






1、如果groupby的列中存在空值,则该分组将被忽略
import pandas as pd import numpy as np def test_groupby(group): """测试groupby函数""" if set(['group1', 'group2']).intersection(set(data.columns)): group['flag'] = 1 else: group['flag'] = 0 return group data = pd.DataFrame({'group1': ['a', 'a', 'b', 'b', np.NaN, 'c'], 'group2': [np.NaN, 'd', 'e', 'e', 'f', 'f'], 'value1': [1, 2, 3, 4, 5, 6]}) df = data.groupby(['group1', 'group2']).apply(lambda x: test_groupby(x)).reset_index(drop=True) df
如上,按照group1和group2进行分组统计,但是group1和group2中分别存在空值,输出结果如下,
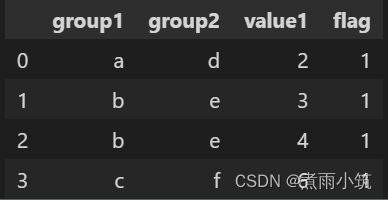
而原data数据如下,
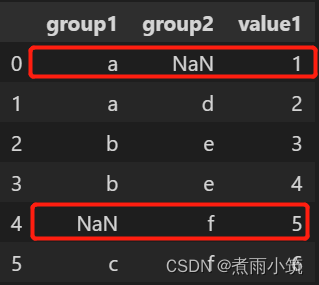
可以对比看到图中红框所示在groupby之后被忽略掉了。
如果想保留红框数据,使其能够参与到groupby的过程,可以在groupby之前对分组字段(即上面的group1、group2进行空值填充),如下,
import pandas as pd
import numpy as np
def test_groupby(group):
"""测试groupby函数"""
if set(['group1', 'group2']).intersection(set(data.columns)):
group['flag'] = 1
else:
group['flag'] = 0
return group
data = pd.DataFrame({'group1': ['a', 'a', 'b', 'b', np.NaN, 'c'],
'group2': [np.NaN, 'd', 'e', 'e', 'f', 'f'],
'value1': [1, 2, 3, 4, 5, 6]})
# 对分组字段进行空值填充
data.fillna({'group1': '', 'group2': ''}, inplace=True)
df = data.groupby(['group1', 'group2']).apply(lambda x: test_groupby(x)).reset_index(drop=True)
df
其输出结果如下,

可见所有数据均参与到了groupby的过程。
















 6427
6427











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











