









一、前言
我们在使用python进行数据分析时,常需选取部分行列数据作组合运算,这就用到loc&iloc函数。
二、详细用法
loc()函数使用索引标签获取行子集,iloc()函数通过行号(即位置)获取行子集。
1、首先生成一个csv文件作为实验DataFrame
import pandas as pd
import csv
with open('data.csv','w',encoding='utf-8',newline='') as csvfile:
fieldnames = ['id','name','age','sex']
writer = csv.DictWriter(csvfile,fieldnames)
writer.writeheader()
writer.writerow({'id':12,'name':'Tom','age':13,'sex':'woman'})
writer.writerow({'id':13,'name':'Jack','age':14,'sex':'man'})
writer.writerow({'id':14,'name':'Rose','age':15,'sex':'woman'})
df = pd.read_csv('data.csv',encoding='utf-8')
df.index = ['A','B','C']
print(df)
2、选取不连续的行和列
2.1、选取不连续的行(列表嵌套的形式)
2.1.1、选取单行或位置不成等差数列的多行
#选取 索引标签为A 且位置为0 的单行
print(df.loc['A']) #loc
print('='*15)
print(df.iloc[0]) #iloc
print('*'*30)
#选取 索引标签为A和B 且位置为0和1 的多行
print(df.loc[['A','B']]) #嵌套列表形式
print('='*15)
print(df.iloc[[0,1]])
print('*'*30)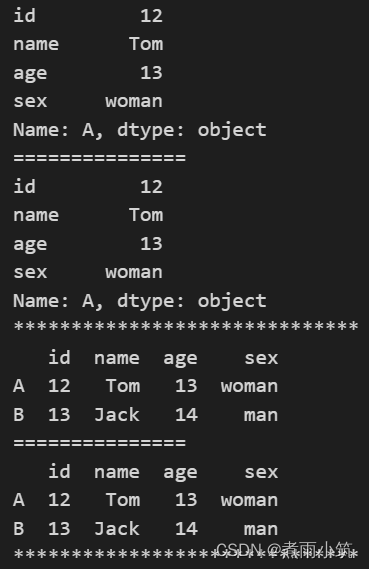
2.1.2、选取位置成等差数列的多行
如选取位置为1、3、5、7...等行 。此时使用切片语法。(注意loc和iloc的区别)
[A:B:C]
#若A、B、C代表索引位置,即运用iloc()函数,则表示从A开始(包括A) 到 B结束(不包括B) 每隔(C-1)个元素进行选取
#若A、B、C代表索引标签,即运用loc函数,则表示从A开始(包括A) 到 B结束(包括B) 每隔(C-1)个元素进行选取特别注意一下loc()函数
#间隔一行选取
print(df.iloc[0:2:2]) #选取了第一行
print('='*20)
print(df.loc['A':'C':2]) #选取A行和C行 特别注意这里不同于iloc的语法
print('*'*35)
#不写到哪结束,默认一直到最后一行
print(df.iloc[0::2])
print('='*20)
print(df.loc['A'::2])
print('*'*35)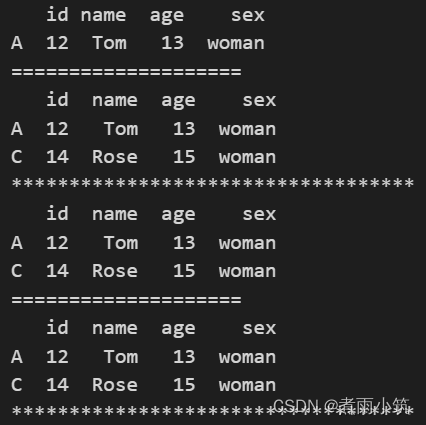
2.2、选取不连续的列
[:,] #逗号将列表分成两部分,左边进行 行的操作,右边进行 列的操作2.2.1、选取单列或位置不成等差数列的多列
#选取 索引标签为id 且位置为0 的单列
print(df.loc[:,'id'])
print('='*15)
print(df.iloc[:,0])
print('*'*30)
#选取 索引标签为name和age 且位置为0和1 的多列
print(df.loc[:,['id','name']])
print('='*15)
print(df.iloc[:,[0,1]])
print('*'*30)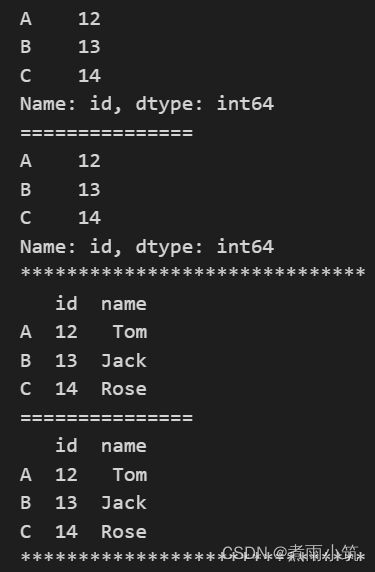
2.2.2、选取位置成等差数列的多行
语法同2.1.2
#从第1列开始(包括第一列)到第三列结束(不包括第3列)每隔一列选取
print(df.iloc[:,0:3:2]) #选取了第一列和第三列
print('='*20)
print(df.loc[:,'id':'sex':2]) #选取第一列和第三列
print('*'*35)
#不写到哪结束,默认一直到最后一列
print(df.iloc[:,0::2])
print('='*20)
print(df.loc[:,'id'::2])
print('*'*35)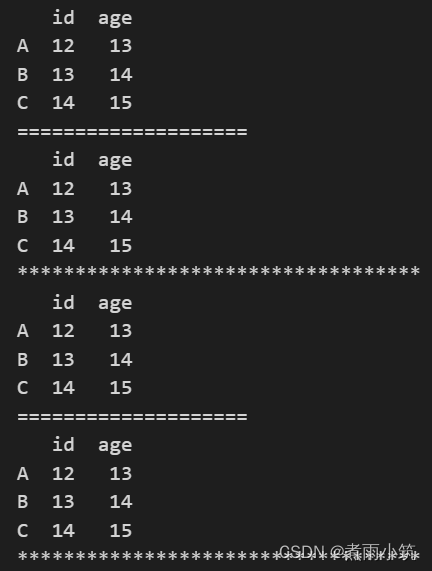
3、选取连续的行和列 (特别注意一下)
##选取连续行 #注意一下
print(df.iloc[0:2]) #选取第1、2行
print('='*20)
print(df.loc['A':'C']) #选取A、B、C即1、2、3行。这里切片语法 不同于 上面iloc的
print('*'*35)
##选取连续列 #注意一下
print(df.iloc[:,0:3]) #选取1、2、3列
print('='*20)
print(df.loc[:,'id':'sex']) #选取id、name、age、sex四列。这里切片语法 不同于 上面iloc的
print('*'*35)
4、同时选取行和列
同时选取行和列就是2、3两节语法的综合。
[index,columns] #逗号将列表分成两部分,左边进行 行的操作,右边进行 列的操作,将2、3节的语法填入即可以上就是本文的全部内容了,若有错误,欢迎各位读者批评指正!















 449
449











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











