









一、Java代码实现WordCount
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Iterator;
import java.util.regex.Pattern;
public class SparkJavaWordCount {
private static final Pattern SPACE = Pattern.compile(" ");
public static void main(String[] args) throws Exception {
if (args.length < 1) {
System.err.println("Usage: SparkJavaWordCount <file>");
System.exit(1);
}
SparkConf sparkConf = new SparkConf().setAppName("SparkJavaWordCount");
JavaSparkContext sc = new JavaSparkContext(sparkConf);
JavaRDD<String> lines = sc.textFile(args[0], 1);
JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterator<String> call(String line) {
return Arrays.asList(line.split(" ")).iterator();
}
});
JavaPairRDD<String, Integer> word = words.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String word) {
return new Tuple2<String, Integer>(word, 1);
}
});
JavaPairRDD<String, Integer> wordCount = word.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer i1, Integer i2) {
return i1 + i2;
}
});
wordCount.foreach(new VoidFunction<Tuple2<String, Integer>>() {
@Override
public void call(Tuple2<String,Integer> o) throws Exception {
System.out.println(o._1 + " : "+o._2);
}
});
}
}
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.cjbs</groupId>
<artifactId>SparkWordCount</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<encoding>UTF-8</encoding>
<scala.version>2.11.8</scala.version>
<spark.version>2.3.0</spark.version>
<hadoop.version>2.6.0</hadoop.version>
<scala.compat.version>2.11</scala.compat.version>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
</dependencies>
<build>
<pluginManagement>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.5.1</version>
</plugin>
</plugins>
</pluginManagement>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<executions>
<execution>
<id>scala-compile-first</id>
<phase>process-resources</phase>
<goals>
<goal>add-source</goal>
<goal>compile</goal>
</goals>
</execution>
<execution>
<id>scala-test-compile</id>
<phase>process-test-resources</phase>
<goals>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<executions>
<execution>
<phase>compile</phase>
<goals>
<goal>compile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
二、测试
1.使用mvn打包
mvn clean package
将jar包上传到/opt/hadoopTest/
2.创建测试文件/opt/hadoopTest/test
添加以下内容
Hello Spark !
Hello Scala !
Hello Java !
执行命令将test文件上传到hdfs
hdfs dfs -put /opt/hadoopTest/test /user/hdfs/input
3.执行命令测试jar包
spark-submit --class com.cjbs.SparkJavaWordCount --master local /opt/hadoopTest/SparkWordCount-1.0-SNAPSHOT.jar /user/hdfs/input/test
报错:
21/07/13 11:32:39 INFO rdd.HadoopRDD: Input split: hdfs://nn:8020/user/hdfs/input/test:0+41
21/07/13 11:32:39 INFO Configuration.deprecation: mapred.tip.id is deprecated. Instead, use mapreduce.task.id
21/07/13 11:32:39 INFO Configuration.deprecation: mapred.task.id is deprecated. Instead, use mapreduce.task.attempt.id
21/07/13 11:32:39 INFO Configuration.deprecation: mapred.task.is.map is deprecated. Instead, use mapreduce.task.ismap
21/07/13 11:32:39 INFO Configuration.deprecation: mapred.task.partition is deprecated. Instead, use mapreduce.task.partition
21/07/13 11:32:39 INFO Configuration.deprecation: mapred.job.id is deprecated. Instead, use mapreduce.job.id
21/07/13 11:32:39 ERROR executor.Executor: Exception in task 0.0 in stage 0.0 (TID 0)
java.lang.AbstractMethodError: com.cjbs.SparkJavaWordCount$1.call(Ljava/lang/Object;)Ljava/lang/Iterable;
at org.apache.spark.api.java.JavaRDDLike$$anonfun$fn$1$1.apply(JavaRDDLike.scala:129)
at org.apache.spark.api.java.JavaRDDLike$$anonfun$fn$1$1.apply(JavaRDDLike.scala:129)
at scala.collection.Iterator$$anon$13.hasNext(Iterator.scala:371)
at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:327)
at org.apache.spark.util.collection.ExternalSorter.insertAll(ExternalSorter.scala:192)
at org.apache.spark.shuffle.sort.SortShuffleWriter.write(SortShuffleWriter.scala:64)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:73)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:41)
at org.apache.spark.scheduler.Task.run(Task.scala:89)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:242)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
21/07/13 11:32:39 ERROR util.SparkUncaughtExceptionHandler: Uncaught exception in thread Thread[Executor task launch worker-0,5,main]
java.lang.AbstractMethodError: com.cjbs.SparkJavaWordCount$1.call(Ljava/lang/Object;)Ljava/lang/Iterable;
at org.apache.spark.api.java.JavaRDDLike$$anonfun$fn$1$1.apply(JavaRDDLike.scala:129)
at org.apache.spark.api.java.JavaRDDLike$$anonfun$fn$1$1.apply(JavaRDDLike.scala:129)
at scala.collection.Iterator$$anon$13.hasNext(Iterator.scala:371)
at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:327)
at org.apache.spark.util.collection.ExternalSorter.insertAll(ExternalSorter.scala:192)
at org.apache.spark.shuffle.sort.SortShuffleWriter.write(SortShuffleWriter.scala:64)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:73)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:41)
at org.apache.spark.scheduler.Task.run(Task.scala:89)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:242)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
21/07/13 11:32:39 INFO spark.SparkContext: Invoking stop() from shutdown hook
解决办法:
具体的原因基本上是因为spark执行程序的版本和集群spark版本不一样,如集群spark版本是1.6.,而执行程序使用的是2.1.;由于版本差异大,部分函数的定义发生变化,会造成以上问题。
查看集群spark版本spark-shell
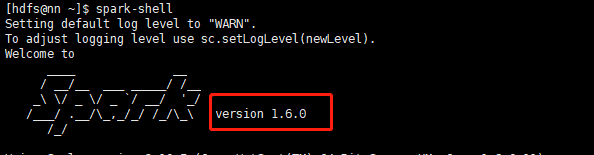
而代码pom中spark版本是2.3

修改pom中spark版本为1.6.0,然后修改java代码
将部分Java代码
JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterator<String> call(String line) {
return Arrays.asList(line.split(" ")).iterator();
}
});
修改为
JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterable<String> call(String line) {
return Arrays.asList(line.split(" "));
}
});
重新执行spark-submit上面那个命令
输出日志
21/07/13 16:12:32 INFO spark.SparkContext: Running Spark version 1.6.0
21/07/13 16:12:32 INFO spark.SecurityManager: Changing view acls to: hdfs
21/07/13 16:12:32 INFO spark.SecurityManager: Changing modify acls to: hdfs
21/07/13 16:12:32 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(hdfs); users with modify permissions: Set(hdfs)
21/07/13 16:12:33 INFO util.Utils: Successfully started service 'sparkDriver' on port 37619.
21/07/13 16:12:33 INFO slf4j.Slf4jLogger: Slf4jLogger started
21/07/13 16:12:33 INFO Remoting: Starting remoting
21/07/13 16:12:33 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://sparkDriverActorSystem@172.30.128.212:39546]
21/07/13 16:12:33 INFO Remoting: Remoting now listens on addresses: [akka.tcp://sparkDriverActorSystem@172.30.128.212:39546]
21/07/13 16:12:33 INFO util.Utils: Successfully started service 'sparkDriverActorSystem' on port 39546.
21/07/13 16:12:33 INFO spark.SparkEnv: Registering MapOutputTracker
21/07/13 16:12:33 INFO spark.SparkEnv: Registering BlockManagerMaster
21/07/13 16:12:33 INFO storage.DiskBlockManager: Created local directory at /tmp/blockmgr-c1ceef34-3949-4f14-b7db-e0ce16a52a8e
21/07/13 16:12:33 INFO storage.MemoryStore: MemoryStore started with capacity 530.0 MB
21/07/13 16:12:33 INFO spark.SparkEnv: Registering OutputCommitCoordinator
21/07/13 16:12:33 INFO util.Utils: Successfully started service 'SparkUI' on port 4040.
21/07/13 16:12:33 INFO ui.SparkUI: Started SparkUI at http://172.30.128.212:4040
21/07/13 16:12:33 INFO spark.SparkContext: Added JAR file:/opt/hadoopTest/SparkWordCount-1.0-SNAPSHOT.jar at spark://172.30.128.212:37619/jars/SparkWordCount-1.0-SNAPSHOT.jar with timestamp 1626163953611
21/07/13 16:12:33 INFO executor.Executor: Starting executor ID driver on host localhost
21/07/13 16:12:33 INFO util.Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 43147.
21/07/13 16:12:33 INFO netty.NettyBlockTransferService: Server created on 43147
21/07/13 16:12:33 INFO storage.BlockManager: external shuffle service port = 7337
21/07/13 16:12:33 INFO storage.BlockManagerMaster: Trying to register BlockManager
21/07/13 16:12:33 INFO storage.BlockManagerMasterEndpoint: Registering block manager localhost:43147 with 530.0 MB RAM, BlockManagerId(driver, localhost, 43147)
21/07/13 16:12:33 INFO storage.BlockManagerMaster: Registered BlockManager
21/07/13 16:12:34 INFO scheduler.EventLoggingListener: Logging events to hdfs://nn:8020/user/spark/applicationHistory/local-1626163953636
21/07/13 16:12:34 INFO spark.SparkContext: Registered listener com.cloudera.spark.lineage.ClouderaNavigatorListener
21/07/13 16:12:34 INFO storage.MemoryStore: Block broadcast_0 stored as values in memory (estimated size 303.8 KB, free 529.7 MB)
21/07/13 16:12:34 INFO storage.MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 26.0 KB, free 529.7 MB)
21/07/13 16:12:34 INFO storage.BlockManagerInfo: Added broadcast_0_piece0 in memory on localhost:43147 (size: 26.0 KB, free: 530.0 MB)
21/07/13 16:12:34 INFO spark.SparkContext: Created broadcast 0 from textFile at SparkJavaWordCount.java:29
21/07/13 16:12:35 INFO mapred.FileInputFormat: Total input paths to process : 1
21/07/13 16:12:35 INFO spark.SparkContext: Starting job: foreach at SparkJavaWordCount.java:52
21/07/13 16:12:35 INFO scheduler.DAGScheduler: Registering RDD 3 (mapToPair at SparkJavaWordCount.java:38)
21/07/13 16:12:35 INFO scheduler.DAGScheduler: Got job 0 (foreach at SparkJavaWordCount.java:52) with 1 output partitions
21/07/13 16:12:35 INFO scheduler.DAGScheduler: Final stage: ResultStage 1 (foreach at SparkJavaWordCount.java:52)
21/07/13 16:12:35 INFO scheduler.DAGScheduler: Parents of final stage: List(ShuffleMapStage 0)
21/07/13 16:12:35 INFO scheduler.DAGScheduler: Missing parents: List(ShuffleMapStage 0)
21/07/13 16:12:35 INFO scheduler.DAGScheduler: Submitting ShuffleMapStage 0 (MapPartitionsRDD[3] at mapToPair at SparkJavaWordCount.java:38), which has no missing parents
21/07/13 16:12:35 INFO storage.MemoryStore: Block broadcast_1 stored as values in memory (estimated size 4.8 KB, free 529.7 MB)
21/07/13 16:12:35 INFO storage.MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 2.7 KB, free 529.7 MB)
21/07/13 16:12:35 INFO storage.BlockManagerInfo: Added broadcast_1_piece0 in memory on localhost:43147 (size: 2.7 KB, free: 530.0 MB)
21/07/13 16:12:35 INFO spark.SparkContext: Created broadcast 1 from broadcast at DAGScheduler.scala:1004
21/07/13 16:12:35 INFO scheduler.DAGScheduler: Submitting 1 missing tasks from ShuffleMapStage 0 (MapPartitionsRDD[3] at mapToPair at SparkJavaWordCount.java:38) (first 15 tasks are for partitions Vector(0))
21/07/13 16:12:35 INFO scheduler.TaskSchedulerImpl: Adding task set 0.0 with 1 tasks
21/07/13 16:12:35 INFO scheduler.TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, localhost, executor driver, partition 0, ANY, 2201 bytes)
21/07/13 16:12:35 INFO executor.Executor: Running task 0.0 in stage 0.0 (TID 0)
21/07/13 16:12:35 INFO executor.Executor: Fetching spark://172.30.128.212:37619/jars/SparkWordCount-1.0-SNAPSHOT.jar with timestamp 1626163953611
21/07/13 16:12:35 INFO spark.ExecutorAllocationManager: New executor driver has registered (new total is 1)
21/07/13 16:12:35 INFO util.Utils: Fetching spark://172.30.128.212:37619/jars/SparkWordCount-1.0-SNAPSHOT.jar to /tmp/spark-da16c47a-9149-48bb-8d38-6548eda3ee0c/userFiles-21dd87bf-7a1f-4c83-849d-c8026f06dfa5/fetchFileTemp7644217065568325884.tmp
21/07/13 16:12:35 INFO executor.Executor: Adding file:/tmp/spark-da16c47a-9149-48bb-8d38-6548eda3ee0c/userFiles-21dd87bf-7a1f-4c83-849d-c8026f06dfa5/SparkWordCount-1.0-SNAPSHOT.jar to class loader
21/07/13 16:12:35 INFO rdd.HadoopRDD: Input split: hdfs://nn:8020/user/hdfs/input/test:0+41
21/07/13 16:12:35 INFO Configuration.deprecation: mapred.tip.id is deprecated. Instead, use mapreduce.task.id
21/07/13 16:12:35 INFO Configuration.deprecation: mapred.task.id is deprecated. Instead, use mapreduce.task.attempt.id
21/07/13 16:12:35 INFO Configuration.deprecation: mapred.task.is.map is deprecated. Instead, use mapreduce.task.ismap
21/07/13 16:12:35 INFO Configuration.deprecation: mapred.task.partition is deprecated. Instead, use mapreduce.task.partition
21/07/13 16:12:35 INFO Configuration.deprecation: mapred.job.id is deprecated. Instead, use mapreduce.job.id
21/07/13 16:12:35 INFO executor.Executor: Finished task 0.0 in stage 0.0 (TID 0). 2181 bytes result sent to driver
21/07/13 16:12:35 INFO scheduler.TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 699 ms on localhost (executor driver) (1/1)
21/07/13 16:12:35 INFO scheduler.TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
21/07/13 16:12:35 INFO scheduler.DAGScheduler: ShuffleMapStage 0 (mapToPair at SparkJavaWordCount.java:38) finished in 0.709 s
21/07/13 16:12:35 INFO scheduler.DAGScheduler: looking for newly runnable stages
21/07/13 16:12:35 INFO scheduler.DAGScheduler: running: Set()
21/07/13 16:12:35 INFO scheduler.DAGScheduler: waiting: Set(ResultStage 1)
21/07/13 16:12:35 INFO scheduler.DAGScheduler: failed: Set()
21/07/13 16:12:35 INFO scheduler.DAGScheduler: Submitting ResultStage 1 (ShuffledRDD[4] at reduceByKey at SparkJavaWordCount.java:45), which has no missing parents
21/07/13 16:12:35 INFO storage.MemoryStore: Block broadcast_2 stored as values in memory (estimated size 2.9 KB, free 529.7 MB)
21/07/13 16:12:35 INFO storage.MemoryStore: Block broadcast_2_piece0 stored as bytes in memory (estimated size 1769.0 B, free 529.7 MB)
21/07/13 16:12:35 INFO storage.BlockManagerInfo: Added broadcast_2_piece0 in memory on localhost:43147 (size: 1769.0 B, free: 530.0 MB)
21/07/13 16:12:35 INFO spark.SparkContext: Created broadcast 2 from broadcast at DAGScheduler.scala:1004
21/07/13 16:12:35 INFO scheduler.DAGScheduler: Submitting 1 missing tasks from ResultStage 1 (ShuffledRDD[4] at reduceByKey at SparkJavaWordCount.java:45) (first 15 tasks are for partitions Vector(0))
21/07/13 16:12:35 INFO scheduler.TaskSchedulerImpl: Adding task set 1.0 with 1 tasks
21/07/13 16:12:35 INFO scheduler.TaskSetManager: Starting task 0.0 in stage 1.0 (TID 1, localhost, executor driver, partition 0, NODE_LOCAL, 1969 bytes)
21/07/13 16:12:35 INFO executor.Executor: Running task 0.0 in stage 1.0 (TID 1)
21/07/13 16:12:35 INFO storage.ShuffleBlockFetcherIterator: Getting 1 non-empty blocks out of 1 blocks
21/07/13 16:12:35 INFO storage.ShuffleBlockFetcherIterator: Started 0 remote fetches in 3 ms
Spark : 1
Hello : 3
Java : 1
! : 3
Scala : 1
21/07/13 16:12:35 INFO executor.Executor: Finished task 0.0 in stage 1.0 (TID 1). 1123 bytes result sent to driver
21/07/13 16:12:35 INFO scheduler.TaskSetManager: Finished task 0.0 in stage 1.0 (TID 1) in 39 ms on localhost (executor driver) (1/1)
21/07/13 16:12:35 INFO scheduler.TaskSchedulerImpl: Removed TaskSet 1.0, whose tasks have all completed, from pool
21/07/13 16:12:35 INFO scheduler.DAGScheduler: ResultStage 1 (foreach at SparkJavaWordCount.java:52) finished in 0.039 s
21/07/13 16:12:35 INFO scheduler.DAGScheduler: Job 0 finished: foreach at SparkJavaWordCount.java:52, took 0.855295 s
21/07/13 16:12:35 INFO spark.SparkContext: Invoking stop() from shutdown hook
21/07/13 16:12:35 INFO ui.SparkUI: Stopped Spark web UI at http://172.30.128.212:4040
21/07/13 16:12:36 INFO spark.MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
21/07/13 16:12:36 INFO storage.MemoryStore: MemoryStore cleared
21/07/13 16:12:36 INFO storage.BlockManager: BlockManager stopped
21/07/13 16:12:36 INFO storage.BlockManagerMaster: BlockManagerMaster stopped
21/07/13 16:12:36 INFO scheduler.OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
21/07/13 16:12:36 INFO remote.RemoteActorRefProvider$RemotingTerminator: Shutting down remote daemon.
21/07/13 16:12:36 INFO remote.RemoteActorRefProvider$RemotingTerminator: Remote daemon shut down; proceeding with flushing remote transports.
21/07/13 16:12:36 INFO spark.SparkContext: Successfully stopped SparkContext
21/07/13 16:12:36 INFO util.ShutdownHookManager: Shutdown hook called
21/07/13 16:12:36 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-da16c47a-9149-48bb-8d38-6548eda3ee0c
21/07/13 16:12:36 INFO Remoting: Remoting shut down
21/07/13 16:12:36 INFO remote.RemoteActorRefProvider$RemotingTerminator: Remoting shut down.
结果截图:
















 1362
1362











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









