







 本文提出了一种名为结构正则化深度聚类(SRDC)的方法,用于无监督域适应问题。SRDC利用源域和目标域之间的结构相似性,通过对目标数据进行判别性聚类来揭示其内在的判别性,同时避免了传统域对齐方法可能破坏目标数据区分性的风险。通过深度网络的特征嵌入和分类器,SRDC结合了源数据的标签信息进行结构源正则化,从而提高了目标域的分类性能。在几个基准数据集上的实验表明,SRDC在无显式域对齐的情况下优于现有的域适应方法。
本文提出了一种名为结构正则化深度聚类(SRDC)的方法,用于无监督域适应问题。SRDC利用源域和目标域之间的结构相似性,通过对目标数据进行判别性聚类来揭示其内在的判别性,同时避免了传统域对齐方法可能破坏目标数据区分性的风险。通过深度网络的特征嵌入和分类器,SRDC结合了源数据的标签信息进行结构源正则化,从而提高了目标域的分类性能。在几个基准数据集上的实验表明,SRDC在无显式域对齐的情况下优于现有的域适应方法。
研究问题:
主流的UDA方法学习两个域之间的对齐特征,使得在源特征上训练的分类器可以很容易地应用到目标特征上,存在破坏目标数据内在判别性的潜在风险。
研究假设:
- 领域判别假设:在各个领域中存在数据判别的内在结构,即源域或目标域中的数据都对应于共享标签空间进行判别聚类。(即数据分布有其内部的特点)
- 类紧密度假设:同一类别标签对应的两个域的聚类在几何上是紧密的。(即源域与目标域类分布有相似性)
研究思路及方法:
没有显式域对齐的情况下,利用源域和目标域之间的结构相似性,对目标域进行聚类。初步理解是用源域辅助目标域分类。
研究基础:
深度聚类方法:DEPICT方法(Deep clustering via joint convolutional autoencoder embedding and relative entropy minimization,2017)
改进:用源数据的真值标签形成的辅助分布代替辅助分布。
备注:
大概阅读了文章,里面提到的“对中间网络特征进行聚类来增强目标判别,通过对发散性较小的源实例进行软选择来增强结构正则化”没仔细看怎么实现的。
全文翻译如下:
摘要
无监督域适应( UDA )是给定源域上分布偏离目标域的有标签数据,对目标域上的无标签数据进行预测。主流的UDA方法学习两个域之间的对齐特征,使得在源特征上训练的分类器可以很容易地应用到目标特征上。然而,这样的迁移策略存在破坏目标数据内在鉴别力的潜在风险。为了缓解这种风险,我们受结构域相似性假设的启发,提出通过对目标数据的判别性聚类来直接揭示目标的内在判别性。我们使用结构源正则化来约束聚类解,这依赖于我们假设的结构域相似性。在技术上,我们使用了一种灵活的基于深度网络的判别聚类框架,最小化网络的预测标签分布与引入的辅助标签分布之间的KL散度;用源数据的真值标签形成的辅助分布代替辅助分布,通过简单的联合网络训练策略实现结构源正则化。我们将所提出的方法称为结构正则化深度聚类( Structurally Regularized Deep Clustering,SRDC ),其中我们还通过中间网络特征的聚类来增强目标判别,并通过对较少发散的源示例的软选择来增强结构正则化。仔细的消融研究表明了我们提出的SRDC的有效性。值得注意的是,在没有显式域对齐的情况下,SRDC在三个UDA基准测试集上优于所有现有方法。
1. Introduction
给定源域上的有标签数据,无监督域适应( UDA )是对目标域上的无标签数据在相同的标签空间进行预测,其中两个域之间可能存在分歧。主流方法受到经典UDA理论[ 2、3、40]的启发,该理论规定了包含域散度的学习边界,其大小取决于分类器的特征空间和假设空间。因此,这些方法(例如,最近一些基于对抗训练的深度网络[ 16 , 48 ])努力学习两个域之间的对齐特征,以便在源特征上训练的分类器可以很容易地应用到目标特征上。尽管这些方法取得了令人印象深刻的结果,但正如[ 9、50、69]所讨论的那样,它们具有破坏目标数据判别的内在结构的潜在风险。[ 9、50]试图缓解这种风险,但在他们提出的解决方案中仍然追求显式的域对齐。
为了解决这个问题,我们首先将UDA问题[ 2、50]中领域紧密度的一般假设实例化为结构领域相似度,即领域区分性和类别紧密度的两个概念- -前者假设在单个领域中存在具有区分性的数据簇的内在结构,后者假设两个领域中对应于相同类别标签的簇是几何紧密的。这一假设促使我们考虑一种UDA方法,该方法通过对目标数据进行判别性聚类来直接揭示数据的内在判别性,我们提出使用结构源正则化来约束聚类解。
在各种基于深度网络的聚类算法[ 4、8、14、61]中,我们选择了一个简单但灵活的非生成式框架[ 14 ],通过最小化网络的预测标签分布和引入的辅助标签分布之间的KL散度来进行判别性聚类。结构源正则化简单地通过一个简单的联合网络训练策略来实现,通过将辅助分布替换为源数据的真实标签所形成的辅助分布。我们将提出的方法称为结构正则化深度聚类( SRDC )。在SRDC中,我们还通过对中间网络特征进行聚类来增强目标判别,通过对发散性较小的源实例进行软选择来增强结构正则化。我们注意到,最近的一些UDA方法[ 13,27,41,51]也考虑了目标数据的聚类;然而,它们仍然通过聚类中心/样本对齐在两个域之间进行显式的特征对齐,从而容易出现上述受损的内在目标判别风险。在基准UDA数据集上的实验表明了我们提出的SRDC的有效性。我们最后将我们的贡献总结如下。
- 为了解决显式学习领域对齐特征破坏数据本征区分度的潜在问题,本文提出了一种源正则化的深度判别聚类方法,以直接揭示目标数据之间的本征区分度。该方法的动机是我们假设两个域之间的结构相似,为此我们将提出的方法称为结构正则化深度聚类( Structurally Regularized Deep Clustering,SRDC )。
- 为了在技术上实现SRDC,我们使用了一种灵活的深度聚类框架,该框架首先引入一个辅助分布,然后最小化引入分布与网络预测标签分布之间的KL散度;用源数据的真实标签代替辅助分布,通过简单的联合网络训练策略实现结构源正则化。在SRDC中,我们还设计了有用的成分,通过对中间网络特征进行聚类来增强目标区分性,并通过对发散性较小的源实例进行软选择来增强结构正则化。
- 我们在基准UDA数据集上进行了细致的消融研究,验证了SRDC中提出的单个成分的有效性。值得注意的是,在没有显式域对齐的情况下,我们提出的SRDC在基准数据集上优于所有现有的方法。
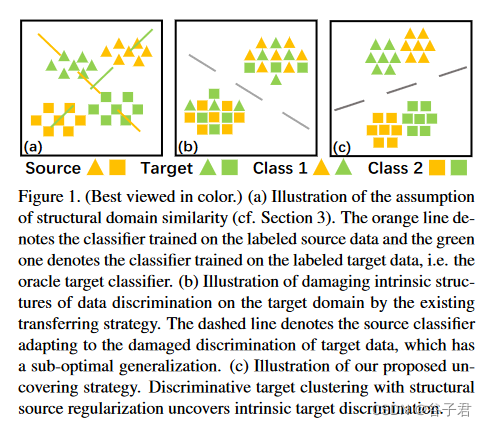
见图1。(最好在色彩上观看。) ( a )结构域相似度( cf .。第三节)假设的说明。橙色线条表示在标记源数据上训练的分类器,绿色线条表示在标记目标数据上训练的分类器,即oracle目标分类器。( b )举例说明了现有迁移策略对目标域数据判别的内在结构的破坏。虚线表示适应目标数据受损判别的源分类器,具有次优泛化性。( c )展示了我们提出的揭开策略。基于结构源正则化的判别目标聚类揭示了目标的内在判别性。
2. Related works
基于对齐的域适应
一个典型的工作[ 16、43、53、63]利用域对抗任务将源域和目标域作为一个整体进行对齐,这样类标签可以从源域转移到未标记的目标域。另一类典型的工作是直接最小化由各种度量值度量的域偏移,例如最大均值差异( MMD ) [ 34、36、37]。这些方法都是基于领域级别的领域对齐。为了实现类级域对齐,[ 35、42]的工作利用了特征表示和类预测的乘法交互,使得域判别器能够感知分类边界。基于集成任务和领域分类器[ 52 ],鼓励对任何输入实例的类别和领域预测之间存在相互抑制的关系。[ 7、13、41、59]的工作是在特征空间中对齐每个共享类的标记源质心和伪标记目标质心。一些工作[ 31、47、48]使用两个领域的单独任务分类器来检测非鉴别特征,并反向学习一个鉴别特征提取器。[ 30,56,57]的一些工作将注意力集中在可迁移区域上,以得到领域不变的分类模型。为了获得目标鉴别特征,[ 28、49]通过GANs从两个域的原始输入数据中生成合成图像[ 19 ]。最近的工作[ 9 ]改进了对抗特征自适应,其中目标数据的判别结构可能会恶化[ 69 ]。文献[ 60 ]的工作将两个领域的特征范数适应于较大的取值范围,使得学习到的特征不仅具有任务区分性,而且具有领域不变性。
基于聚类的领域自适应。
聚类假设认为分类边界不应该穿过高密度区域,而是位于低密度区域[ 6 ]。为了强化聚类假设,条件熵最小化[ 20、32]在UDA社区[ 11、44、45、50、51、60、64、68]中被广泛使用。文献[ 27 ]的工作采用球形K - means分配目标标签。最近的工作[ 13 ]采用了基于Fisher - like准则的深度聚类损失[ 38 ]。然而,他们只是将目标聚类作为一种增量技术来改进显式特征对齐。文献[ 50 ]的前期工作是基于互信息最大化的聚类准则,仍然显式地强制域对齐。相比之下,在没有显式领域对齐的情况下,SRDC旨在通过结构源正则化的判别性目标聚类来揭示目标的内在判别性。
潜在域发现。
潜在领域发现方法[ 10,18,22,39]侧重于在假设数据实际上可能包含多个不同分布的情况下捕获源、目标数据或混合数据的潜在结构。我们提出的SRDC与这些方法具有相同的动机,但不同之处在于利用源域和目标域之间的结构相似性,通过结构源正则化深度判别目标聚类来揭示目标类之间的内在区别。
3 传递与揭示内在目标辨别的策略
考虑具有
n
s
n_s
ns个标记样本
{
(
x
j
s
,
y
j
s
)
}
j
=
1
n
s
\left\{\left(x_j^s, y_j^s\right)\right\}_{j=1}^{n_s}
{(xjs,yjs)}j=1ns的源域
S
\mathcal{S}
S 和具有
n
t
n_t
nt 个未标记样本
{
x
i
t
}
i
=
1
n
t
\left\{\boldsymbol{x}_i^t\right\}_{i=1}^{n_t}
{xit}i=1nt的目标域
T
\mathcal{T}
T .无监督域适应( UDA )假设
S
\mathcal{S}
S和
T
\mathcal{T}
T之间有一个共享的标签空间
Y
\mathcal{Y}
Y。令
∣
Y
∣
=
K
|\mathcal{Y}|=K
∣Y∣=K,对于任意源实例
x
s
x^s
xs,有
y
s
∈
{
1
,
2
,
…
,
K
}
y^s \in\{1,2, \ldots, K\}
ys∈{1,2,…,K}。直推式UDA的目标是通过学习一个将任意输入实例
x
∈
X
x \in \mathcal{X}
x∈X提升到特征空间
Z
\mathcal{Z}
Z的特征嵌入函数
φ
:
X
→
Z
\varphi: \mathcal{X} \rightarrow \mathcal{Z}
φ:X→Z 和一个分类器
f
:
Z
→
R
K
f: \mathcal{Z} \rightarrow \mathbb{R}^K
f:Z→RK来预测
{
y
^
i
t
}
i
=
1
n
t
\left\{\hat{y}_i^t\right\}_{i=1}^{n_t}
{y^it}i=1nt of
{
x
i
l
}
i
=
1
n
t
\left\{x_i^l\right\}_{i=1}^{n_t}
{xil}i=1nt 。与直推式UDA略有不同的是,直推式UDA是在从相同
T
\mathcal{T}
T中采样的保留实例上测量学习到的
φ
(
⋅
)
\varphi(\cdot)
φ(⋅) 和
f
(
⋅
)
f(\cdot)
f(⋅)的性能。这种细微的差别其实很重要,因为我们期望将学习到的
φ
(
⋅
)
\varphi(\cdot)
φ(⋅)和
f
(
⋅
)
f(\cdot)
f(⋅)作为现成的模型,并且在学习不同的源域时,我们期望它们是一致的。
在UDA中,域紧密度一般被假设为理论上的[ 2、40]或者直观上的[ 50 ]。在这项工作中,我们将文献[ 50 ]中的假设总结为源域和目标域之间的结构相似性,其中包括如下的域区分和类贴近度的概念,如图1所示。
- 领域判别假设在各个领域中存在数据判别的内在结构,即源域或目标域中的数据都对应于共享标签空间进行判别聚类。
- 类紧密度假设同一类别标签对应的两个域的聚类在几何上是紧密的。
基于这些假设,许多现有的工作[ 16、35、42、48、53、66]采取了在两个域之间学习对齐特征表示的迁移策略,使得在源特征上训练的分类器可以很容易地应用到目标特征上。然而,正如[ 9、50、69]最近的工作所讨论的那样,这种策略存在破坏目标域上固有的数据区分性的潜在风险。图1中也给出了这种破坏的说明。我们注意到,更重要的是,适应目标数据受损区分的分类器对归纳式UDA任务的效果较差,因为它们与oracle目标分类器偏离太大,即在带有真值标签的目标数据上训练的理想分类器。
基于上述分析,我们有动机通过对目标数据进行判别式聚类来直接揭示内在的目标区分度。为了利用标记的源数据,我们提出使用结构源正则化来约束聚类解,该正则化依赖于我们假设的跨域结构相似性。第4节给出了本文方法的详细介绍,图1给出了示意图。我们注意到,最近的一些方法[ 13,27,41,51]也考虑了目标数据的聚类;然而,它们仍然通过聚类中心/样本的对齐来进行跨领域的显式特征对齐,从而容易出现上述受损的内在目标判别风险。
4 .基于结构源正则化的判别目标聚类
我们将特征嵌入函数
φ
(
⋅
;
θ
)
\varphi(\cdot ; \boldsymbol{\theta})
φ(⋅;θ)和分类器
f
(
⋅
;
ϑ
)
f(\cdot ; \vartheta)
f(⋅;ϑ) 参数化为深度网络[ 21,25,26,65],其中
{
θ
,
ϑ
}
\{\boldsymbol{\theta}, \boldsymbol{\vartheta}\}
{θ,ϑ}收集网络参数。为了简单起见,我们也将它们写成
φ
(
⋅
)
\varphi(\cdot)
φ(⋅)和
f
(
⋅
)
f(\cdot)
f(⋅),并用
f
∘
φ
f \circ \varphi
f∘φ 表示整个网络。对于输入实例
x
x
x,网络计算特征表示
z
=
φ
(
x
)
z=\varphi(x)
z=φ(x),并在最后的softmax操作后输出概率向量
p
=
softmax
(
f
(
z
)
)
∈
[
0
,
1
]
K
\boldsymbol{p}=\operatorname{softmax}(f(z)) \in[0,1]^K
p=softmax(f(z))∈[0,1]K。
如第3节所述,为了揭示目标域的内在区分性,我们选择从源域直接对目标实例进行结构正则化聚类。在各种聚类方法[ 4、8、14、61]中,我们选择了一个灵活的深度判别聚类框架[ 14 ],该框架最小化了网络的预测标签分布和引入的辅助标签分布之间的KL散度;通过将辅助分布替换为源数据真实标签的辅助分布,我们可以通过简单的网络联合训练策略轻松地实现结构源正则化,我们称之为结构正则化深度聚类( SRDC )。在SRDC中,我们还通过对中间网络特征进行聚类来增强目标判别,通过对发散性较小的源实例进行软选择来增强结构正则化。
4 . 1 .深度判别目标聚类
对于未标记的目标数据
{
x
i
t
}
i
=
1
n
t
\left\{x_i^t\right\}_{i=1}^{n_t}
{xit}i=1nt,网络经过softmax操作后,预测得到我们统称为Pt的概率向量
{
p
i
t
}
i
=
1
n
ℓ
\left\{p_i^t\right\}_{i=1}^{n_{\ell}}
{pit}i=1nℓ。对于目标实例
x
i
t
x_i^t
xit,我们也将
p
i
t
\boldsymbol{p}_i^t
pit的
k
t
h
k^{t h}
kth元素写为
p
i
,
k
t
p_{i, k}^t
pi,kt。
P
t
\boldsymbol{P}^t
Pt从而近似得到网络对
T
\mathcal{T}
T样本的预测标签分布。与[ 14、24]类似,我们首先引入一个辅助对应物
Q
t
Q^t
Qt,所提出的SRDC在( 1 )更新
Q
t
Q^t
Qt和( 2 )中交替使用更新后的
Q
t
Q^t
Qt作为标签训练网络更新参数
{
θ
,
ϑ
}
\{\theta, \vartheta\}
{θ,ϑ},优化了深度判别聚类的后续目标。
min
Q
t
,
{
θ
,
ϑ
}
L
f
∘
φ
t
=
KL
(
Q
t
∥
P
t
)
+
∑
k
=
1
K
ϱ
k
t
log
ϱ
k
t
\min _{\boldsymbol{Q}^t,\{\boldsymbol{\theta}, \boldsymbol{\vartheta}\}} \mathcal{L}_{f \circ \varphi}^t=\operatorname{KL}\left(\boldsymbol{Q}^t \| \boldsymbol{P}^t\right)+\sum_{k=1}^K \varrho_k^t \log \varrho_k^t
Qt,{θ,ϑ}minLf∘φt=KL(Qt∥Pt)+k=1∑Kϱktlogϱkt
其中
ϱ
k
t
=
1
n
t
∑
i
=
1
n
t
q
i
,
k
t
\varrho_k^t=\frac{1}{n_t} \sum_{i=1}^{n_t} q_{i, k}^t
ϱkt=nt1∑i=1ntqi,kt和( 1 )式中的第二项用于平衡
{
q
i
t
}
i
=
1
n
t
\left\{q_i^t\right\}_{i=1}^{n_t}
{qit}i=1nt中的簇分配- -否则将得到通过移除簇边界合并簇的退化解[ 29 ]。此外,它鼓励目标域上标签分布的熵最大化,即鼓励簇大小平衡。由于缺乏关于目标标签分布的先验知识,我们简单地依靠第二项来解释一个统一的分布。第一项计算离散概率分布
P
t
P^t
Pt and
Q
t
Q^t
Qt 之间的KL散度
K
L
(
Q
t
∥
P
t
)
=
1
n
t
∑
i
=
1
n
t
∑
k
=
1
K
q
i
,
k
t
log
q
i
,
k
t
p
i
,
k
t
.
\mathrm{KL}\left(\boldsymbol{Q}^t \| \boldsymbol{P}^t\right)=\frac{1}{n_t} \sum_{i=1}^{n_t} \sum_{k=1}^K q_{i, k}^t \log \frac{q_{i, k}^t}{p_{i, k}^t} .
KL(Qt∥Pt)=nt1i=1∑ntk=1∑Kqi,ktlogpi,ktqi,kt.
更具体地说,目标( 1 )的优化采取以下交替步骤。
- 辅助分布更新。固定网络参数
{
θ
,
ϑ
}
\{\boldsymbol{\theta}, \boldsymbol{\vartheta}\}
{θ,ϑ}(目标实例的
{
p
i
t
}
i
=
1
n
t
\left\{\boldsymbol{p}_i^t\right\}_{i=1}^{n_t}
{pit}i=1nt也是固定的)。通过将( 1 )的近似梯度设为零,我们有如下的闭式解[ 14 ]
q i , k ι = p i , k t / ( ∑ i ′ = 1 n t p i ′ , k t ) 1 2 ∑ k ′ = 1 K p i , k ′ t / ( ∑ i ′ = 1 n t p i ′ , k ′ t ) 1 2 q_{i, k}^\iota=\frac{p_{i, k}^t /\left(\sum_{i^{\prime}=1}^{n_t} p_{i^{\prime}, k}^t\right)^{\frac{1}{2}}}{\sum_{k^{\prime}=1}^K p_{i, k^{\prime}}^t /\left(\sum_{i^{\prime}=1}^{n_t} p_{i^{\prime}, k^{\prime}}^t\right)^{\frac{1}{2}}} qi,kι=∑k′=1Kpi,k′t/(∑i′=1ntpi′,k′t)21pi,kt/(∑i′=1ntpi′,kt)21 - 网络更新。通过固定
Q
t
Q^t
Qt,这一步等价于使用
Q
t
Q^t
Qt作为标签通过交叉熵损失训练网络,从而产生
min θ , ϑ − 1 n l ∑ i = 1 n t ∑ k = 1 K q i , k t log p i , k t \min _{\boldsymbol{\theta}, \boldsymbol{\vartheta}}-\frac{1}{n_l} \sum_{i=1}^{n_t} \sum_{k=1}^K q_{i, k}^t \log p_{i, k}^t θ,ϑmin−nl1i=1∑ntk=1∑Kqi,ktlogpi,kt
在这项工作中,我们还通过在特征空间 Z \mathcal{Z} Z中的判别性聚类来增强目标判别性。更具体地说,设 { μ k } k = 1 K \left\{\boldsymbol{\mu}_k\right\}_{k=1}^K {μk}k=1K是源数据和目标数据在空间 Z \mathcal{Z} Z中的可学习的聚类中心。根据文献[ 58 ],我们定义了实例特征 z i t = φ ( x i t ) z_i^t=\varphi\left(x_i^t\right) zit=φ(xit)在空间 Z \mathcal{Z} Z中基于实例到中心距离的软聚类分配概率向量 p ~ i t \widetilde{\boldsymbol{p}}_i^t p it,其第 k t h k^{t h} kth个元素定义为
p ~ i , k ι = exp ( ( 1 + ∥ z i ι − μ k ∥ 2 ) − 1 ) ∑ k ′ = 1 K exp ( ( 1 + ∥ z i t − μ k ′ ∥ 2 ) − 1 ) . \widetilde{p}_{i, k}^\iota=\frac{\exp \left(\left(1+\left\|z_i^\iota-\mu_k\right\|^2\right)^{-1}\right)}{\sum_{k^{\prime}=1}^K \exp \left(\left(1+\left\|z_i^t-\boldsymbol{\mu}_{k^{\prime}}\right\|^2\right)^{-1}\right)} . p i,kι=∑k′=1Kexp((1+∥zit−μk′∥2)−1)exp((1+∥ziι−μk∥2)−1).
我们把 { p ~ i t } i = 1 n t \left\{\widetilde{\boldsymbol{p}}_i^t\right\}_{i=1}^{n_t} {p it}i=1nt 统称为 P ~ t \widetilde{\boldsymbol{P}}^t P t。通过引入相应的辅助分布 Q ~ t \widetilde{Q}^t Q t,我们有如下目标在空间 Z \mathcal{Z} Z中进行深度判别聚类
min Q ~ t , θ , { μ k t } k = 1 K L φ t = KL ( Q ~ t ∥ P ~ t ) + ∑ k = 1 K ϱ ~ k t log ϱ ~ k t \min _{\widetilde{\boldsymbol{Q}}^t, \boldsymbol{\theta},\left\{\boldsymbol{\mu}_k^t\right\}_{k=1}^K} \mathcal{L}_{\varphi}^t=\operatorname{KL}\left(\widetilde{\boldsymbol{Q}}^t \| \widetilde{\boldsymbol{P}}^t\right)+\sum_{k=1}^K \widetilde{\varrho}_k^t \log \widetilde{\varrho}_k^t Q t,θ,{μkt}k=1KminLφt=KL(Q t∥P t)+k=1∑Kϱ ktlogϱ kt
其中 ϱ ~ k t = 1 n t ∑ i = 1 n t q ~ i , k t \tilde{\varrho}_k^t=\frac{1}{n_t} \sum_{i=1}^{n_t} \widetilde{q}_{i, k}^t ϱ~kt=nt1∑i=1ntq i,kt。目标( 5 )可以按照与( 1 )相同的交替方式进行优化,推导出类似于( 2 )和( 3 )的公式,其中我们注意到特征 { z i t } i = 1 n t \left\{z_i^t\right\}_{i=1}^{n_t} {zit}i=1nt是用更新的网络参数 θ \theta θ计算的,并且我们还根据 { z i t } i = 1 n t \left\{z_i^t\right\}_{i=1}^{n_t} {zit}i=1nt(与标记源 { z j s } j = 1 n s \left\{z_j^s\right\}_{j=1}^{n_s} {zjs}j=1ns)的当前聚类分配在每个训练历元开始时重新初始化 { μ k } k = 1 K \left\{\mu_k\right\}_{k=1}^K {μk}k=1K。 { μ k } k = 1 K \left\{\boldsymbol{\mu}_k\right\}_{k=1}^K {μk}k=1K 在每个历元的训练迭代过程中通过( 5 )的反向衍生梯度不断更新。
结合( 1 )和( 5 )给出了深度判别目标聚类的目标,并将其作为SRDC算法总体目标的第一项
min Q t , Q ~ t , { θ , ϑ } , { μ k } k = 1 K L S R D C t = L f ∘ φ t + L φ t . \min _{\boldsymbol{Q}^t, \tilde{\boldsymbol{Q}}^t,\{\boldsymbol{\theta}, \boldsymbol{\vartheta}\},\left\{\boldsymbol{\mu}_k\right\}_{k=1}^K} \mathcal{L}_{\mathrm{SRDC}}^t=\mathcal{L}_{f \circ \varphi}^t+\mathcal{L}_{\varphi}^t . Qt,Q~t,{θ,ϑ},{μk}k=1KminLSRDCt=Lf∘φt+Lφt.
备注。单独给定无标签的目标数据,由于辅助分布Qt可以是任意的,其优化不受适当约束,因此不能保证目标( 1 )本身具有合理的解来揭示目标数据的内在判别性。将( 5 )式代入总体目标( 6 )式,通过对适当初始化的聚类中心 { μ k } k = 1 K \left\{\boldsymbol{\mu}_k\right\}_{k=1}^K {μk}k=1K进行 { z i t } i = 1 n t \left\{z_i^t\right\}_{i=1}^{n_t} {zit}i=1nt的软分配来缓解该问题。为了保证合理的解,深度聚类方法[ 14、58]通常使用一个额外的重构损失作为数据依赖的正则项。在我们提出的用于域适应的SRDC中,下面引入的结构源正则化与[ 14、58]中使用的重建正则化具有类似的目的。
4 . 2 .结构源正则化
基于第3节提出的指定源域和目标域之间结构相似性的UDA假设,我们提出通过联合训练同一个网络
f
∘
φ
f \circ \varphi
f∘φ的简单策略来迁移标记源数据的全局判别结构。注意,
K
K
K way分类器
f
f
f定义了将特征空间
Z
\mathcal{Z}
Z划分为区域的超平面,其中
K
K
K个超平面对
K
K
K个类唯一负责。由于两个域共享相同的标签空间,联合训练理想地将两个域中来自相同类的实例推送到
Z
\mathcal{Z}
Z中的相同区域,从而隐式地实现两个域之间的特征对齐。图1给出了一个示意图。
从技术上讲,对于有标签的源数据
{
(
x
j
s
,
y
j
s
)
}
j
=
1
n
s
\left\{\left(x_j^s, y_j^s\right)\right\}_{j=1}^{n_s}
{(xjs,yjs)}j=1ns,我们简单地将( 1 )中的辅助分布替换为由真实标签
{
y
j
s
}
j
=
1
n
s
\left\{y_j^s\right\}_{j=1}^{n_s}
{yjs}j=1ns形成的辅助分布,从而通过交叉熵最小化实现有监督的网络训练
min
θ
,
ϑ
L
f
∘
φ
s
=
−
1
n
s
∑
j
=
1
n
s
∑
k
=
1
K
I
[
k
=
y
j
s
]
log
p
j
,
k
s
,
\min _{\boldsymbol{\theta}, \boldsymbol{\vartheta}} \mathcal{L}_{f \circ \varphi}^s=-\frac{1}{n_s} \sum_{j=1}^{n_s} \sum_{k=1}^K \mathrm{I}\left[k=y_j^s\right] \log p_{j, k}^s,
θ,ϑminLf∘φs=−ns1j=1∑nsk=1∑KI[k=yjs]logpj,ks,
其中
p
j
,
k
s
p_{j, k}^s
pj,ks是源实例
x
j
s
x_j^s
xjs的预测概率向量
p
j
s
p_j^s
pjs的第k个元素,I [ · ]是指示函数。我们还在特征空间
Z
\mathcal{Z}
Z中增强源判别,与( 5 )式平行,得到
min
θ
,
{
μ
k
}
k
=
1
K
L
φ
s
=
−
1
n
s
∑
j
=
1
n
s
∑
k
=
1
K
I
[
k
=
y
j
s
]
log
p
~
j
,
k
s
,
\min _{\boldsymbol{\theta},\left\{\boldsymbol{\mu}_k\right\}_{k=1}^K} \mathcal{L}_{\varphi}^s=-\frac{1}{n_s} \sum_{j=1}^{n_s} \sum_{k=1}^K \mathrm{I}\left[k=y_j^s\right] \log \widetilde{p}_{j, k}^s,
θ,{μk}k=1KminLφs=−ns1j=1∑nsk=1∑KI[k=yjs]logp
j,ks,
where
p
~
j
,
k
s
=
exp
(
(
1
+
∥
z
j
s
−
μ
k
∥
2
)
−
1
)
∑
k
′
=
1
K
exp
(
(
1
+
∥
z
j
s
−
μ
k
′
∥
2
)
−
1
)
.
\widetilde{p}_{j, k}^s=\frac{\exp \left(\left(1+\left\|\boldsymbol{z}_j^s-\boldsymbol{\mu}_k\right\|^2\right)^{-1}\right)}{\sum_{k^{\prime}=1}^K \exp \left(\left(1+\left\|\boldsymbol{z}_j^s-\boldsymbol{\mu}_{k^{\prime}}\right\|^2\right)^{-1}\right)} .
p
j,ks=∑k′=1Kexp((1+
zjs−μk′
2)−1)exp((1+
zjs−μk
2)−1).
结合式( 7 )和式( 8 ),利用带标签的源数据给出训练目标
min
{
θ
,
ϑ
}
,
{
μ
k
}
k
=
1
K
L
SRDC
s
=
L
f
∘
φ
s
+
L
φ
s
.
\min _{\{\boldsymbol{\theta}, \boldsymbol{\vartheta}\},\left\{\boldsymbol{\mu}_k\right\}_{k=1}^K} \mathcal{L}_{\text {SRDC }}^s=\mathcal{L}_{f \circ \varphi}^s+\mathcal{L}_{\varphi}^s .
{θ,ϑ},{μk}k=1KminLSRDC s=Lf∘φs+Lφs.
利用( 10 )作为结构源正则项,我们得到了SRDC算法的最终目标
min
Q
t
,
Q
~
t
,
{
θ
,
ϑ
}
,
{
μ
k
}
k
−
1
K
L
S
R
D
C
=
L
S
R
D
C
t
+
λ
L
S
R
D
C
s
,
\min _{\boldsymbol{Q}^t, \tilde{\boldsymbol{Q}}^t,\{\boldsymbol{\theta}, \boldsymbol{\vartheta}\},\left\{\boldsymbol{\mu}_k\right\}_{k-1}^K} \mathcal{L}_{\mathrm{SRDC}}=\mathcal{L}_{\mathrm{SRDC}}^t+\lambda \mathcal{L}_{\mathrm{SRDC}}^s,
Qt,Q~t,{θ,ϑ},{μk}k−1KminLSRDC=LSRDCt+λLSRDCs,
式中:
λ
\lambda
λ为惩罚参数
4 . 3 .通过软源样本选择进行增强
在迁移学习[ 23、62]中,通常假设源样本对于学习可迁移模型的重要性不同。实现这一假设的一个简单策略是根据源实例二次加权与目标实例[ 7,17,67]的相似性来实现。在本工作中,我们也将该策略应用到SRDC中。
具体地,令
{
c
k
t
∈
Z
}
k
=
1
K
\left\{c_k^t \in \mathcal{Z}\right\}_{k=1}^K
{ckt∈Z}k=1K 为特征空间中的
K
K
K个目标聚类中心。对于任意一个已标注源示例
(
x
s
,
y
s
)
\left(x^s, y^s\right)
(xs,ys),根据以下余弦距离计算其与
c
y
s
t
c_{y^s}^t
cyst的相似度,即簇
y
s
y^s
ys的目标中心
w
s
(
x
s
)
=
1
2
(
1
+
c
y
s
ℓ
⊤
x
s
∥
c
y
s
t
∥
∥
x
s
∥
)
∈
[
0
,
1
]
.
w^s\left(x^s\right)=\frac{1}{2}\left(1+\frac{c_{y^s}^{\ell \top} \boldsymbol{x}^s}{\left\|\boldsymbol{c}_{y^s}^t\right\|\left\|\boldsymbol{x}^s\right\|}\right) \in[0,1] .
ws(xs)=21(1+
cyst
∥xs∥cysℓ⊤xs)∈[0,1].
在网络训练过程中,每隔一段时间计算一次
{
c
k
t
}
k
=
1
K
\left\{c_k^t\right\}_{k=1}^K
{ckt}k=1K。注意到
{
c
k
t
}
k
=
1
K
\left\{c_k^t\right\}_{k=1}^K
{ckt}k=1K 不同于式( 4 )和式( 9 )中的
{
μ
k
}
k
=
1
K
\left\{\mu_k\right\}_{k=1}^K
{μk}k=1K ,它们都是在每个历元训练迭代过程中不断更新的源数据和目标数据的聚类中心。我们使用( 12 )计算所有
{
(
x
j
s
,
y
j
s
)
}
j
=
1
n
s
\left\{\left(x_j^s, y_j^s\right)\right\}_{j=1}^{n_s}
{(xjs,yjs)}j=1ns的权重,并使用以下加权版本的目标来增强( 7 )和( 8 )
L
f
∘
φ
(
⋅
;
{
w
j
s
}
j
=
1
n
s
)
s
=
−
1
n
s
∑
j
=
1
n
s
w
j
s
∑
k
=
1
K
I
[
k
=
y
j
s
]
log
p
j
,
k
s
,
L
φ
(
⋅
;
{
w
j
s
}
j
=
1
n
s
)
s
=
−
1
n
s
∑
j
=
1
n
s
w
j
s
∑
k
=
1
K
I
[
k
=
y
j
s
]
log
p
~
j
,
k
s
.
\begin{gathered} \mathcal{L}_{f \circ \varphi\left(\cdot ;\left\{w_j^s\right\}_{j=1}^{n_s}\right)}^s=-\frac{1}{n_s} \sum_{j=1}^{n_s} w_j^s \sum_{k=1}^K \mathrm{I}\left[k=y_j^s\right] \log p_{j, k}^s, \\ \mathcal{L}_{\varphi\left(\cdot ;\left\{w_j^s\right\}_{j=1}^{n_s}\right)}^s=-\frac{1}{n_s} \sum_{j=1}^{n_s} w_j^s \sum_{k=1}^K \mathrm{I}\left[k=y_j^s\right] \log \widetilde{p}_{j, k}^s . \end{gathered}
Lf∘φ(⋅;{wjs}j=1ns)s=−ns1j=1∑nswjsk=1∑KI[k=yjs]logpj,ks,Lφ(⋅;{wjs}j=1ns)s=−ns1j=1∑nswjsk=1∑KI[k=yjs]logp
j,ks.
第5节的实验表明,基于上述加权目标的SRDC取得了较好的效果。
5. Experiments
5.1。Setups
Office-31 [ 46 ]是目前最流行的用于视觉域适应的真实世界基准数据集,包含Amazon ( A )、Webcam ( W )和DSLR ( D )三个不同域共享的31类4 110张图像。我们在所有六种迁移任务上对所有方法进行了评估。
ImageCLEF-DA [ 1 ]是一个由加州理工学院- 256 ( C )、ImageNet ILSVRC 2012 ( I )和Pascal VOC 2012 ( P )三个域共享的具有12个类的基准数据集。每类有50幅图像,每个域有600幅图像。我们在所有六种迁移任务上对所有方法进行了评估。
Office- Home [ 55 ]是一个更具挑战性的基准数据集,共有65类15500张图像,由4个极其不同的领域共享:艺术类图像( Ar )、剪贴画( Cl )、产品图像( Pr )和真实世界图像( Rw )。我们在全部12个迁移任务上对所有方法进行评估。
实施细则。我们遵循UDA [ 16、33、35、48、60]的标准协议,使用所有有标记的源样本和所有无标记的目标样本作为训练数据。对于每个迁移任务,我们使用center - Crop目标域图像报告结果,并报告3次随机试验的均值
(
±
( \pm
(± std
)
)
) 的分类结果。我们使用ImageNet [ 12 ]预训练的ResNet - 50 [ 21 ]作为基网络,其中最后一个FC层替换为任务特定的FC层( s )来参数化分类器
f
(
⋅
)
f(\cdot)
f(⋅)。我们在PyTorch中实现了我们的实验。我们从预训练的层中微调并训练新增加的层,其中后者的学习速率是前者的10倍。我们采用小批量SGD,学习率调度为[ 16 ]:学习率由
η
p
=
η
0
(
1
+
α
p
)
−
β
\eta_p=\eta_0(1+\alpha p)^{-\beta}
ηp=η0(1+αp)−β调整,其中p为训练历元归一化到
[
0
,
1
]
[0,1]
[0,1]的过程,
η
0
=
0.001
,
α
=
\eta_0=0.001, \alpha=
η0=0.001,α=
10
,
β
=
0.75
10, \beta=0.75
10,β=0.75。根据文献[ 16 ],将
λ
\lambda
λ从0增加到1,
λ
p
=
2
(
1
+
exp
(
−
γ
p
)
)
−
1
−
1
\lambda_p=2(1+\exp (-\gamma p))^{-1}-1
λp=2(1+exp(−γp))−1−1,其中
γ
=
10
\gamma=10
γ=10 .其他实施细则见补充材料。
5.2. Ablation studies and analysis
消融研究。
为了研究我们提出的SRDC的单个组件的影响,我们使用基于ResNet - 50的Office - 31进行消融研究,通过评估SRDC的几种变体:( 1 )源模型,在标记的源样本上微调基础网络;( 2 ) SRDC ( w / o结构源正则化),它使用( 6 )来微调源预训练模型,即不使用结构源正则化;( 3 ) SRDC ( w / o特征判别),表示在特征空间Z中不区分源和目标的训练;( 4 ) SRDC ( w / o软源样本选择),通过软源样本选择进行无增强训练。结果报告于表1。我们可以观察到,当我们设计的组件中的任何一个被移除时,性能都会下降,验证了( 1 )特征判别和结构源正则化对于提高目标聚类是有效的;( 2 )提出的软源样本选择方案导致更好的正则化。
源细化。
为了确认我们提出的软源样本选择方案可以选择更多可迁移的源样本,我们在图2中展示了从目标域A中随机采样的图像,以及从源域W中排名靠前和排名靠后的样本。这里,红色数字是由( 12 )计算的源权重。我们可以观察到( 1 )最低权重超过0.5,这是合理的,因为所有源样本都与目标域相关,因为两个域共享相同的标签空间;( 2 )最高权重小于1,这是合理的,因为两个领域之间存在分布偏移;( 3 )具有规范视点的源图像比具有自上而下、自下而上和侧面视点的源图像具有更高的权重,这是很直观的,因为所有的目标图像只从规范视点显示[ 46 ]。以上观察结果肯定了我们提出的软源样本选择方案的合理性。
感性UDA设置下的比较。
为了验证我们提出的揭示目标内在区分度的策略比现有的在两个域[ 16、48]之间学习对齐特征表示的迁移策略能够得到更接近oracle目标分类器的聚类解,我们在归纳UDA的设置下设计了对比实验。我们按照50 % / 50 %的分割方案将Office - 31的每个域划分为训练集和测试集。我们使用源域的有标记集合和目标域的无标记训练集作为训练数据。在表2中,我们报告了在目标训练集上使用表现最好的模型在目标领域的测试集上的结果。在这里,Oracle Model在标记的目标训练集上微调基础网络。我们可以看到,我们提出的发现策略SRDC取得了更接近Oracle模型的结果,验证了本文工作的动机和我们提出的SRDC的有效性。特征可视化。针对图3中A→W和W→A两个反向迁移任务,我们利用t - SNE [ 54 ]通过Source Model和SRDC对目标域上的嵌入特征进行可视化。我们可以定性地观察到,与源模型相比,基于数据聚类的SRDC能够更好地区分目标域特征,揭示具有判别性的数据结构。混淆矩阵。我们在图4中给出了A→W和W→A两个反向迁移任务上Source Model和SRDC的正确率混淆矩阵。与图3的定性结果类似,我们可以观察到从源模型到SRDC的定量改进,进一步证实了SRDC的优势。
收敛性能。
在图5中A→W和W→A两个反向迁移任务上的测试误差验证了Source Model和SRDC的收敛性能。我们可以观察到SRDC比源模型具有更快更平滑的收敛性能。
5.3. Comparisons with the state of the art
基于ResNet - 50的Office - 31的结果报告在表3中,其中现有方法的结果引自各自的论文或[ 5,33,35]的著作。我们可以看到,SRDC在几乎所有的迁移任务上都优于所有比较的方法。值得注意的是,SRDC显著增强了对困难迁移任务的分类结果。A→W和W→A,两域相差较大。SRDC超越了BSP旨在提高对抗特征适应的判别性的最新工作,表明数据聚类可能是目标判别的一个更有前途的方向。
基于ResNet - 50的ImageCLEF - DA的结果报告在表4中,其中现有方法的结果引自各自的论文或工作[ 35 ]。SRDC在所有迁移任务上都取得了比所有对比方法更好的结果,并且在硬迁移任务上的结果有了显著的提高。C→P和P→C,验证SRDC在源域和目标域大小相等且类别平衡的迁移任务上的有效性。
基于ResNet - 50的Office - Home的结果报告在表5中,其中现有方法的结果引自各自的论文或[ 35、45 ]的著作。我们可以观察到SRDC在大多数迁移任务上显著超过所有对比方法,仍有较大的提升空间。这是合理的,因为Office - Home中的四个域包含更多的类别,它们在视觉上的差异更大,域内分类结果也更低[ 55 ]。令人鼓舞的是,在这些困难的任务上,SRDC比当前最先进的方法MDD有很大的改进,这突出了通过数据聚类发现判别结构的重要性。
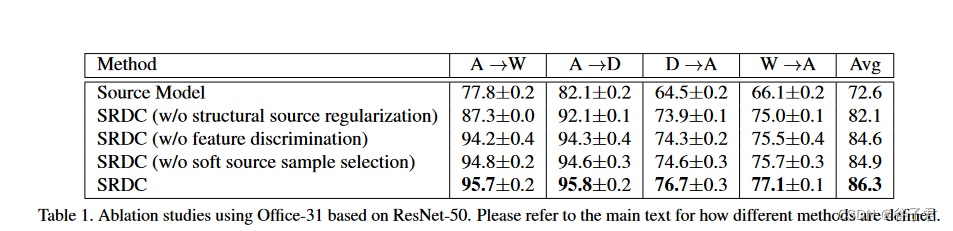
见表1。基于ResNet - 50的Office - 31消融研究。不同方法是如何定义的,请参考正文。

见图2。左边的图像从目标域A中随机采样,右边的图像从源域W中随机采样(第3列)和(第4列),共3类。注意,红色数字为式( 12 )计算的源权重。
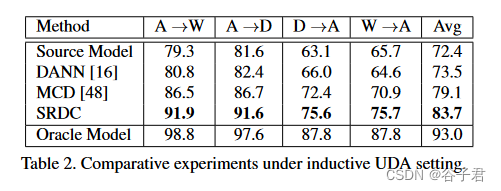
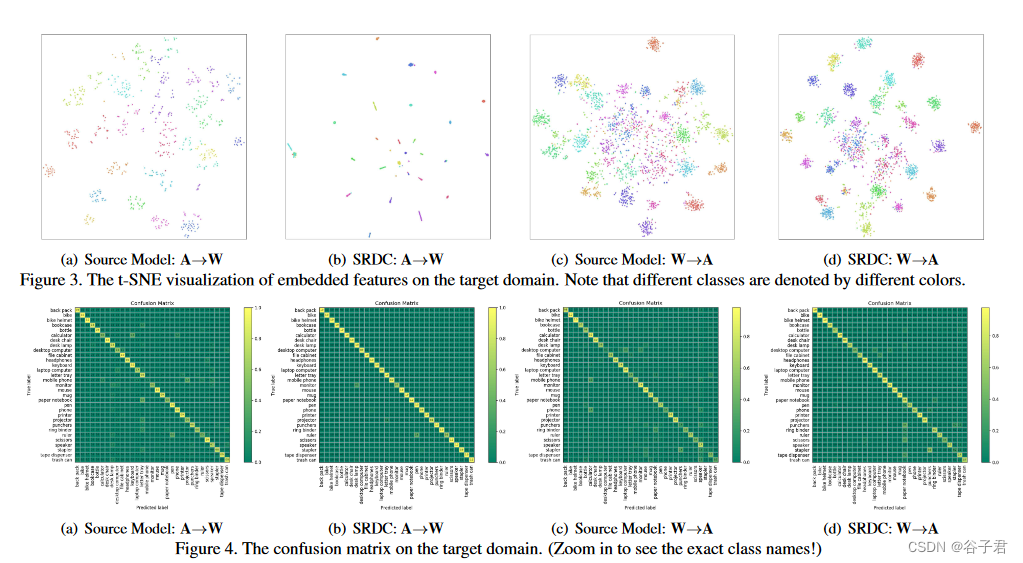
图3。目标域上嵌入特征的t - SNE可视化。注意,不同的类用不同的颜色表示。
见图4。目标域上的混淆矩阵。(放大查看确切的类名!)
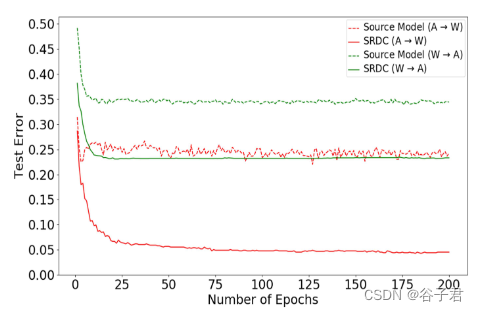
见图5。收敛。
6. Conclusion
在这项工作中,受结构域相似性假设的启发,我们提出了一种源正则化的深度判别聚类方法,称为结构正则化深度聚类( SRDC )。SRDC通过直接揭示目标数据的内在区分度,解决了现有基于对齐的UDA方法破坏数据内在区分度的潜在问题。在技术上,我们使用基于深度网络的区分性聚类的灵活框架,最小化网络的预测标签分布与引入的辅助标签分布之间的KL散度;用源数据的真值标签形成的辅助分布代替辅助分布,通过联合网络训练实现结构源正则化。在SRDC中,我们还通过对中间网络特征进行聚类来增强目标判别,通过对发散性较小的源实例进行软选择来增强结构正则化。在基准测试集上的实验验证了本文方法的有效性。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









