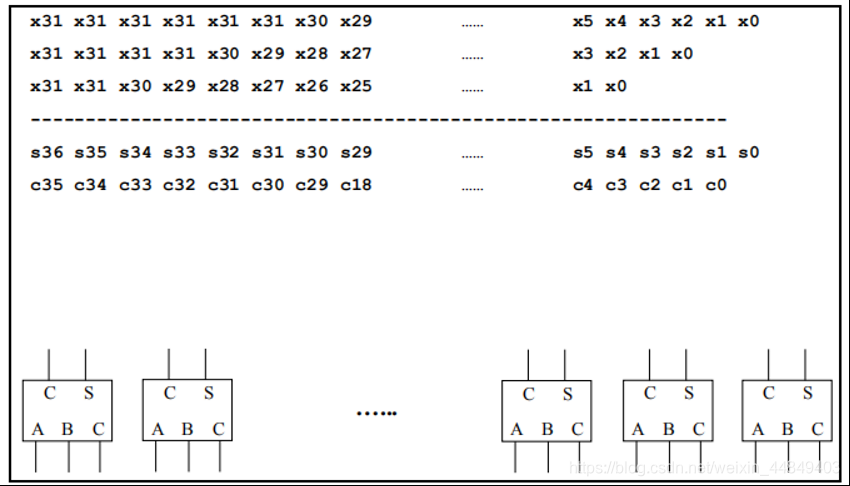
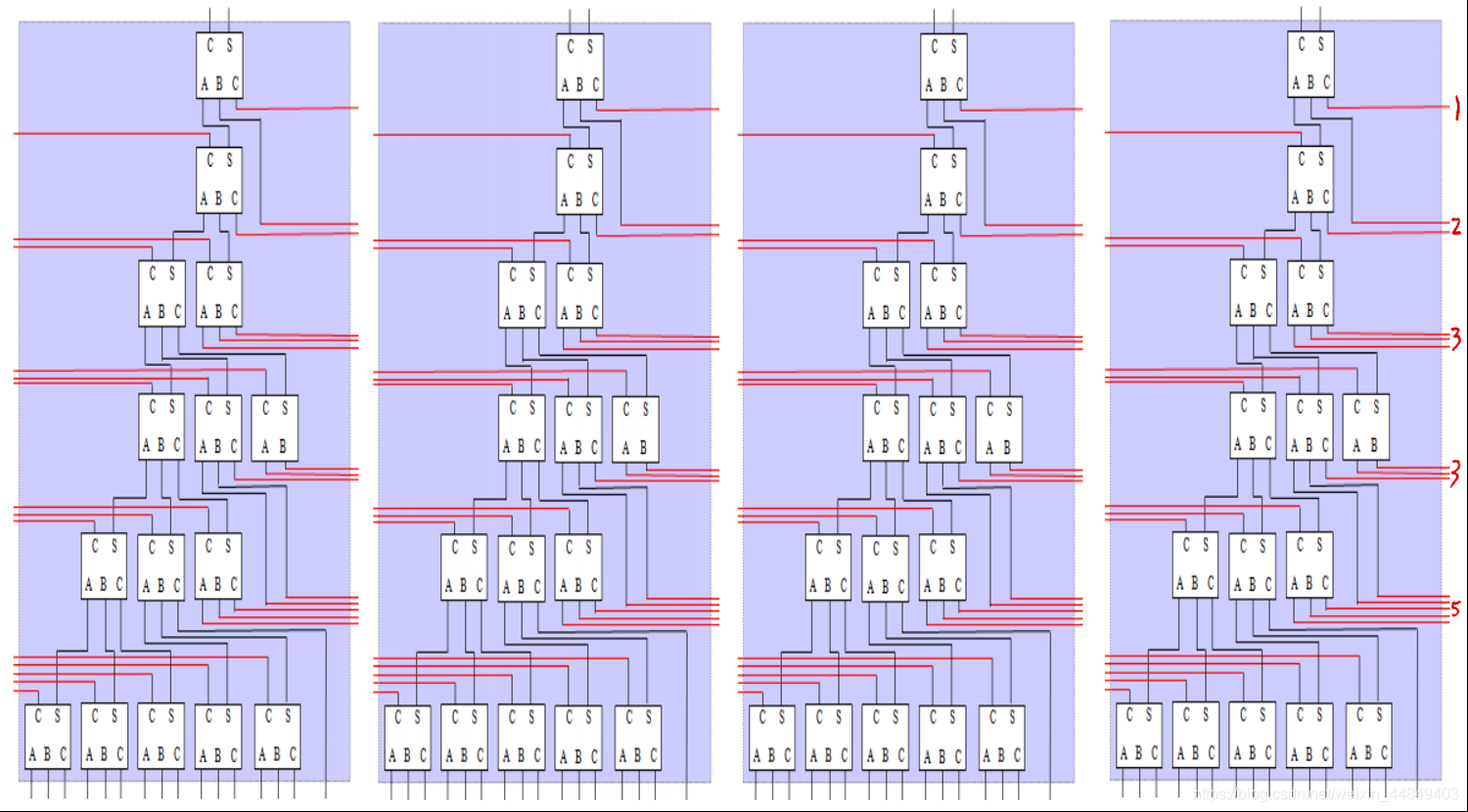
4)16个数相加的1位加法树:(16个数的某一位)
全加器的进位生成部分连接到下一级时要连接到下一级的高位;
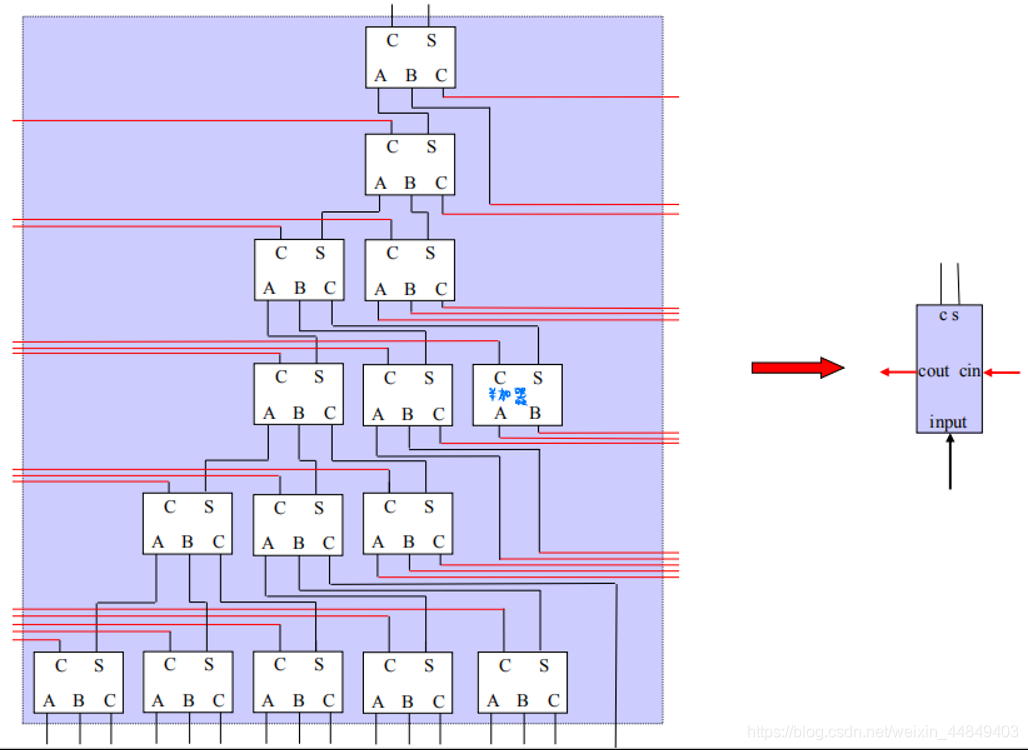
5)16个数相加的四位华莱士树(左右进位相连):
(7)32*32补码乘法器框图:
1)逻辑框图:
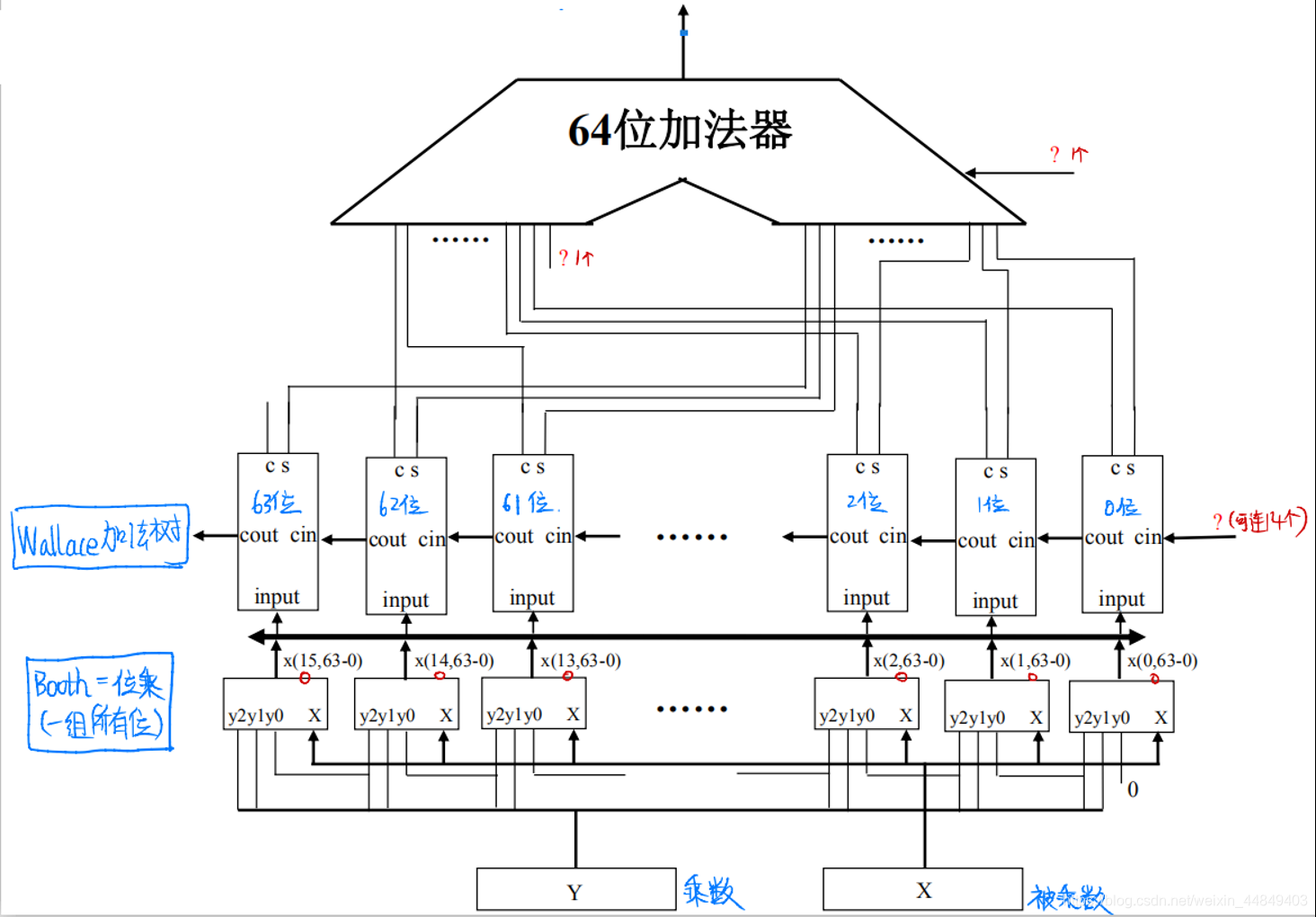
- “?”标志是连接16个“末位加1”信号的地方;
- “ 0 ”部分是可能产生的16个“末位加1”信号的地方;
2)注意问题:
采用Booth编码和Wallace树的乘法器经常需要累加[-X]补和[-2X]补。而[-X]补和[-2X]补涉及到取反加1的操作。这里是如何避免这些单独加1的?
①其中有14个连到华莱士树第0位加法树的进位输入;
②剩下两个连到加法器的进位输入端以及其中一个输入端的最低位;
(“其中一个输入端的最低位”:华莱士树形成的最后两个数据中有一个是通过华莱士树最后一级全加器的进位端形成的,需要左移一位与另外一个数相加,这里说的即是:左移后空出来一个最低位)
3)说明:
①32位的[X]补, [-X]补,[2X]补 ,[-2X]补 如何扩展到64位?
- [X]补 : 左边符号位扩充, 右边补0
- [-X]补: 对[X]补按位求反, 左边符号位扩充, 右边补1, 末位加1
②硬件优化:
- 低位“0”不用加
- 高位符号位扩充位可以优化
- 请查阅相关资料














 6472
6472











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









