







一、消费者重复消费问题
让每个消息携带一个全局的唯一ID,即可保证消息的幂等性,具体消费过程为:
- 消费者获取到消息后先根据id去查询redis/db是否存在该消息
- 如果不存在,则正常消费,消费完毕后写入redis/db
- 如果存在,则证明消息被消费过,直接丢弃。
生产者
@PostMapping("/send")
public void sendMessage(){
JSONObject jsonObject = new JSONObject();
jsonObject.put("message","Java旅途");
String json = jsonObject.toJSONString();
Message message = MessageBuilder.withBody(json.getBytes()).setContentType(MessageProperties.CONTENT_TYPE_JSON).setContentEncoding("UTF-8").setMessageId(UUID.randomUUID()+"").build();
amqpTemplate.convertAndSend("javatrip",message);
}消费者
@Component
@RabbitListener(queuesToDeclare = @Queue(value = "javatrip", durable = "true"))
public class Consumer {
@RabbitHandler
public void receiveMessage(Message message) throws Exception {
Jedis jedis = new Jedis("localhost", 6379);
String messageId = message.getMessageProperties().getMessageId();
String msg = new String(message.getBody(),"UTF-8");
System.out.println("接收到的消息为:"+msg+"==消息id为:"+messageId);
String messageIdRedis = jedis.get("messageId");
if(messageId == messageIdRedis){
return;
}
JSONObject jsonObject = JSONObject.parseObject(msg);
String email = jsonObject.getString("message");
jedis.set("messageId",messageId);
}
}
二、消息的时序性
拆分多个queue,每个queue一个consumer,就是多一些queue而已,确实是麻烦点;这样也会造成吞吐量下降,可以在消费者内部采用多线程的方式取消费。

三、数据丢失问题

1,生产者发送消息至MQ的数据丢失
解决方法:在生产者端开启comfirm 确认模式,你每次写的消息都会分配一个唯一的 id,
然后如果写入了 RabbitMQ 中,RabbitMQ 会给你回传一个 ack 消息,告诉你说这个消息 ok 了
2,MQ收到消息,暂存内存中,还没消费,自己挂掉,数据会都丢失
解决方式:MQ设置为持久化。将内存数据持久化到磁盘中(
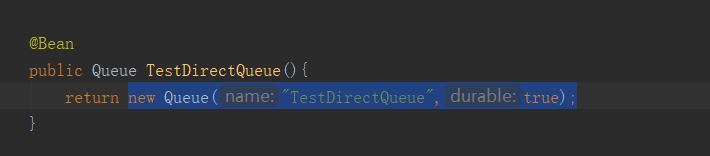 第二个参数就是是否持久化)
第二个参数就是是否持久化)
3,消费者刚拿到消息,还没处理,挂掉了,MQ又以为消费者处理完
解决方式:用 RabbitMQ 提供的 ack 机制,简单来说,就是你必须关闭 RabbitMQ 的自动 ack,可以通过一个 api 来调用就行,然后每次你自己代码里确保处理完的时候,再在程序里 ack 一把。这样的话,如果你还没处理完,不就没有 ack 了?那 RabbitMQ 就认为你还没处理完,这个时候 RabbitMQ 会把这个消费分配给别的 consumer 去处理,消息是不会丢的。
comfirm 确认模式
rabbitmq 整个消息投递的路径为:
producer—>rabbitmq broker—>exchange—>queue—>consumer
⚫ 消息从 producer 到 exchange 则会返回一个 confirmCallback 。
⚫ 消息从 exchange–>queue 投递失败则会返回一个 returnCallback 。
我们将利用这两个 callback 控制消息的可靠性投递
➢ 设置ConnectionFactory的publisher-confirms=“true” 开启 确认模式。
➢ 使用rabbitTemplate.setConfirmCallback设置回调函数。当消息发送到exchange后回
调confirm方法。在方法中判断ack,如果为true,则发送成功,如果为false,则发
送失败,需要处理。
➢ 设置ConnectionFactory的publisher-returns=“true” 开启 退回模式。
➢ 使用rabbitTemplate.setReturnCallback设置退回函数,当消息从exchange路由到
queue失败后,如果设置了rabbitTemplate.setMandatory(true)参数,则会将消息退
回给producer。并执行回调函数returnedMessage。
application.yml
server:
port: 8080
servlet:
context-path: /rabbit
tomcat:
max-http-post-size: 4MB
max-swallow-size: 4MB
spring:
rabbitmq:
host: 172.16.4.203
port: 5672
username: mq
password: mq123
publisher-confirms: true #确认消息已经发生到交换机
publisher-returns: true #确认消息已经发送到队列
RabbitConfig
@Configuration
public class RabbitConfig {
@Bean
public RabbitTemplate createRabbitTemplate(ConnectionFactory connectionFactory){
RabbitTemplate rabbitTemplate = new RabbitTemplate();
rabbitTemplate.setConnectionFactory(connectionFactory);
rabbitTemplate.setMandatory(true);
rabbitTemplate.setConfirmCallback(new RabbitTemplate.ConfirmCallback(){
@Override
public void confirm(CorrelationData correlationData, boolean ack, String cause) {
System.out.println("ConfirmCallback: "+"相关数据:"+correlationData);
System.out.println("ConfirmCallback: "+"确认情况:"+ack);
System.out.println("ConfirmCallback: "+"原因:"+cause);
}
});
rabbitTemplate.setReturnCallback(new RabbitTemplate.ReturnCallback() {
@Override
public void returnedMessage(Message message, int replyCode, String replyText, String exchange, String routingKey) {
System.out.println("ReturnCallback: "+"消息:"+message);
System.out.println("ReturnCallback: "+"回应码:"+replyCode);
System.out.println("ReturnCallback: "+"回应信息:"+replyText);
System.out.println("ReturnCallback: "+"交换机:"+exchange);
System.out.println("ReturnCallback: "+"路由键:"+routingKey);
}
});
return rabbitTemplate;
}
}ack 机制(https://www.cnblogs.com/milicool/p/9662447.html)
配置
# 开启 ack 手动确认 simple: acknowledge-mode: manual # 开启 ack 手动确认

生产者
@Component
public class Producer {
@Autowired
private RabbitTemplate rabbitTemplate;
/**
* 给hello队列发送消息
*/
public void send() {
for (int i =0; i< 100; i++) {
String msg = "hello, 序号: " + i;
System.out.println("Producer, " + msg);
rabbitTemplate.convertAndSend("queue-test", msg);
}
}
}消费者
@Component
public class Comsumer {
private Logger log = LoggerFactory.getLogger(Comsumer.class);
@RabbitListener(queues = "queue-test")
public void process(Message message, Channel channel) throws IOException {
// 采用手动应答模式, 手动确认应答更为安全稳定
channel.basicAck(message.getMessageProperties().getDeliveryTag(), true);
log.info("receive: " + new String(message.getBody()));
}
}















 1456
1456











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









