







一直都特别好奇加的各种群每天发的简版新闻是从哪里获取的,
自己也来爬个热搜试试。
需求就是爬了一个百度热搜榜top30~然后把它存在本地excel里
准备工作
pip install requests
pip install re
pip install xlwt
1.拿到热点的标题
我们要访问的地址是
https://top.baidu.com/board?tab=realtime
打开以后,按F12,可以看到标题的格式都是如下图这样的结构

这里讲一下正则表达式的基础内容
- . 表示匹配后一位
- *是通配符,匹配若干个字符,也包含0
- ?是通配符,匹配0个或1个字符
- 括号表示只返回匹配值
举例: A (.?) B提取AB中间的内容
在这个格式里,我们可以用 (.?) 直接拿到标题
title = re.findall('class="c-single-text-ellipsis"> (.*?)<' , reps.text)
这样拿到的数据是一个列表,格式是[‘’,‘’,‘’]
2. 拿到热点的访问地址
除了拿标题,我们还可以把网址也提取出来,标题的格式如下
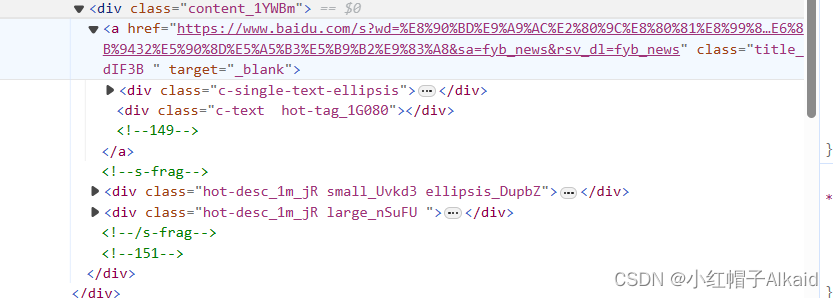
也可以用正则直接拿出来
add = re.findall('href="(.*?)"',reps.text)
拿到的数据也是一个列表。但是这个地址并不都是我想要的
把他打印出来,
for i in range(0,len(add)):
a=a+1
print(a,add[i])
发现前面后面都有一些不需要的网址,
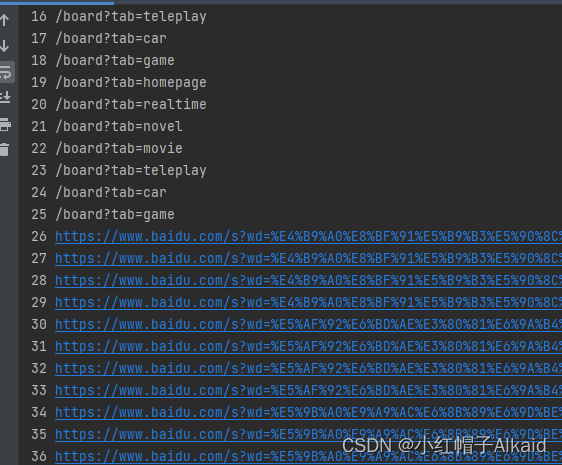
然后观察发现地址很多是重复的,所以也需要在拿出想要的数据后,做一个去重:
a=0
add_new=[] #申明一个列表
for i in range(25,len(add)-7):#匹配到很多地址,只拿需要的部分
a=a+1
add_new.append(add[i])#把地址装进一个列表
add_new01 =[]#重新定义一个列表来装去重之后的数据
for i in add_new:
if i not in add_new01:
add_new01.append(i)
3.将标题和地址组装起来
因为就俩数据,可以直接使用字典组装
dic1={}
for i in range(0,30):
dic1[title[i]]=add_new01[i]#将标题和地址一一对应
4.保存excel
首先创建一个对象
excel1= xlwt.Workbook() #创建workbook对象
然后是工作表
wooksheet= excel1.add_sheet('百度热榜top30', cell_overwrite_ok=True) #创建工作表
定义列名,然后写入标题是第0行,第0列,网址是第0行第1列
head = ['标题','网址']
for h in range(0,2):
wooksheet.write(0,h,head[h])
然后把第三步已经组装好的标题和地址写入
因为刚刚列名已经把第0行用了,所以现在要从第一行row=1开始
row=1
for k, v in dic1.items():
wooksheet.write(row,0,k) #把标题写入
wooksheet.write(row,1,v) #把地址写入
row += 1 #换行
保存,地址可以写相对也可以写绝对
excel1.save('./百度热搜top30.xls')#定义保存的地址
就此执行之后,就在目录下生成了xls文件
打开检查一下,爬的没问题
5.遇到的问题
我觉得最大的问题就是拿网址那里,观察了几天,发现有时候前面不需要的网址的个数是会变的。暂时没想到什么好办法。。或许可以通过长度来判断?…
6. 完整代码
以下是完整代码~
# -*- coding: utf-8 -*-#
import requests
import re
import xlwt
url = 'https://top.baidu.com/board?tab=realtime' # 要爬取的网页链接
reps = requests.get(url)
#1.对标题进行处理
title = re.findall('class="c-single-text-ellipsis"> (.*?)<' , reps.text)
#2. 对数据地址进行处理
add = re.findall('href="(.*?)"',reps.text)
a=0
add_new=[] #申明一个列表
for i in range(33,len(add)-7):#匹配到很多地址,只拿需要的部分
a=a+1
add_new.append(add[i])#把地址装进一个列表
#add_new=list(set(add_new))#用集合的方式去重.得到新的去重了的地址add_new,格式是列表。后来发现这种方式会打乱顺序,所以注释掉了
add_new01 =[]#重新定义一个列表来装去重之后的数据
for i in add_new:
if i not in add_new01:
add_new01.append(i)
#3.创建一个字典组装标题和地址
dic1={}
for i in range(0,30):
dic1[title[i]]=add_new01[i]#将标题和地址一一对应
#4.保存到excel
excel1= xlwt.Workbook() #创建workbook对象
wooksheet= excel1.add_sheet('百度热榜top30', cell_overwrite_ok=True) #创建工作表
head = ['标题','网址']
for h in range(0,2):
wooksheet.write(0,h,head[h])
row=1
for k, v in dic1.items():
wooksheet.write(row,0,k) #把标题写入
wooksheet.write(row,1,v) #把地址写入
row += 1 #换行
excel1.save('百度热搜top30.xls')#定义保存的地址














 600
600











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









