







 本文档介绍了自然语言处理领域的多个工具,如HanLP、Jieba、LTP和NLPIR,重点分析了HanLP的使用,包括安装、运行及功能演示,如分词、词性标注、命名实体识别。通过对比不同工具,作者选择HanLP进行文本处理任务,包括分词、词性标注、命名实体识别、词频统计和词性统计,并生成词云。实验结果显示,去除停用词能提高处理效果,HanLP在处理中文文本时展现出强大的功能。
本文档介绍了自然语言处理领域的多个工具,如HanLP、Jieba、LTP和NLPIR,重点分析了HanLP的使用,包括安装、运行及功能演示,如分词、词性标注、命名实体识别。通过对比不同工具,作者选择HanLP进行文本处理任务,包括分词、词性标注、命名实体识别、词频统计和词性统计,并生成词云。实验结果显示,去除停用词能提高处理效果,HanLP在处理中文文本时展现出强大的功能。
前言
关于自然语言处理,前人已经做过很多工作,拥有耀眼的成就。在有限的作业周期内,仅在中文领域,笔者仍然不能详尽地了解每一个工具的功能。所以,笔者决定先采用“广度优先”的策略,广泛地开展调研,在本报告中纪录下与中文自然语言处理相关的资料,如宗成庆的《统计自然语言处理》[1]。然后,在完成本次作业后,换用“深度优先”的策略,基于报告中记录的资料,继续钻研自然语言处理的模型和工具。
本报告分为四个部分。第一部分介绍以HanLP、Jieba、LTP和NLPIR等为代表的能够处理中文的工具。第二部分展示HanLP的安装和运行过程,并演示了HanLP的基本功能。第三部分记录基于HanLP对作业中的语料进行处理的结果。第四部分总结了本次作业的心得与体会,并给出了笔者使用HanLP的个人感受。最后,第五部分,给出笔者所参考资料的出处。
报告的重点是第三部分文本处理,处理的过程包括分词、词性标注、命名实体识别、词频统计、词性统计五大任务。其中在分词的过程中自定义了分词字典,并且给出了去除停用词和未去除停用词两种版本的结果。后续任务基于去除停用词的分词结果进行。由于分词是词性标注等任务的基础,所以将两者放在同一小节介绍。命名实体识别任务中,具体统计了语料中的人名、地名和机构名三类实体。词频统计和词性统计通过Count实现,基于词频统计的结果,绘制了词云。
分词、词性标注、命名实体识别的结果保存在result1.xls文件中,词频统计、词性统计的结果保存在result2.xls文件中。
一、中文文本处理工具简介
HanLP是面向生产环境的多语种自然语言处理工具包。HanLP支持包括简繁中英日俄法德在内的104种语言上的10种联合任务:分词、词性标注、命名实体识、依存句法分析、成分句法分析、语义依存分析、语义角色标注、词干提取、词法语法特征提取、抽象意义表示。HanLP支持用户基于Python、Java和Go语言进行开发。同时,HanLP推出了云端服务版本HanLP.com[4],用户仅需编写简单程序与RESTful API相连或交互,就能调用云端服务器的各种文本处理功能。

Jieba是Python中文分词组件。Jieba支持中文简体和繁体文本分词,并且用户可以自定义词典。Jieba的开发者目前就职于百度(见下图,开发者在自己的Github首页给出了工作信息),Jieba还拥有与百度开发的PaddlePaddle深度学习框架[6]相互配合的分词模式。Paddle模式,基于训练序列标注(双向GRU)网络模型实现分词,并且支持词性标注。尽管主要开发者只发布了Python版本的Jieba,但是在众多开发者参与下,目前Jieba的版本还包括:Java、C++、Rust、Node.js、Erlang和R等。
LTP(Language Technology Platform)是哈工大社会计算与信息检索研究中心研制的中文语言技术平台。LTP提供了一系列中文自然语言处理工具,用户可以使用这些工具对于中文分词、词性标注、命名实体识别、依存句法分析、语义角色标注等工作。目前针对开发者,LTP拥有C++、Rust、Java和Python[9]版本。同时,为了降低使用LTP的门槛,哈工大推出语言云(LTP-CLOUD)[10],用户无需下载SDK、无需购买高性能的机器,只需要根据API参数构造HTTP请求即可在线调用文本处理工具。
4. NLPIR中文分词系统[11][12]
NLPIR是支持多种编码、操作系统、开发语言与平台的中文分词系统。NLPIR的功能包括:中英文混合分词(、词性标注、命名实体识别、新词识别、关键词提取等。NLPIR的开发者时中科院博士张华平,目前在北京理工大学任教。开发人员既能够下载支持各种操作系统与开发语言的NLPIR SDK,进行二次开发;又能够下载客户端NLPIR-Parser,在无需开发和联网的情况下,处理各类文档。
5. 本章小结
除了上述列出的四种能够进行中文处理的工具外,目前市面上还有其它可行的工具[13],如清华大学的THULAC[14]、斯坦福大学的Stanford Word Segmenter[15]等。
在本次作业中,笔者决定练习使用HanLP,原因有以下两点。
首先,是挑战自己,学习新工具。为了真正有所收获,在完成作业时应该跳出舒适区。Jieba是笔者曾经使用过的工具,挑战性不大,所以不使用Jieba完成作业。NLPIR有友好的图形化操作界面,几乎可以不编写代码,执行各种文本处理任务,完成作业的难度因此下降,所以也不使用NLPIR完成作业。
其次,基于资料,高效掌握新工具。在完成作业的过程中,笔者希望有专家或书籍的指导,以免走弯路,耽误时间和精力。由于笔者能够轻松借阅HanLP开发者何晗所著的《自然语言处理入门》,同时在线阅读HanLP官方文档,于是选择HanLP作为完成作业的工具,便是自然而然的事情了。当然了,后续笔者也会收集和阅读与LTP有关的资料,练习LTP的使用。
二、HanLP使用演示
- 安装jpype1包(HanLP基于Java开发,调用已经开发好的jar包,需要借助jpype1)。进入Python安装目录的命令行界面,输入命令pip install jpype1。

- 安装pyhanlp包(HanLP 1.x[16]的Python接口;HanLP 2.x[2]的Python接口分为RESTful API hanlp_restful和native API的hanlp)。输入命令pip install pyhanlp。

- 测试pyhanlp是否安装成功。打开Anaconda的命令行,输入命令hanlp。

2. 运行配置
- 硬件配置
在本地机上进行实验,CPU型号AMD Ryzen 7 4800U,主频1.8GHz;内存为16G;空闲硬盘容量大于100GB(不一定需要如此大的空间,只是本地机的实际情况)。
- 软件配置
由于HanLP基于Java开发,所以运行HanLP,需要配置JDK。

除了上述的jpype1包和pyhanlp包外,还有一些Python的包,需要使用pip命令安装(就不一一列出)。如将最终结果存储为Excel格式故需要xlrd包、字符串的匹配故需要用到re包等、pyhanlp功能测试故需要absl-py包。
综上,软件配置如下表所示:
| 名称 | 版本号 |
| Windows | 10 |
| Python | 3.8 |
| JDK | 11 |
| jpype1 | 0.7 |
| pyhanlp | 0.1.66(HanLP 1.x) |
| xlrd | 1.2.0 |
| re | Python标准库自带 |
| absl-py | 0.1.10 |
为了方便结果的可视化,使用Jupyter Notebook进行功能演示。
- 分词和词性标注
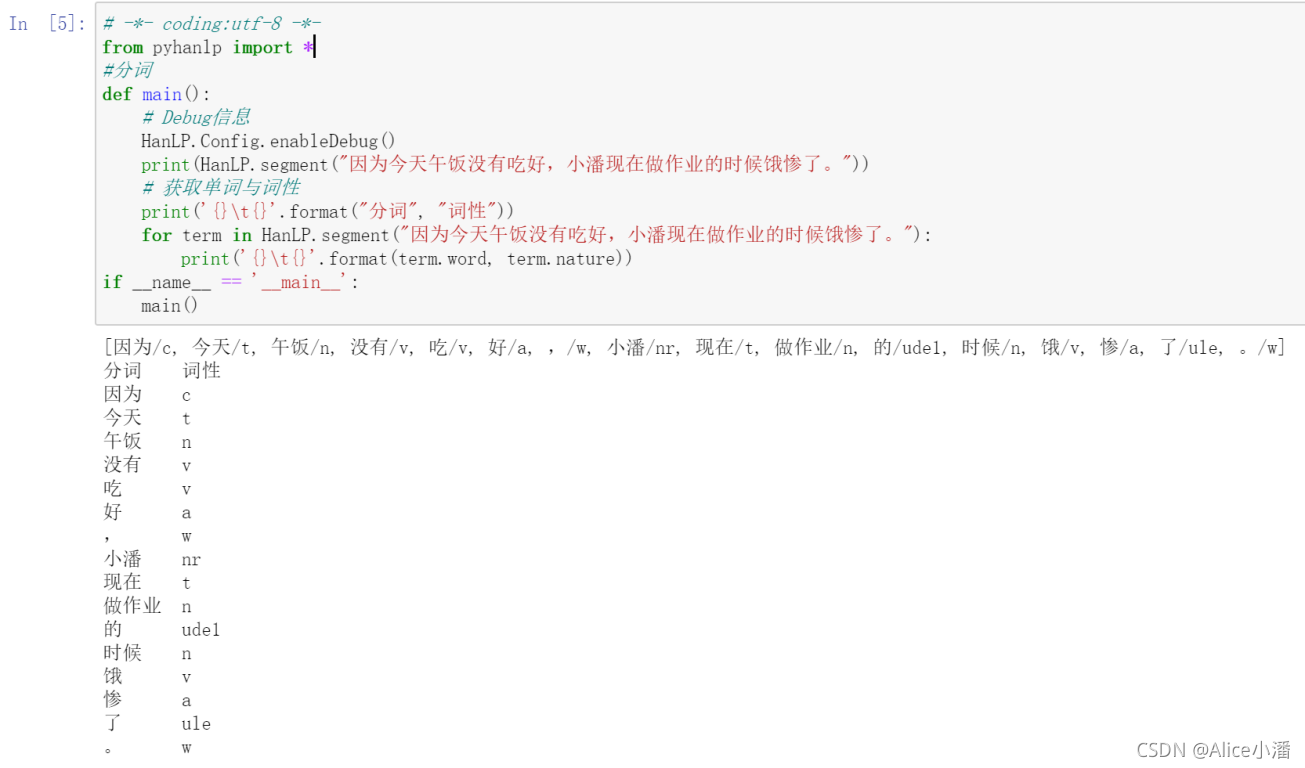
- 关键词提取
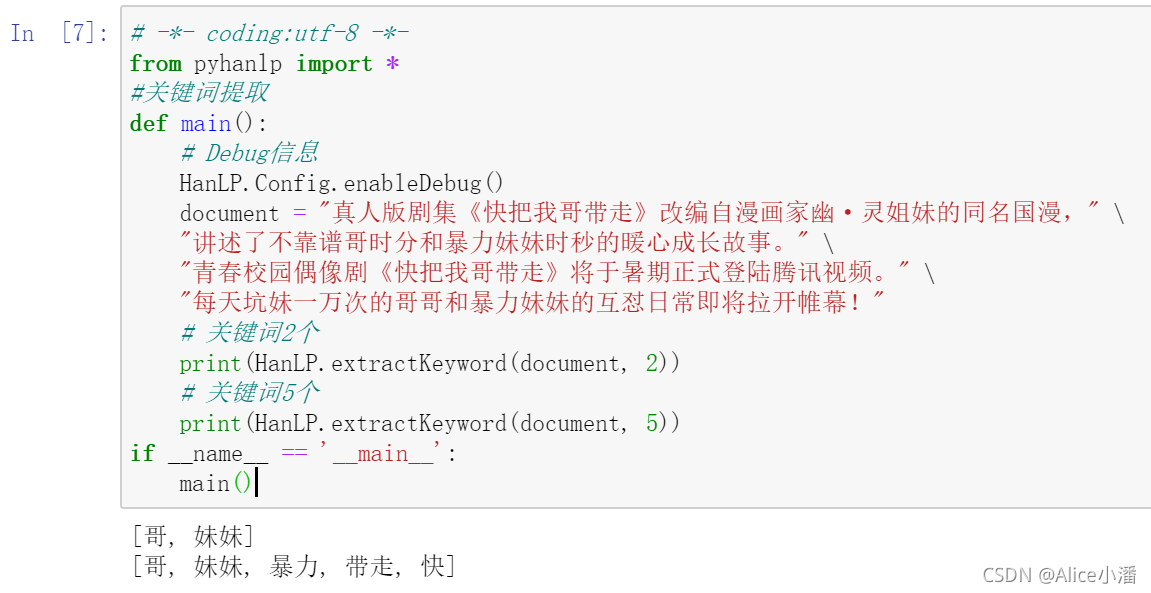
- 摘要生成

- 依存词法分析

HanLP.parseDependency返回的结果很有意思,笔者想弄清楚它的返回形式,所以开始查看源代码。
回溯HanLP.,找到Java文件的位置。
在com.hankcs.hanlp.corpus.dependency.CoNll.CoNLLWord中。

故返回值类型分别是:
- ID 当前词在句子中的序号
- LEMMA 当前词语(或标点)的原型或词干
- LEMMA 当前词语(或标点)的原型或词干
- CPOSTAG 当前词语的词性(粗粒度)
- POSTAG 当前词语的词性(细粒度)
- HEAD.ID 当前词语的中心词的序号
- DEPREL 当前词语与中心词的依存关系

- 其它功能
除了上述功能外,HanLP还能实现情感分析、文本聚类和分类等任务,在本报告中就不再一一列举。
三、文本处理记录
1. 需求说明
整体程序的流程图如下所示:
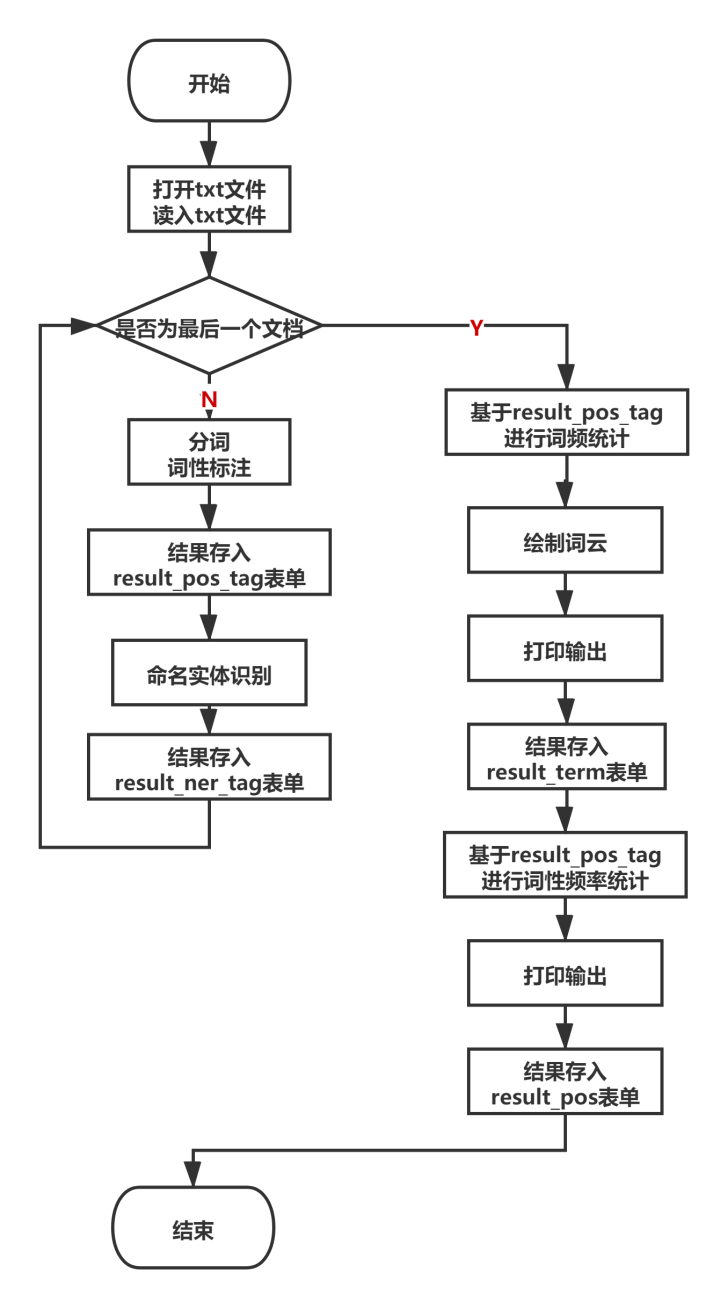
文本处理的任务分为以下5个:
- 分词(丰富原有字典、丰富原有停用词表) 每个文档
- 词性标注 每个文档
备注:以上结果用Excel文件中的两张表单存储
(使用了停用词的result_pos_tag_sw和未使用停用词的result_pos_tag_no_sw)。
- 命名实体识别 每个文档
备注:以上结果用Excel文件中的一张表单存储(result_ner_tag)。
- 统计词频(绘制词云) 所有文档
备注:控制台打印输出,格式为Term tFrequency tPercentage;绘制词云;用Excel文件中的一张表单存储(result_term)。
- 统计词性频率 所有文档
备注:控制台打印输出,格式为POS tFrequency;用Excel文件中的一张表单存储(result_pos)。
2. 代码
数据和结果文件见GitHub
# -*- coding:utf-8 -*-
import re
from pyhanlp import *
import xlwt
import xlrd
from collections import Counter
from wordcloud import WordCloud
import matplotlib.pyplot as plt
# **************1 打开文件 分割文档**************
with open("分词作业语料.txt", "r", encoding="utf-8") as f:
# 读取文件
data = f.read()
# 正则化匹配 分割文档
# 正则表达式 不能识别作为字符串的*
data1 = data.replace("*", "'")
ex = "''''''''\n\n(.*?)\n\n''''''''"
document = re.findall(ex, data1, re.S)
# **************2 分词 词性标注**************
# 结果存入result_pos_tag表单
workbook = xlwt.Workbook()
# 使用停用词表
sheet1 = workbook.add_sheet('result_pos_tag_sw', cell_overwrite_ok=True)
sheet1.write(0, 0, 'document id')
sheet1.write(0, 1, 'term')
sheet1.write(0, 2, 'pos tag')
CoreStopWordDictionary = JClass("com.hankcs.hanlp.dictionary.stopword.CoreStopWordDictionary")
CustomDictionary = JClass("com.hankcs.hanlp.dictionary.CustomDictionary")
# CoreStopWordDictionary.add("渴望") # 新增停用词
CustomDictionary.add("西安奥体中心", "ns") # 自定义字典
CustomDictionary.insert("马龙", "nr")
# print(CustomDictionary.get("马龙"))
doc_id = 1
row_id = 1
segment = HanLP.newSegment()
segment.enablePartOfSpeechTagging(True)
for doc in document:
# 剔除文档中的换行符等
temp = doc.replace("\n", "")
temp = temp.replace("\u3000", "")
temp = temp.replace("\xe3\x80\x80\xe3\x80\x80", "")
for term in CoreStopWordDictionary.apply(segment.enableCustomDictionaryForcing(True).seg(temp)):
sheet1.write(row_id, 0, doc_id)
sheet1.write(row_id, 1, str(term.word))
sheet1.write(row_id, 2, str(term.nature))
row_id = row_id + 1
doc_id = doc_id + 1
# 未使用停用词表
sheet2 = workbook.add_sheet('result_pos_tag_no_sw', cell_overwrite_ok=True)
sheet2.write(0, 0, 'document id')
sheet2.write(0, 1, 'term')
sheet2.write(0, 2, 'pos tag')
# 分词 词性标注
doc_id = 1
row_id = 1
for doc in document:
# 剔除文档中的换行符等
temp = doc.replace("\n", "")
temp = temp.replace("\u3000", "")
temp = temp.replace("\xe3\x80\x80\xe3\x80\x80", "")
for term in HanLP.segment(temp):
sheet2.write(row_id, 0, doc_id)
sheet2.write(row_id, 1, str(term.word))
sheet2.write(row_id, 2, str(term.nature))
row_id = row_id + 1
doc_id = doc_id + 1
# **************3 命名实体识别**************
# 结果存入result_ner_tag表单
sheet3 = workbook.add_sheet('result_ner_tag', cell_overwrite_ok=True)
sheet3.write(0, 0, 'document id')
sheet3.write(0, 1, 'term')
sheet3.write(0, 2, 'ner tag')
doc_id = 1
row_id = 1
# 人名识别
nrsegment = HanLP.newSegment().enableNameRecognize(True)
nrsegment.enableCustomDictionaryForcing(True)
nrsegment.enablePartOfSpeechTagging(True)
# 机构识别
ntsegment = HanLP.newSegment().enableOrganizationRecognize(True)
ntsegment.enablePartOfSpeechTagging(True)
# 地名识别
nssegment = HanLP.newSegment().enableOrganizationRecognize(True)
nssegment.enablePartOfSpeechTagging(True)
for doc in document:
# 剔除文档中的换行符等
temp = doc.replace("\n", "")
temp = temp.replace("\u3000", "")
temp = temp.replace("\xe3\x80\x80\xe3\x80\x80", "")
for term in nrsegment.seg(doc):
if str(term.nature) == "nr":
sheet3.write(row_id, 0, doc_id)
sheet3.write(row_id, 1, str(term.word))
sheet3.write(row_id, 2, "人名")
row_id = row_id + 1
for term in ntsegment.seg(doc):
if str(term.nature) == 'nt':
sheet3.write(row_id, 0, doc_id)
sheet3.write(row_id, 1, str(term.word))
sheet3.write(row_id, 2, "机构")
row_id = row_id + 1
for term in nssegment.seg(doc):
if str(term.nature) == 'ns':
sheet3.write(row_id, 0, doc_id)
sheet3.write(row_id, 1, str(term.word))
sheet3.write(row_id, 2, "地点")
row_id = row_id + 1
doc_id = doc_id + 1
workbook.save('result1.xls')
# **************4 统计词频**************
data = xlrd.open_workbook('result1.xls')
table = data.sheet_by_index(0)
c = Counter()
for x in table.col_values(1)[1:1171]:
c[x] += 1
# 绘制词云
wordcloud = WordCloud(
font_path="C:/Windows/Fonts/simsun.ttc",
background_color="white",
width=1000,
height=1000,
max_words=100, # 显示最大词数
min_font_size=50,
max_font_size=200,
colormap='winter'
)
wordcloud.fit_words(c)
plt.figure(figsize=(8, 8), dpi=72)
plt.imshow(wordcloud, interpolation='bilinear') # 绘制数据内的图片,双线性插值绘图
plt.axis("off") # 去掉坐标轴
plt.savefig('termCount.jpg', dpi=300) # 指定分辨率保存
workbook = xlwt.Workbook()
sheet1 = workbook.add_sheet('result_term', cell_overwrite_ok=True)
sheet1.write(0, 0, 'term')
sheet1.write(0, 1, 'tfrequency')
sheet1.write(0, 2, 'tpercentage')
row_id = 1
print("词", '\\', "频次", '\\', "百分比")
for (k, v) in c.most_common():
perc = '{:.1f}%'.format(v/1169*100)
sheet1.write(row_id, 0, k)
sheet1.write(row_id, 1, v)
sheet1.write(row_id, 2, perc)
print(k, '\\', v, '\\', perc)
row_id = row_id + 1
# **************5 统计词性频次**************
table = data.sheet_by_index(0)
c = Counter()
for x in table.col_values(2)[1:1171]:
c[x] += 1
sheet2 = workbook.add_sheet('result_pos', cell_overwrite_ok=True)
sheet2.write(0, 0, 'pos')
sheet2.write(0, 1, 'pfrequency')
row_id = 1
print("词性", '\\', "频次")
for (k, v) in c.most_common():
perc = '{:.1f}%'.format(v/1169*100)
sheet2.write(row_id, 0, k)
sheet2.write(row_id, 1, v)
print(k, '\\', v)
row_id = row_id + 1
workbook.save('result2.xls')
3. 词性标注
基于HanLP提供的基础分词器,逐渐修正分词字典和停用词表,是分词器适用于本文档集合。值得一提的是,HanLP默认初始分词字典的优先级高,所以可能会出现添加了分词的新词,但是分词结果与之相悖的情况。为了应对这种错误,需要开发者编写代码,将自定义字典的优先级设高。为了体现出自定义字典的重要性,还进行了未修正分词字典和停用词表的分词和词性标注实验。
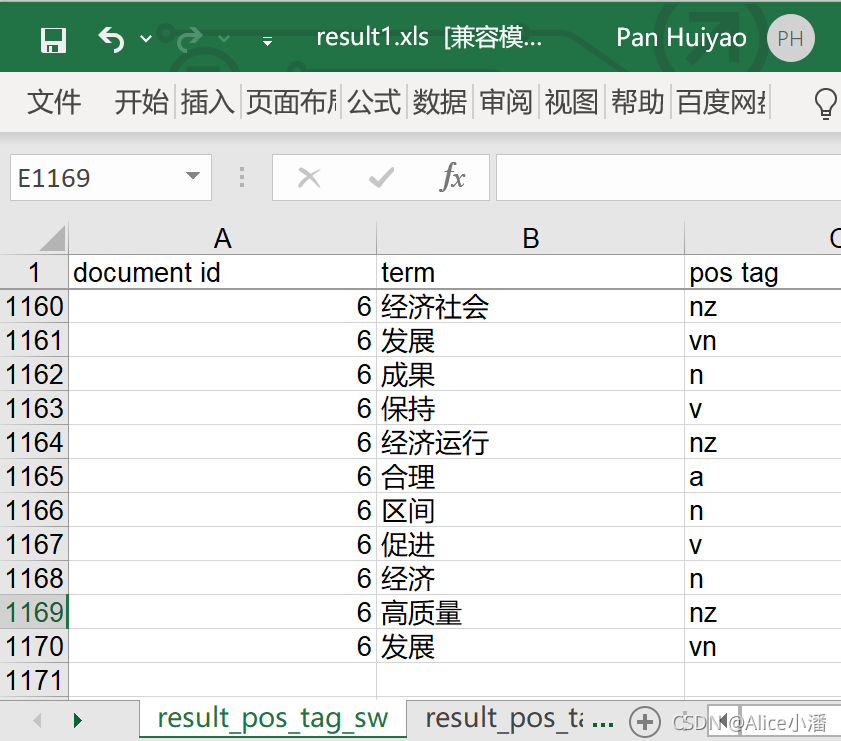
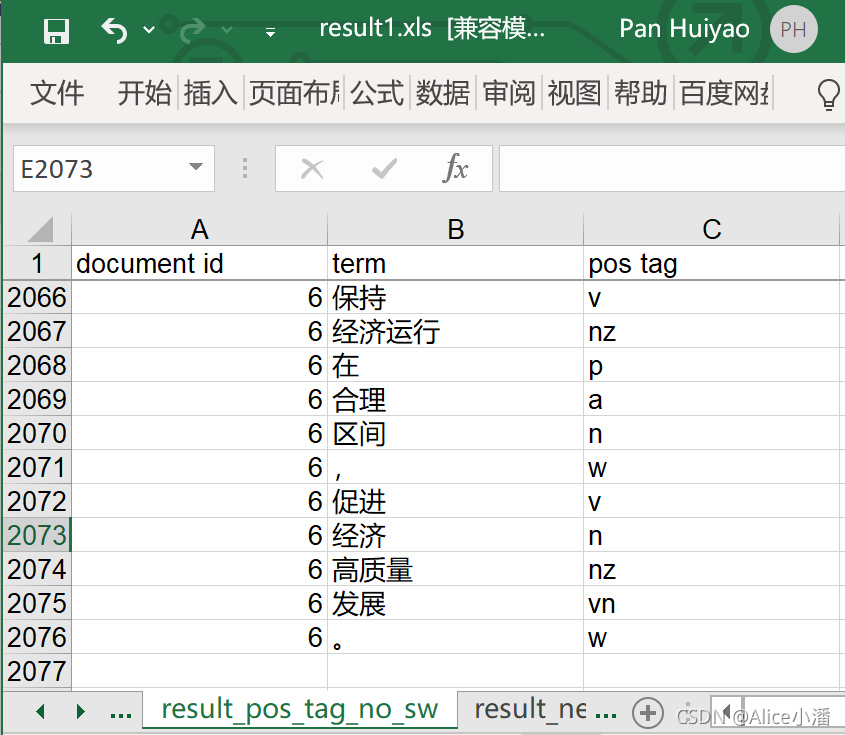
从结果中可以看出,如果不去除停用词,标点符号等字符串也会被分词,结果记录有2075条;而去除停用词后,结果有1169条。HanLP的词性标注结果参照北大词性标注标准[17],如p表示介词(英语介词prepositional的第1个字母)、q表示量词(英语quantity的第1个字母)、r表示代词(英语代词pronoun的第2个字母,因p已用于介词)。一般情况下,建议使用去除停用词的结果
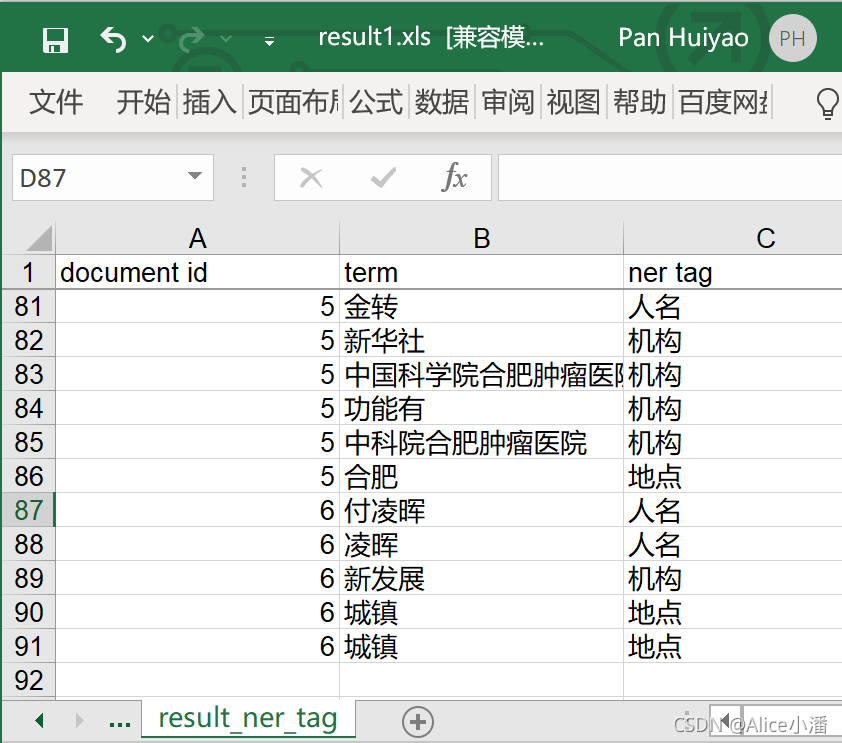
4. 命名实体识别
HanLP支持人名识别、地名识别、机构名识别,用户可以自定义实体字典,可以在分词阶段修正字典时完成,只需要给新增的词添加相应的实体标签即可。
命名实体识别关键程序有以下三条,功能分别是人名、地名和机构名的识别。
HanLP.newSegment().enableNameRecognize(true)
HanLP.newSegment().enablePlaceRecognize(true)
HanLP.newSegment().enableOrganizationRecognize(true)
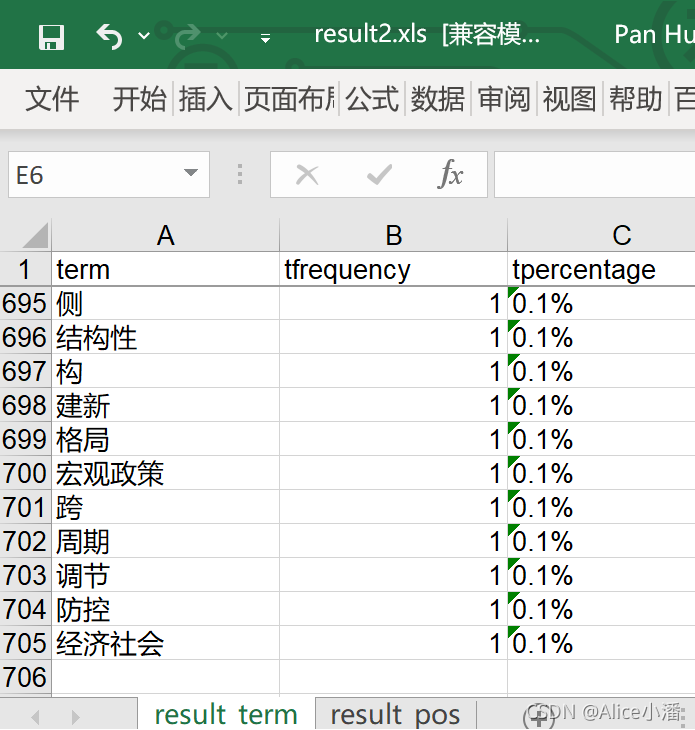
词频统计通过Count实现,统计和计算得出了每个词出现的频次和百分比。基于词频统计的结果,绘制了词云。

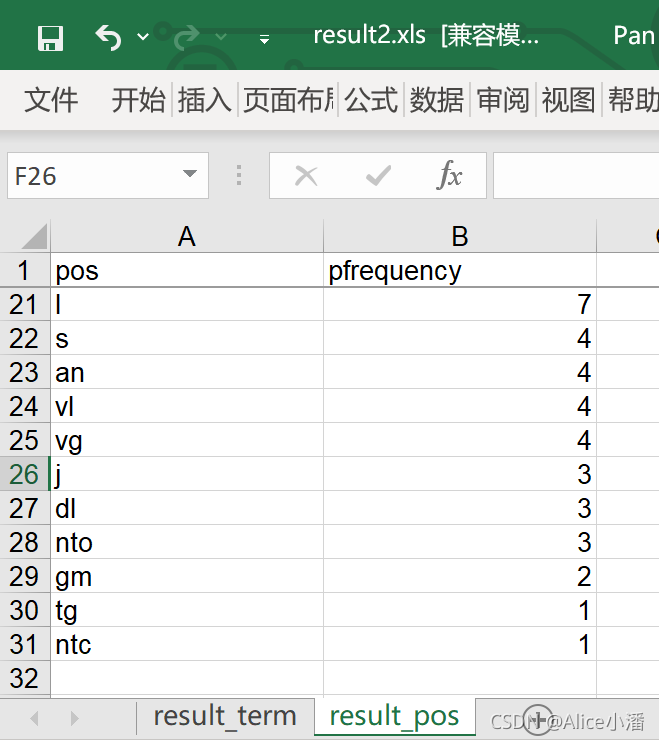
6. 词性统计
词性统计通过Count实现,统计和计算得出了每个词性出现的频次。其中名词n、动词v、名动词vn出现的频次最高。
四、实验总结
在实验的过程中,不可避免的犯了一些低级的错误,如:
- 自己定义的文件名与Python已有的包名重合,导致运行错误。
- 试图通过正则化识别*,但是忽视了在正则化的规则中,*被作为保留字符,有特殊含义,导致运行错误。
实验的结果还能够继续优化,如:
- 自定义的字典和停用词表还能够更精细。
- 可以多试几种分词和命名实体识别模型(隐马、感知机序列、条件随机场等),找到最适合本文档集合的模型。
最后,对于HanLP,笔者的使用心得如下:
- 难度较大,底层代码用java编写,在Python程序编写的过程中,调用各类接口需要遵循java语言的规则,想要查看源代码找解决方案的过程比较复杂。
- 专业性强,更适合NLP领域的专业开发者使用,HanLP涵盖了自然语言处理的很多模型,并且代码开源,适合专业开发者根据需求,参考HanLP源代码,创建自己的文本分析模型。
五、参考资料
- 宗成庆 2013. 统计自然语言处理 第2版., 北京: 清华大学出版社.
- GitHub - hankcs/HanLP https://github.com/hankcs/HanLP
- 何晗 2019. 自然语言处理入门, 北京: 人民邮电出版社.\
- HanLP官网 HanLP官网
- GitHub - fxsjy/jieba https://github.com/fxsjy/jieba
- 飞桨PaddlePaddle 飞桨PaddlePaddle-源于产业实践的开源深度学习平台
- GitHub - HIT-SCIR/ltp https://github.com/HIT-SCIR/ltp
- 语言技术平台( Language Technology Plantform | LTP ) 语言技术平台( Language Technology Plantform | LTP )
- Ltp Python Package Index (PyPI) ltp · PyPI
- 语言云(语言技术平台云 LTP-Cloud) 语言云(语言技术平台云 LTP-Cloud)
- GitHub - NLPIR-team/NLPIR https://github.com/NLPIR-team/NLPIR
- NLPIR-ICTCLAS汉语分词系统-首页 NLPIR-ICTCLAS汉语分词系统-首页
- 知乎 有哪些比较好的中文分词方案? 竹间智能 Emotibot的回答 有哪些比较好的中文分词方案? - 知乎
- GitHub - thunlp/THULAC https://github.com/thunlp/THULAC
- The Stanford Natural Language Processing Group The Stanford Natural Language Processing Group
- GitHub - hankcs/pyhanlp https://github.com/hankcs/pyhanlp
17. 分词词性标注北大标准 分词:词性标注北大标准_John.Deng的专栏-CSDN博客

















 1319
1319

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









