










1. 正则表达式的介绍
正则表达式(Regular Expression,简称:Regex)是一种文本模式的表示方法,它使用单个字符串来描述、匹配一系列符合某个句法规则的字符串。正则表达式常用于字符串的搜索、替换以及复杂的字符串模式匹配操作。
正则表达式由普通字符(例如字符 a 到 z)和特殊字符(称为元字符)组成,它在不同的编程语言和工具中有着广泛的应用,例如 Python、JavaScript、Perl、Java 等语言,以及文本编辑器、搜索工具等软件中。
正则表达式的能力非常强大,可以用于各种复杂的字符串处理任务,如数据验证、数据提取、数据替换等。然而,编写复杂的正则表达式可能比较困难,需要一定的学习和实践。
2. 小例子
一个文本文件里面存储了一些市场职位信息,格式如下所示:
Python3 高级开发工程师 上海互教教育科技有限公司上海-浦东新区2万/月02-18满员
测试开发工程师(C++/python) 上海墨鹍数码科技有限公司上海-浦东新区2.5万/每月02-18未满员
Python3 开发工程师 上海德拓信息技术股份有限公司上海-徐汇区1.3万/每月02-18剩余11人
测试开发工程师(Python) 赫里普(上海)信息科技有限公司上海-浦东新区1.1万/每月02-18剩余5人
Python高级开发工程师 上海行动教育科技股份有限公司上海-闵行区2.8万/月02-18剩余255人
python开发工程师 上海优似腾软件开发有限公司上海-浦东新区2.5万/每月02-18满员
现在,我们需要写一个程序,从这些文本里面抓取所有职位的薪资。
这是典型的字符串处理。分析这里面的规律,可以发现,薪资的数字后面都有关键字 万/月 或者 万/每月。根据我们学过的知识,我们不难写出下面的代码:
# 打开指定文本,获取文本中的内容
with open('Python/正则表达式/code/exp1.txt', 'r') as f:
lines = f.readlines()
# 遍历每一行
for line in lines:
# 查找'万/月'在字符串中的索引
pos2 = line.find('万/月') # 如果没有找到则返回-1
if pos2 == -1: # 说明 '万/月' 没有找到
pos2 = line.find('万/每月') # 查找 '万/每月' 在字符串中的索引
if pos2 == -1: # 说明 '万/每月' 也没有找到
continue
# 找到了 '万/月' 或者 '万/每月'
idx = pos2 - 1 # 数字的末尾索引
# 往前找
while line[idx].isdigit() or line[idx] == '.': # 如果前面的是数字或者小数点
idx -= 1 # 继续往前找
# 现在我们可以确定数字的索引范围了
pos1 = idx + 1
print(line[pos1: pos2], '万/每月')
运行结果:
2 万/每月
2.5 万/每月
1.3 万/每月
1.1 万/每月
2.8 万/每月
2.5 万/每月
💡 关于
'Python/正则表达式/code/exp1.txt':自己新建一个.txt文本,将内容放入文件即可。
为了从每行获取薪资对应的数字,我们写了不少行代码,这种从字符串中搜索出某种特征的子串有没有更简单的方法呢?解决方案就是我们今天要介绍的正则表达式(Regular Expression)。如果我们使用正则表达式,代码可以这样:
import re # re: regular expression
# 打开指定文本,获取文本中的内容
with open('Python/正则表达式/code/exp1.txt', 'r') as f:
lines = f.readlines()
text = ''.join(lines) # 使用 join 方法将列表转换为字符串
p = re.compile('([\d.]+)万/每{0,1}月')
for one in p.findall(text):
print(f"{one} 万/月")
2 万/每月
2.5 万/每月
1.3 万/每月
1.1 万/每月
2.8 万/每月
2.5 万/每月
p = re.compile('([\d.]+)万/每{0,1}月') 的组成部分的解释:
re.compile: 这是 Python 中re模块的一个函数,用于编译一个正则表达式模式,返回一个模式(pattern)对象,该对象可以用于匹配文本。([\d.]+): 这是一个捕获组(group),用于匹配一个或多个数字(\d表示任何数字,包括 0-9)或小数点(.)。+表示匹配前面的子表达式一次或多次。这个捕获组将匹配一个数字序列,可能包含小数点,例如2.5。万/每{0,1}月: 这部分匹配文本“万/每月”或“万/月”。这里使用了量词{0,1},它表示前面的字符“每”可以出现 0 次或 1 次。这意味着既可以匹配“万/每月”,也可以匹配“万/月”。
3. 在线验证
怎么验证我们写的表达式是否能正确匹配到要搜索的字符串呢?可以访问 regex101,从而进行在线验证。Fig.1 即为示意图。

4. Regular Expression 常见语法
4.1 普通字符
写在正则表达式里面的普通字符都是表示: 直接匹配它们。比如在下面的文本中,如果我们要找所有的 test,正则表达式就非常简单,直接输入 test 即可。如 Fig.2 所示:
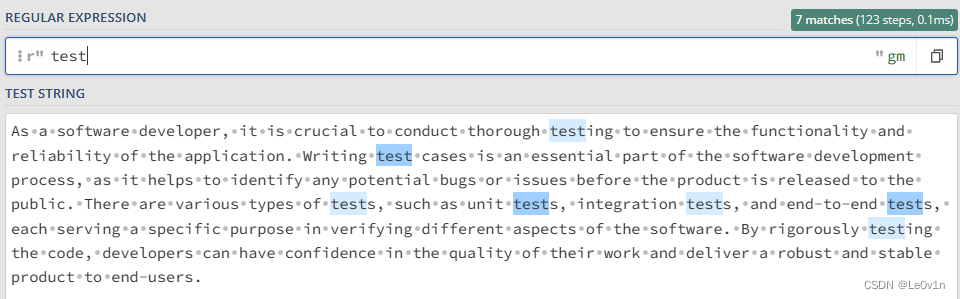
汉字也是一样,要寻找汉字,直接写在正则表达式里面就可以了。
4.2 特殊字符(Meta Characters)
但是有些特殊的字符,术语叫 metacharacters(元字符)。它们出现在正则表达式字符串中,不是表示直接匹配他们,而是表达一些特别的含义。
关于 Meta 的介绍可以参考:什么是 metadata(元数据、meta、metadata、诠释资料、元资料)
这些特殊的元字符及其含义如 Table.1 所示。
| 符号 | 描述 |
|---|---|
. | 匹配除换行符 \n 之外的任意单个字符。 |
* | 匹配前面的元素零次或多次。 |
+ | 匹配前面的元素一次或多次。 |
? | 匹配前面的元素零次或一次。在量词后使用时,可以使量词变为非贪婪模式。 |
\ | 转义字符,用于匹配特殊字符,让它们被视为普通字符。 |
[] | 用于创建字符类,匹配方括号内的任意一个字符。 |
^ | 匹配行的开始。在字符类内部使用时,表示取非,匹配不在方括号内的任意一个字符。 |
$ | 匹配行的结束。 |
{m,n} | 匹配前面的元素至少 m 次,至多 n 次。 |
| | 逻辑或操作符,匹配符号前后的表达式中的任意一个。 |
() | 分组操作符,将括号内的表达式作为一个整体进行处理,并可以捕获匹配的子字符串以供后续使用。 |
接下来我们分别介绍这些特殊字符。
4.2.1 特殊字符: .(通配符:匹配除换行符外的所有字符)
. 又名通配符,表示要匹配除了 换行符 \n之外的任意 单个 字符。比如,要从下面的文本中,选择出所有的颜色。
苹果是绿色的
橙子是橙色的
香蕉是黄色的
乌鸦是黑色的
也就是要找到所有以 色 结尾,并且包括前面的一个字符的 词语。就可以这样写正则表达式:
.色
其中 . 代表了任意的一个字符。
.色 合起来就表示要找任意一个字符后面是 色 这个字,合起来两个字的字符串。验证一下,如 Fig.3 所示:

我们也在 Python 中以代码的形式演示一下:
import re
content = """苹果是绿色的
橙子是橙色的
香蕉是黄色的
乌鸦是黑色的
"""
pattern = re.compile(pattern=".色")
for item in pattern.findall(string=content):
print(item)
绿色
橙色
黄色
黑色
高亮行 re.compile 函数返回的是正则表达式对象,它对应的匹配规则在参数中进行定义。之后我们可以调用这个对象的 findall 方法来进行正则表达式搜索操作。
💡 如果我们只是一次性使用这个匹配规则,可以不用先 re.compile 产生正则表达式对象,可以直接使用 re.findall 函数,相当于我们直接调用了一个静态方法(函数)。
import re
content = """苹果是绿色的
橙子是橙色的
香蕉是黄色的
乌鸦是黑色的
"""
for item in re.findall(pattern='.色',
string=content):
print(item)
绿色
橙色
黄色
黑色
Question:特殊字符 . 可以匹配除了 \n 外的特殊字符吗?
Answer:特殊字符 . 在正则表达式中被称为“通配符”,它能够匹配除换行符 \n 以外的任意单个字符,包括特殊字符。例如,如果我们的正则表达式是 a.c,它将匹配以下字符串:
abca*ca@ca c(其中
在上述例子中,. 能够匹配任意单个字符,包括特殊字符如 *、@ 和空格。需要注意的是,. 对换行符 \n 不起作用,如果我们想要匹配包括换行符在内的任意字符,需要使用特殊的模式或者标志,如在 Python 的 re 模块中使用 re.DOTALL 标志。
💡
.也是可以匹配.的 🤣
4.2.2 特殊字符:*(重复匹配任意次)
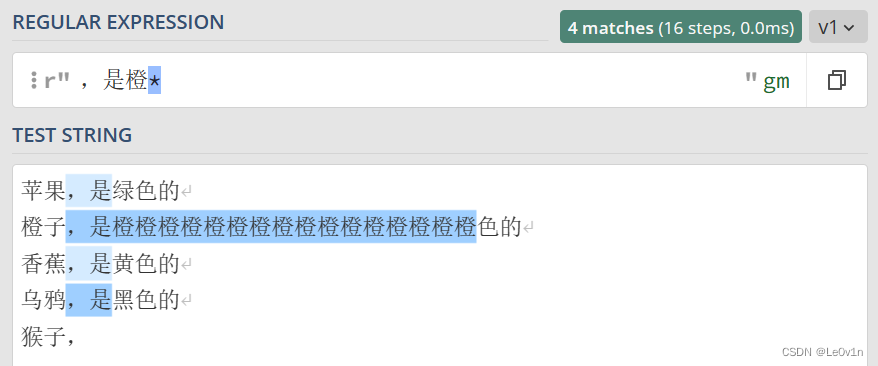
* 表示匹配前面的子表达式任意次,包括 0 次。比如,我们要从下面的文本中,选择每行逗号后面的字符串内容,包括逗号本身。注意,这里的逗号是中文的逗号。
苹果,是绿色的
橙子,是橙色的
香蕉,是黄色的
乌鸦,是黑色的
猴子,
那我们就可以这样写正则表达式:
,.*
* 紧跟在 . 后面,意思是“匹配前面的子表达式任意次”,其中的子表达式是 .,表示除了换行符外的任意字符,所以 .* 表示前面的任意字符。而 , 就是普通字符匹配,没有什么好说的。因此整个表达式的意思就是在逗号后面的所有字符,包括逗号。我们验证一下,结果如 Fig.4:

特别是最后一行,猴子,后面没有其它字符了,但是 * 表示可以匹配 0 次,所以表达式也是成立的。我们也用 Python 代码看一下:
import re
content = """苹果,是绿色的
橙子,是橙色的
香蕉,是黄色的
乌鸦,是黑色的
猴子,
"""
for item in re.findall(pattern=',.*',
string=content):
print(item)
,是绿色的
,是橙色的
,是黄色的
,是黑色的
,
💡 注意,.* 在正则表达式中非常常见,表示匹配任意字符任意次数。
当然这个 * 前面不是非得是 .,也可以是其它字符,如 Fig.5 所示。
4.2.3 特殊字符:+(重复匹配多次,不包括 0 次)
+ 表示匹配前面的子表达式一次或多次,不包括 0 次。
还是上面的例子,我们要从文本中,选择每行逗号后面的字符串内容,包括逗号本身。但是添加一个条件,如果逗号后面没有内容,就不要选择了。
苹果,是绿色的
橙子,是橙色的
香蕉,是黄色的
乌鸦,是黑色的
猴子,
我们可以这样写正则表达式:
,.+
验证结果如 Fig.6 所示。
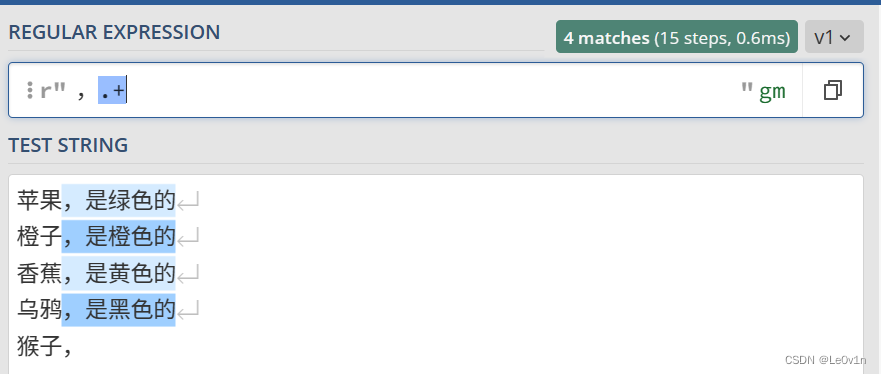
最后一行,猴子, 后面没有其它字符了,+ 表示至少匹配 1 次,所以最后一行没有子串选中。
4.2.4 特殊字符:?(匹配 0 ~ 1 次)
? 表示匹配前面的子表达式 0 次或 1 次。
还是上面的例子,我们要从文本中,选择每行逗号后面的1个字符,也包括逗号本身。
苹果,绿色的
橙子,橙色的
香蕉,黄色的
乌鸦,黑色的
猴子,
那正则表达式可以这样写:
,.?
验证结果如 Fig.7 所示。
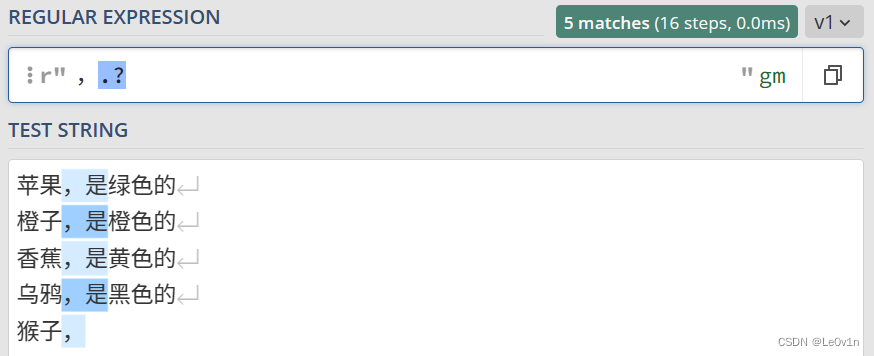
最后一行,猴子, 后面没有其它字符了,但是 `?`` 表示匹配 1 次或 0 次,所以最后一行也选中了一个逗号字符。
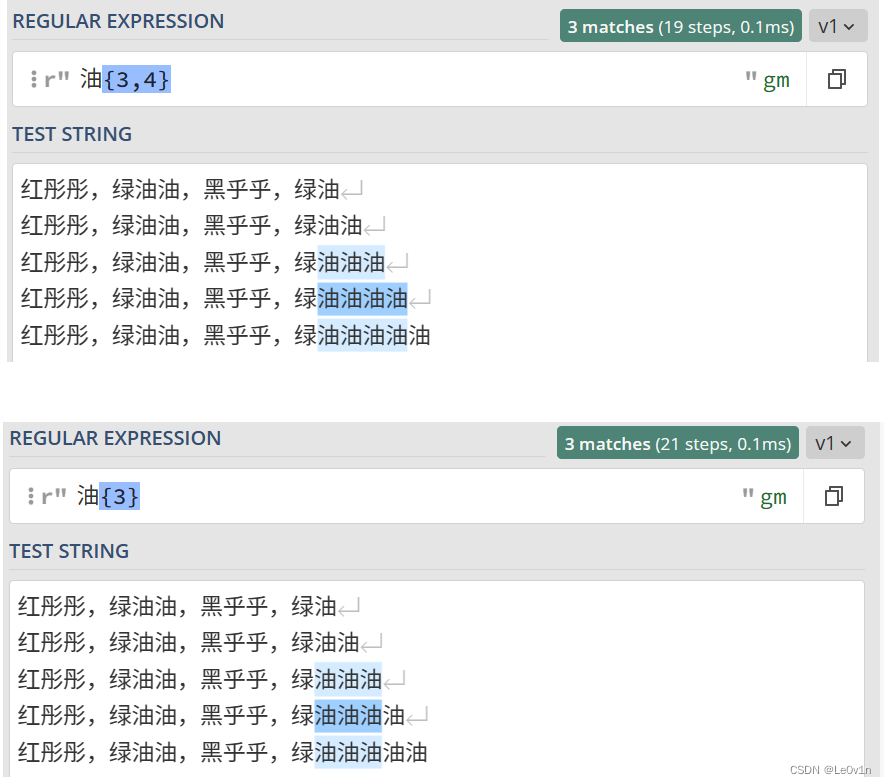
4.2.5 特殊字符:{}(匹配指定次数)
示例文本如下所示:
红彤彤,绿油油,黑乎乎,绿油
红彤彤,绿油油,黑乎乎,绿油油
红彤彤,绿油油,黑乎乎,绿油油油
红彤彤,绿油油,黑乎乎,绿油油油油
红彤彤,绿油油,黑乎乎,绿油油油油油
- 表达式
油{3}就表示匹配连续的油字 3 次。 - 表达式
油{3,4}就表示匹配连续的油字至少 3 次,至多 4 次
示例如 Fig.8 所示。
4.2.6 特殊字符:\(转义字符)
反斜杠 \ 用作转义字符,它有两种作用:
- 用于转义紧跟其后的特殊字符,使其失去特殊含义,被当作普通字符对待。
- 用于创建一些特定的字符类,如换行符
\n、制表符\t等。
例如,如果我们想匹配一个实际的点 .,而不是作为通配符的点,我们需要在点前面加上反斜杠 \.。同样,如果我们想匹配一个实际的反斜杠 \,我们需要使用两个反斜杠 \\,因为在字符串中反斜杠本身也是一个转义字符。
我们的示例文本如下:
example.com
example.net
example.org
现在我们想要得到 . 后面的后缀以确定网页的类型(包括 . 本身),那么我们的 Regex 可以这样写:
\..*
我们验证一下,验证结果见 Fig.9。
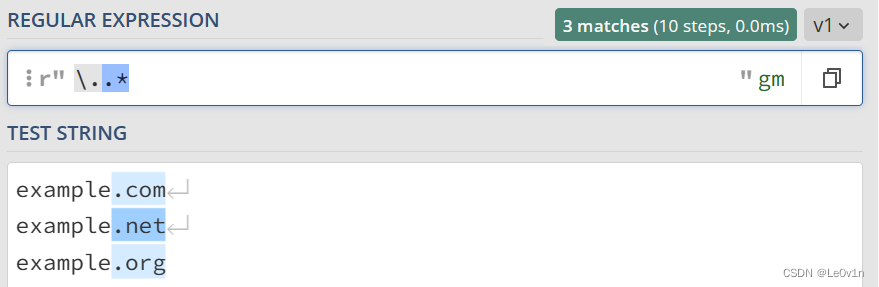
在这里,\. 表示 . 本身,它是一个普通字符而非特殊字符。.* 表示除了换行符外的所有字符。
我们也用 Python 进行一下验证:
import re
text = "这是一个例子:example.com"
pattern = r"example\.com"
match = re.search(pattern, text)
if match:
print(f"匹配结果:{match.group()}")
else:
print("没有匹配结果")
# 匹配包含反斜杠的文本
text_with_backslash = "路径:C:\\Program Files\\Example"
pattern_with_backslash = r"C:\\Program Files\\Example"
match_with_backslash = re.search(pattern_with_backslash, text_with_backslash)
if match_with_backslash:
print(f"匹配结果:{match_with_backslash.group()}")
else:
print("没有匹配结果")
匹配结果:example.com
匹配结果:C:\Program Files\Example
Question:为什么要加 r ?
Answer:在 Python 中,字符串前加上 r 或 R 表示这是一个原始字符串(raw string)。在原始字符串中,反斜杠 \ 不会被当作转义字符处理,而是保持其字面意义。这意味着在原始字符串中,反斜杠后面的字符不会被特殊解释。💡 如果我们不使用原始字符串,我们需要写四个反斜杠 \\\\ 来表示一个反斜杠 🤣。
4.2.7 特殊字符:[](匹配字符集中任意字符)
方括号 [] 用于创建一个字符集,匹配方括号内列出的任意一个字符。字符集可以包含普通字符和特殊字符,但特殊字符在字符集中将失去其特殊含义,被视为普通字符。
例如,字符集 [abc] 将匹配字母 a、b 或 c 中的任意一个。字符集也可以包含字符范围,如 [a-z] 将匹配从小写 a 到小写 z 的任意字母。
如果字符集的第一个字符是脱字符 ^,则表示取非,匹配任何不在方括号内的字符。例如,[^abc] 将匹配除了 a、b 和 c 之外的任意字符。
我们的示例文本如下:
abc def ghi jkl mno a b c d aa a a a a a a sdsad sajkjclkx jsadkl dskljnsdlijewqlkjsadj lasdjlkjdwijsalkj lksajd lkasjwd
- 现在我们想要得到字符 ace,那么我们的 Regex 可以这样写:
[ace] - 如果我们不想要字符 ace,那么我们的 Regex 可以这样写:
[^ace] - 如果我们想要字符 a 到 e 范围内的所有字符,那么我们的 Regex 可以这样写:
[a-e]
验证如 Fig.10 所示。
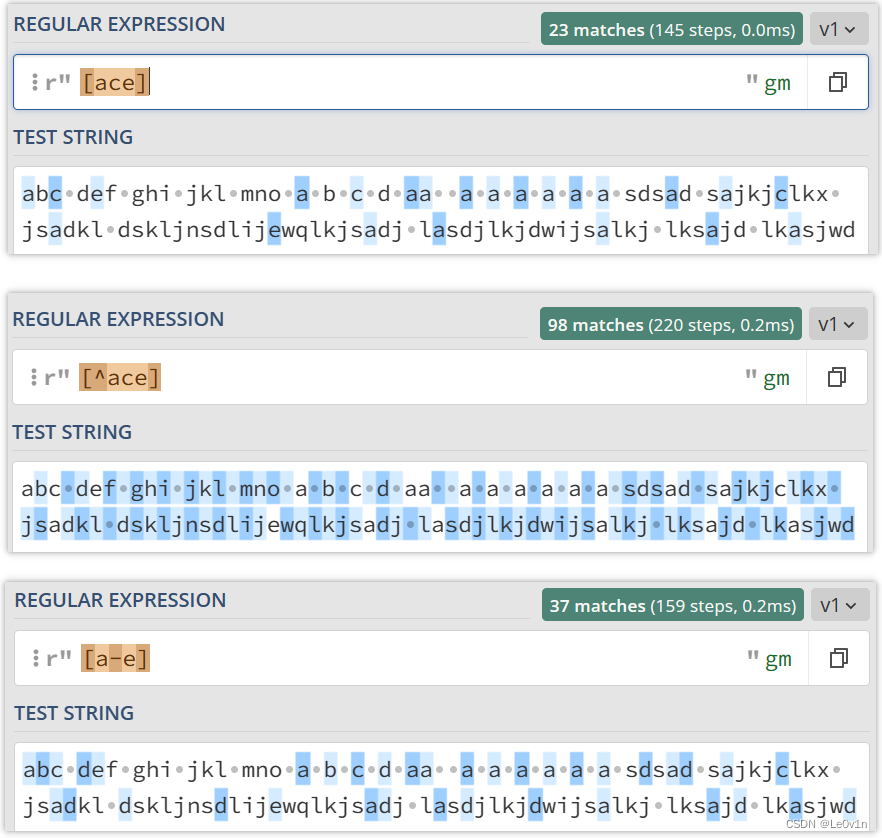
可以看到,当我们不想要字符 ace 时([ace]),空格也被包围了,很合理。当 [a-e] 时,空格并没有被选中,也非常合理。
[] 的 Python 示例:
import re
# 匹配字符集内的任意字符
text = "abc def ghi jkl mno a b c d aa a a a a a a sdsad sajkjclkx jsadkl dskljnsdlijewqlkjsadj lasdjlkjdwijsalkj lksajd lkasjwd"
pattern = r"[ace]"
matches = re.findall(pattern, text)
print(f"匹配结果:{matches}")
# 匹配不在字符集内的任意字符
text = "abc def ghi jkl mno a b c d aa a a a a a a sdsad sajkjclkx jsadkl dskljnsdlijewqlkjsadj lasdjlkjdwijsalkj lksajd lkasjwd"
pattern = r"[^ace]"
matches = re.findall(pattern, text)
print(f"匹配结果:{matches}")
# 匹配字符范围
text = "abc def ghi jkl mno a b c d aa a a a a a a sdsad sajkjclkx jsadkl dskljnsdlijewqlkjsadj lasdjlkjdwijsalkj lksajd lkasjwd"
pattern = r"[a-e]"
matches = re.findall(pattern, text)
print(f"匹配结果:{matches}")
匹配结果:['a', 'c', 'e', 'a', 'c', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'c', 'a', 'e', 'a', 'a', 'a', 'a', 'a']
匹配结果:['b', ' ', 'd', 'f', ' ', 'g', 'h', 'i', ' ', 'j', 'k', 'l', ' ', 'm', 'n', 'o', ' ', ' ', 'b', ' ', ' ', 'd', ' ', ' ', ' ', ' ', ' ', ' ', ' ', ' ', ' ', 's', 'd', 's', 'd', ' ', 's', 'j', 'k', 'j', 'l', 'k', 'x', ' ', 'j', 's', 'd', 'k', 'l', ' ', 'd', 's', 'k', 'l', 'j', 'n', 's', 'd', 'l', 'i', 'j', 'w', 'q', 'l', 'k', 'j', 's', 'd', 'j', ' ', 'l', 's', 'd', 'j', 'l', 'k', 'j', 'd', 'w', 'i', 'j', 's', 'l', 'k', 'j', ' ', 'l', 'k', 's', 'j', 'd', ' ', 'l', 'k', 's', 'j', 'w', 'd']
匹配结果:['a', 'b', 'c', 'd', 'e', 'a', 'b', 'c', 'd', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'd', 'a', 'd', 'a', 'c', 'a', 'd', 'd', 'd', 'e', 'a', 'd', 'a', 'd', 'd', 'a', 'a', 'd', 'a', 'd']
在这个例子中,re.findall 函数用于找到所有匹配正则表达式的子串。第一个模式 [ace] 匹配文本中所有的 a、c 和 e。第二个模式 [^ace] 匹配除了 a、c 和 e 之外的字符。第三个模式 [a-e] 匹配从 a 到 e 的所有字母。
4.2.8 特殊字符:^(锚定匹配字符串的开头和脱字符)
脱字符 ^ 有两种用途:
- 〔锚定匹配字符串的开头〕当
^出现在正则表达式的开头时,它表示匹配行的开始。也就是说,它指定接下来的模式(pattern)必须出现在被搜索字符串的开头。 - 〔脱字符〕当
^出现在字符集的方括号[]内时,它表示取非,用于排除字符集内的字符。在这种情况下,它匹配任何不在方括号内列出的字符(我们刚刚接触过)。
💡 这里对第一种作用再次阐述:当 ^ 出现在模式的开头时,它表示锚定(anchoring)作用,用于指定匹配必须发生在被搜索字符串的开始位置。也就是说,只有当被搜索的字符串以这个模式开始时,匹配才会成功。
也就是说 ^ 表示匹配文本的开头位置。
再补充一个知识:正则表达式可以设定单行模式和多行模式,详情见 4.5 Regex 的单行模式和多行模式。
- 如果是单行模式,
^表示匹配整个文本的开头位置。 - 如果是多行模式,
^表示匹配文本每行的开头位置。
比如,下面的文本中,每行最前面的数字表示水果的编号,最后的数字表示价格。
001-苹果价格-60
002-橙子价格-70
003-香蕉价格-80
如果我们要提取所有的水果编号,用这样的正则表达式:
^\d+
其中:
\d可以先看一下 4.4 匹配某种字符类型,简单来说:\d匹配 0-9 之间任意一个数字字符,等价于表达式[0-9]。+表示至少匹配一次
那此时我们有点疑问,如果是 \d+,那意味着会至少匹配一次及以上的数字,那么它不仅会匹配编号,也会匹配价格,我们用例子看一下:
import re
text = """
001-苹果价格-60
002-橙子价格-70
003-香蕉价格-80
"""
pattern = r"[\d+]"
matches = re.findall(pattern, text)
print(f"{matches = }")
matches = ['0', '0', '1', '6', '0', '0', '0', '2', '7', '0', '0', '0', '3', '8', '0']
可以看出来,我们的想法是正确的。那么我们怎么才能只匹配一次呢?设定为不贪婪的模式(4.3-贪婪模式和非贪婪模式)?我们实际看一下:
import re
text = """
001-苹果价格-60
002-橙子价格-70
003-香蕉价格-80
"""
pattern = r"[\d+?]"
matches = re.findall(pattern, text)
print(f"{matches = }")
matches = ['0', '0', '1', '6', '0', '0', '0', '2', '7', '0', '0', '0', '3', '8', '0']
错了!为什么?
这是因为我们使用的是 [] 进行的匹配([] 表示匹配字符集中任意字符),在 [] 中,所有的特殊字符会被当做普通字符,所以 ? 没有开启不贪婪模式。那我们怎么办?去掉 [] ?我们可以试一下:
text = """
001-苹果价格-60
002-橙子价格-70
003-香蕉价格-80
"""
pattern = r"\d+"
matches = re.findall(pattern, text)
print(f"{matches = }")
matches = ['001', '60', '002', '70', '003', '80']
我们发现这样不仅编号被匹配了,价钱也被匹配了。那我们让其不再贪婪试试?
text = """
001-苹果价格-60
002-橙子价格-70
003-香蕉价格-80
"""
pattern = r"\d+?"
matches = re.findall(pattern, text)
print(f"{matches = }")
matches = ['0', '0', '1', '6', '0', '0', '0', '2', '7', '0', '0', '0', '3', '8', '0']
确实是不贪婪了,但还是会匹配所有的数字 🤣。
到这里我们就要使用本节的主角 ^ 了。它的作用是让匹配范围只在每行的开头,我们试一下:
import re
text = """
001-苹果价格-60
002-橙子价格-70
003-香蕉价格-80
"""
pattern = r"^\d+"
matches = re.findall(pattern, text)
print(f"{matches = }")
matches = []
这是什么情况,为什么没有匹配到任何内容?出现这种原因是因为我的 text 有问题,如上的方式并不是从第一行开始的,而是从第二行开始的,正确的写法应该是:
text = """001-苹果价格-60
002-橙子价格-70
003-香蕉价格-80"""
这样才是正确的 3 行,否则为 5 行!我们用代码看一下:
text = """
001-苹果价格-60
002-橙子价格-70
003-香蕉价格-80
"""
print(f"{text}")
结果如 Fig.11 所示:

我们再看一下 3 行的写法和效果:
text = """001-苹果价格-60
002-橙子价格-70
003-香蕉价格-80"""
print(text)
结果见 Fig.12。

那我们接下来再看一下在正确使用 """""" 的情况下 Regex 的效果:
import re
text = """001-苹果价格-60
002-橙子价格-70
003-香蕉价格-80"""
pattern = r"^\d+"
matches = re.findall(pattern, text)
print(f"{matches = }")
matches = ['001']
为什么只匹配了一个?这是因为我们使用的是单行模式,如果需要使用多行模式,则:
import re
text = """001-苹果价格-60
002-橙子价格-70
003-香蕉价格-80"""
pattern = r"^\d+"
matches = re.findall(pattern, text, re.M) # 传入参数 re.M 则开启多行模式
print(f"{matches = }")
matches = ['001', '002', '003']
再写一个简单的例子:
import re
# 示例字符串
text1 = "hello world"
text2 = "say hello world"
# 正则表达式,用于匹配以 "hello" 开始的字符串
pattern = r"^hello"
# 使用 re.match 检查匹配
match1 = re.match(pattern, text1)
match2 = re.match(pattern, text2)
# 输出结果
if match1:
print(f"text1: 匹配结果:{match1.group()}")
else:
print("text1: 没有匹配结果")
if match2:
print(f"text2: 匹配结果:{match2.group()}")
else:
print("text2: 没有匹配结果")
# 匹配不在字符集中的字符
pattern = r"[^ol]"
matches = re.findall(pattern, text1)
print(f"匹配结果:{matches}")
text1: 匹配结果:hello
text2: 没有匹配结果
匹配结果:['h', 'e', ' ', 'w', 'r', 'd']
在这个例子中,re.match 函数会检查 text1 是否以 hello 开始,如果是,则返回一个匹配对象。对于 text2,由于它不是以 hello 开始,所以 re.match 不会返回任何匹配结果。对于取非的用法我们在上一小节刚刚用过,这里不再赘述。
4.2.9 特殊字符:$(锚定匹配字符串的末尾)
美元符号 $ 用于锚定匹配字符串的末尾。当 $ 出现在正则表达式的末尾时,它表示匹配必须发生在被搜索字符串的结束位置。也就是说,只有当被搜索的字符串以这个模式结束時,匹配才会成功。
与 ^ 类似:
- 如果是 dotall mode,表示匹配整个文本的结尾位置。
- 如果是 multiline mode,表示匹配文本每行的结尾位置。
比如,下面的文本中,每行最前面的数字表示水果的编号,最后的数字表示价格:
001-苹果价格-60
002-橙子价格-70
003-香蕉价格-80
如果我们要提取所有的水果价格,可以使用如下的 regex:
\d+$
⚠️ 注意:$ 应该放在最后,而不是像 ^ 那样放在最前面。
我们使用 Python 试一下:
import re
text = """001-苹果价格-60
002-橙子价格-70
003-香蕉价格-80"""
pattern = r"\d+$"
matches = re.findall(
pattern=pattern,
string=text,
flags=re.M
)
print(f"{matches = }")
matches = ['60', '70', '80']
如果我们不开启 multiline mode,那么如下:
import re
text = """001-苹果价格-60
002-橙子价格-70
003-香蕉价格-80"""
pattern = r"\d+$"
matches = re.findall(
pattern=pattern,
string=text,
)
print(f"{matches = }")
matches = ['80']
因为单行模式下,$ 只会匹配整个文本的结束位置。
4.2.10 特殊字符:|(或)
在正则表达式中,竖线符号 | 是一个特殊字符,表示逻辑上的“或”操作。它用于指定多个模式中的任意一个匹配。
具体来说,| 用于在正则表达式中创建一个模式组,它表示在该位置可以匹配两个或多个模式中的任意一个。这意味着如果字符串与其中任何一个模式匹配,整个正则表达式就会匹配成功。
下面是一些示例说明 | 的用法:
-
匹配多个字符串中的任意一个:
- 表达式:
apple|banana,表示匹配字符串中的 “apple” 或 “banana”。
- 表达式:
-
匹配多个模式中的任意一个:
- 表达式:
(cat|dog)fish,表示匹配 “catfish” 或 “dogfish”。
- 表达式:
-
结合使用其他正则表达式元字符:
- 表达式:
gr(a|e)y,表示匹配 “gray” 或 “grey”。
- 表达式:
需要注意的是,| 的作用范围是模式组。如果我们希望限定 | 的作用范围,可以使用圆括号 ( ) 来明确指定模式组。
以下是一个示例,演示了如何在 Python 中使用 | 进行正则表达式匹配:
import re
pattern = r"apple|banana"
text = "I like bananas and apple"
match = re.search(pattern, text)
if match:
print("Match found:", match.group())
else:
print("No match")
Match found: banana
输出结果将是:Match found: banana,因为字符串 “bananas” 匹配到了模式中的 “banana”。
总结起来,| 是正则表达式中的特殊字符,用于表示逻辑上的“或”操作,允许匹配多个模式中的任意一个。
Question:re.search 和 re.findall 有什么区别?
Answer:re.search 和 re.findall 是 Python 中正则表达式模块 re 提供的两个不同的函数,它们在查找和匹配文本时有一些区别。
-
re.search(pattern, string):- 功能:在给定的字符串中搜索第一个与正则表达式模式匹配的部分。
- 返回值:如果找到匹配项,则返回一个匹配对象(Match object),否则返回
None。 - 匹配顺序:
re.search函数只返回第一个匹配项,即使在字符串中有多个匹配。
-
re.findall(pattern, string):- 功能:在给定的字符串中查找所有与正则表达式模式匹配的部分。
- 返回值:返回一个包含所有匹配项的列表,如果没有匹配项,则返回空列表。
- 匹配顺序:
re.findall函数会从左到右扫描字符串,并返回所有匹配项的列表。
例如,正则表达式 cat|dog 将匹配包含 “cat” 或 “dog” 的字符串。如果字符串中同时存在 “cat” 和 “dog”,则只会匹配第一个遇到的 “cat” 或 “dog”(相当于使用的是 search 而不是 findall),结果见 Fig.13。

import re
# 示例字符串
text = "I have a cat and a dog."
# 正则表达式,用于匹配 "cat" 或 "dog"
pattern = r"cat|dog"
# 使用 re.findall 查找所有匹配项
matches1 = re.findall(pattern, text)
matches2 = re.search(pattern, text)
# 输出结果
print(f"{matches1 = }")
print(f"{matches2 = }")
print(f"{matches2.group()}") if matches2 else ...
print(f"{matches2.groups()}") if matches2 else ...
matches1 = ['cat', 'dog']
matches2 = <re.Match object; span=(9, 12), match='cat'>
cat
()
结果分析如下:
matches1是通过re.findall函数查找到的所有匹配项的列表,其中包含了字符串中所有匹配到的 “cat” 和 “dog”。matches2是通过re.search函数找到的第一个匹配项的匹配对象。匹配对象的span=(9, 12)表示匹配项在字符串中的起始位置是索引 9,结束位置是索引 12。match='cat'表示匹配项是字符串中的 “cat”。matches2.group()返回匹配项的字符串表示,即 “cat”。因为matches2是一个匹配对象,所以可以使用group()方法来获取匹配项的字符串。matches2.groups()返回一个空元组()。这是因为在正则表达式中没有使用圆括号( )来创建捕获组,所以没有可以提取的分组信息。
综上所述,结果表示在示例字符串中找到了两个匹配项,分别是 “cat” 和 “dog”。re.findall 返回了所有匹配项的列表,而 re.search 返回了第一个匹配项的匹配对象。我们可以使用匹配对象的 group() 方法来获取匹配项的字符串表示。在这个例子中,没有定义捕获组,所以 groups() 返回一个空元组。
Question:| 相当于是多个元素并列?
Answer:是的,| 在正则表达式中相当于多个元素并列,表示逻辑上的“或”操作。当使用 | 字符时,它允许我们指定多个模式中的任意一个来进行匹配。它会从左到右依次尝试匹配每个模式,并返回第一个匹配到的结果。
例如,正则表达式 apple|banana 表示匹配 “apple” 或者 “banana” 这两个模式中的任意一个。如果目标字符串中包含了其中任意一个词,整个正则表达式就会匹配成功。
另一个例子是,正则表达式 gr(a|e)y 表示匹配以 “gray” 或者 “grey” 开头的单词。它会匹配 “gray” 或者 “grey” 这两个单词。
需要注意的是,| 的作用范围是在它两侧的模式组。如果需要限定 | 的作用范围,可以使用圆括号 ( ) 将模式组起来。
综上所述,| 在正则表达式中用于表示多个元素的并列,提供了灵活的匹配选择。它允许我们指定多个模式中的任意一个来进行匹配操作。
Question:那我们是不是也可以使用 [cat,dog] 来代替 cat|dog?
Answer:实际上,[cat,dog] 并不会产生我们期望的效果。在字符类中,逗号 , 不会被解释为逻辑上的“或”操作符,而是表示一个普通的逗号字符。所以 [cat,dog] 实际上表示匹配字符 'c'、'a'、't'、逗号 ,、'd'、'o'、'g' 中的任意一个。
4.2.11 特殊字符:()(分组)
在正则表达式中,括号 ( ) 用于创建分组(grouping)。分组允许我们对模式的部分进行分组,并对分组应用特定的操作,如重复、替换等。
组(Group)就是把正则表达式匹配的内容里面其中的某些部分标记为某个组。我们可以在正则表达式中标记多个组。
为什么要有组的概念呢?因为有时,我们需要提取已经匹配的内容里面的某个部分。我从下面的文本中,选择每行逗号前面的字符串,也包括逗号本身。
4.2.11.1 单个分组
苹果,苹果是绿色的
橙子,橙子是橙色的
香蕉,香蕉是黄色的
就可以这样写正则表达式:
^.*,
但是,如果我们要求不要包括逗号呢?我们当然不能直接写成:
^.*
因为最后的逗号是特征所在,如果去掉它,就没法找逗号前面的了。但是把逗号放在正则表达式中,又会包含逗号。解决问题的方法就是使用组选择符:括号。我们可以这样写:
^(.*),
结果见 Fig.14。
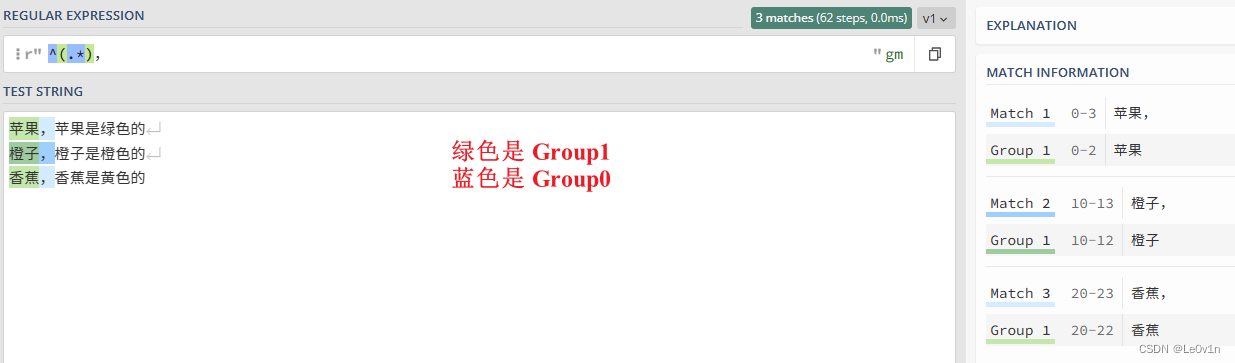
我们可以发现,要从整个表达式中提取的部分放在括号中,这样水果的名字就被单独的放在一个组(group)中了。对应的 Python 代码如下:
import re
text = """苹果,苹果是绿色的
橙子,橙子是橙色的
香蕉,香蕉是黄色的"""
p = r"^(.*),"
matches = re.findall(pattern=p, string=text, flags=re.M)
print(f"{matches = }")
matches = ['苹果', '橙子', '香蕉']
我们可能会有疑问,不是应该有两个组吗?为什么只有 Group1 的结果?
findall() 函数只返回每个匹配的第一个分组的内容,而不是返回所有分组的内容。
如果我们希望获取每个分组的内容,可以使用 finditer() 函数来遍历每个匹配对象,并使用其 group() 方法来获取分组的内容:
import re
text = """苹果,苹果是绿色的
橙子,橙子是橙色的
香蕉,香蕉是黄色的"""
p = r"^(.*),"
matches1 = re.findall(pattern=p, string=text, flags=re.M)
print(f"{matches1 = }")
print('='*50)
matches2 = re.finditer(p, text, re.M)
for match in matches2:
print(f"Full match: {match.group(0)}")
print(f"Group1: {match.group(1)}")
print('-'*50)
matches1 = ['苹果', '橙子', '香蕉']
==================================================
Full match: 苹果,
Group1: 苹果
--------------------------------------------------
Full match: 橙子,
Group1: 橙子
--------------------------------------------------
Full match: 香蕉,
Group1: 香蕉
--------------------------------------------------
4.2.11.2 多个分组
分组也可以多次使用。比如,我们要从下面的文本中,提取出每个人的名字和对应的手机号。
张三,手机号码15945678901
李四,手机号码13945677701
王二,手机号码13845666901
可以使用这样的正则表达式:
^(.*),.*(\d{11})
效果如 Fig.15 所示。

对应代码如下:
import re
text = """张三,手机号码15945678901
李四,手机号码13945677701
王二,手机号码13845666901"""
p = r"^(.*),.*(\d{11})"
matches1 = re.findall(pattern=p, string=text, flags=re.M)
print(f"{matches1 = }")
print('='*50)
matches2 = re.finditer(p, text, re.M)
for match in matches2:
print(f"Full match: {match.group(0)}")
print(f"Group1: {match.group(1)}")
print(f"Group2: {match.group(2)}")
print('-'*50)
matches1 = [('张三', '15945678901'), ('李四', '13945677701'), ('王二', '13845666901')]
==================================================
Full match: 张三,手机号码15945678901
Group1: 张三
Group2: 15945678901
--------------------------------------------------
Full match: 李四,手机号码13945677701
Group1: 李四
Group2: 13945677701
--------------------------------------------------
Full match: 王二,手机号码13845666901
Group1: 王二
Group2: 13845666901
--------------------------------------------------
4.2.11.3 分组命名
当有多个分组的时候,我们可以使用 (?P<分组名>...) 这样的格式,给每个分组命名。这样做的好处是,更方便后续的代码提取每个分组里面的内容,如 Fig.16 所示。

import re
text = """张三,手机号码15945678901
李四,手机号码13945677701
王二,手机号码13845666901"""
p = r"^(?P<name>.*),.*(?P<phone>\d{11})"
matches1 = re.findall(pattern=p, string=text, flags=re.M)
print(f"{matches1 = }")
print('='*50)
matches2 = re.finditer(p, text, re.M)
for match in matches2:
print(f"Full match: {match.group(0)}")
print(f"Group-name: {match.group('name')}")
print(f"Group-phone: {match.group('phone')}")
print('-'*50)
matches1 = [('张三', '15945678901'), ('李四', '13945677701'), ('王二', '13845666901')]
==================================================
Full match: 张三,手机号码15945678901
Group-name: 张三
Group-phone: 15945678901
--------------------------------------------------
Full match: 李四,手机号码13945677701
Group-name: 李四
Group-phone: 13945677701
--------------------------------------------------
Full match: 王二,手机号码13845666901
Group-name: 王二
Group-phone: 13845666901
--------------------------------------------------
4.3 贪婪模式和非贪婪模式
我们要把下面的字符串中的所有 html 标签都提取出来:
source = '<html><head><title>Title</title>'
得到这样的一个列表:
['<html>', '<head>', '<title>', '</title>']
我们很容易想到使用正则表达式 <.*>,那我们实验一下:
import re
source = '<html><head><title>Title</title>'
p = re.compile(pattern=r'<.*>')
print(p.findall(source))
['<html><head><title>Title</title>']
我们发现结果并不是我们想要的。这是因为在正则表达式中,'*'、'+'、'?' 都是贪婪的,使用它们时,会尽可能多的匹配内容,所以,<.*> 中的 *(表示任意次数的重复),一直匹配到了字符串最后的 </title> 里面的 e。
解决这个问题,就需要使用非贪婪模式,也就是在星号后面加上 ?,变成这样 <.*?>:
import re
source = '<html><head><title>Title</title>'
p = re.compile(pattern=r'<.*?>')
print(p.findall(source))
['<html>', '<head>', '<title>', '</title>']
4.4 匹配某种字符类型
转义字符 \ 后面接一些字符,表示匹配某种类型的一个字符,例如:
\d匹配 0-9 之间任意一个数字字符,等价于表达式[0-9]\D匹配任意一个非 0-9 数字的字符,等价于表达式[^0-9]\s是一个特殊字符,代表任意空白字符。这包括空格、制表符(\t)、换行符(\n)、回车符(\r)等,等价于[\t\n\r\f\v]\S匹配任意一个非空白字符,等价于表达式[^ \t\n\r\f\v]\w匹配任意一个文字字符,包括大小写字母、数字、下划线,等价于表达式[a-zA-Z0-9_]- 默认情况也包括 Unicode 文字字符,如果指定 ASCII 码标记,则只包括 ASCII 字母
\W匹配任意一个非文字字符,等价于表达式[^a-zA-Z0-9_]
💡 反斜杠 \ 也可以用在方括号里面,比如 [\s,.],它代表了一组特殊字符的组合。这个字符集合中的每个字符都有特定的含义:
,是一个普通字符,代表逗号。.也是一个普通字符(在[]中,特殊字符会被视为普通字符),代表点号。、
所以,[\s,.] 作为一个整体,表示匹配任意空白字符、逗号或点号。
在 Python 中,我们可以这样使用它:
import re
text = 'Hello, World! \nThis is a test.'
pattern = r"[\s,.]" # 匹配空白字符、,、.
matches = re.findall(pattern, text)
print(f"{matches = }")
matches = [',', ' ', ' ', '\n', ' ', ' ', ' ', '.']
在这个例子中,re.findall 函数将返回所有匹配的空白字符、逗号或点号。
4.5 Regex 的单行模式和多行模式
在正则表达式中,单行模式(single line mode)和多行模式(multiline mode)是两种不同的模式,它们影响正则表达式对字符串的处理方式。
前面说过, . 是不匹配换行符的,可是有时候,特征字符串就是跨行的,比如要找出下面文字中所有的职位名称:
<div class="el">
<p class="t1">
<span>
<a>Python开发工程师</a>
</span>
</p>
<span class="t2">南京</span>
<span class="t3">1.5-2万/月</span>
</div>
<div class="el">
<p class="t1">
<span>
<a>java开发工程师</a>
</span>
</p>
<span class="t2">苏州</span>
<span class="t3">1.5-2/月</span>
</div>
如果我们直接使用表达式:
class=\"t1".*?<a>(.*?)</a>
其中,? 表示非贪婪模式。
我们会发现匹配不上,因为 t1 和 <a> 之间有两个空行。这时我们需要 . 也匹配换行符,则可以使用 DOTALL 参数或者 (?s),结果如 Fig.17 所示。
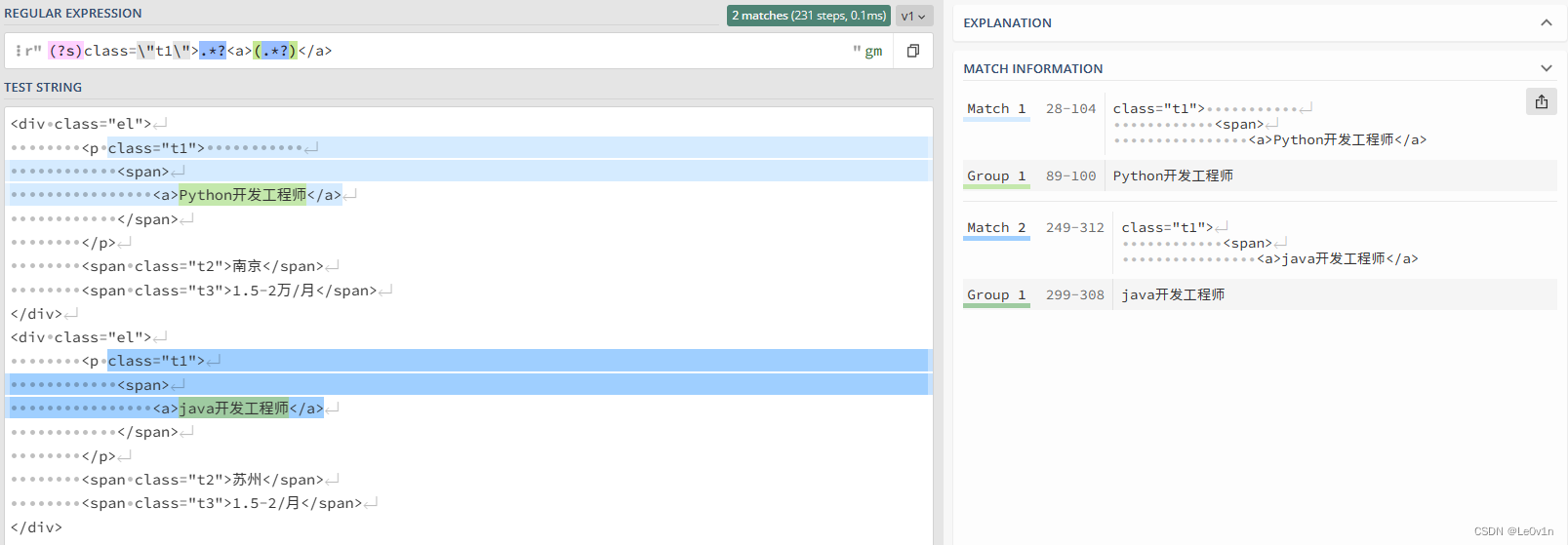
对应的 Python 代码如下:
import re
text = """<div class="el">
<p class="t1">
<span>
<a>Python开发工程师</a>
</span>
</p>
<span class="t2">南京</span>
<span class="t3">1.5-2万/月</span>
</div>
<div class="el">
<p class="t1">
<span>
<a>java开发工程师</a>
</span>
</p>
<span class="t2">苏州</span>
<span class="t3">1.5-2/月</span>
</div>"""
p1 = r"class=\"t1\">.*?<a>(.*?)</a>"
p2 = r"(?s)class=\"t1\">.*?<a>(.*?)</a>"
matches1 = re.findall(pattern=p1, string=text, flags=re.DOTALL)
matches2 = re.findall(pattern=p2, string=text)
print(f"{matches1 = }")
print(f"{matches2 = }")
matches1 = ['Python开发工程师', 'java开发工程师']
matches2 = ['Python开发工程师', 'java开发工程师']
4.5.1 dotall mode
在 dotall mode 中,点号(.)可以匹配任何单个字符,包括换行符(\n)。
在 4.2.1 特殊字符:
.(通配符:匹配除换行符外的所有字符) 中说过,.是匹配除换行符外的所有字符,但在单行模式中,这个限制被取消,.可以匹配一切!
在 Python 的 re 模块中,可以通过在正则表达式中使用 (?s) 来启用 dotall mode,或者在编译正则表达式时使用 re.DOTALL 标志。
示例:
import re
# text = "Hello\nWorld"
text = """Hello
World"""
pattern = r".+" # + 表示至少匹配一次
matches = re.findall(
pattern=pattern,
string=text,
flags=re.DOTALL
)
print(f"{matches = }")
matches = ['Hello\nWorld']
在这个例子中,matches 将包含整个文本 "Hello\nWorld",因为 . 匹配了换行符。
💡 两种
text的写法是等价的
4.5.2 multiline mode
在 multiline mode 中,锚定字符 ^ 和 $ 分别匹配字符串的每一行的开始和结束,而不仅仅是整个字符串的开始和结束。
在Python的 re 模块中,可以通过在正则表达式中使用 (?m) 来启用多行模式,或者在编译正则表达式时使用 re.MULTILINE 标志。
import re
# text = """Hello World
# Hello World Again!"""
text = "Hello World\nHello World Again!"
pattern = r"^Hello" # ^ 表示开头
matches = re.findall(
pattern=pattern,
string=text,
flags=re.M
)
print(f"{matches = }")
matches = ['Hello', 'Hello']
在这个例子中,matches 将包含两个匹配项:"Hello" 和 "Hello",因为 ^ 锚定字符在多行模式下匹配了每一行的开始。
⚠️ 注意:虽然通常将 (?s)(flags=re.dotall)称为单行模式,将 (?m)(flags=re.M)称为多行模式,但更准确的说法是:
(?s)(flags=re.dotall)启用了 dotall 模式,允许.匹配换行符(?m)(flags=re.M)启用了 multiline 模式,影响了锚定字符^和$的行为
这也就是为什么单行模式叫作 dotall mode,多行模式叫作 multiline mode。
Question:在 Python 中,默认使用的是什么模式?
Answer:在 Python 的 re 模块中,默认情况下,正则表达式既不是 dotall mode 也不是 multiline mode)。这意味着:
- 点号(
.)默认不会匹配换行符(\n)。 - 锚定字符
^和$默认分别匹配整个字符串的开始和结束,而不是每一行的开始和结束。
Question:dotall mode 和 multiline mode 可以在除 Python 外的 Regex 中使用吗?
Answer:Dotall mode 和 multiline mode 是 Python 正则表达式中的特殊模式标志,并且它们不是所有正则表达式库都具备的功能。这意味着在除了 Python 之外的正则表达式实现中,可能没有与这些模式标志完全相等的选项。
然而,不同的正则表达式库可能提供类似的功能,尽管可能有不同的名称或语法。
在 Visual Studio Code 中的查找替换:
-
Dotall mode: 在 VSCode 中,默认情况下点号(
.)无法匹配换行符。要启用 dotall 模式,我们可以在搜索框中使用[\s\S]或[^]来匹配包括换行符在内的任意字符。 -
Multiline mode: 在 VSCode 中,默认情况下
^和$分别匹配整个文本的开头和结尾。如果我们希望它们匹配每一行的开头和结尾,可以在搜索框中使用(?m)来启用 multiline 模式。
在 Microsoft Word 中的查找替换:
-
Dotall mode: 在 Word 的查找替换功能中,默认情况下点号(
.)无法匹配换行符。要匹配包括换行符在内的任意字符,可以使用以下语法:- 在搜索框中输入
^13,其中^13代表换行符。 - 在高级选项中,将搜索模式设置为 “任意字符” 或 “通配符”,具体取决于我们的需求。
- 在搜索框中输入
-
Multiline mode: 在 Word 的查找替换功能中,默认情况下
^和$分别匹配段落的开头和结尾。要使其匹配每一行的开头和结尾,可以使用以下语法:- 在搜索框中输入
^p,其中^p代表换行符和段落标记。 - 在高级选项中,将搜索模式设置为 “段落标记” 或 “使用通配符”,具体取决于我们的需求。
- 在搜索框中输入
需要注意的是,不同的文本编辑器和处理工具可能具有不同的语法和选项,因此在使用特定工具时,最好参考其文档或帮助文件,以了解如何使用正则表达式进行高级查找和替换操作。
Question:dotall mode 和 multiline mode 可以同时开启吗?
Answer:在正则表达式中,Dotall mode(单行模式)和 multiline mode(多行模式)通常是互斥的,因为它们控制了正则表达式引擎对文本的解释方式。
5. 回到开头的例子
有了上面的知识,我们再来看本文开始的例子:从下面的文本里面抓取所有职位的薪资。
Python3 高级开发工程师 上海互教教育科技有限公司上海-浦东新区2万/月02-18满员
测试开发工程师(C++/python) 上海墨鹍数码科技有限公司上海-浦东新区2.5万/每月02-18未满员
Python3 开发工程师 上海德拓信息技术股份有限公司上海-徐汇区1.3万/每月02-18剩余11人
测试开发工程师(Python) 赫里普(上海)信息科技有限公司上海-浦东新区1.1万/每月02-18剩余5人
我们使用的表达式是:
([\d.])+万/每{0,1}月
为什么这么写呢?其中:
-
[\d.]+表示匹配数字或者点的多次出现,这样就可以匹配像:33333.33这样的数字。 -
万/每{0,1}月是后面紧接着的,如果没有这个,就会匹配到别的数字,比如 Python3 里面的3。(每{0,1}月这部分表示匹配每月每这个字可以出现 0 次或者 1 次)
那还可以用什么来表示这个每{0,1}月吗?我们还可以用每?月。因为问号表示前面的字符匹配 0 次或者 1 次。
6. 切割字符串
字符串对象的 split 方法只适用于简单的字符串分割。有时我们需要更加灵活的字符串切割。
比如,我们需要从下面字符串中提取武将的名字。
names = '关羽; 张飞, 赵云,马超, 黄忠 李逵'
我们发现这些名字之间,有的是分号隔开,有的是逗号隔开,有的是空格隔开,而且分割符号周围还有不定数量的空格。这时,可以使用正则表达式里面的 split 方法:
import re
text = "关羽; 张飞, 赵云,马超, 黄忠 李逵"
p = r"[;,\s]\s*"
matches = re.split(
pattern=p,
string=text
)
print(f"{matches = }")
matches = ['关羽', '张飞', '赵云', '马超', '黄忠', '李逵']
💡 Tips:
[;,\s]:匹配分号、逗号或空白字符(空格、制表符等)中的任意一个。\s*:匹配零个或多个连续的空白字符。
Question:这个 split 方法只有 Python 有吗?
Answer:split 方法并非仅限于 Python,在许多编程语言中都有类似的功能和方法。以下是一些其他编程语言中常见的字符串分割方法:
-
JavaScript:
split()方法:使用指定的分隔符将一个字符串拆分为字符串数组。- 示例:
const str = "关羽; 张飞, 赵云,马超, 黄忠 李逵"; const arr = str.split(/[;,\s]\s*/);
-
Java:
split()方法:将字符串使用指定的正则表达式作为分隔符进行分割,并返回一个字符串数组。- 示例:
String str = "关羽; 张飞, 赵云,马超, 黄忠 李逵"; String[] arr = str.split("[;,\\s]\\s*");
-
C#:
Split()方法:使用指定的分隔符将一个字符串拆分为字符串数组。- 示例:
string str = "关羽; 张飞, 赵云,马超, 黄忠 李逵"; string[] arr = str.Split(new[] { ';', ',', ' ' }, StringSplitOptions.RemoveEmptyEntries);
-
Ruby:
split()方法:使用指定的分隔符将一个字符串拆分为字符串数组。- 示例:
str = "关羽; 张飞, 赵云,马超, 黄忠 李逵"; arr = str.split(/[;,\s]\s*/);
Question:那除了编程语言外,比如我们在 regex101 这种网站可以使用 split 方法吗?
Answer:在 regex101 这样的在线正则表达式测试工具中,通常提供的是正则表达式的匹配、查找和替换等功能,一般不提供 split 这种编程方法。
7. 字符串替换
7.1 匹配模式替换
字符串对象的 replace 方法只适应于简单的替换。有时我们需要更加灵活的字符串替换。
比如,我们需要在下面这段文本中所有的链接中找到所以 /avxxxxxx/ 这种以 /av 开头,后面接一串数字,这种模式的字符串。然后这些字符串全部替换为 /cn345678/。
names = """
下面是这学期要学习的课程:
<a href='https://www.bilibili.com/video/av66771949/?p=1' target='_blank'>点击这里,边看视频讲解,边学习以下内容</a>
这节讲的是牛顿第2运动定律
<a href='https://www.bilibili.com/video/av46349552/?p=125' target='_blank'>点击这里,边看视频讲解,边学习以下内容</a>
这节讲的是毕达哥拉斯公式
<a href='https://www.bilibili.com/video/av90571967/?p=33' target='_blank'>点击这里,边看视频讲解,边学习以下内容</a>
这节讲的是切割磁力线
"""
被替换的内容不是固定的,所以没法用字符串的 replace 方法。这时,可以使用正则表达式里面的 sub 方法:
import re
text = """
下面是这学期要学习的课程:
<a href='https://www.bilibili.com/video/av66771949/?p=1' target='_blank'>点击这里,边看视频讲解,边学习以下内容</a>
这节讲的是牛顿第2运动定律
<a href='https://www.bilibili.com/video/av46349552/?p=125' target='_blank'>点击这里,边看视频讲解,边学习以下内容</a>
这节讲的是毕达哥拉斯公式
<a href='https://www.bilibili.com/video/av90571967/?p=33' target='_blank'>点击这里,边看视频讲解,边学习以下内容</a>
这节讲的是切割磁力线
"""
p = r"/av\d+/"
text = re.sub(
pattern=p,
repl=r"/cn345678/",
string=text
)
print(f"{text = }")
text = "\n\n下面是这学期要学习的课程:\n\n<a href='https://www.bilibili.com/video/cn345678/?p=1' target='_blank'>点击这里,边看视频讲解,边学习以下内容</a>\n这节讲的是牛顿第2运动定律\n\n<a href='https://www.bilibili.com/video/cn345678/?p=125' target='_blank'>点击这里,边看视频讲解,边学习以下内容</a>\n这节讲的是毕达哥拉斯公式\n\n<a href='https://www.bilibili.com/video/cn345678/?p=33' target='_blank'>点击这里,边看视频讲解,边学习以下内容</a>\n这节讲的是切割磁力线\n"
sub 方法就是也是替换字符串,但是被替换的内容用正则表达式来表示符合特征的所有字符串。
- 第一个参数
/av\d+/这个正则表达式,表示以/av开头,后面是一串数字,再以/结尾的这种特征的字符串,是需要被替换的 - 第二个参数,这里是
'/cn345677/'这个字符串,表示用什么来替换。 - 第三个参数是源字符串。
7.2 指定替换函数
刚才的例子中,我们用来替换的是一个固定的字符串 /cn345677/。如果,我们要求替换后的内容的是 原来的数字+6,比如 /av66771949/ 替换为 /av66771955/。
这种更加复杂的替换,我们可以把 sub 的第 2 个参数指定为一个函数,该函数的返回值,就是用来替换的字符串。如下:
import re
text = """
下面是这学期要学习的课程:
<a href='https://www.bilibili.com/video/av66771949/?p=1' target='_blank'>点击这里,边看视频讲解,边学习以下内容</a>
这节讲的是牛顿第2运动定律
<a href='https://www.bilibili.com/video/av46349552/?p=125' target='_blank'>点击这里,边看视频讲解,边学习以下内容</a>
这节讲的是毕达哥拉斯公式
<a href='https://www.bilibili.com/video/av90571967/?p=33' target='_blank'>点击这里,边看视频讲解,边学习以下内容</a>
这节讲的是切割磁力线
"""
def subFunc(match):
# match对象的group(0)返回的是整个匹配上的字符串
src = match.group(0)
# match对象的group(1)返回的是第一个group分组的内容
number = int(match.group(1)) + 6
dst = f"/av{number}/"
print(f"💡 {src} 被替换为 {dst}")
return dst
p = r"/av(\d+)/" # 这里我们把匹配上的数字添加为一个组
text = re.sub(
pattern=p,
repl=subFunc, # 注意函数不要加(),加了表示函数的调用
string=text
)
print(f"{text = }")
💡 /av66771949/ 被替换为 /av66771955/
💡 /av46349552/ 被替换为 /av46349558/
💡 /av90571967/ 被替换为 /av90571973/
text = "\n\n下面是这学期要学习的课程:\n\n<a href='https://www.bilibili.com/video/av66771955/?p=1' target='_blank'>点击这里,边看视频讲解,边学习以下内容</a>\n这节讲的是牛顿第2运动定律\n\n<a href='https://www.bilibili.com/video/av46349558/?p=125' target='_blank'>点击这里,边看视频讲解,边学习以下内容</a>\n这节讲的是毕达哥拉斯公式\n\n<a href='https://www.bilibili.com/video/av90571973/?p=33' target='_blank'>点击这里,边看视频讲解,边学习以下内容</a>\n这节讲的是切割磁力线\n"
💡 获取组内字符串的规则如下:
match.group(0):获取整个匹配字符串match.group(1):获取第1个组内字符串match.group(2):获取第2个组内字符串- …
💡 Python 3.6 以后的版本,写法也可以更加简洁,直接像列表一样使用下标,如下:
match[0]
match[1]
match[2]
8. 常用的正则表达式
8.1 VSCode
8.1.1 中文空格中文 替换为 中文中文
方法1:
# find
([\u4e00-\u9fff])\s([\u4e00-\u9fff])
# replace
$1$2
方法2:
# find
(\p{Script=Han})\s(\p{Script=Han})
# replace
$1$2
8.2 Word
TODO















 1350
1350











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









