







单一文件操作
Pandas库介绍
1.基于Numpy数据分析包
2.用于数据挖掘和数据分析,同时也提供数据清洗功能
使用时先导入:import pandas as pd
两大数据结构:Series,DataFrame
3.Series :带索引的一维数组
带标签的一维数组,轴标签统称为索引。可存储整数、浮点数、字符串等类型
pd.Series([1,”apple”,3.5,4]) #默认索引为1,2,3,4 隐式索引
pd.Series([1,”apple”,3.5,4],index = [‘a’,’b’,’c’,’d’,]) #索引为a,b,c,d 自定义索引
4.DataFrame(可采用字典)
既有行索引又有列索引,可看成由多个series组成的数据结构,存整数、浮点数、字符串等数据
pd.DataFrame({‘Animal’:[‘Dog’,’Cat’,’Bear’]
‘Owner’:[‘Alice’,’Bob’,’Cathy’]
})
5.读文件pd.read_xx(),写文件data.to_xx()
文本文件的读写
1.绝对路径
使用\ : \ :‘C:\Users\test.txt’
添加r:r’C:\Users\test.txt’
直接用/: ‘C:/Users/test.txt’
相对路径
.:当前目录
…:上级目录 需要import os
可用os.getcwd()查看当前工作路径
盘符后需加冒号
2.txt文件与csv文件都是文本文件
txt文件 csv文件(默认excel打开)
Text File,记事本文件 Comma separated values,逗号分隔值文件
对于分隔符无明确要求 字段间有逗号隔开
-逗号、制表符、空格等多种符号 -逗号分隔的txt文件
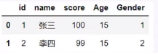
Id name score id,name,score
1 张三 100 1,张三,100
2 李四 99 2,李四,99
3 王五 98 3,王五,98
3.文本文件文件的读取
全部读取:
txt文件 Import pandas as pd
data = pd.read_csv(‘E:\sample.txt’,sep =’txt所使用的的分隔符’)
csv文件 import pandas as pd
data = pd.read_csv(‘E:\saple.csv’)
注意:sep:如果不指定参数,Python则会使用逗号分隔;
如果数据第一行不是列名,则采用:data = pd.read_csv(file,header = None)
部分读取:
读入指定列的文本文件 import pandas as pd
data = pd.read_csv(‘E:\sample.csv’,usecols = [‘id’,‘Age’])
等同usecols = [1,3],读取2列和4列数据 列索引从0开始
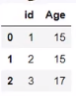
读入前面n行的文本文件 import pandas as pd
data = pd.read_csv(‘E:\sample.csv’,nrows = 2)
pd.read_csv(filepath,skiprows = 2)从文件的第三行开始读取数据(跳过包含列名在内的前2行)
3.文本文件写入
覆盖写入已有文件
Import pandas as pd
Data.to_csv(‘E:\sample.csv’,index = False)
index = False:行索引不写入文件
数据中如果有中文,添加encoding = ‘utf_8_sig’ ubk
data.to_csv(‘E:\new.csv’) #路径下会出现new.txt文件,与sample文件内容同,且带有索引可用index = False
在已有文件后追加写入
Import pandas as pd
Data.to_csv(‘E:\sample.csv’,mode = ‘a’,head = False)
#mode = ‘a’:append mode 如果指定文件已存在,则在指定文件后追加写入;如果指定文件不存在,则创建该文件然后写入
header = false:不重复写入列名
Excel文件的读写
xls文件、xlsx文件
1.读取
单一sheet文件读取
Import pandas as pd
Data = pd.read_excel(‘E:\sample.xlsx’)
多个sheet文件读取
import pandas as pd
data = pd.read_excel(‘E:\sample.xlsx’,sheet_name = ‘sheet_2’)
Read_excel()函数能够读取Excel2003(.xls)和xcel2007(.xlsx)两个类型的文件
不指定sheet_name时默认读取第一张表的数据
读取指定列数据时使用usecols,
eg:col_list = [‘id’,’Age’]或col_list = [1,3] #声明列行
Data = pd.read_excel(excel_file,usecols = col_list)
2.写入
写入单一sheet
Import pandas as pd
Data.to_excel(‘E:\sample.xlsx’,sheet_name = ‘sheet1’,index = False)
同时写入多个sheet
import pandas as pd
writefile = r‘E:\sample.xlsx’ #路径
with pd.ExcelWriter(writefile) as writer: #创建类型并赋值给write
data.to_excel(writer,sheet_name = ‘sheet1’,index = False)
data.to_excel(writer,sheet_name = ‘sheet1’,index = False)
# writefile:需要写入的文件路径
data:类型为datafrae的数据
sheet_name:需要写入的sheet名
index=False:写入时不写入行索引
数据分析文件的读取
sas文件、spss文件(使用之前依赖库conda install -c conda-forge pyreadstat)
1.读取(有点问题没有读取出来可能与安装路径有关系)
sas文件读取
import pandas as pd
Data = pd.read_sas(‘E:\sample.sas7bdat’)
spss文件读取
import pandas as pd
data = pd.read_spss(‘E:\sample.sav’)

###############
#####pandas####
###############
#import pandas
#print(pandas.Series([1,2,3]))
import pandas as pd
print(pd.Series([1,2,3]))
###################1.Series和DataFrame#####################
#####Series###
#隐式索引
series = ['Apple',2,'Book',3]
s1 = pd.Series(series)
print(s1)
#自定义索引
index_name = ['a','b','c','d']
s2 = pd.Series(series,index_name)
print(s2)
######DataFrame###
#隐式索引
dic = {'Animal':['Dog','Cat','Bear'],
'Owerner':['Alice','Bob','Cathy']}
df1 = pd.DataFrame(dic)
print(df1)
#自定义索引
index_name2 = ['a','b','c']
df2 = pd.DataFrame(dic,index_name2)
print(df2)
####################2.txt文件和csv文件################
#绝对路径 电脑shift键加鼠标右键有一个‘复制为路径’选项
#r或者\ 不转义
r"D:\.spyder-py3\signal\txt_sample.txt" #绝对路径
"D:\\.spyder-py3\\signal\\txt_sample.txt"
#相对路径 os.getcwd()获取相对路径
import os
print(os.getcwd())
#txt文件读取
print('txt文件读取')
txt = pd.read_csv('./signal/txt_sample.txt',sep = ' ')#相对
print(txt)
txt1 = pd.read_csv(r"D:\\.spyder-py3\\signal\\txt_sample.txt",sep = ' ')
print(txt1)
#csv文件读取
print('csv文件的读取')
cv = pd.read_csv('./signal/excel_sample.csv',encoding = 'gbk')
print(cv)
#txt文件的写入
txt.to_csv('./signal/write_txt_sample.txt',index = False,sep = ' ')
#csv文件的写入
cv.to_csv('./signal/write_excel_sample.csv',index = False,encoding = 'gbk')
#读入指定列的文本文件
cv = pd.read_csv('./signal/write_excel_sample.csv',usecols = ['Name','Age'],encoding = 'gbk')
print(cv)
#读入前几行
cv = pd.read_csv('./signal/write_excel_sample.csv',nrows = 2,encoding = 'gbk')
###############3.Excel文件的读写##############################
#单一文件的读取
print('Excel文件的读取')
print('单一文件')
excel = pd.read_excel('./signal/excel.xlsx')
print(excel)
#多个文件的读取
excel1 = pd.read_excel('./signal/excel.xlsx',sheet_name = 'Sheet2')
print(excel1)
#读取列
excel2 = pd.read_excel('./signal/excel.xlsx',usecols = [0,1])
print(excel2)
#写入单一
excel.to_excel('./signal/write_excel.xlsx',index = False)
#写入多张
path = r"D:\.spyder-py3\signal\write_excel.xlsx"
with pd.ExcelWriter(path) as writer:
excel.to_excel(writer,sheet_name = 'Sheet1',index = False)
excel.to_excel(writer,sheet_name = 'Sheet2',index = False)
##########4.数据分析文件###################
#sav文件 #未能读取出来,可能与安装路径有关系
#data4 =pd.read_sas(r"D:\.spyder-py3\sas_sample.sas7bdat")
#print(data4)
data3 = pd.read_spss(r'D:\.spyder-py3\signal\spss_sample.sav')
print(data3)















 8万+
8万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









