







1.概述
JobManager 是 Flink 集群的主节点,它包含三大重要的组件:
- ResourceManager
- Flink集群的资源管理器,负责slot的管理和申请工作。
- Dispatcher
- 负责接收客户端提交的 JobGraph,随后启动一个Jobmanager,类似 Yarn中的ApplicationMaster角色,类似Spark中的Driver角色。
- JobManager
- 负责一个具体job的执行,在Flink集群中,可能会有多个JobManager 同时执行,job的主控程序
- WebmonitorEndpoint
- 该类型中维护了很多的Handler,如果客户端通过flink run 的方式提交flink提交一个job到flink集群,最后都是由WebmonitorEndpoint来接收,并决定使用哪个handler进行处理(SubmitJobHandler)。
总而言之:Flink集群的主节点内部运行着 ResourceManager 和 Dispatcher 对象,当客户端提交一个job到Flink集群运行时(客户端会将job先构建为JobGraph对象 StreamGraph–>JobGraph),Dsipatcher 负责启动JobManager对象,该对象负责对应job 内部的Task执行以及向ResourceManager申请运行该Task所需要的资源。
2.JobManager启动
2.1 StandaloneSessionClusterEntrypoint(解析+启动)
根据Flink集群主节点启动脚本分析可知,StandAloneSessionClusterEntrypoint 是 JobManager 的启动主类。
Flink集群主节点启动做了两件事情:① 解析参数以及配置文件 ② 启动相关的服务。
/*
* 注释: flink有三种方式执行应用程序:session mode, per-job mode, applocation mode
* 模型的区别主要包含:
* 1. 集群生命周期和资源隔离保证
* 2. 应用程序的main()方法是在客户端执行还是在集群执行
*/
/**
* Entry point for the standalone session cluster.
*/
public class StandaloneSessionClusterEntrypoint extends SessionClusterEntrypoint {
public StandaloneSessionClusterEntrypoint(Configuration configuration) {
super(configuration);
}
@Override
protected DefaultDispatcherResourceManagerComponentFactory createDispatcherResourceManagerComponentFactory(Configuration configuration) {
/*************************************************
* 注释:
* 1、参数是:StandaloneResourceManagerFactory 实例
* 2、返回值:DefaultDispatcherResourceManagerComponentFactory 实例
*/
return DefaultDispatcherResourceManagerComponentFactory
.createSessionComponentFactory(StandaloneResourceManagerFactory.getInstance());
}
/*************************************************
*
* 注释: 入口
*/
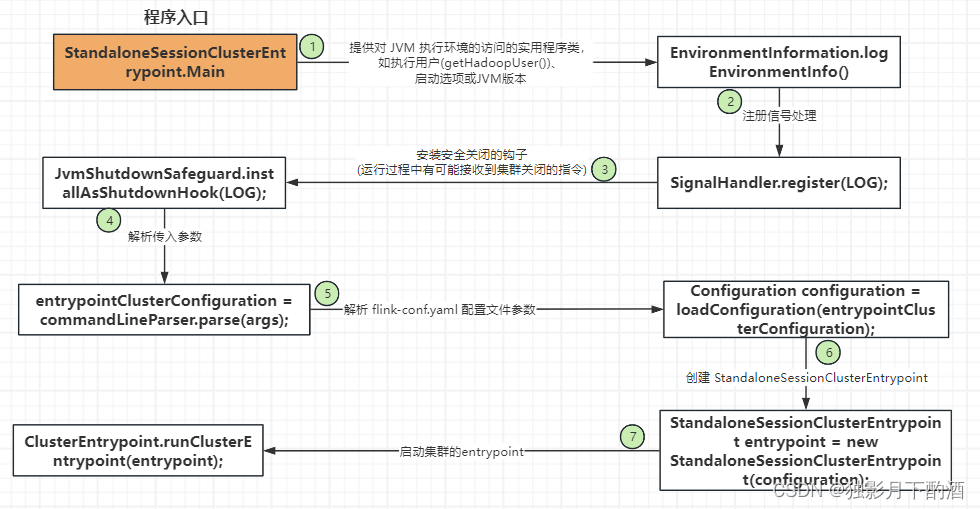
public static void main(String[] args) {
// 注释:提供对 JVM 执行环境的访问的实用程序类,如执行用户(getHadoopUser())、启动选项或JVM版本。
// startup checks and logging
EnvironmentInformation.logEnvironmentInfo(LOG, StandaloneSessionClusterEntrypoint.class.getSimpleName(), args);
// 注释:注册信号处理
SignalHandler.register(LOG);
// 注释: 安装安全关闭的钩子(保证Flink集群关闭或者宕机后关闭对应的服务)
// 注释: Flink集群启动过程中或者在启动好了之后的运行中,都有可能接收到关闭集群的命令
JvmShutdownSafeguard.installAsShutdownHook(LOG);
EntrypointClusterConfiguration entrypointClusterConfiguration = null;
final CommandLineParser<EntrypointClusterConfiguration> commandLineParser = new CommandLineParser<>(
new EntrypointClusterConfigurationParserFactory());
try {
/*************************************************
* 注释: 解析传入的参数
* 内部通过 EntrypointClusterConfigurationParserFactory 解析配置文件,
* 返回 EntrypointClusterConfiguration 为 ClusterConfiguration 的子类
*/
entrypointClusterConfiguration = commandLineParser.parse(args);
} catch(FlinkParseException e) {
LOG.error("Could not parse command line arguments {}.", args, e); commandLineParser.printHelp(StandaloneSessionClusterEntrypoint.class.getSimpleName());
System.exit(1);
}
/*************************************************
* 注释:解析 flink 的配置文件: fink-conf.ymal
*/
Configuration configuration = loadConfiguration(entrypointClusterConfiguration);
/*************************************************
* 注释:创建 StandaloneSessionClusterEntrypoint对象,调用父类的构造方法
*/
StandaloneSessionClusterEntrypoint entrypoint = new StandaloneSessionClusterEntrypoint(configuration);
/*************************************************
* 注释:启动集群的entrypoint
* 方法接收的是父类 ClusterEntrypoint,可想而知:其他几种启动方式也通过该方法。
*/
ClusterEntrypoint.runClusterEntrypoint(entrypoint);
}
}
上述代码图解:
2.2 ClusterEntrypoint.runClusterEntrypoint(启动主节点)
public static void runClusterEntrypoint(ClusterEntrypoint clusterEntrypoint) {
final String clusterEntrypointName = clusterEntrypoint.getClass().getSimpleName();
try {
// 注释: 启动 Flink 主节点: JobManager
clusterEntrypoint.startCluster();
} catch(ClusterEntrypointException e) {
LOG.error(String.format("Could not start cluster entrypoint %s.", clusterEntrypointName), e);
System.exit(STARTUP_FAILURE_RETURN_CODE);
}
// 注释: 获取结果(启动完成)
clusterEntrypoint.getTerminationFuture().whenComplete((applicationStatus, throwable) -> {
final int returnCode;
if(throwable != null) {
returnCode = RUNTIME_FAILURE_RETURN_CODE;
} else {
returnCode = applicationStatus.processExitCode();
}
LOG.info("Terminating cluster entrypoint process {} with exit code {}.", clusterEntrypointName, returnCode, throwable);
System.exit(returnCode);
});
}
2.3 clusterEntrypoint.startCluster(启动主节点detail)
- 1.注册了一些插件,这些插件使用单独的类加载器加载
- 2.根据配置信息初始化了文件系统
public void startCluster() throws ClusterEntrypointException {
LOG.info("Starting {}.", getClass().getSimpleName());
try {
replaceGracefulExitWithHaltIfConfigured(configuration);
/*************************************************
* 注释: PluginManager 是新版支持提供通用的插件机制
* 负责管理集群插件,这些插件是使用单独的类加载器加载的,以便它们的依赖关系,不要干扰 Flink 的依赖关系。
*/
PluginManager pluginManager = PluginUtils.createPluginManagerFromRootFolder(configuration);
/*************************************************
* 注释: 根据配置初始化文件系统
* 三种东西;
* 1、本地 Local 客户端的时候会用 JobGragh ===> JobGraghFile
* 2、HDFS FileSytem(DistributedFileSystem)
* 3、封装对象 HadoopFileSystem, 里面包装了 HDFS 的 FileSYSTEM 实例对象
*/
configureFileSystems(configuration, pluginManager);
//注释:配置安全相关配置:securityContext = NoOpSecurityContext
SecurityContext securityContext = installSecurityContext(configuration);
// 注释: 通过一个线程来运行
securityContext.runSecured((Callable<Void>) () -> {
/*************************************************
* 注释: 集群启动入口
*/
runCluster(configuration, pluginManager);
return null;
});
} catch(Throwable t) {
final Throwable strippedThrowable = ExceptionUtils.stripException(t, UndeclaredThrowableException.class);
try {
// clean up any partial state
shutDownAsync(ApplicationStatus.FAILED, ExceptionUtils.stringifyException(strippedThrowable), false)
.get(INITIALIZATION_SHUTDOWN_TIMEOUT.toMilliseconds(), TimeUnit.MILLISECONDS);
} catch(InterruptedException | ExecutionException | TimeoutException e) {
strippedThrowable.addSuppressed(e);
}
throw new ClusterEntrypointException(String.format("Failed to initialize the cluster entrypoint %s.", getClass().getSimpleName()),
strippedThrowable);
}
}
2.4 runCluster(初始化+实例化)
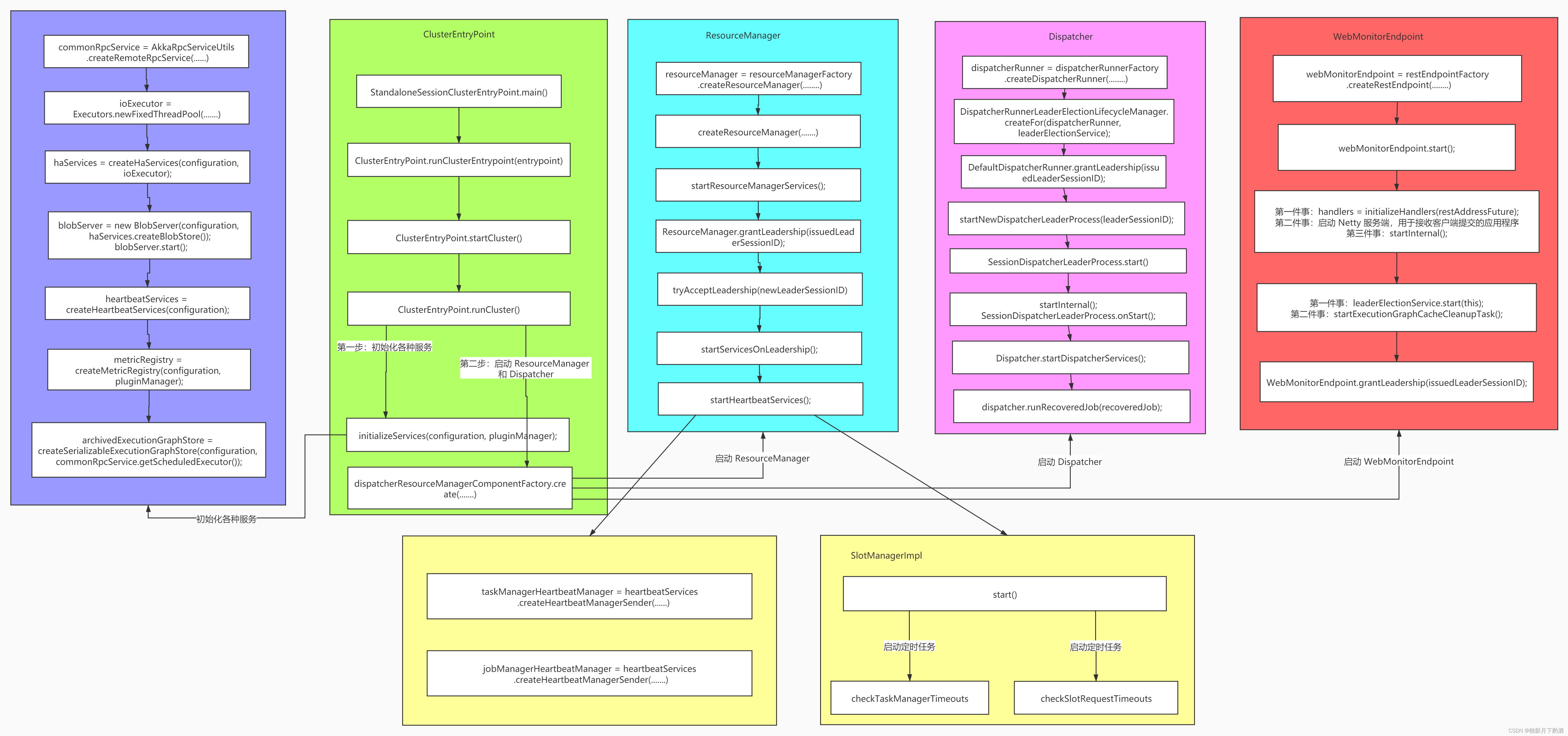
通过runCluster(configuration, pluginManager)方法启动集群,在该方法中做了两件事情:
- initializeServices() 初始化相关服务(RpcService/haServices/blobServer/heartbeatServices/metricRegistry/archivedExecutionGraphStore)
- dispatcherResourceManagerComponentFactory.create() 启动 Dispatcher 和 ResourceManager 服务。
- dispatcherResourceManagerComponentFactory内部有三个成员变量:dispatcherRunnerFactory、resourceManagerFactory、restEndpointFactory
private void runCluster(Configuration configuration, PluginManager pluginManager) throws Exception {
synchronized(lock) {
/*** 注释: 初始化服务,如 JobManager 的 Akka RPC 服务,HA 服务,心跳检查服务等 Master 节点需要使用到的服务
* 1、commonRpcService: 基于 Akka 的 RpcService 实现。RPC 服务启动 Akka 参与者来接收从 RpcGateway 调用 RPC
* 2、haServices: 提供对高可用性所需的所有服务的访问注册,分布式计数器和领导人选举
* 3、blobServer: 负责监听传入的请求生成线程来处理这些请求。还负责创建要存储的目录结构blob 或临时缓存它们。
* 4、heartbeatServices:提供心跳所需的所有服务。包括创建心跳接收器和心跳发送者。
* 5、metricRegistry: 跟踪所有已注册的 Metric,它作为连接 MetricGroup 和 MetricReporter
* 6、archivedExecutionGraphStore: 存储执行图ExecutionGraph的可序列化形式。
*/
initializeServices(configuration, pluginManager);
// 注释: 将 jobmanager 地址写入配置
// write host information into configuration
configuration.setString(JobManagerOptions.ADDRESS, commonRpcService.getAddress());
configuration.setInteger(JobManagerOptions.PORT, commonRpcService.getPort());
/*************************************************
* 注释: 初始化一个 DefaultDispatcherResourceManagerComponentFactory 工厂实例
* 内部初始化了四大工厂实例
* 1、DispatcherRunnerFactory = DefaultDispatcherRunnerFactory
* 2、ResourceManagerFactory = StandaloneResourceManagerFactory
* 3、RestEndpointFactory(WebMonitorEndpoint的工厂) = SessionRestEndpointFactory
* 返回值:DefaultDispatcherResourceManagerComponentFactory
* 内部包含了这三个工厂实例,即三个成员变量
* 再补充一个:dispatcherLeaderProcessFactoryFactory = SessionDispatcherLeaderProcessFactoryFactory
*/
final DispatcherResourceManagerComponentFactory dispatcherResourceManagerComponentFactory =
createDispatcherResourceManagerComponentFactory(configuration);
/*************************************************
* 注释:启动关键组件:Dispatcher 和 ResourceManager。
* 1、Dispatcher: 负责接收客户端提交的作业,持久化它们,生成要执行的作业管理器任务,并在主任务失败时恢复它们。此外, 它知道关于 Flink 会话集群的状态。负责为新提交的作业启动新的 JobManager服务
* 2、ResourceManager: 负责资源的调度。在整个 Flink 集群中只有一个 ResourceManager,资源相关的内容都由这个服务负责 registerJobManager(JobMasterId, ResourceID, String, JobID, Time) 负责注册 jobmaster,requestSlot(JobMasterId, SlotRequest, Time) 从资源管理器请求一个槽
* 3、WebMonitorEndpoint: 服务于 web 前端 Rest 调用的 Rest 端点,用于接收客户端发送的执行任务的请求
*/
clusterComponent = dispatcherResourceManagerComponentFactory
.create(configuration,
ioExecutor,
commonRpcService,
haServices,
blobServer,
heartbeatServices,
metricRegistry,
archivedExecutionGraphStore,
new RpcMetricQueryServiceRetriever(metricRegistry.getMetricQueryServiceRpcService()),
this);
/*************************************************
* 注释:集群关闭时的回调
*/
clusterComponent.getShutDownFuture().whenComplete((ApplicationStatus applicationStatus, Throwable throwable) -> {
if(throwable != null) {
shutDownAsync(ApplicationStatus.UNKNOWN, ExceptionUtils.stringifyException(throwable), false);
} else {
// This is the general shutdown path. If a separate more specific shutdown was
// already triggered, this will do nothing
shutDownAsync(applicationStatus, null, true);
}
});
}
}
2.5 initializeServices(实例化detail)
该方法是初始化各种服务,有以下服务:
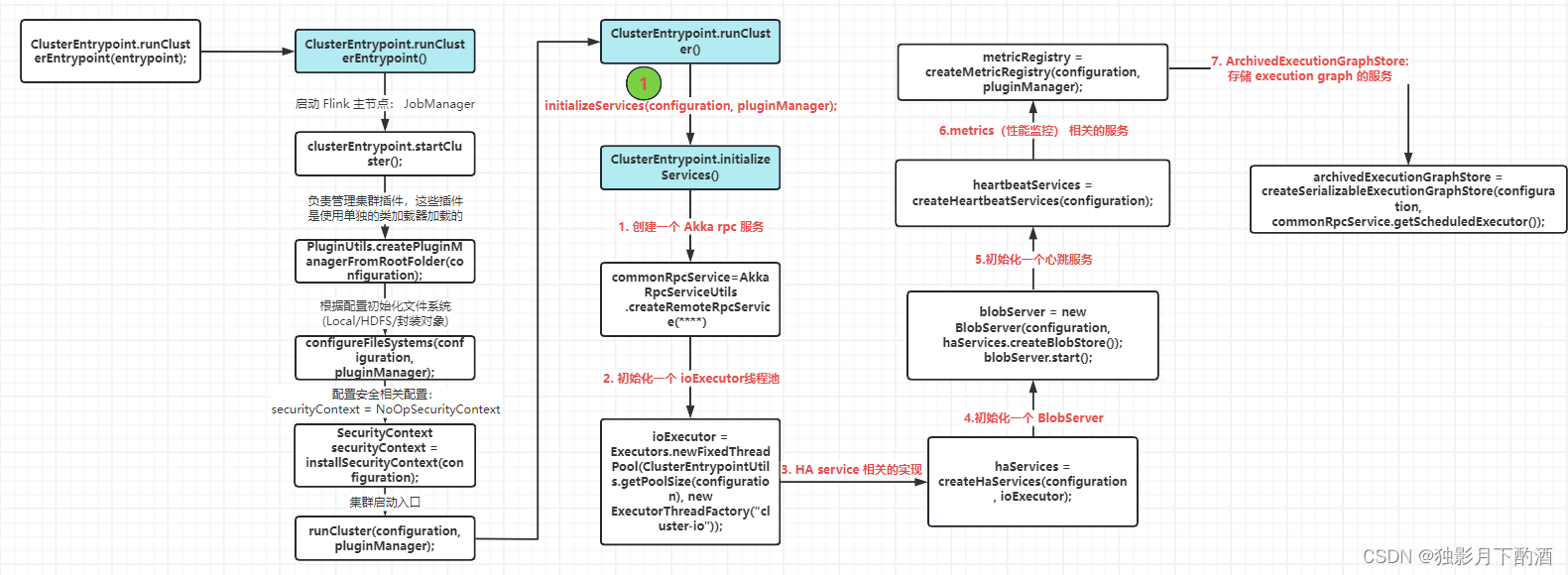
- commonRpcService:
- 该组件启动后,其内部启动一个ActorSystem,当前ActorSystem内部启动一个Actor。
- 该组件是一个基于Akka的ActorSystem,其实就是一个tcp的rpc服务,端口为6123。
- ioExecutor
- 初始化一个专门负责IO的线程池,数量=4*cpu个数,如果当前节点有32个cpu,当前线程池启动的线程数量 =4*32=128个。
- haServices
- HA service 相关的实现,根据用户需求配置不同的HA服务,例如:ZooKeeperHaServices。
- blobServer
- 负责一些大文件的上传,比如用户作业的 jar 包、TM 上传 log 文件等。
- heartbeatServices
- 初始化一个心跳服务,管理主节点上组件的心跳服务。(本质是heartbeatServices对象的基础上创建,实例化对象:heartbeatServicesImpl对象)
- 心跳的关键参数:
- 心跳间隔时间:heartbeat.interval = 10000(10秒)
- 心跳超时时间 heartbeat.timeout = 50000 (50秒)
- metricRegistry
- 初始化一个性能监控服务
- archivedExecutionGraphStore
- 初始化一个存储ExecutionGraph的服务,存储 execution graph 的服务,默认实现有两种:
- MemoryArchivedExecutionGraphStore 主要是在内存中缓存
- FileArchivedExecutionGraphStore 会持久化到文件系统,也会在内存中缓存。
- 初始化一个存储ExecutionGraph的服务,存储 execution graph 的服务,默认实现有两种:
protected void initializeServices(Configuration configuration, PluginManager pluginManager) throws Exception {
LOG.info("Initializing cluster services.");
synchronized(lock) {
/*************************************************
* 创建 Akka rpc 服务 commonRpcService: 基于 Akka 的 RpcService 实现。
* RPC 服务启动 Akka 参与者来接收从 RpcGateway 调用 RPC
* commonRpcService是一个基于 akka 的 actorSystem,其实就是一个 tcp 的 rpc 服务,端口为:6123
* 1、初始化 ActorSystem
* 2、启动 Actor
*/
commonRpcService = AkkaRpcServiceUtils
.createRemoteRpcService(configuration, configuration.getString(JobManagerOptions.ADDRESS), getRPCPortRange(configuration),
configuration.getString(JobManagerOptions.BIND_HOST), configuration.getOptional(JobManagerOptions.RPC_BIND_PORT));
// TODO_MA 注释: 设置 host 和 port
// update the configuration used to create the high availability services
configuration.setString(JobManagerOptions.ADDRESS, commonRpcService.getAddress());
configuration.setInteger(JobManagerOptions.PORT, commonRpcService.getPort());
/*************************************************
* 初始化一个 ioExecutor
* 如果当前节点有32 个 cpu ,那么当前 ioExecutor启动的线程的数量为:128
*/
ioExecutor = Executors.newFixedThreadPool(ClusterEntrypointUtils.getPoolSize(configuration), new ExecutorThreadFactory("cluster-io"));
/*************************************************
* HA service 相关的实现,它的作用有很多,到底使用哪种根据用户的需求来定义
* 比如:处理 ResourceManager 的 leader 选举、JobManager leader 的选举等;
* haServices = ZooKeeperHaServices
*/
haServices = createHaServices(configuration, ioExecutor);
/*************************************************
* 注释: 第四步: 初始化一个 BlobServer
* 主要管理一些大文件的上传等,比如用户作业的 jar 包、TM 上传 log 文件等
* Blob 是指二进制大对象也就是英文 Binary Large Object 的缩写
*/
blobServer = new BlobServer(configuration, haServices.createBlobStore());
blobServer.start();
/*************************************************
* 初始化一个心跳服务
* 在主节点中很多角色都有心跳服务。这些角色的心跳服务,都是在这heartbeatServices 的基础之上创建的。谁需要心跳服务,通过 heartbeatServices 去提供一个实例 HeartBeatImpl,用来完成心跳
*/
heartbeatServices = createHeartbeatServices(configuration);
/*************************************************
* 1、metricQueryServiceRpcService 也是一个 ActorySystem
* 2、用来跟踪所有已注册的Metric
*/
metricRegistry = createMetricRegistry(configuration, pluginManager);
final RpcService metricQueryServiceRpcService = MetricUtils.startRemoteMetricsRpcService(configuration, commonRpcService.getAddress());
metricRegistry.startQueryService(metricQueryServiceRpcService, null);
final String hostname = RpcUtils.getHostname(commonRpcService);
processMetricGroup = MetricUtils
.instantiateProcessMetricGroup(metricRegistry, hostname, ConfigurationUtils.getSystemResourceMetricsProbingInterval(configuration));
/*************************************************
* ArchivedExecutionGraphStore: 存储execution graph的服务, 默认有两种实现,
* 1、MemoryArchivedExecutionGraphStore 主要是在内存中缓存,
* 2、FileArchivedExecutionGraphStore 会持久化到文件系统,也会在内存中缓存。
* 这些服务都会在前面第二步创建 DispatcherResourceManagerComponent 对象时使用到。
* 默认实现是基于 File 的
*/
archivedExecutionGraphStore = createSerializableExecutionGraphStore(configuration, commonRpcService.getScheduledExecutor());
}
}
对于 commonRpcService 服务的流程图解:
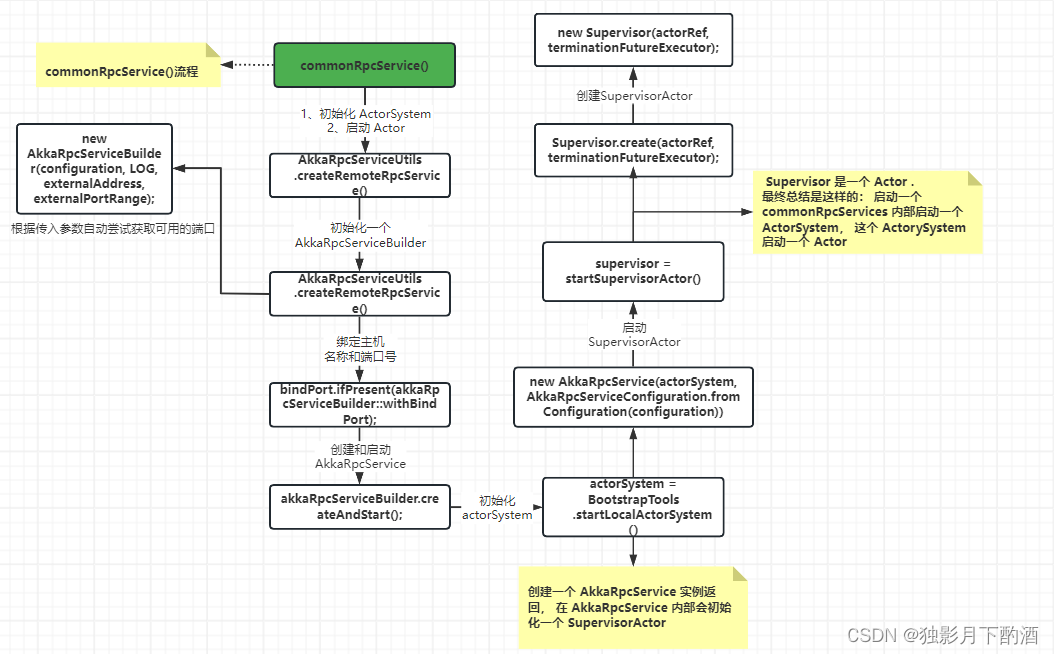
总而言之: 启动 commonRpcService 服务,在其内部启动了一个 ActorSystem,在该 ActorSystem 启动了一个actor。
对于 createHaServices 服务的流程图解:
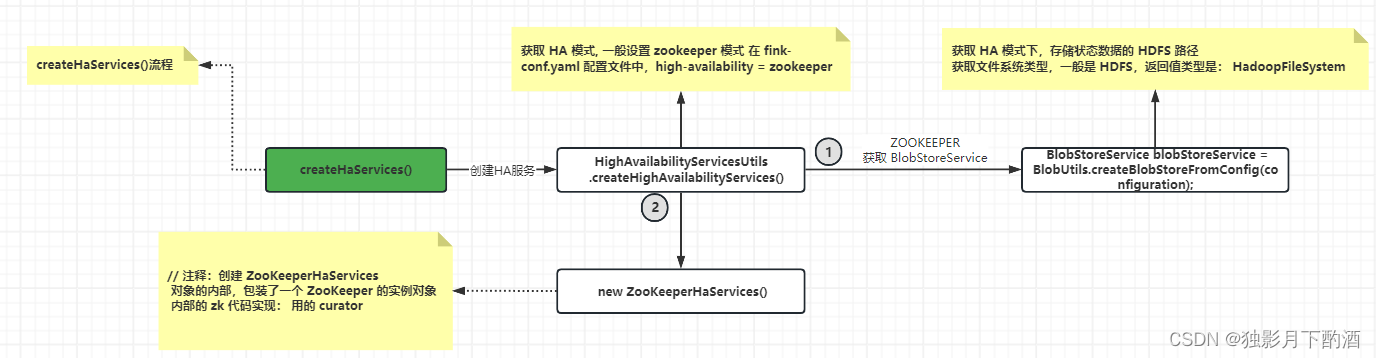
Flink 的 HA 模式一般选择 Zookeeper。
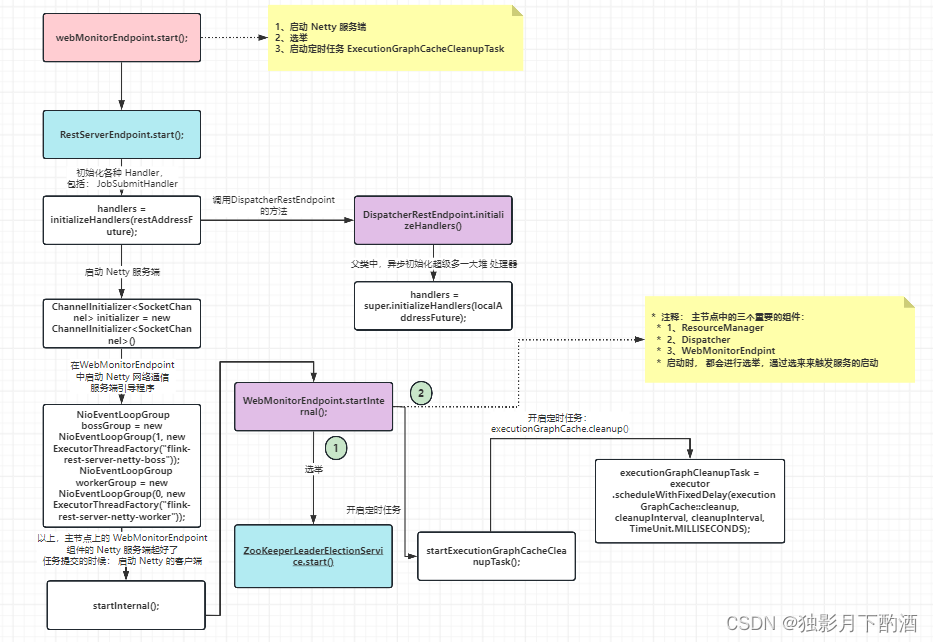
2.6 启动 webMonitorEndpoint 服务
webMonitorEndpoint 启动分为两部分:
- webMonitorEndpoint 的实例化与webMonitorEndpoint 的启动
- 通过restEndpointFactory.createRestEndpoint()方法创建webMonitorEndpoint对象
- 初始化各种Handler对象,包括JobSubmitHandler
- 启动Netty服务端
- 启动完成之后,会进行选举,选举成功后会执行leaderElectionService.isLeader() ==> leaderContender.grantLeaderShip()
该方法通过dispatcherResourceManagerComponentFactory中的三个工厂对象创建对应的三个实例对象。
- webMonitorEndpoint = restEndpointFactory.createRestEndpoint()
- resourceManager = resourceManagerFactory.createResourceManager()
- dispatcherRunner = dispatcherRunnerFactory.createDispatcherRunner()

@Override
public DispatcherResourceManagerComponent create(Configuration configuration, Executor ioExecutor, RpcService rpcService,
HighAvailabilityServices highAvailabilityServices, BlobServer blobServer, HeartbeatServices heartbeatServices, MetricRegistry metricRegistry,
ArchivedExecutionGraphStore archivedExecutionGraphStore, MetricQueryServiceRetriever metricQueryServiceRetriever,
FatalErrorHandler fatalErrorHandler) throws Exception {
// 注释: 检索当前leader并进行通知一个倾听者的服务
LeaderRetrievalService dispatcherLeaderRetrievalService = null;
//注释: 检索当前leader并进行通知一个倾听者的服务
LeaderRetrievalService resourceManagerRetrievalService = null;
// 注释: 服务于web前端Rest调用的Rest端点
WebMonitorEndpoint<?> webMonitorEndpoint = null;
// 注释: ResourceManager实现。资源管理器负责资源的分配和记帐
ResourceManager<?> resourceManagr = null;
//注释: 封装Dispatcher如何执行的
DispatcherRunner dispatcherRunner = null;
try {
// 注释: 用于 Dispatcher leader 选举
//注释: dispatcherLeaderRetrievalService = ZooKeeperLeaderRetrievalService
dispatcherLeaderRetrievalService = highAvailabilityServices.getDispatcherLeaderRetriever();
// 注释: 用于 ResourceManager leader 选举
// 注释: resourceManagerRetrievalService = ZooKeeperLeaderRetrievalService
resourceManagerRetrievalService = highAvailabilityServices.getResourceManagerLeaderRetriever();
// 注释: Dispatcher 的 Gateway
final LeaderGatewayRetriever<DispatcherGateway> dispatcherGatewayRetriever = new RpcGatewayRetriever<>(rpcService,
DispatcherGateway.class, DispatcherId::fromUuid, 10, Time.milliseconds(50L));
// 注释: ResourceManager 的 Gateway
final LeaderGatewayRetriever<ResourceManagerGateway> resourceManagerGatewayRetriever = new RpcGatewayRetriever<>(rpcService,
ResourceManagerGateway.class, ResourceManagerId::fromUuid, 10, Time.milliseconds(50L));
//注释: 创建线程池,用于执行 WebMonitorEndpoint 所接收到的 client 发送过来的请求
final ScheduledExecutorService executor = WebMonitorEndpoint
.createExecutorService(configuration.getInteger(RestOptions.SERVER_NUM_THREADS),
configuration.getInteger(RestOptions.SERVER_THREAD_PRIORITY), "DispatcherRestEndpoint");
//注释 初始化 MetricFetcher
final long updateInterval = configuration.getLong(MetricOptions.METRIC_FETCHER_UPDATE_INTERVAL);
final MetricFetcher metricFetcher = updateInterval == 0 ? VoidMetricFetcher.INSTANCE : MetricFetcherImpl
.fromConfiguration(configuration, metricQueryServiceRetriever, dispatcherGatewayRetriever, executor);
/*************************************************
* 注释: 创建 WebMonitorEndpoint 实例, 在 Standalone模式下:DispatcherRestEndpoint
* 1、restEndpointFactory = SessionRestEndpointFactory
* 2、webMonitorEndpoint = DispatcherRestEndpoint
* 3、highAvailabilityServices.getClusterRestEndpointLeaderElectionService() = ZooKeeperLeaderElectionService
*/
webMonitorEndpoint = restEndpointFactory
.createRestEndpoint(configuration, dispatcherGatewayRetriever, resourceManagerGatewayRetriever, blobServer, executor, metricFetcher,
highAvailabilityServices.getClusterRestEndpointLeaderElectionService(), fatalErrorHandler);
/*************************************************
* 注释: 启动 DispatcherRestEndpoint
* 1、启动 Netty 服务端
* 2、选举
* 3、启动定时任务 ExecutionGraphCacheCleanupTask
*/
log.debug("Starting Dispatcher REST endpoint.");
webMonitorEndpoint.start();
final String hostname = RpcUtils.getHostname(rpcService);
/*************************************************
* 注释: 创建 StandaloneResourceManager 实例对象
* 1、resourceManager = StandaloneResourceManager
* 2、resourceManagerFactory = StandaloneResourceManagerFactory
*/
resourceManager = resourceManagerFactory
.createResourceManager(configuration, ResourceID.generate(), rpcService, highAvailabilityServices, heartbeatServices,
fatalErrorHandler, new ClusterInformation(hostname, blobServer.getPort()), webMonitorEndpoint.getRestBaseUrl(), metricRegistry,
hostname);
final HistoryServerArchivist historyServerArchivist = HistoryServerArchivist
.createHistoryServerArchivist(configuration, webMonitorEndpoint, ioExecutor);
final PartialDispatcherServices partialDispatcherServices = new PartialDispatcherServices(configuration, highAvailabilityServices,
resourceManagerGatewayRetriever, blobServer, heartbeatServices,
() -> MetricUtils.instantiateJobManagerMetricGroup(metricRegistry, hostname), archivedExecutionGraphStore, fatalErrorHandler,
historyServerArchivist, metricRegistry.getMetricQueryServiceGatewayRpcAddress());
/*************************************************
* 注释: 创建 并启动 Dispatcher
* 1、dispatcherRunner = DispatcherRunnerLeaderElectionLifecycleManager
* 2、dispatcherRunnerFactory = DefaultDispatcherRunnerFactory
* 第一个参数: ZooKeeperLeaderElectionService
* -
* 老版本: 这个地方是直接创建一个 Dispatcher 对象然后调用 dispatcher.start() 来启动
* 新版本: 直接创建一个 DispatcherRunner, 内部就是要创建和启动 Dispatcher
*/
log.debug("Starting Dispatcher.");
dispatcherRunner = dispatcherRunnerFactory
.createDispatcherRunner(highAvailabilityServices.getDispatcherLeaderElectionService(), fatalErrorHandler,
// 注释: 注意第三个参数
new HaServicesJobGraphStoreFactory(highAvailabilityServices), ioExecutor, rpcService, partialDispatcherServices);
/*************************************************
* 注释: resourceManager 启动
*/
log.debug("Starting ResourceManager.");
resourceManager.start();
/*************************************************
* 注释: resourceManagerRetrievalService 启动
*/
resourceManagerRetrievalService.start(resourceManagerGatewayRetriever);
/*************************************************
* 注释: ZooKeeperHaServices 启动
*/
dispatcherLeaderRetrievalService.start(dispatcherGatewayRetriever);
/*************************************************
* 注释: 构建 DispatcherResourceManagerComponent
*/
return new DispatcherResourceManagerComponent(dispatcherRunner, resourceManager, dispatcherLeaderRetrievalService,
resourceManagerRetrievalService, webMonitorEndpoint);
} catch(Exception exception) {
................
}
2.6.1 restEndpointFactory.createRestEndpoint(实例化)
restEndpointFactory = SessionRestEndpointFactory(代码跳转的类),创建webMonitorEndpoint实例化对象,返回的是DispatcherRestEndpoint对象。webMonitorEndpoint处理客户端所有的请求。
public enum SessionRestEndpointFactory implements RestEndpointFactory<DispatcherGateway> {
INSTANCE;
@Override
public WebMonitorEndpoint<DispatcherGateway> createRestEndpoint(Configuration configuration,
LeaderGatewayRetriever<DispatcherGateway> dispatcherGatewayRetriever,
LeaderGatewayRetriever<ResourceManagerGateway> resourceManagerGatewayRetriever, TransientBlobService transientBlobService,
ScheduledExecutorService executor, MetricFetcher metricFetcher, LeaderElectionService leaderElectionService,
FatalErrorHandler fatalErrorHandler) throws Exception {
final RestHandlerConfiguration restHandlerConfiguration = RestHandlerConfiguration.fromConfiguration(configuration);
/*************************************************
* RestEndpointFactory.createExecutionGraphCache(restHandlerConfiguration) = DefaultExecutionGraphCache
*/
return new DispatcherRestEndpoint(RestServerEndpointConfiguration.fromConfiguration(configuration), dispatcherGatewayRetriever, configuration,
restHandlerConfiguration, resourceManagerGatewayRetriever, transientBlobService, executor, metricFetcher, leaderElectionService,
RestEndpointFactory.createExecutionGraphCache(restHandlerConfiguration), fatalErrorHandler);
}
}
2.6.2 webMonitorEndpoint.start(启动)
该方法主要作用:
- 初始化各种Handler,包括: JobSubmitHandler(专门处理客户端提交的作业)
- 客户端提交的job时,由Jobmanager中的Netty服务端的JobSubmitHandler来处理
- JobSubmitHandler接收到客户端的请求,通过handleRequest方法做了以下事情:
- 恢复得到 JobGragh
- 获取jar包以及依赖jar包
- 上传JobGraph + 程序jar + 依赖 jar,然后提交任务(Dispatcher.submitJob)
- 启动 Netty 服务端(启动位置:WebMonitorEndpoint)
public final void start() throws Exception {
synchronized(lock) {
Preconditions.checkState(state == State.CREATED, "The RestServerEndpoint cannot be restarted.");
log.info("Starting rest endpoint.");
final Router router = new Router();
final CompletableFuture<String> restAddressFuture = new CompletableFuture<>();
//注释: 主要是初始化各种 Handler,包括: JobSubmitHandler
handlers = initializeHandlers(restAddressFuture);
// 注释: 针对所有的 Handlers 进行排序,排序规则:RestHandlerUrlComparator
Collections.sort(handlers, RestHandlerUrlComparator.INSTANCE);
checkAllEndpointsAndHandlersAreUnique(handlers);
handlers.forEach(handler -> registerHandler(router, handler, log));
// 注释: 启动 Netty 服务端
ChannelInitializer<SocketChannel> initializer = new ChannelInitializer<SocketChannel>() {
@Override
protected void initChannel(SocketChannel ch) {
RouterHandler handler = new RouterHandler(router, responseHeaders);
// SSL should be the first handler in the pipeline
if(isHttpsEnabled()) {
ch.pipeline().addLast("ssl", new RedirectingSslHandler(restAddress, restAddressFuture, sslHandlerFactory));
}
ch.pipeline()
.addLast(new HttpServerCodec())
.addLast(new FileUploadHandler(uploadDir))
.addLast(new FlinkHttpObjectAggregator(maxContentLength, responseHeaders))
.addLast(new ChunkedWriteHandler())
.addLast(handler.getName(), handler)
.addLast(new PipelineErrorHandler(log, responseHeaders));
}
};
// 创建两个工作组的线程 bossGroup与workerGroup
NioEventLoopGroup bossGroup = new NioEventLoopGroup(1, new ExecutorThreadFactory("flink-rest-server-netty-boss"));
NioEventLoopGroup workerGroup = new NioEventLoopGroup(0, new ExecutorThreadFactory("flink-rest-server-netty-worker"));
// 注释: 启动 Netty 网络通信 服务端引导程序
bootstrap = new ServerBootstrap();
bootstrap.group(bossGroup, workerGroup).channel(NioServerSocketChannel.class).childHandler(initializer);
Iterator<Integer> portsIterator;
try {
portsIterator = NetUtils.getPortRangeFromString(restBindPortRange);
} catch(IllegalConfigurationException e) {
throw e;
} catch(Exception e) {
throw new IllegalArgumentException("Invalid port range definition: " + restBindPortRange);
}
// 注释: 绑定端口,通过轮询的方式来搞定
int chosenPort = 0;
while(portsIterator.hasNext()) {
try {
chosenPort = portsIterator.next();
final ChannelFuture channel;
if(restBindAddress == null) {
channel = bootstrap.bind(chosenPort);
} else {
channel = bootstrap.bind(restBindAddress, chosenPort);
}
serverChannel = channel.syncUninterruptibly().channel();
break;
} catch(final Exception e) {
// continue if the exception is due to the port being in use, fail early otherwise
if(!(e instanceof org.jboss.netty.channel.ChannelException || e instanceof java.net.BindException)) {
throw e;
}
}
}
if(serverChannel == null) {
throw new BindException("Could not start rest endpoint on any port in port range " + restBindPortRange);
}
log.debug("Binding rest endpoint to {}:{}.", restBindAddress, chosenPort);
final InetSocketAddress bindAddress = (InetSocketAddress) serverChannel.localAddress();
final String advertisedAddress;
if(bindAddress.getAddress().isAnyLocalAddress()) {
advertisedAddress = this.restAddress;
} else {
advertisedAddress = bindAddress.getAddress().getHostAddress();
}
final int port = bindAddress.getPort();
log.info("Rest endpoint listening at {}:{}", advertisedAddress, port);
restBaseUrl = new URL(determineProtocol(), advertisedAddress, port, "").toString();
restAddressFuture.complete(restBaseUrl);
state = State.RUNNING;
/*************************************************
* 注释:到此为止,主节点上的 WebMonitorEndpoint组件的Netty服务端起好了。
* 任务提交时: 启动 Netty 的客户端
*/
// 注释: 启动
startInternal();
}
}
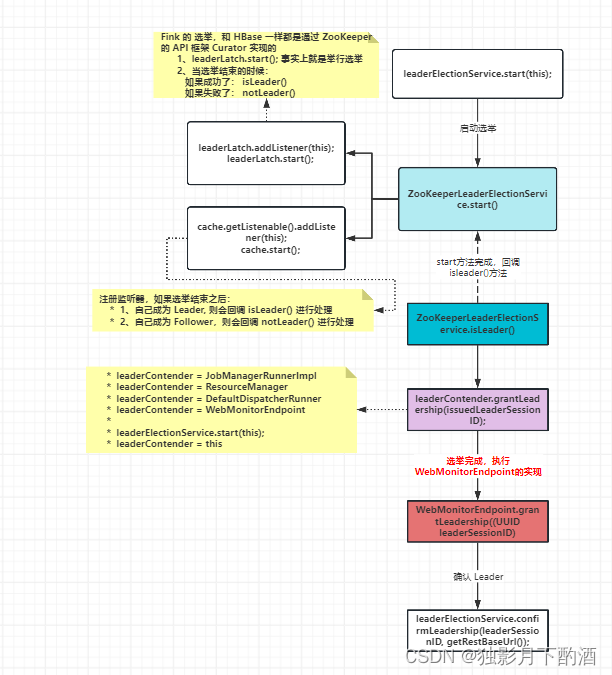
2.6.3 startInternal();
Flink集群中的主节点中有三个重要的组件:ResourceManager、Dispatcher、WebMonitorEndpint,启动时均会进行选举,通过选举来触发该服务。
public void startInternal() throws Exception {
/*************************************************
* 注释: 选举 ZooKeeperLeaderElectionService
* 不管你在那个地方见到这种格式的代码:leaderElectionService.start(this);
* 1、参与选举的 某个获胜的角色会调用: leaderElectionService.isLeader() ==> leaderContender.grantLeaderShip()
* 2、参与选举的 某个失败的角色会调用: leaderElectionService.notLeader()
*/
leaderElectionService.start(this);
/*************************************************
* 注释: 开启定时任务
* executionGraphCache = DefaultExecutionGraphCach 清除已经执行完毕的ExecutionGraph
*/
startExecutionGraphCacheCleanupTask();
if(hasWebUI) {
log.info("Web frontend listening at {}.", getRestBaseUrl());
}
}
WebMonitorEndpoint启动时选举流程图解:
2.7 启动 resourceManager 服务
ResourceManager的启动主要分为以下:
- resourceManagerFactory.createResourceManager创建resourceManager对象,完成实例化之后会执行OnStart()方法[开启ResourceManager的服务]
- 开启两个心跳服务(监控JobManager与TaskManager的心跳)
- 开启两个定时任务(每隔30s检查TaskManager的心跳,每隔5min检查是否有申请slot的request超时未处理)
2.7.1 resourceManagerFactory.createResourceManager(实例化)
该方法创建 StandaloneResourceManager 实例对象,resourceManager = StandaloneResourceManager。在resourceManager的内部通过动态代理的方式构建了一个Rpc Server,用来处理TaskManager启动完成后,进行注册和心跳的请求服务。
public ResourceManager<T> createResourceManager(Configuration configuration, ResourceID resourceId, RpcService rpcService,
HighAvailabilityServices highAvailabilityServices, HeartbeatServices heartbeatServices, FatalErrorHandler fatalErrorHandler,
ClusterInformation clusterInformation, @Nullable String webInterfaceUrl, MetricRegistry metricRegistry, String hostname) throws Exception {
final ResourceManagerMetricGroup resourceManagerMetricGroup = ResourceManagerMetricGroup.create(metricRegistry, hostname);
final SlotManagerMetricGroup slotManagerMetricGroup = SlotManagerMetricGroup.create(metricRegistry, hostname);
/*************************************************
* 注释: 创建 ResourceManagerRuntimeServices 实例
*/
final ResourceManagerRuntimeServices resourceManagerRuntimeServices = createResourceManagerRuntimeServices(configuration, rpcService,
highAvailabilityServices, slotManagerMetricGroup);
/*************************************************
* 注释: 创建 ResourceManager 实例
*/
return createResourceManager(configuration, resourceId, rpcService, highAvailabilityServices, heartbeatServices, fatalErrorHandler,
clusterInformation, webInterfaceUrl, resourceManagerMetricGroup, resourceManagerRuntimeServices);
}
// createResourceManager--> StandaloneResourceManagerFactory.createResourceManager
@Override
protected ResourceManager<ResourceID> createResourceManager(
Configuration configuration,
ResourceID resourceId,
RpcService rpcService,
HighAvailabilityServices highAvailabilityServices,
HeartbeatServices heartbeatServices,
FatalErrorHandler fatalErrorHandler,
ClusterInformation clusterInformation,
@Nullable String webInterfaceUrl,
ResourceManagerMetricGroup resourceManagerMetricGroup,
ResourceManagerRuntimeServices resourceManagerRuntimeServices) {
final Time standaloneClusterStartupPeriodTime = ConfigurationUtils.getStandaloneClusterStartupPeriodTime(configuration);
/*************************************************
* 注释: 返回 StandaloneResourceManager 实例对象
*/
return new StandaloneResourceManager(
rpcService,
resourceId,
highAvailabilityServices,
heartbeatServices,
resourceManagerRuntimeServices.getSlotManager(),
ResourceManagerPartitionTrackerImpl::new,
resourceManagerRuntimeServices.getJobLeaderIdService(),
clusterInformation,
fatalErrorHandler,
resourceManagerMetricGroup,
standaloneClusterStartupPeriodTime,
AkkaUtils.getTimeoutAsTime(configuration));
}
// StandaloneResourceManager
public StandaloneResourceManager(RpcService rpcService, ResourceID resourceId, HighAvailabilityServices highAvailabilityServices,
HeartbeatServices heartbeatServices, SlotManager slotManager, ResourceManagerPartitionTrackerFactory clusterPartitionTrackerFactory,
JobLeaderIdService jobLeaderIdService, ClusterInformation clusterInformation, FatalErrorHandler fatalErrorHandler,
ResourceManagerMetricGroup resourceManagerMetricGroup, Time startupPeriodTime, Time rpcTimeout) {
/*************************************************
* 注释: 注意该父类方法
*/
super(rpcService, resourceId, highAvailabilityServices, heartbeatServices, slotManager, clusterPartitionTrackerFactory, jobLeaderIdService,
clusterInformation, fatalErrorHandler, resourceManagerMetricGroup, rpcTimeout);
this.startupPeriodTime = Preconditions.checkNotNull(startupPeriodTime);
}
// StandaloneResourceManager-->ResourceManager
public ResourceManager(RpcService rpcService, ResourceID resourceId, HighAvailabilityServices highAvailabilityServices,
HeartbeatServices heartbeatServices, SlotManager slotManager, ResourceManagerPartitionTrackerFactory clusterPartitionTrackerFactory,
JobLeaderIdService jobLeaderIdService, ClusterInformation clusterInformation, FatalErrorHandler fatalErrorHandler,
ResourceManagerMetricGroup resourceManagerMetricGroup, Time rpcTimeout) {
/*************************************************
* 注释: 当执行完毕这个构造方法的时候,会触发调用 onStart() 方法执行
*/
super(rpcService, AkkaRpcServiceUtils.createRandomName(RESOURCE_MANAGER_NAME), null);
this.resourceId = checkNotNull(resourceId);
this.highAvailabilityServices = checkNotNull(highAvailabilityServices);
this.heartbeatServices = checkNotNull(heartbeatServices);
this.slotManager = checkNotNull(slotManager);
this.jobLeaderIdService = checkNotNull(jobLeaderIdService);
this.clusterInformation = checkNotNull(clusterInformation);
this.fatalErrorHandler = checkNotNull(fatalErrorHandler);
this.resourceManagerMetricGroup = checkNotNull(resourceManagerMetricGroup);
this.jobManagerRegistrations = new HashMap<>(4);
this.jmResourceIdRegistrations = new HashMap<>(4);
this.taskExecutors = new HashMap<>(8);
this.taskExecutorGatewayFutures = new HashMap<>(8);
this.jobManagerHeartbeatManager = NoOpHeartbeatManager.getInstance();
this.taskManagerHeartbeatManager = NoOpHeartbeatManager.getInstance();
this.clusterPartitionTracker = checkNotNull(clusterPartitionTrackerFactory).get(
(taskExecutorResourceId, dataSetIds) -> taskExecutors.get(taskExecutorResourceId).getTaskExecutorGateway()
.releaseClusterPartitions(dataSetIds, rpcTimeout).exceptionally(throwable -> {
log.debug("Request for release of cluster partitions belonging to data sets {} was not successful.", dataSetIds, throwable);
throw new CompletionException(throwable);
}));
}
//ResourceManager--> FencedRpcEndpoint
protected FencedRpcEndpoint(RpcService rpcService, String endpointId, @Nullable F fencingToken) {
/*************************************************
* 注释:注意这个父类方法
*/
super(rpcService, endpointId);
Preconditions.checkArgument(rpcServer instanceof FencedMainThreadExecutable, "The rpcServer must be of type %s.",
FencedMainThreadExecutable.class.getSimpleName());
// no fencing token == no leadership
this.fencingToken = fencingToken;
this.unfencedMainThreadExecutor = new UnfencedMainThreadExecutor((FencedMainThreadExecutable) rpcServer);
this.fencedMainThreadExecutor = new MainThreadExecutor(getRpcService().fenceRpcServer(rpcServer, fencingToken),
this::validateRunsInMainThread);
}
//FencedRpcEndpoint--> RpcEndpoint
protected RpcEndpoint(final RpcService rpcService, final String endpointId) {
this.rpcService = checkNotNull(rpcService, "rpcService");
this.endpointId = checkNotNull(endpointId, "endpointId");
/*************************************************
* 注释: 启动 ResourceManager 的 RPCServer 服务
* 启动的是 ResourceManager 的 Rpc 服务端。
* 在TaskManager启动好之后,接收注册和心跳的请求,来汇报Taskmanagaer的资源情况
* 通过动态代理构建一个Rpc Server
*/
this.rpcServer = rpcService.startServer(this);
this.mainThreadExecutor = new MainThreadExecutor(rpcServer, this::validateRunsInMainThread);
}
// 上述代码执行完成之后,实例化完成了,接下来就要执行ResourceManager中的onStart()方法,最终实现的是ResourceManager中的onStart()方法。
@Override
public void onStart() throws Exception {
try {
/*************************************************
* 注释: 开启 RM 服务
*/
startResourceManagerServices();
} catch(Exception e) {
final ResourceManagerException exception = new ResourceManagerException(
String.format("Could not start the ResourceManager %s", getAddress()), e);
onFatalError(exception);
throw exception;
}
}
// startResourceManagerServices
private void startResourceManagerServices() throws Exception {
try {
/*************************************************
* 注释:leaderElectionService = ZooKeeperLeaderElectionService
*/
leaderElectionService = highAvailabilityServices.getResourceManagerLeaderElectionService();
// 注释:在 Standalone 模式下,什么也没做
initialize();
// 注释: 执行选举,成功之后,调用 leaderElectionService.isLeader()
// 注释: this = ResourceManager
leaderElectionService.start(this);
jobLeaderIdService.start(new JobLeaderIdActionsImpl());
registerTaskExecutorMetrics();
} catch(Exception e) {
handleStartResourceManagerServicesException(e);
}
}
//-->leaderElectionService.start(this);
@Override
public void start(LeaderContender newContender) throws Exception {
if (contender != null) {
// Service was already started
throw new IllegalArgumentException("Leader election service cannot be started multiple times.");
}
contender = Preconditions.checkNotNull(newContender);
// directly grant leadership to the given contender
contender.grantLeadership(HighAvailabilityServices.DEFAULT_LEADER_ID);
}
//-->contender.grantLeadership(HighAvailabilityServices.DEFAULT_LEADER_ID)
@Override
public void grantLeadership(final UUID newLeaderSessionID) {
/*************************************************
* 调用: tryAcceptLeadership 方法
*/
final CompletableFuture<Boolean> acceptLeadershipFuture = clearStateFuture
.thenComposeAsync((ignored) -> tryAcceptLeadership(newLeaderSessionID), getUnfencedMainThreadExecutor());
//注释: 调用 confirmLeadership
final CompletableFuture<Void> confirmationFuture = acceptLeadershipFuture.thenAcceptAsync((acceptLeadership) -> {
if(acceptLeadership) {
// confirming the leader session ID might be blocking,
leaderElectionService.confirmLeadership(newLeaderSessionID, getAddress());
}
}, getRpcService().getExecutor());
//注释: 调用 whenComplete
confirmationFuture.whenComplete((Void ignored, Throwable throwable) -> {
if(throwable != null) {
onFatalError(ExceptionUtils.stripCompletionException(throwable));
}
});
}
//--> tryAcceptLeadership(newLeaderSessionID)
private CompletableFuture<Boolean> tryAcceptLeadership(final UUID newLeaderSessionID) {
// 注释: 判断,如果集群有了 LeaderResourceManager
if(leaderElectionService.hasLeadership(newLeaderSessionID)) {
// 注释: 生成一个 ResourceManagerID
final ResourceManagerId newResourceManagerId = ResourceManagerId.fromUuid(newLeaderSessionID);
log.info("ResourceManager {} was granted leadership with fencing token {}", getAddress(), newResourceManagerId);
//注释: 如果之前已成为过 Leader 的话,则清理之前的状态
// clear the state if we've been the leader before
if(getFencingToken() != null) {
clearStateInternal();
}
setFencingToken(newResourceManagerId);
/*************************************************
* 注释: 启动服务
* 1、启动心跳服务
* 启动两个定时任务
* 2、启动 SlotManager 服务
* 启动两个定时任务
*/
startServicesOnLeadership();
return prepareLeadershipAsync().thenApply(ignored -> true);
} else {
return CompletableFuture.completedFuture(false);
}
}
//-->startServicesOnLeadership()
protected void startServicesOnLeadership() {
/*************************************************
* 注释: 开启心跳服务
*/
startHeartbeatServices();
/*************************************************
* 注释: 启动 SlotManagerImpl 只是开启了两个定时任务而已
*/
slotManager.start(getFencingToken(), getMainThreadExecutor(), new ResourceActionsImpl());
}
//-->startHeartbeatServices
/*************************************************
* 注释: 当前 ResourceManager 启动了两个心跳服务:
* 1、taskManagerHeartbeatManager 心跳管理器 关心点的是: taskManager 的死活
* 2、jobManagerHeartbeatManager 心跳管理器 关心点的是: jobManager 的死活
* taskManager 集群的资源提供者,任务执行者,从节点
* jobManager 每一个job会启动的一个主控程序
* 不管是集群的从节点执行心跳,还是每一个job会启动的一个主控程序,都向 ResourceManager 去汇报
*/
private void startHeartbeatServices() {
/*************************************************
* 注释: 用来收听: TaskManager 的心跳
*/
taskManagerHeartbeatManager = heartbeatServices
.createHeartbeatManagerSender(resourceId, new TaskManagerHeartbeatListener(), getMainThreadExecutor(), log);
/*************************************************
* 注释: 用来收听: JobManager 的心跳
*/
jobManagerHeartbeatManager = heartbeatServices
.createHeartbeatManagerSender(resourceId, new JobManagerHeartbeatListener(), getMainThreadExecutor(), log);
}
// 完成心跳服务的对象是HeartbeatManagerSenderImpl
// HeartbeatServices--HeartbeatManagerSenderImpl,调用的是类实例的 run() 方法的执行
HeartbeatManagerSenderImpl(long heartbeatPeriod, long heartbeatTimeout, ResourceID ownResourceID, HeartbeatListener<I, O> heartbeatListener,
ScheduledExecutor mainThreadExecutor, Logger log, HeartbeatMonitor.Factory<O> heartbeatMonitorFactory) {
super(heartbeatTimeout, ownResourceID, heartbeatListener, mainThreadExecutor, log, heartbeatMonitorFactory);
this.heartbeatPeriod = heartbeatPeriod;
/*************************************************
* 注释: 调度当前的类实例的 run() 方法的执行
* 执行的就是当前类的 run() 方法,当前只是一个调度任务
*/
mainThreadExecutor.schedule(this, 0L, TimeUnit.MILLISECONDS);
}
//--run()
@Override
public void run() {
/*************************************************
* 注释: 在 Flink 的心跳机制中,跟其他的 集群不一样:
* 1、ResourceManager 发送心跳给 从节点 Taskmanager
* 2、从节点接收到心跳之后,返回响应
*/
// 注释: 实现循环执行
if(!stopped) {
log.debug("Trigger heartbeat request.");
for(HeartbeatMonitor<O> heartbeatMonitor : getHeartbeatTargets().values()) {
// 注释: ResourceManager 给目标发送(TaskManager 或者 JobManager)心跳
requestHeartbeat(heartbeatMonitor);
}
/*************************************************
* 注释: 实现循环发送心跳的效果
*/
getMainThreadExecutor().schedule(this, heartbeatPeriod, TimeUnit.MILLISECONDS);
}
}
// --requestHeartbeat
/*************************************************
* 注释: HeartbeatMonitor 如果有从节点返回心跳响应,则会被加入到 HeartbeatMonitor
* HeartbeatMonitor管理所有的心跳目标对象
*/
private void requestHeartbeat(HeartbeatMonitor<O> heartbeatMonitor) {
O payload = getHeartbeatListener().retrievePayload(heartbeatMonitor.getHeartbeatTargetId());
final HeartbeatTarget<O> heartbeatTarget = heartbeatMonitor.getHeartbeatTarget();
/*************************************************
* 注释: 发送心跳 集群中启动的从节点(heartbeatTarget)
*/
heartbeatTarget.requestHeartbeat(getOwnResourceID(), payload);
}
//--HeartbeatManagerImpl(requestHeartbeat)
@Override
public void requestHeartbeat(final ResourceID requestOrigin, I heartbeatPayload) {
if(!stopped) {
log.debug("Received heartbeat request from {}.", requestOrigin);
/*************************************************
* 注释: 汇报心跳
*/
final HeartbeatTarget<O> heartbeatTarget = reportHeartbeat(requestOrigin);
// 注释: 实现循环处理
if(heartbeatTarget != null) {
if(heartbeatPayload != null) {
heartbeatListener.reportPayload(requestOrigin, heartbeatPayload);
}
heartbeatTarget.receiveHeartbeat(getOwnResourceID(), heartbeatListener.retrievePayload(requestOrigin));
}
}
}
// 开启两个定时任务 slotManager.start
@Override
public void start(ResourceManagerId newResourceManagerId, Executor newMainThreadExecutor, ResourceActions newResourceActions) {
LOG.info("Starting the SlotManager.");
this.resourceManagerId = Preconditions.checkNotNull(newResourceManagerId);
mainThreadExecutor = Preconditions.checkNotNull(newMainThreadExecutor);
resourceActions = Preconditions.checkNotNull(newResourceActions);
started = true;
/*************************************************
* 注释:开启第一个定时任务: checkTaskManagerTimeouts,检查 TaskManager 心跳
* taskManagerTimeout = resourcemanager.taskmanager-timeout = 30000
*/
taskManagerTimeoutCheck = scheduledExecutor
.scheduleWithFixedDelay(() -> mainThreadExecutor.execute(() -> checkTaskManagerTimeouts()), 0L, taskManagerTimeout.toMilliseconds(),
TimeUnit.MILLISECONDS);
/*************************************************
* 注释开启第二个定时任务: checkSlotRequestTimeouts,检查SplotRequest超时处理
* slotRequestTimeout = slot.request.timeout = 5L * 60L * 1000L
*/
slotRequestTimeoutCheck = scheduledExecutor
.scheduleWithFixedDelay(() -> mainThreadExecutor.execute(() -> checkSlotRequestTimeouts()), 0L, slotRequestTimeout.toMilliseconds(),
TimeUnit.MILLISECONDS);
registerSlotManagerMetrics();
}
ResourceManager实例化流程图:

2.7.2 resourceManager.start(启动)
自身给自身发一个START的消息,说明ResourceManager 已经成功启动完成。
resourceManager.start();
-->start
public final void start() {
rpcServer.start();
}
-->rpcServer.start()
@Override
public void start() {
/*************************************************
* 注释: 发送 START 消息
* 只要发送了 START 这个消息,也就意味着: ResourceManager 已经成功启动好了。
*/
rpcEndpoint.tell(ControlMessages.START, ActorRef.noSender());
}
ResourceManager启动的流程图:

ResourceManger 选举机制流程图:
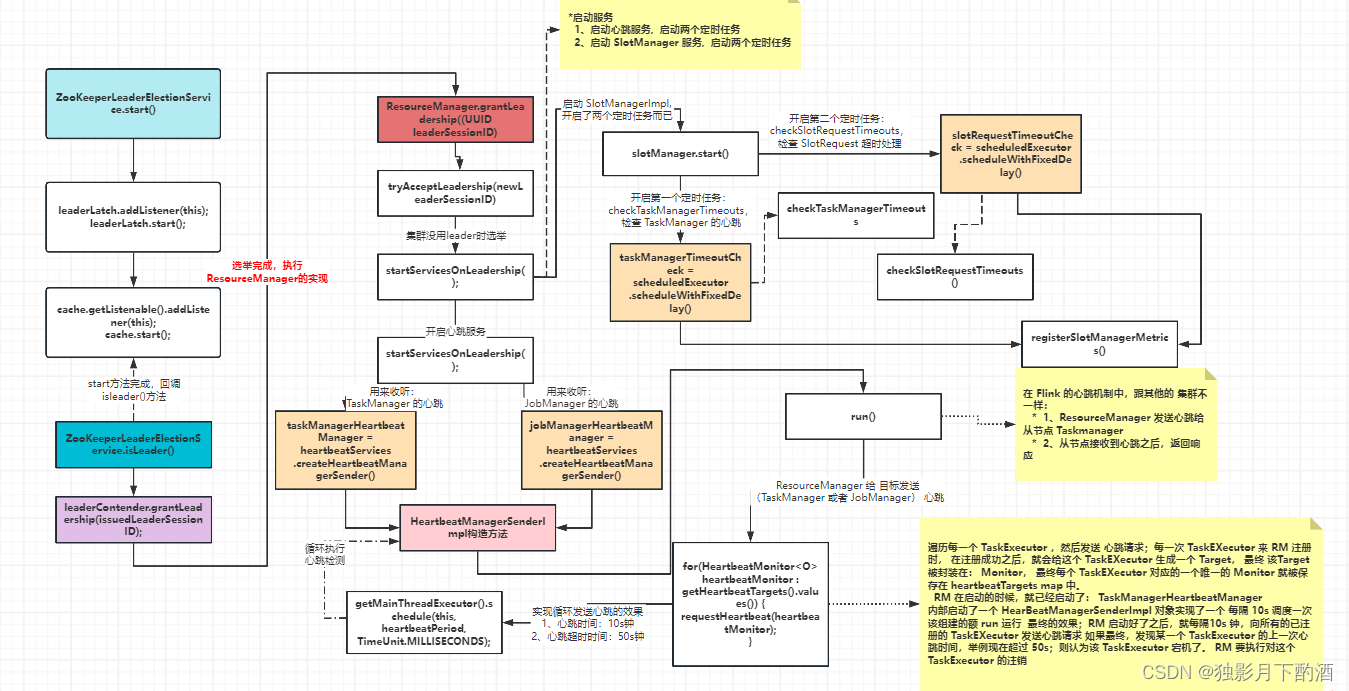
ResourceManager启动过程中:
- 开启两个心跳服务:
- ResourceManager 与 TaskManager 维持心跳
- ResourceManager 与 JobManger 维持心跳
- 开启两个定时任务:
- 检查 TaskManager 的心跳
- 检查 SplotRequest 超时处理
2.8 启动 dispatcher 服务
在老版本中直接创建一个 Dispatcher 对象然后调用 dispatcher.start() 来启动;新版本直接创建一个 DispatcherRunner, 内部就是要创建和启动 Dispatcher。启动过程主要有以下动作:
- 1.通过dispatcherRunnerFactory对象创建DispatcherRunner对象。
- 2.在实例化DispatcherRunner对象时会进行选举,选举成功会执行DispatcherRunner.isLeader()。
- 3.通过DefaultDispatcherRunner.grantLeadership方法构建Dispatcher对象,实例化完成之后会执行OnStart()方法。
- Dispatcher启动过程中会开启性能监控与引导程序的初始化。
2.8.1 dispatcherRunnerFactory.createDispatcherRunner(实例化)
dispatcherRunner = dispatcherRunnerFactory.createDispatcherRunner(highAvailabilityServices.getDispatcherLeaderElectionService(), fatalErrorHandler,
//注释: 注意第三个参数
new HaServicesJobGraphStoreFactory(highAvailabilityServices), ioExecutor, rpcService, partialDispatcherServices);
//-->createDispatcherRunner
@Override
public DispatcherRunner createDispatcherRunner(
// 注释: ZooKeeperLeaderElectionService
LeaderElectionService leaderElectionService,
FatalErrorHandler fatalErrorHandler,
// 注释: HaServicesJobGraphStoreFactory
JobGraphStoreFactory jobGraphStoreFactory,
Executor ioExecutor,
RpcService rpcService,
PartialDispatcherServices partialDispatcherServices) throws Exception {
// 注释: dispatcherLeaderProcessFactoryFactory = SessionDispatcherLeaderProcessFactoryFactory
final DispatcherLeaderProcessFactory dispatcherLeaderProcessFactory = dispatcherLeaderProcessFactoryFactory.createFactory(
jobGraphStoreFactory,
ioExecutor,
rpcService,
partialDispatcherServices,
fatalErrorHandler);
/*************************************************
* 注释:
* 第一个参数:ZooKeeperLeaderElectionService
* 第四个参数:SessionDispatcherLeaderProcessFactoryFactory
*/
return DefaultDispatcherRunner.create(
leaderElectionService,
fatalErrorHandler,
dispatcherLeaderProcessFactory);
}
//--> DefaultDispatcherRunner.create()
public static DispatcherRunner create(LeaderElectionService leaderElectionService, FatalErrorHandler fatalErrorHandler,
DispatcherLeaderProcessFactory dispatcherLeaderProcessFactory) throws Exception {
/*************************************************
* 注释:
* 第一个参数: ZooKeeperLeaderElectionService
* 第三个参数: SessionDispatcherLeaderProcessFactoryFactory
*/
final DefaultDispatcherRunner dispatcherRunner = new DefaultDispatcherRunner(leaderElectionService, fatalErrorHandler,
dispatcherLeaderProcessFactory);
/*************************************************
* 注释: 开启 DispatcherRunner 的生命周期
* 第一个参数: dispatcherRunner = DefaultDispatcherRunner
* 第二个参数: leaderElectionService = ZooKeeperLeaderElectionService
*/
return DispatcherRunnerLeaderElectionLifecycleManager.createFor(dispatcherRunner, leaderElectionService);
}
// DispatcherRunnerLeaderElectionLifecycleManager.createFor
public static <T extends DispatcherRunner & LeaderContender> DispatcherRunner createFor(T dispatcherRunner, LeaderElectionService leaderElectionService) throws Exception {
/*************************************************
* 注释:
* 第一个参数: dispatcherRunner = DefaultDispatcherRunner
* 第二个参数: leaderElectionService = ZooKeeperLeaderElectionService
*/
return new DispatcherRunnerLeaderElectionLifecycleManager<>(dispatcherRunner, leaderElectionService);
}
//--> DispatcherRunnerLeaderElectionLifecycleManager
private DispatcherRunnerLeaderElectionLifecycleManager(T dispatcherRunner, LeaderElectionService leaderElectionService) throws Exception {
this.dispatcherRunner = dispatcherRunner;
this.leaderElectionService = leaderElectionService;
/*************************************************
* 注释: 启动选举
* 参数:dispatcherRunner = DefaultDispatcherRunner
* 调用对象:leaderElectionService = ZooKeeperLeaderElectionService
* 这个选举服务对象 leaderElectionService 内部的 leaderContender 是 : DefaultDispatcherRunner
*/
leaderElectionService.start(dispatcherRunner);
// leaderElectionService.start(this);
}
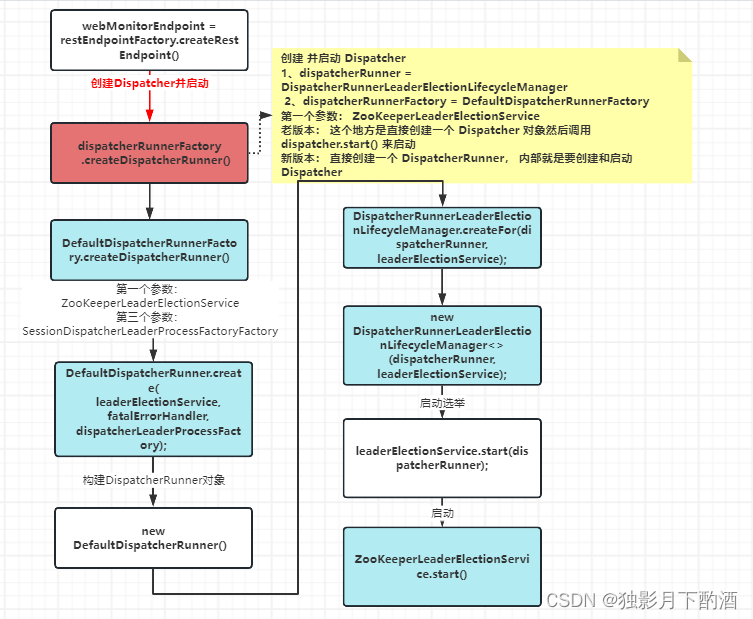
从上图可知:由 dispatcherRunnerFactory创建dispatcherRunner对象,在选举的过程中初始化dispatcher对象。
2.8.2 DispatcherRunner 选举
//-->leaderElectionService.start(dispatcherRunner);
@Override
public void start(LeaderContender contender) throws Exception {
Preconditions.checkNotNull(contender, "Contender must not be null.");
Preconditions.checkState(leaderContender == null, "Contender was already set.");
LOG.info("Starting ZooKeeperLeaderElectionService {}.", this);
synchronized(lock) {
client.getUnhandledErrorListenable().addListener(this);
// 注释: 取值根据实际情况而定
leaderContender = contender;
/*************************************************
* 注释:Fink的选举,和HBase一样都是通过 ZooKeeper的API框架Curator实现
* 1、leaderLatch.start(); 事实上就是举行选举
* 2、当选举结束的时候:
* 如果成功了: isLeader()
* 如果失败了: notLeader()
*/
leaderLatch.addListener(this);
leaderLatch.start();
/*************************************************
* 注释: 注册监听器,如果选举结束之后:
* 1、自己成为 Leader, 则会回调 isLeader() 进行处理
* 2、自己成为 Follower,则会回调 notLeader() 进行处理
*/
cache.getListenable().addListener(this);
cache.start();
client.getConnectionStateListenable().addListener(listener);
running = true;
}
}
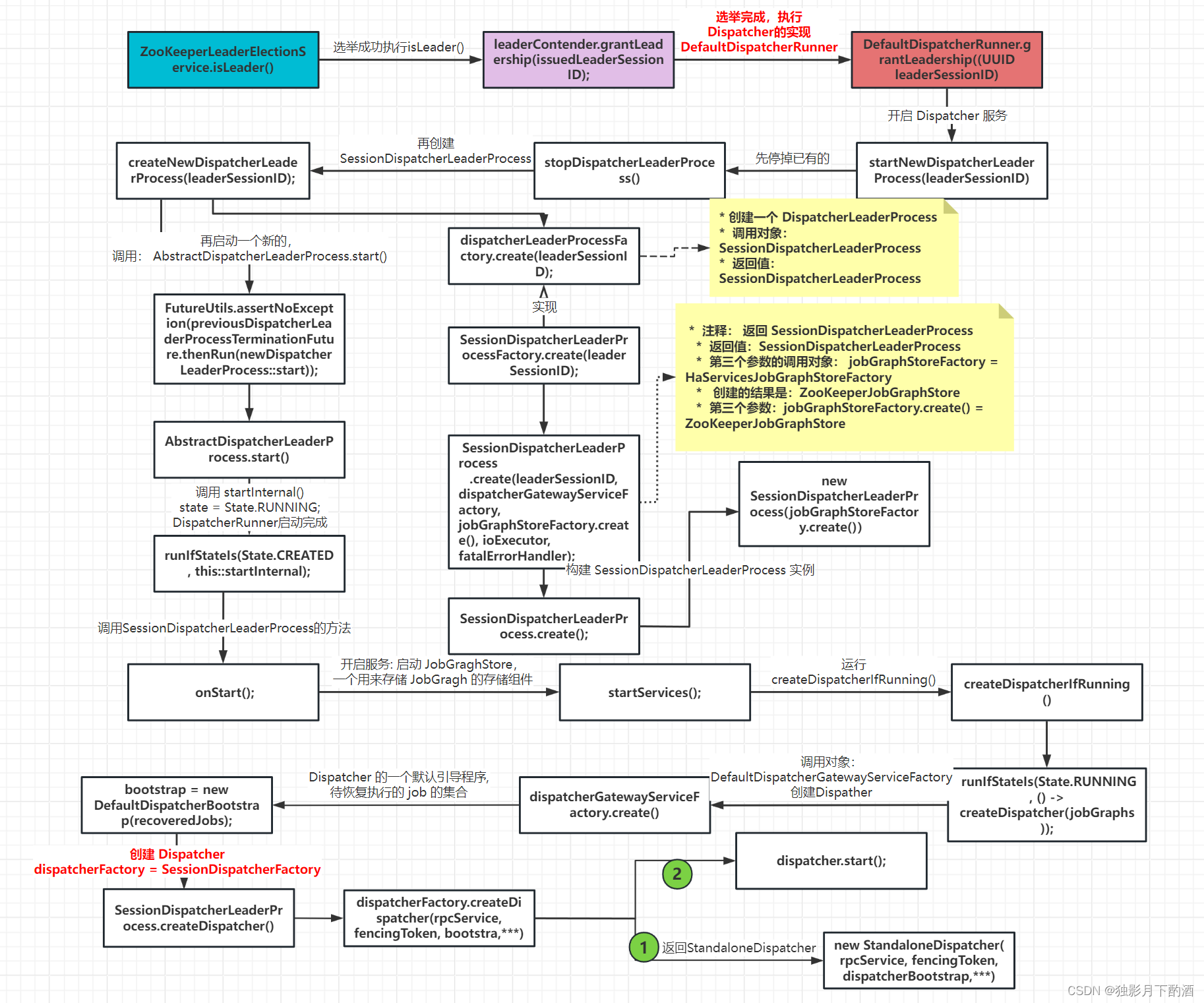
//->选举成功,调用isLeader()方法
@Override
public void isLeader() {
synchronized(lock) {
if(running) {
issuedLeaderSessionID = UUID.randomUUID();
clearConfirmedLeaderInformation();
if(LOG.isDebugEnabled()) {
LOG.debug("Grant leadership to contender {} with session ID {}.", leaderContender.getDescription(), issuedLeaderSessionID);
}
/*************************************************
* 注释: 分配 LeaderShip
* leaderContender = JobManagerRunnerImpl
* leaderContender = ResourceManager
* leaderContender = DefaultDispatcherRunner
* leaderContender = WebMonitorEndpoint
* leaderElectionService.start(this);
* leaderContender = this
*/
leaderContender.grantLeadership(issuedLeaderSessionID);
} else {
LOG.debug("Ignoring the grant leadership notification since the service has " + "already been stopped.");
}
}
}

2.8.3 开启 Dispatcher 服务
// DefaultDispatcherRunner.grantLeadership
@Override
public void grantLeadership(UUID leaderSessionID) {
/*************************************************
* 注释: 开启 Dispatcher 服务
*/
runActionIfRunning(() -> startNewDispatcherLeaderProcess(leaderSessionID));
}
//startNewDispatcherLeaderProcess(leaderSessionID))
private void startNewDispatcherLeaderProcess(UUID leaderSessionID) {
// 注释: 先停掉已有的
stopDispatcherLeaderProcess();
// 注释: SessionDispatcherLeaderProcess
dispatcherLeaderProcess = createNewDispatcherLeaderProcess(leaderSessionID);
final DispatcherLeaderProcess newDispatcherLeaderProcess = dispatcherLeaderProcess;
/*************************************************
* 注释: 再启动一个新的
* 调用: SessionDispatcherLeaderProcess.start()
*/
FutureUtils.assertNoException(previousDispatcherLeaderProcessTerminationFuture.thenRun(newDispatcherLeaderProcess::start));
}
//-->AbstractDispatcherLeaderProcess.start()
@Override
public final void start() {
/*************************************************
* 注释: 调用 startInternal()
*/
runIfStateIs(State.CREATED, this::startInternal);
}
//--> startInternal()
private void startInternal() {
log.info("Start {}.", getClass().getSimpleName());
state = State.RUNNING;
// 注释: SessionDispatcherLeaderProcess
onStart();
}
//--> onStart()
@Override
protected void onStart() {
/*************************************************
* 注释: 开启服务: 启动 JobGraghStore
* 一个用来存储 JobGragh 的存储组件
*/
startServices();
// 注释: 到现在为止,依然还没有启动 Dispatcher
onGoingRecoveryOperation = recoverJobsAsync()
/*************************************************
* 注释: 运行: createDispatcherIfRunning()
*/
.thenAccept(this::createDispatcherIfRunning)
.handle(this::onErrorIfRunning);
}
//-->startServices
private void startServices() {
try {
/*************************************************
* 注释: 开启 ZooKeeperJobGraphStore
*/
jobGraphStore.start(this);
} catch (Exception e) {
throw new FlinkRuntimeException(
String.format(
"Could not start %s when trying to start the %s.",
jobGraphStore.getClass().getSimpleName(),
getClass().getSimpleName()),
e);
}
}
//-->createDispatcherIfRunning
private void createDispatcherIfRunning(Collection<JobGraph> jobGraphs) {
runIfStateIs(State.RUNNING, () -> createDispatcher(jobGraphs));
}
//->createDispatcher
private void createDispatcher(Collection<JobGraph> jobGraphs) {
/*************************************************
* 调用对象: DefaultDispatcherGatewayServiceFactory
*/
final DispatcherGatewayService dispatcherService = dispatcherGatewayServiceFactory.create(
// 注释: DispatcherID
DispatcherId.fromUuid(getLeaderSessionId()),
//注释: jobGraghs
jobGraphs,
//注释: ZooKeeperJobGraphStore
jobGraphStore);DefaultDispatcherGatewayServiceFactory.
completeDispatcherSetup(dispatcherService);
}
//--> DefaultDispatcherGatewayServiceFactory.create
@Override
public AbstractDispatcherLeaderProcess.DispatcherGatewayService create(DispatcherId fencingToken, Collection<JobGraph> recoveredJobs,
JobGraphWriter jobGraphWriter) {
// 注释: Dispatcher 的一个默认引导程序
// 注释: 待恢复执行的 job 的集合
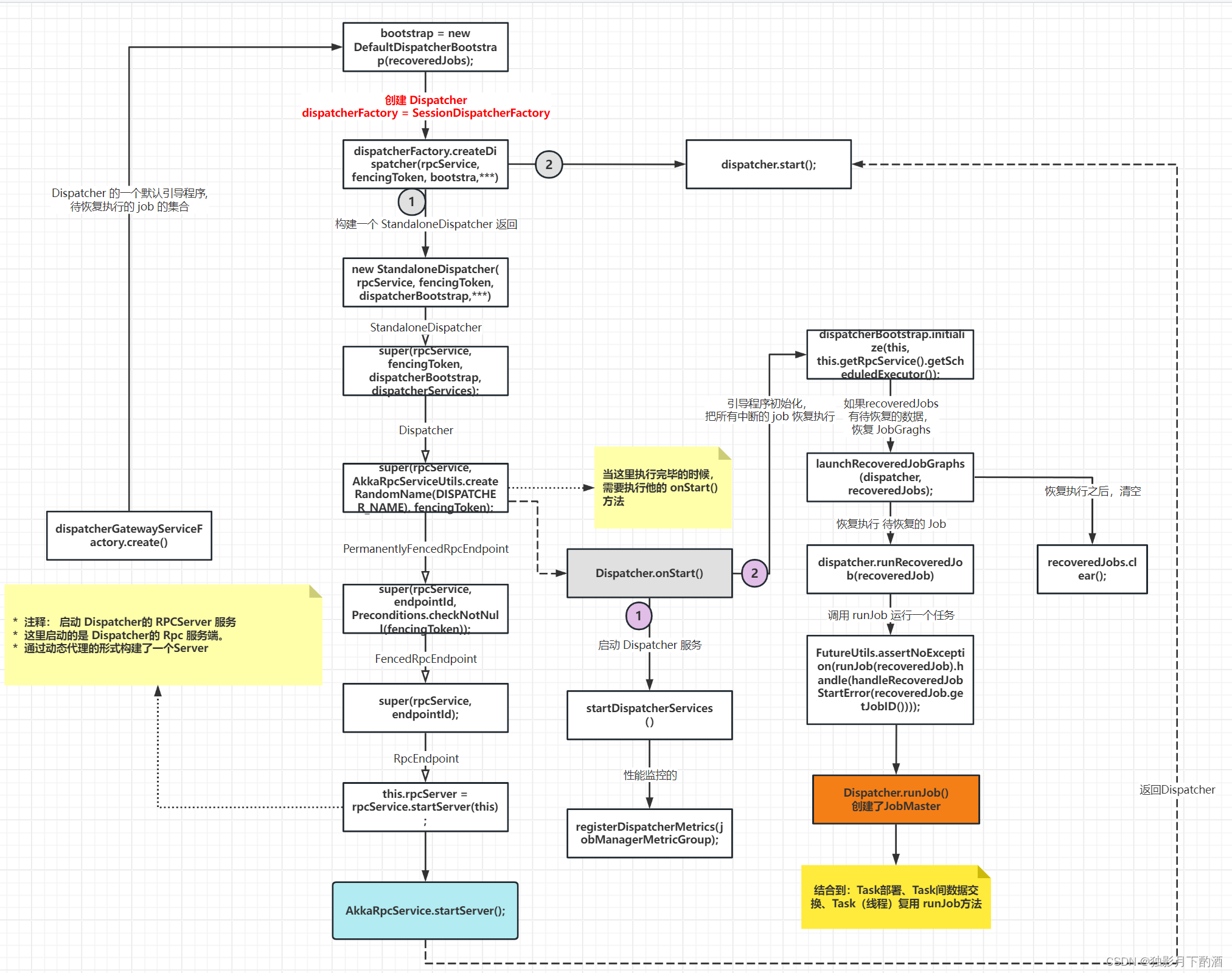
final DispatcherBootstrap bootstrap = new DefaultDispatcherBootstrap(recoveredJobs);
final Dispatcher dispatcher;
try {
/*************************************************
* 注释: 创建 Dispatcher
* dispatcherFactory = SessionDispatcherFactory
*/
dispatcher = dispatcherFactory.createDispatcher(rpcService, fencingToken, bootstrap,
// 注释: PartialDispatcherServicesWithJobGraphStore
PartialDispatcherServicesWithJobGraphStore.from(partialDispatcherServices, jobGraphWriter));
} catch(Exception e) {
throw new FlinkRuntimeException("Could not create the Dispatcher rpc endpoint.", e);
}
/*************************************************
* 注释: Dispatcher 也是一个 RpcEndpoint 启动起来了之后,给自己发送一个 Hello 消息证明启动
*/
dispatcher.start();
// 注释: 返回一个返回值
return DefaultDispatcherGatewayService.from(dispatcher);
}
//--> StandaloneDispatcher createDispatcher
@Override
public StandaloneDispatcher createDispatcher(RpcService rpcService, DispatcherId fencingToken, DispatcherBootstrap dispatcherBootstrap,
PartialDispatcherServicesWithJobGraphStore partialDispatcherServicesWithJobGraphStore) throws Exception {
/*************************************************
* 注释: 构建一个 StandaloneDispatcher 返回
*/
// create the default dispatcher
return new StandaloneDispatcher(rpcService, fencingToken, dispatcherBootstrap,
DispatcherServices.from(partialDispatcherServicesWithJobGraphStore, DefaultJobManagerRunnerFactory.INSTANCE));
}
// StandaloneDispatcher构造方法-->super()-->Dispatcher
public Dispatcher(RpcService rpcService, DispatcherId fencingToken, DispatcherBootstrap dispatcherBootstrap,
DispatcherServices dispatcherServices) throws Exception {
super(rpcService, AkkaRpcServiceUtils.createRandomName(DISPATCHER_NAME), fencingToken);
checkNotNull(dispatcherServices);
this.configuration = dispatcherServices.getConfiguration();
this.highAvailabilityServices = dispatcherServices.getHighAvailabilityServices();
this.resourceManagerGatewayRetriever = dispatcherServices.getResourceManagerGatewayRetriever();
this.heartbeatServices = dispatcherServices.getHeartbeatServices();
this.blobServer = dispatcherServices.getBlobServer();
this.fatalErrorHandler = dispatcherServices.getFatalErrorHandler();
this.jobGraphWriter = dispatcherServices.getJobGraphWriter();
this.jobManagerMetricGroup = dispatcherServices.getJobManagerMetricGroup();
this.metricServiceQueryAddress = dispatcherServices.getMetricQueryServiceAddress();
this.jobManagerSharedServices = JobManagerSharedServices.fromConfiguration(configuration, blobServer, fatalErrorHandler);
this.runningJobsRegistry = highAvailabilityServices.getRunningJobsRegistry();
jobManagerRunnerFutures = new HashMap<>(16);
this.historyServerArchivist = dispatcherServices.getHistoryServerArchivist();
this.archivedExecutionGraphStore = dispatcherServices.getArchivedExecutionGraphStore();
this.jobManagerRunnerFactory = dispatcherServices.getJobManagerRunnerFactory();
this.jobManagerTerminationFutures = new HashMap<>(2);
this.shutDownFuture = new CompletableFuture<>();
this.dispatcherBootstrap = checkNotNull(dispatcherBootstrap);
}
2.8.4 启动 Dispatcher 服务
// 这儿执行完毕的时候,需要执行 onStart() 方法
@Override
public void onStart() throws Exception {
try {
/*************************************************
* 注释: 启动 Dispatcher 服务
*/
startDispatcherServices();
} catch(Exception e) {
final DispatcherException exception = new DispatcherException(String.format("Could not start the Dispatcher %s", getAddress()), e);
onFatalError(exception);
throw exception;
}
/*************************************************
* 注释: 引导程序初始化
* 把所有中断的 job 恢复执行
*/
dispatcherBootstrap.initialize(this, this.getRpcService().getScheduledExecutor());
}
//startDispatcherServices
private void startDispatcherServices() throws Exception {
try
/*************************************************
* 注释: 性能监控的
*/
registerDispatcherMetrics(jobManagerMetricGroup);
} catch(Exception e) {
handleStartDispatcherServicesException(e);
}
}
//dispatcherBootstrap.initialize-->launchRecoveredJobGraphs-->dispatcher.runRecoveredJob
void runRecoveredJob(final JobGraph recoveredJob) {
checkNotNull(recoveredJob);
/*************************************************
* 注释: 调用 runJob 运行一个任务
*/
FutureUtils.assertNoException(runJob(recoveredJob).handle(handleRecoveredJobStartError(recoveredJob.getJobID())));
}
// runJob
private CompletableFuture<Void> runJob(JobGraph jobGraph) {
Preconditions.checkState(!jobManagerRunnerFutures.containsKey(jobGraph.getJobID()));
/*************************************************
* 注释: 创建 JobManagerRunner
*/
final CompletableFuture<JobManagerRunner> jobManagerRunnerFuture = createJobManagerRunner(jobGraph);
jobManagerRunnerFutures.put(jobGraph.getJobID(), jobManagerRunnerFuture);
/*************************************************
* 注释: 启动 JobManagerRunner
*/
return jobManagerRunnerFuture.thenApply(
// 提交任务 == start JobManagerRunner
FunctionUtils.uncheckedFunction(this::startJobManagerRunner)
).thenApply(
FunctionUtils.nullFn()
).whenCompleteAsync(
(ignored, throwable) -> {
if(throwable != null) {
jobManagerRunnerFutures.remove(jobGraph.getJobID());
}
}, getMainThreadExecutor());
}
3.总结
- Flink集群的主节点包含的重要组件:ResourceManager、Dispatcher、JobManger以及WebMonitorEndpoint。
- ResourceManager主要负责集群资源的调度管理
- JobManger是主控程序,负责具体的Job执行,在一个集群可能存在多个JobManger同时执行。
- Dispatcher主要是接收用户提交的JobGraph,随后启动一个JobManager负责当前job的执行
- WebMonitorEndpoint里维护了很多的Handler,客户端提交的作业都是由webMonitor来接收,并决定使用哪个Handler进行处理
- Flink集群中主节点的启动主要做了以下的事情
- 解析传入参数以及flink配置文件的参数
- 初始化相关的服务
- commonRpcServices: 基于Akka的RpcService实现
- haServices:HA相关服务
- blobServer:处理大文件的服务
- heartbeatServices:提供心跳所需的所有服务
- metricRegistry:性能监控服务
- archivedExecutionGraphStore:存储ExecutionGraph的可序列化形式
- 启动ResourceManager
- 启动Dispatcher
- 启动WebMonitorEndpoint
- flink集群的主节点中运行着ResourceManager、Dispatcher、WebMonitorEndpoint;当客户端向Flink集群提交作业时(客户端会事先构建好JobGraph),由Dispatcher启动一个新的JobManager(JobMaster),同时JobManager会向ResourceManager申请运行该Job所需的集群资源。
- Flink集群直接点启动的入口是StandaloneSessionClusterEntryPoint
- WebMonitor的启动(standalone):由restEndpointFactory创建restEndpoint实对象,随后启动WebMonitor对象,在该对象中会初始化很多的Handler用来处理各种请求,同时启动Netty服务端,启动完成后会有选举的动作
- ResourceManager的启动:通过resourceManagerFactory.createResourceManager构建resourceManager对象,完成实例化后会执行OnStart()方法,会启动RpcServer服务(主要是为了TaskManager启动完成后进行注册和心跳服务),同时会进行选举,选举成成功会执行LeaderShipService.IsLeader(),且会开启两个心跳服务以及两个定时任务。
- Dispatcher启动:
- 1.通过dispatcherRunnerFactory对象创建DispatcherRunner对象。
- 2.在实例化DispatcherRunner对象时会进行选举,选举成功会执行DispatcherRunner.isLeader()。
- 3.通过DefaultDispatcherRunner.grantLeadership方法构建Dispatcher对象,实例化完成之后会执行OnStart()方法。Dispatcher启动过程中会开启性能监控与引导程序的初始化(恢复中断的作业)。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









