







前言
前段时间自己在做计算机网络的期末课设,题目就是关于IP首部检验和的计算程序的实现,要实现这个程序的首要步骤就是要搞明白相关的计算原理。可是我翻来找去,发现课本上对这部分的描述十分的.......干净利索。
IP首部的检验和不采用复杂的CRC检验码而采用下面的简单计算方法:
在发送方,先把IP数据报首部划分为许多16位字的序列,并把检验和字段置零。用反码算术运算把所有16位字相加后,将得到的和的反码写入检验和字段。
接收方收到数据报后,将首部的所有16位字再使用反码算术运算相加一次。将得到的和取反码,即得出接收方检验和的计算结果。
若首部未发生任何变化,则此结果必为0,于是就保留这个数据报。否则即认为出差错。
说句实话,当时我看完这段话之后,本来只有一个问题在阻碍着我,然后一个问题就变成了很多的问题。
既然课本看不懂那我就去网上找找,没想到找到的结果也和课本上差不多,基本没啥用。给的例子看着好像很详细,实际上知识点非常的混乱,东说一句,西说一句,在完全不了解原理之前这些东西简直就是天书(至少在当时的我看来是这样的)。不过好在最后还是通过为数不多的高质量文章知道了如何计算IP首部检验和及其具体计算步骤,所以在这做一个详细的计算方法的总结与说明,以尽可能的帮助那些有类似经历的朋友 。
“什么是IP数据报”,“IP首部检验和是干什么用”,类似的理论叙述就不在这里详细阐述了,直接上方法。
详细计算步骤
要计算IP首部检验和,我们得先知道在IP数据报的固定部分里有什么字段(这个不是套话,很重要),以下12个字段是我们待会在计算过程中使用到的数据。
①版本(Version) ②首部长度(Header Length) ③区分服务(Differentiated Service Field)
④总长度(Total Length) ⑤标识 (Identification) ⑥标志 (Flags)
⑦片偏移(Fragment Offset) ⑧生存时间 (Time to Live) ⑨协议(Protocol)
⑩首部检验和(Header CheckSum) ⑩①源地址(Source Address)
⑩②目的地址 (Destination Address)
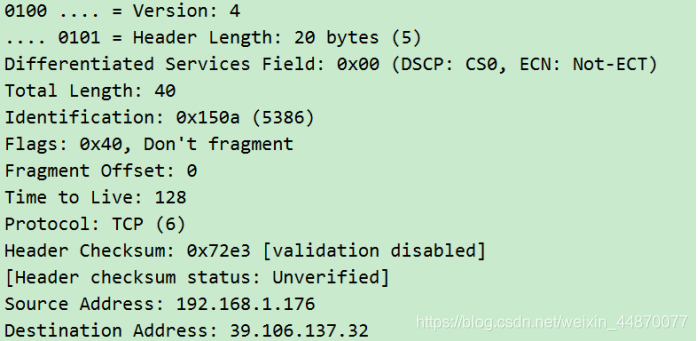
上面这张图是我在WireShark中随机抓取的一个IP数据报的报头部分的数据。
通过分析这个数据报,结合上面说的12个字段,我们可以得到以下信息:
(1)版本 = 4 (2)首部长度 = 5 (3)区分服务 = 0x00 (4)总长度 = 40
(5)标识 = 5386 (0x150a) (6)标志 = 0x40 (7)片偏移 = 0
(8)生存时间 = 128 (9)协议 = 6 (10)首部检验和 = 0x72e3
(11)源地址 = 192.168.1.176 (12)目的地址 = 39.106.137.32
这里稍微介绍一下“协议”字段,课本上对协议的字段值是这么说明的:
协议名 ICMP IGMP IP TCP EGP IGP UDP IPv6 ESP OSPF 协议字段值 1 2 4 6 8 9 17 41 50 89
即什么协议就取其对应的值,上面的数据报里的协议是TCP,所以取的值是6。
在了解了上述知识点后,现在我们可以开始计算了。为了更为直观的说明计算过程,接下来均采用二进制数据作为计算数据。实际上,采用二进制数据进行计算与采用十六进制数据进行计算并无区别,读者可根据自身情况进行选择。
将上述11个字段(除了首部检验和)转为二进制(这里提一嘴,在实际的程序中,包内的首部检验和是要置零然后要参与计算的,但是因为“将首部检验和置零参与计算”和“将首部检验和排除在外然后计算”,这两者在计算结果上没有任何区别。所以,遵循怎么简单怎么来的原则,在下面的计算步骤中就不再涉及首部检验和,大家心里有个数就好),并进行字段拼接。
要注意的是,每个拼接的字段长度均为 16 位(拼接规则:每个字段括号内的数字为该字段转为二进制的最长位数,若该字段转为二进制后小于所规定的最长位数,则在该二进制首位添零,直至达到最长位数)。(“+”表示拼接)
① 版本(4) + 首部长度(4) + 区分服务(8)
② 总长度(16)
③ 标识(16)
④ 标志(8) + 片偏移(8)
⑤ 生存时间(8) + 协议(8)
⑥ 源地址第一部分(8) + 源地址第二部分(8)
⑦ 源地址第三部分(8) + 源地址第四部分(8)
⑧ 目的地址第一部分(8) + 目的地址第二部分(8)
⑨ 目的地址第三部分(8) + 目的地址第四部分(8)
由此,将得到的11个字段通过上述转换,我们可以得到如下数据(“+”表示拼接):
① 0100 0101 0000 0000(4 + 5 + 00)
② 0000 0000 0010 1000(40)
③ 0001 0101 0000 1010(5386)
④ 0100 0000 0000 0000(0x40 + 0)
⑤ 1000 0000 0000 0110(128 + 6)
⑥ 1100 0000 1010 1000(192 + 168)
⑦ 0000 0001 1011 0000(1 + 176)
⑧ 0010 0111 0110 1010(39 + 106)
⑨ 1000 1001 0010 0000(137 + 32)
将这 9 个二进制数据相加,我们可以得到 0010 1000 1101 0001 1010 即 0x2 8d1a
可以看出,累加后的数据发生了进位,即 0b0010(0x0002)部分。
是否发生了进位可以通过位数进行判断,以二进制为例,从最后一位开始向前数 16 位,超出的位数即进位部分(0010),若该二进制数刚好为16 位,则说明未发生进位。
若发生了进位情况,只需要将进位部分(0010)与剩余部分(1000 1101 0001 1010)重新累加,直至得到的二进制数据位数等于 16 位,然后对该二进制数据取反码,即可得到首部检验和。此处可以用递归的思想实现,长度 > 16 继续递归,else return 当前计算结果
0010(进位部分) + 1000 1101 0001 1010(剩余部分) = 1000 1101 0001 1100,此时位数为 16 位,未发生进位,则无需累加。对该二进制取反码,可以得到 0111 0010 1110 0011 即 0x72e3,该计算结果与包内IP首部检验和相同,计算完成。
结语
以上就是IP首部检验和的计算步骤,都是较为详尽的步骤。对刚接触该方法的读者来说,个人建议采用二进制的计算模式,二进制在字段拼接上比较直观易懂,能使读者尽快的了解字段拼接规则。但二进制在计算方面较为冗长,容易在累加的过程中出现错误;如果读者对该计算思想有了较为清晰的认识,可以改为采用十六进制数据进行计算,这样在计算方面会比二进制简短不少,同时也不容易出错。

















 3180
3180

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









