







概述
Redis(Remote Dictionary Server) 是一个使用 C 语言编写的,开源的(BSD许可)高性能非关系型(NoSQL)的键值对数据库。
Redis 可以存储键和五种不同类型的值之间的映射。键的类型只能为字符串,值支持五种数据类型:字符串、列表、集合、散列表、有序集合。
Redis 的数据是存在内存中的,读写速度非常快,被广泛应用于缓存方向,每秒可以处理超过 10万次读写操作,是已知性能最快的Key-Value DB。另外,Redis 也经常用来做分布式锁。除此之外,Redis 支持事务 、持久化、LUA脚本、LRU驱动事件、多种集群方案。
安装Redis
1、下载安装并解压到本地 (下载地址:Redis)
2、启动服务:右键以管理员身份打开–”redis-server.exe“
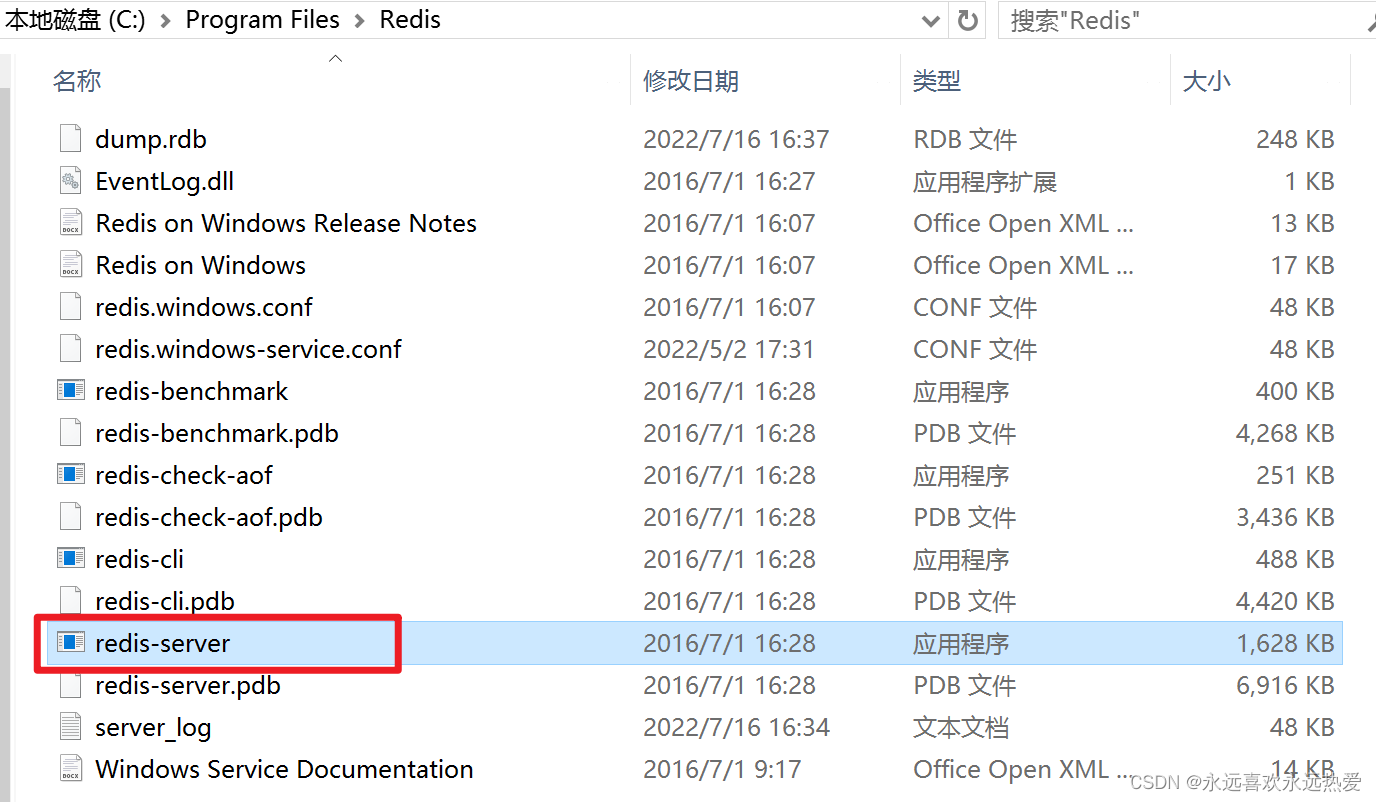
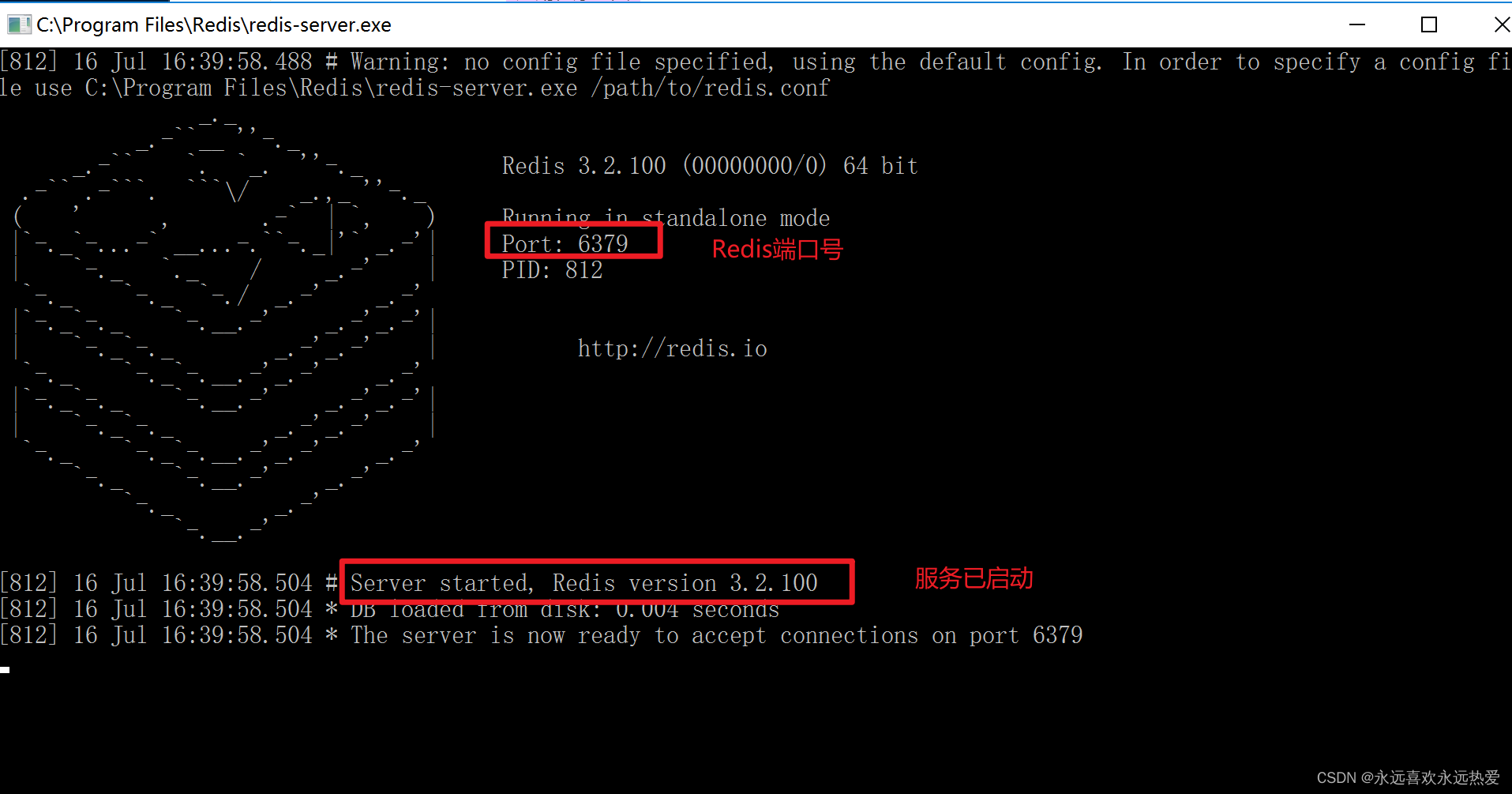
3、连接测试:双击“redis-cli.exel”连接Redis

Redis作用
Redis常用命令
127.0.0.1:6379> ping #查看当前连接是否正常,正常返回PONG
PONG
127.0.0.1:6379> clear #清楚当前控制台(为了更好的看到下面输入的命令)
127.0.0.1:6379> keys * #查看当前库里所有的key
1) "db"
127.0.0.1:6379> FLUSHALL #清空所有库的内容
OK
127.0.0.1:6379> keys *
(empty array)
127.0.0.1:6379> set name dingdada #添加一个key为‘name’ value为‘dingdada’的数据
OK
127.0.0.1:6379> get name #查询key为‘name’的value值
"dingdada"
127.0.0.1:6379> keys *
1) "name"
127.0.0.1:6379> set name1 dingdada2
OK
127.0.0.1:6379> get name1
"dingdada2"
127.0.0.1:6379> keys * #查看当前库里所有的key
1) "name1"
2) "name"
127.0.0.1:6379> EXISTS name #判断当前key是否存在
(integer) 1
127.0.0.1:6379> move name 1 #移除当前库1的key为‘name‘的数据
(integer) 1
127.0.0.1:6379> keys *
1) "name1"
127.0.0.1:6379> FLUSHALL #再次清空所有库的内容
OK
## 多加几条数据 下面测试设置key的过期时间
127.0.0.1:6379> set name dingdada
OK
127.0.0.1:6379> set name1 dingdada1
OK
127.0.0.1:6379> set name2 dingdada2
OK
127.0.0.1:6379> EXPIRE name 15 #设置key为’name‘的数据过期时间为15秒 单位seconds
(integer) 1
127.0.0.1:6379> ttl name #查看当前key为’name‘的剩余生命周期时间
(integer) 13
127.0.0.1:6379> ttl name
(integer) 12
127.0.0.1:6379> ttl name
(integer) 11
127.0.0.1:6379> ttl name
(integer) 8
127.0.0.1:6379> ttl name
(integer) 6
127.0.0.1:6379> ttl name
(integer) 3
127.0.0.1:6379> ttl name
(integer) 2
127.0.0.1:6379> ttl name
(integer) 1
127.0.0.1:6379> ttl name
(integer) 0
127.0.0.1:6379> ttl name #如若返回-2,证明key已过期
(integer) -2
127.0.0.1:6379> get name #再次查询即为空
(nil)
127.0.0.1:6379> type name1
string
127.0.0.1:6379>
Redis五大数据类型
1、String(字符串)
2、List(列表)
3、Set(集合)元素唯一不重复
4、Hash(哈希)
5、zSet(有序集合)
优缺点
优点
- 读写性能优异, Redis能读的速度是110000次/s,写的速度是81000次/s。
- 支持数据持久化,支持AOF和RDB两种持久化方式。
- 支持事务,Redis的所有操作都是原子性的,同时Redis还支持对几个操作合并后的原子性执行。
- 数据结构丰富,除了支持string类型的value外还支持hash、set、zset、list等数据结构。
- 支持主从复制,主机会自动将数据同步到从机,可以进行读写分离。
缺点
- 数据库容量受到物理内存的限制,不能用作海量数据的高性能读写,因此Redis适合的场景主要局限在较小数据量的高性能操作和运算上。
- Redis 不具备自动容错和恢复功能,主机从机的宕机都会导致前端部分读写请求失败,需要等待机器重启或者手动切换前端的IP才能恢复。
- 主机宕机,宕机前有部分数据未能及时同步到从机,切换IP后还会引入数据不一致的问题,降低了系统的可用性。
- Redis
较难支持在线扩容,在集群容量达到上限时在线扩容会变得很复杂。为避免这一问题,运维人员在系统上线时必须确保有足够的空间,这对资源造成了很大的浪费。
为什么要用 Redis /为什么要用缓存
主要从“高性能”和“高并发”这两点来看待这个问题。
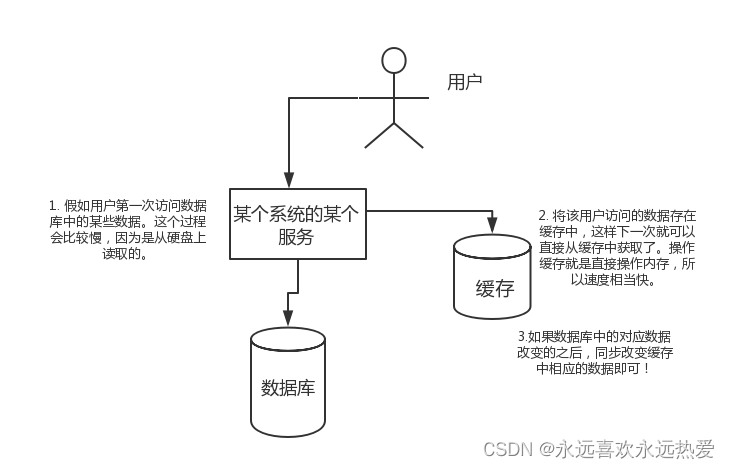
高性能:
假如用户第一次访问数据库中的某些数据。这个过程会比较慢,因为是从硬盘上读取的。将该用户访问的数据存在数缓存中,这样下一次再访问这些数据的时候就可以直接从缓存中获取了。操作缓存就是直接操作内存,所以速度相当快。如果数据库中的对应数据改变的之后,同步改变缓存中相应的数据即可!
高并发:
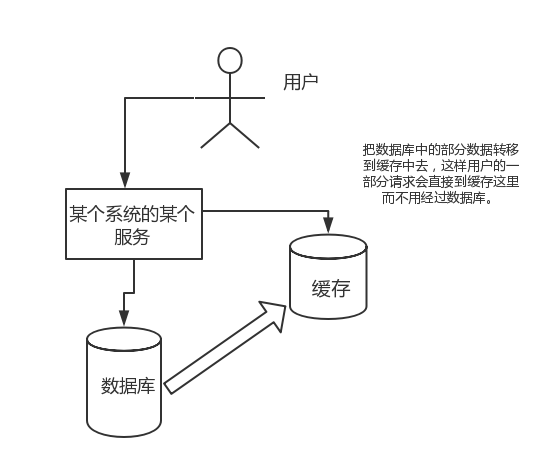
直接操作缓存能够承受的请求是远远大于直接访问数据库的,所以我们可以考虑把数据库中的部分数据转移到缓存中去,这样用户的一部分请求会直接到缓存这里而不用经过数据库。
Redis持久化
什么是Redis持久化?
持久化就是把内存的数据写到磁盘中去,防止服务宕机了内存数据丢失。
Redis 的持久化机制是什么?各自的优缺点?
Redis 提供两种持久化机制 RDB(默认) 和 AOF 机制:
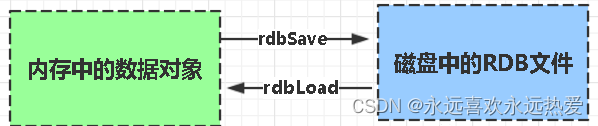
RDB:是Redis DataBase缩写快照
RDB是Redis默认的持久化方式。按照一定的时间将内存的数据以快照的形式保存到硬盘中,对应产生的数据文件为dump.rdb。通过配置文件中的save参数来定义快照的周期。














 76
76











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









