







全文翻译如下:
通用域适应( UniDA )旨在将从有标签的源域学习到的知识迁移到无标签的目标域,而不需要对标签集进行任何约束。然而,域转移和类别转移使得UniDA极具挑战性,主要归因于需要同时识别共享的"已知"样本和私有的"未知"样本。以往的方法很少利用两个域之间的内在流形结构关系进行特征对齐,而是依靠基于softmax的具有类别竞争性质的分数来检测潜在的"未知"样本。因此,在本文中,我们提出了一种称为TNT的新的近邻对抗学习框架来解决这些问题。具体来说,TNT首先提出了一种新的领域对齐原则:语义一致的样本应该在几何上彼此相邻,无论是在领域内还是跨领域。从该准则出发,设计了基于相互近邻的跨域多样本对比损失,实现了公共类别匹配和私有类别分离。第二,面向精确的"未知"样本检测,TNT从证据深度学习的角度引入了类无竞争不确定性分数。TNT不设置单一阈值,而是学习一个类别感知的异质阈值向量来拒绝多样的"未知"样本。在三个基准测试集上的大量实验表明,TNT显著优于先前最先进的UniDA方法。
深度神经网络是数据饥饿的,因为它在具有丰富数据标签的域上表现得很好,但在新的无标签域上没有很好的泛化能力。由于领域偏见,任务相关的性能显著降低。领域自适应( DA )旨在通过消除特征差异,将知识从标签丰富的源领域迁移到标签稀缺的目标领域( Ganin和Lempitsky 2015)来解决这一问题。假设
L
s
L_{s}
Ls和
L
t
L_{t}
Lt分别是两个域中的标签集。传统的无监督DA通常假设
L
s
=
L
t
L_{s}=L_{t}
Ls=Lt,即封闭的DA ( CDA ) ( Tzeng等2017)。然而,在复杂的现实世界场景中,这一假设可能并不容易满足。通常,我们会遇到
L
l
⊂
L
s
L_{l} \subset L_{s}
Ll⊂Ls,即部分DA ( PDA ) ( Cao et al 2018),或
L
s
⊂
L
l
L_{s} \subset L_{l}
Ls⊂Ll,即开集DA ( ODA ) ( Panareda和Gall 2017),或
L
s
∩
L
t
≠
∅
,
L
s
∪
L
t
≠
L_{s} \cap L_{t} \neq \emptyset, L_{s} \cup L_{t} \neq
Ls∩Lt=∅,Ls∪Lt=
L
s
L_{s}
Ls or
L
t
L_{t}
Lt,即开部分DA ( OPDA ) ( You et al . 2019)。这些变体近年来引起了社会各界的关注,并被独立解决。然而,消极方面倾向于混淆这一进化过程。具体来说,适用于一种变体的方法可能不适用于另一种变体。更现实的是,我们可能事先并不知道这些变异中的哪些会发生。
通用DA ( Universal DA,UniDA )被提出来同时考虑领域迁移和类别迁移。它假设两个标签空间可以不同,并且它们之间的关系事先未知。在UniDA中,我们需要将目标样本分为"已知"标签和"未知"标签。然而,在这里,UniDA提出了两个技术挑战。首先,域差异的去除应该约束在两个域之间的公共类别上,同时需要分离各自的私有类别。其次,在没有目标标签监督的情况下,估计目标域上的标签分布和检测潜在的目标"未知"样本是另一个主要的技术难点。
对于第一个挑战,UAN ( You et al . 2019)和CMU ( Fu et al 2020)使用加权对抗网络来发现共享标签集并促进公共类适应。DANCE ( Saito等2020)使用邻域聚类目标将每个目标样本移动到源原型或其目标邻居。这些方法难以挖掘两个域之间的流形结构关系,迫切需要一种显式的类级特征对齐准则。针对第二个挑战,现有方法通过手动设置基于softmax的置信度或熵得分的全局阈值来拒绝"未知"样本。
在本文中,我们针对这两个挑战提出了一个名为TNT的证据邻域对比学习框架。首先,为了使模型能够知道"未知",我们通过引入证据深度学习( EDL )范式( Sensoy , Kaplan和Kandemir 2018)将其建模为贝叶斯不确定性估计问题。EDL使用Multinomial - Dirichlet分层模型来预测类别概率的分布,并提供相关的不确定性。在此基础上,针对"未知"样本检测,提出了一种理论上与数据似然一致的对数证据得分。我们的数学见解和实证结果表明,这种不确定性评分优于基于softmax的评分。为了克服EDL在封闭集合中的过拟合风险,我们提出了不确定性与置信度对抗目标来校准模型预测,该目标塑造了证据面,并规范了证据收集过程。我们不设置全局阈值,而是学习一个类别感知的异质阈值向量,以更有效地识别"未知"样本。
其次,为了匹配公共类别并分离各自的私有类别,我们提出了一种新颖的领域对齐原则:语义一致的样本应该在几何上彼此相邻,无论是在域内还是跨域(见图1 ( B )) )。基于这一标准,我们发展了一种邻域一致性对比学习范式来揭示两个领域的内在流形结构。具体来说,我们首先构造域内和域间的相互最近邻( MNN )对,它们可以被视为同一类别中的正对,否则为负对。然后设计多样本对比损失来整合域内和域间正负关系的这种知识。为了驱动域对齐过程,我们最小化这种对比损失,将域内和跨域的相似样本拉近,将不相似的样本推开,以避免标签负迁移。
我们的贡献可以概括如下:
- 我们从一个新的角度来处理UniDA问题,即通过贝叶斯证据学习和不确定性估计来支持开集知识转移。针对"未知"样本检测,引入具有理论洞察力的基于证据的不确定性评分。
- 我们提出了一种新颖的UniDA特征对齐准则,即域内和域间的相互最近邻应该相互靠近。通过将它们作为数据整合的桥梁,开发了跨领域多样本对比损失来消除领域偏差和解决类别偏移问题。
- 我们在各种UniDA基准上进行了广泛的实验,实证结果表明TNT优于先前最先进的UniDA方法。更深入的分析验证了所提出的不确定性评分和异质阈值的有效性。
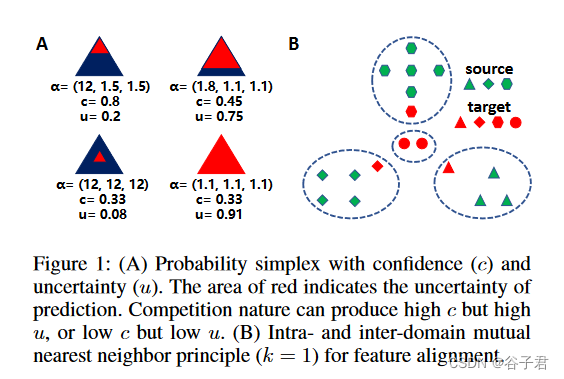
图1:( A )具有置信度( c )和不确定性( u )的概率单形。红色区域表示预测的不确定性。竞争性质可以产生高c高u,或者低c低u。( B )域内和域间互近邻原则( k = 1)用于特征对齐。
相关工作
普遍域适应
通用DA是一个具有挑战性的DA任务,它不需要关于源和目标标签空间之间关系的先验知识。You et al ( 2019 )提出UAN,通过量化样本级别的迁移能力来发现两个域之间的共享类。Fu et al . ( 2020 )聚合了置信度、熵和一致性三种互补的不确定性度量,用于准确检测目标私有类。Saito等( 2020 )提出DANCE通过邻域聚类学习目标领域结构,并使用熵分离损失实现特征对齐。Li et al . ( 2021 )提出了DCC,利用领域共识知识发现公共样本和私有样本上的判别聚类。这些方法没有考虑两个域之间的内在流形结构关系,从而使得它们在域对齐方面是次优的。在本文中,我们利用域内和域间MNN对来桥接两个域。
深度不确定性学习
理解和量化神经网络预测中的不确定性对高风险领域(加夫利科夫斯基等2021)的安全决策至关重要。近年来,研究人员对深度学习中的不确定性估计表现出越来越浓厚的兴趣。基于模型和基于数据的不确定性是描述神经网络( Choi等2019 ;宝、余、孔2021)预测不确定性的两种常见方式。为了区分两个域之间的公共和私有类别,通过深度神经网络学习的预测不确定性可以是一个有前景的度量。最近,证据深度学习被开发用于量化分类不确定性,在分布外查询( Sensoy , Kaplan和Kandemir 2018)的检测中表现出前所未有的成功。在本文中,据我们所知,我们首次在UniDA中加入了证据学习模块来区分"已知"和潜在的"未知"样本。
对比学习
对比学习是一种典型的自监督学习范式( He et al 2020 ; Chen等2020)。它通过对比正对和负对来学习表征。许多先进的表征学习任务方法都是基于对比学习框架(陈诗一、何2021)。其中包括基于实例的( Grill等2020)、基于聚类的( Caron等2020)和基于近邻的对比学习技术(钟甫宁等2021)。虽然正样本可以来自每个实例的增强视图,但实例间的相似性与假设的实例区分相冲突,损害了特征学习(王永进、刘志刚、于2021)。在本文中,我们提出利用相互最近邻作为正对来实现两个域之间的特征对齐。
方法
综述
在UniDA中,我们有一个有标签的源域
D
s
=
D_{s}=
Ds=
{
(
x
i
s
,
y
i
s
)
}
i
=
1
N
s
\left\{\left(x_{i}^{s}, y_{i}^{s}\right)\right\}_{i=1}^{N_{s}}
{(xis,yis)}i=1Ns 和
L
s
L_{s}
Ls "已知"类别,其中
D
s
∼
P
s
D_{s} \sim P_{s}
Ds∼Ps和一个无标签的目标域
D
t
=
{
(
x
i
t
)
}
i
=
1
N
t
D_{t}=\left\{\left(x_{i}^{t}\right)\right\}_{i=1}^{N_{t}}
Dt={(xit)}i=1Nt,其中
D
t
∼
P
t
D_{t} \sim P_{t}
Dt∼Pt,并且
P
s
≠
P
t
P_{s} \neq P_{t}
Ps=Pt。目标域包含一些"已知"类别和潜在的"未知"类别,记其标签空间为
L
t
L_{t}
Lt。我们的目标是学习一个分类模型,并用Ls中的一个"已知"标签或"未知"标签来标记目标样本。
如图2所示,我们的模型由两个基本模块组成:( 1 )特征提取器
g
g
g,将输入图像映射为嵌入表示
z
=
g
(
x
)
z=g(x)
z=g(x);( 2 )证据神经网络头
f
f
f,预测Dirichlet分布参数对应的类证据。估计的证据可以进一步确定输入的预测概率和不确定性。然后我们利用总证据的分布特征进行"未知"样本推断。为了避免模型过拟合,我们设计了不确定性对置信度对抗机制进行预测校准。在训练中,我们还提出了跨领域的相互近邻对比学习模块来驱动特征对齐过程。
深度证据学习与不确定性估计
现有的DA模型利用深度神经网络顶部带有softmax算子的线性投影层对目标数据进行判别。最终模型可以解释为Multinomial分布的参数回归框架。特别地,对于
L
s
L_{s}
Ls类分类问题,假设离散类概率
p
=
p=
p=
(
p
1
,
p
2
,
…
,
p
L
s
)
\left(p_{1}, p_{2}, \ldots, p_{L_{s}}\right)
(p1,p2,…,pLs),由网络输出决定;则有标签样本
(
x
,
y
)
(x, y)
(x,y)的似然函数为
L
(
p
∣
x
)
=
Multinomial
(
y
∣
p
1
,
p
2
,
…
,
p
L
s
)
=
∏
j
=
1
L
s
p
j
y
j
\mathcal{L}(p | x)=\operatorname{Multinomial}\left(y | p_{1}, p_{2}, \ldots, p_{L_{s}}\right)=\prod_{j=1}^{L_{s}} p_{j}^{y_{j}}
L(p∣x)=Multinomial(y∣p1,p2,…,pLs)=j=1∏Lspjyj
最小化标记样本关于网络参数的负对数似然
−
log
L
(
p
∣
x
)
-\log \mathcal{L}(p | x)
−logL(p∣x) 等价于交叉熵损失。它只给出了分类概率上Multinomial分布的点估计。因此,输出无法捕捉预测概率的方差,即二阶不确定性。此外,由于输出概率被softmax的分母压扁,网络倾向于对"未知"数据(温忠麟等2021)产生过度自信的预测。在ODA和OPDA设置中,这种现象更加普遍和有害。
为了克服上述局限性,证据深度学习( EDL )通过引入贝叶斯层次模型,提出了一种联合完成多类分类和不确定性估计的原则性方法。EDL引入多项式分布的共轭先验分布Dirichlet分布来表示类概率分配
p
p
p的密度。具体地,假设
p
p
p服从先验Dirichlet分布,证据参数
α
=
(
α
1
,
α
2
,
…
,
α
L
s
)
,
α
i
>
1
,
∀
1
≤
i
≤
L
s
\alpha=\left(\alpha_{1}, \alpha_{2}, \ldots, \alpha_{L_{s}}\right), \alpha_{i}>1, \forall 1 \leq i \leq L_{s}
α=(α1,α2,…,αLs),αi>1,∀1≤i≤Ls,
Dir
(
p
∣
α
)
=
1
B
(
α
)
∏
k
=
1
L
s
p
k
α
k
−
1
\operatorname{Dir}(p | \alpha)=\frac{1}{B(\alpha)} \prod_{k=1}^{L_{s}} p_{k}^{\alpha_{k}-1}
Dir(p∣α)=B(α)1k=1∏Lspkαk−1
式中:
B
(
α
)
B(\alpha)
B(α) 为Multinomial Beta函数。则EDL模型的训练损失为负对数边际似然,由
L
1
=
∑
i
=
1
N
s
−
log
(
∫
∏
j
=
1
L
s
p
i
j
y
i
j
s
1
B
(
α
i
s
)
∏
j
=
1
L
s
p
i
j
α
i
j
s
−
1
d
p
i
)
=
∑
i
=
1
N
s
∑
j
=
1
L
s
y
i
j
s
(
log
S
i
s
−
log
α
i
j
s
)
\begin{aligned} \mathcal{L}_{1} & =\sum_{i=1}^{N_{s}}-\log \left(\int \prod_{j=1}^{L_{s}} p_{i j}^{y_{i j}^{s}} \frac{1}{B\left(\alpha_{i}^{s}\right)} \prod_{j=1}^{L_{s}} p_{i j}^{\alpha_{i j}^{s}-1} d p_{i}\right) \\ & =\sum_{i=1}^{N_{s}} \sum_{j=1}^{L_{s}} y_{i j}^{s}\left(\log S_{i}^{s}-\log \alpha_{i j}^{s}\right) \end{aligned}
L1=i=1∑Ns−log(∫j=1∏LspijyijsB(αis)1j=1∏Lspijαijs−1dpi)=i=1∑Nsj=1∑Lsyijs(logSis−logαijs)
式中:S为总证据
S
=
∑
k
=
1
L
s
α
k
S=\sum_{k=1}^{L_{s}} \alpha_{k}
S=∑k=1Lsαk。这里,
α
\alpha
α是非负网络预测输出,可以表示为
α
=
f
(
g
(
x
)
)
+
1
\alpha=f(g(x))+1
α=f(g(x))+1。根据登普斯特- Shafer证据理论( Sentz和Ferson 2002),第k类的判别概率为
p
k
=
α
k
S
p_{k}=\frac{\alpha_{k}}{S}
pk=Sαk,预测不确定性u与总证据S成反比,确定为
u
=
L
s
S
u=\frac{L_{s}}{S}
u=SLs。在训练阶段,通过最小化
L
1
\mathcal{L}_{1}
L1目标,我们可以为每个已知源类别收集证据。同时,得到的总证据S或不确定性u使我们能够在推断过程中区分"已知"和"未知"样本。
讨论:为什么总证据评分S比基于softmax的评分更适合发现潜在的目标私有类?为了便于理解,我们假设网络f用来预测
α
\alpha
α的激活函数是指数函数,并且忽略常数1的影响。那么我们有
log
max
i
p
(
y
i
∣
x
)
=
log
max
i
α
i
S
=
−
log
S
+
log
max
i
α
i
\log \max _{i} p\left(y_{i} | x\right)=\log \max _{i} \frac{\alpha_{i}}{S}=-\log S+\log \max _{i} \alpha_{i}
logimaxp(yi∣x)=logimaxSαi=−logS+logimaxαi
当我们在带标签数据上最大化
log
max
i
p
(
y
i
∣
x
)
\log \max _{i} p\left(y_{i} | x\right)
logmaxip(yi∣x)时,通过最小化负对数边际似然
L
1
\mathcal{L}_{1}
L1,
max
i
α
i
\max _{i} \alpha_{i}
maxiαi趋于更高,S趋于更低。此时,预测不确定性u趋于更高,超出了我们的预期。对于"已知"类别,预测应准确且确定,而对于"未知"类别,预测不确定性应高,即低S (克里希南和Tickoo 2020)。更重要的是,如前所述,基于softmax的评分引入了不同类之间的竞争,这很容易产生任意高的评分值,即过度自信的预测。与softmax归一化的竞争性质相反,总证据得分S是基于求和的统计量,不存在任何竞争。
不确定性校准的U - C对抗机制
不确定性表征了将目标样本区分为"已知"类别的风险。发现潜在目标私有类别的一个自然方法是设置不确定性度量的阈值。不确定性大于该阈值的样本被识别为"未知"标签的概率较高。然而,最小化L1会迫使"已知"类别样本的总证据S被压缩。由于不确定性u与S成反比,最小化L1会存在"已知"类别不确定性大,"未知"类别不确定性小的潜在风险,进而造成模型的过拟合。同时,"已知"和"未知"样本之间的不确定性差距对于发现潜在的私有类别可能不是最优的。
我们定义
c
=
max
k
p
k
c=\max _{k} p_{k}
c=maxkpk为预测置信度。一个校准良好的预测模型应该同时考虑置信度和不确定性。对于"已知"样本,置信度c高,不确定度u低;对于"未知"样本,置信度c低,不确定度u高。为了加强它们之间的反向关系,我们提出了一个
u
−
c
u-c
u−c对抗目标,定义为
L
2
=
L
2
s
+
L
2
t
=
−
∑
i
=
1
N
s
c
i
s
log
(
1
−
u
i
s
)
−
∑
j
=
1
N
t
(
c
j
ℓ
log
(
1
−
u
j
ℓ
)
+
(
1
−
c
j
ℓ
)
log
u
j
ℓ
)
\begin{aligned} \mathcal{L}_{2} & =\mathcal{L}_{2}^{s}+\mathcal{L}_{2}^{t}=-\sum_{i=1}^{N_{s}} c_{i}^{s} \log \left(1-u_{i}^{s}\right) \\ & -\sum_{j=1}^{N_{t}}\left(c_{j}^{\ell} \log \left(1-u_{j}^{\ell}\right)+\left(1-c_{j}^{\ell}\right) \log u_{j}^{\ell}\right) \end{aligned}
L2=L2s+L2t=−i=1∑Nscislog(1−uis)−j=1∑Nt(cjℓlog(1−ujℓ)+(1−cjℓ)logujℓ)
第一项旨在标记源域上给出低不确定性
(
u
→
0
)
(u \rightarrow 0)
(u→0)和高置信度
(
c
→
1
)
(c \rightarrow 1)
(c→1),而第二项则试图惩罚未标记目标域上的u - versus - c同质性,迫使它们朝着相反的方向优化。这样,模型被鼓励为"已知"类别学习一个偏斜和尖锐的狄利克雷单形,并为"未知"样本提供一个不偏斜和平坦的狄利克雷单形。可以看出,我们的u - c对抗机制在训练时不依赖于额外的验证集。从而为校准预测不确定性提供了更好的灵活性。
到目前为止,我们还没有讨论如何确定一个阈值
δ
\delta
δ来拒绝潜在的目标私有样本。以往的方法大多使用验证集来设置单一的全局阈值。本文提出了一种基于对数总证据(
log
S
\log S
logS )分布的类别感知阈值选择方法。其背后的动因是"已知"类别的多样性决定了阈值的异质性。假设"未知"的阈值向量为(
δ
^
∈
R
L
s
\hat{\delta} \in R^{L_{s}}
δ^∈RLs;然后对目标样本
i
i
i进行标记
y
i
t
=
{
j
,
if
log
S
i
t
≥
δ
^
j
,
j
=
arg
max
1
≤
k
≤
L
s
α
i
k
t
u
n
k
n
o
w
n
,
if
log
S
i
t
<
δ
^
j
,
j
=
arg
max
1
≤
k
≤
L
s
α
i
k
t
y_{i}^{t}=\left\{\begin{array}{ll} j, & \text { if } \log S_{i}^{t} \geq \hat{\delta}_{j}, j=\arg \max _{1 \leq k \leq L_{s}} \alpha_{i k}^{t} \\ u n k n o w n, & \text { if } \log S_{i}^{t}<\hat{\delta}_{j}, j=\arg \max _{1 \leq k \leq L_{s}} \alpha_{i k}^{t} \end{array}\right.
yit={j,unknown, if logSit≥δ^j,j=argmax1≤k≤Lsαikt if logSit<δ^j,j=argmax1≤k≤Lsαikt
具体来说,我们首先收集每个源类别下样本的对数总证据得分,并记为
Ω
k
=
{
log
S
i
s
:
y
i
s
=
k
}
,
1
≤
k
≤
L
s
\Omega_{k}=\left\{\log S_{i}^{s}: y_{i}^{s}=k\right\}, 1 \leq k \leq L_{s}
Ωk={logSis:yis=k},1≤k≤Ls。然后在
Ω
k
\Omega_{k}
Ωk 上拟合一个高斯分布,得到均值估计
v
^
k
\hat{v}_{k}
v^k和标准差估计
σ
^
k
\hat{\sigma}_{k}
σ^k .根据"三西格玛"规则,我们设定
δ
^
k
=
v
^
k
−
2
×
σ
^
k
\hat{\delta}_{k}=\hat{v}_{k}-2 \times \hat{\sigma}_{k}
δ^k=v^k−2×σ^k,可以包含每个类别中95 %以上的源样本,并忽略次要异常值。我们的阈值决策方法基于数据并从源域中学习,避免了复杂的超参数选择。
互近邻对比学习用于特征对齐
域偏见的干扰使得在源域上训练的分类器很难在目标域上获得良好的泛化性能。因此,消除领域差异和学习领域不变表示是提高DA模型泛化性的基础。然而,对于UniDA来说,这个目标更加困难,因为我们需要匹配两个域之间的公共类别,以及分离各自的私有类别。全局域层面的对齐可能会降低潜在私有类与公共类之间的特征间隔,从而降低对目标域的区分度。类层次对齐的困境是目标域上的类别定义以及两个域之间的类别关系。几何最近邻在流形学习中常用来描述相似模式,因此这里我们引入了一种新的DA归纳偏差:彼此相邻的数据点是提高域中每个类别紧凑性的支柱,也是公共类别匹配的桥梁。在此基础上,我们提出了将领域内和领域间的邻域共识统一起来的多抽样率对比学习范式。
具体来说,假设所有的嵌入向量
{
z
i
s
}
i
=
1
N
s
∪
{
z
j
t
}
j
=
1
N
t
\left\{z_{i}^{s}\right\}_{i=1}^{N_{s}} \cup\left\{z_{j}^{t}\right\}_{j=1}^{N_{t}}
{zis}i=1Ns∪{zjt}j=1Nt are
l
2
l_{2}
l2都是l2归一化的,首先用
N
k
s
(
i
)
N_{k}^{s}(i)
Nks(i) and
N
k
t
(
i
)
N_{k}^{t}(i)
Nkt(i)分别表示样本i在源域和目标域中的余弦距离度量的k近邻集合。如果
i
∈
D
s
i \in D_{s}
i∈Ds,则其
N
k
s
(
i
)
N_{k}^{s}(i)
Nks(i)可以用具有一致类别标签的样本代替。则样本i在两个域中的互近邻集合
M
k
s
(
i
)
M_{k}^{s}(i)
Mks(i) and
M
k
t
(
i
)
M_{k}^{t}(i)
Mkt(i)可以定义为
M
k
s
(
i
)
=
{
{
j
∈
D
s
:
y
i
=
y
j
}
,
if
i
∈
D
s
{
j
∈
D
s
:
i
∈
N
k
t
(
j
)
∩
j
∈
N
k
s
(
i
)
}
,
if
i
∈
D
t
M
k
t
(
i
)
=
{
{
l
∈
D
t
:
i
∈
N
k
s
(
l
)
∩
l
∈
N
k
t
(
i
)
}
,
if
i
∈
D
s
{
l
∈
D
t
:
i
∈
N
k
t
(
l
)
∩
l
∈
N
k
t
(
i
)
}
,
if
i
∈
D
t
\begin{array}{c} M_{k}^{s}(i)=\left\{\begin{array}{ll} \left\{j \in D_{s}: y_{i}=y_{j}\right\}, & \text { if } i \in D_{s} \\ \left\{j \in D_{s}: i \in N_{k}^{t}(j) \cap j \in N_{k}^{s}(i)\right\}, & \text { if } i \in D_{t} \\ M_{k}^{t}(i) & =\left\{\begin{array}{ll} \left\{l \in D_{t}: i \in N_{k}^{s}(l) \cap l \in N_{k}^{t}(i)\right\}, & \text { if } i \in D_{s} \\ \left\{l \in D_{t}: i \in N_{k}^{t}(l) \cap l \in N_{k}^{t}(i)\right\}, & \text { if } i \in D_{t} \end{array}\right. \end{array}\right. \\ \end{array}
Mks(i)=⎩
⎨
⎧{j∈Ds:yi=yj},{j∈Ds:i∈Nkt(j)∩j∈Nks(i)},Mkt(i) if i∈Ds if i∈Dt={{l∈Dt:i∈Nks(l)∩l∈Nkt(i)},{l∈Dt:i∈Nkt(l)∩l∈Nkt(i)}, if i∈Ds if i∈Dt
在这里,我们的目标是在源域和目标域之间拉近彼此的最近邻对,同时将那些非几何上接近的样本推开。受InfoNCE loss ( Hjelm等2018)的启发,我们提出了一个新的跨领域多样本对比学习目标函数,其表达式为
L
c
i
=
{
if
i
∈
D
s
,
−
log
∑
j
∈
M
k
s
(
i
)
exp
(
z
i
θ
z
j
s
/
τ
)
+
∑
l
∈
M
k
t
(
i
)
exp
(
z
i
s
z
l
t
/
τ
)
∑
m
=
1
N
s
exp
(
z
i
s
z
m
s
/
τ
)
+
∑
n
=
1
N
t
exp
(
z
i
s
z
n
t
/
τ
)
if
i
∈
D
t
,
−
log
∑
j
∈
M
k
s
(
i
)
exp
(
z
i
t
z
j
s
/
τ
)
+
∑
l
∈
M
k
t
(
i
)
exp
(
z
i
t
z
l
t
/
τ
)
∑
m
=
1
N
s
s
exp
(
z
i
t
z
m
s
/
τ
)
+
∑
n
=
1
N
t
exp
(
z
i
t
z
n
t
/
τ
)
\mathcal{L}_{c}^{i}=\left\{\begin{array}{l} \text { if } i \in D_{s}, \\ -\log \frac{\sum_{j \in M_{k}^{s}(i)} \exp \left(z_{i}^{\theta} z_{j}^{s} / \tau\right)+\sum_{l \in M_{k}^{t}(i)} \exp \left(z_{i}^{s} z_{l}^{t} / \tau\right)}{\sum_{m=1}^{N_{s}} \exp \left(z_{i}^{s} z_{m}^{s} / \tau\right)+\sum_{n=1}^{N_{t}} \exp \left(z_{i}^{s} z_{n}^{t} / \tau\right)} \\ \text { if } i \in D_{t}, \\ -\log \frac{\sum_{j \in M_{k}^{s}(i)} \exp \left(z_{i}^{t} z_{j}^{s} / \tau\right)+\sum_{l \in M_{k}^{t}(i)} \exp \left(z_{i}^{t} z_{l}^{t} / \tau\right)}{\sum_{m=1}^{N_{s}^{s}} \exp \left(z_{i}^{t} z_{m}^{s} / \tau\right)+\sum_{n=1}^{N_{t}} \exp \left(z_{i}^{t} z_{n}^{t} / \tau\right)} \end{array}\right.
Lci=⎩
⎨
⎧ if i∈Ds,−log∑m=1Nsexp(ziszms/τ)+∑n=1Ntexp(zisznt/τ)∑j∈Mks(i)exp(ziθzjs/τ)+∑l∈Mkt(i)exp(ziszlt/τ) if i∈Dt,−log∑m=1Nssexp(zitzms/τ)+∑n=1Ntexp(zitznt/τ)∑j∈Mks(i)exp(zitzjs/τ)+∑l∈Mkt(i)exp(zitzlt/τ)
式中:
τ
\tau
τ 为温度参数。在训练时,我们将源和目标样本拆分为不同的小批量,并分别转发。令
B
s
B_{s}
Bs and
B
t
B_{t}
Bt 分别表示源和目标批次,则总体训练对比损失计算为来自
B
s
B_{s}
Bs的所有源样本和来自
B
t
B_{t}
Bt的所有目标样本之和。
L
3
=
∑
i
∈
B
s
L
c
i
+
∑
j
∈
B
t
L
c
j
\mathcal{L}_{3}=\sum_{i \in B_{s}} \mathcal{L}_{c}^{i}+\sum_{j \in B_{t}} \mathcal{L}_{c}^{j}
L3=i∈Bs∑Lci+j∈Bt∑Lcj
如上所述,近邻识别过程和损失函数隐式地覆盖了涉及两个域的所有嵌入特征的计算,这对于大数据集来说很快就变得难以解决。为了解决这个问题,我们使用一个混合内存库
Z
ˉ
=
{
z
ˉ
1
s
,
…
,
z
ˉ
N
s
s
,
z
ˉ
1
t
,
…
,
z
ˉ
N
t
t
}
\bar{Z}=\left\{\bar{z}_{1}^{s}, \ldots, \bar{z}_{N_{s}}^{s}, \bar{z}_{1}^{t}, \ldots, \bar{z}_{N_{t}}^{t}\right\}
Zˉ={zˉ1s,…,zˉNss,zˉ1t,…,zˉNtt}来保持所有源和目标特征的运行平均值。我们用随机单位矢量初始化记忆库,并在训练过程中通过混合
z
ˉ
i
\bar{z}_{i}
zˉi 和
z
i
z_{i}
zi 来更新其值,其中
γ
\gamma
γ是一个混合参数。
z
ˉ
i
←
γ
z
ˉ
i
+
(
1
−
γ
)
z
i
\bar{z}_{i} \leftarrow \gamma \bar{z}_{i}+(1-\gamma) z_{i}
zˉi←γzˉi+(1−γ)zi
总体目标。该模型通过三项联合优化,即证据深度学习损失
L
1
\mathcal{L}_{1}
L1、不确定性校准损失
L
2
\mathcal{L}_{2}
L2和对比特征对齐损失
L
3
\mathcal{L}_{3}
L3。
L
=
L
1
+
L
2
+
λ
L
3
\mathcal{L}=\mathcal{L}_{1}+\mathcal{L}_{2}+\lambda \mathcal{L}_{3}
L=L1+L2+λL3
其中
λ
\lambda
λ取0.1以平衡各损失分量。















 99
99











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









