










1. pathlib库介绍
1.1 pathlib和pathlib.Path
pathlib是Python标准库中的一个模块,它提供了一组面向对象的文件系统路径操作。在Python早期版本中,文件和目录路径通常使用字符串来处理,或者使用os.path模块中的函数来执行操作,如路径拼接、获取文件属性等。pathlib模块在Python 3.4及更高版本中引入,提供了一种更现代、更直观的方式来处理文件系统路径。
pathlib.Path是pathlib模块中的核心类,它表示一个文件系统路径。Path对象可以表示文件或目录的路径,并且提供了许多方法来执行常见的路径操作,如路径拼接、检查路径是否存在、遍历目录、读取和写入文件等。
1.2 Path的特点
- 面向对象:
Path对象允许我们使用对象和方法来处理路径,而不是传统的字符串操作。这使得代码更加清晰和可读。 - 跨平台:
Path对象会根据我们的操作系统自动处理路径分隔符(如Windows上的\和Unix/Linux/MacOS上的/),这使得我们的代码可以在不同的系统上运行,而无需做任何修改。 - 便捷的方法:
Path提供了许多便捷的方法来执行常见的文件系统操作,如open()、read_text()、write_text()、mkdir()、iterdir()等,这些方法简化了文件和目录的操作。 - 属性访问:
Path对象提供了许多属性,如name(文件名)、suffix(文件扩展名)、stem(无扩展名的文件名)、parent(父目录)等,这些属性可以很容易地访问路径的不同部分。 - 模式匹配:
Path对象支持使用glob模式匹配来查找符合特定模式的文件或目录。 - 操作符重载:
Path对象支持使用/操作符来进行路径拼接,这比使用字符串拼接更加直观。
总之,使用pathlib.Path可以让我们以更统一、更现代的方式处理文件系统路径,从而提高代码的质量和可维护性。
1.3 官方定义
The pathlib module – object-oriented filesystem paths(面向对象的文件系统路径)
简单来说,pathlib就是一个面向对象的文件操作类,我们一般会直接使用它的Path类。
1.4 pathlib组成部分关系
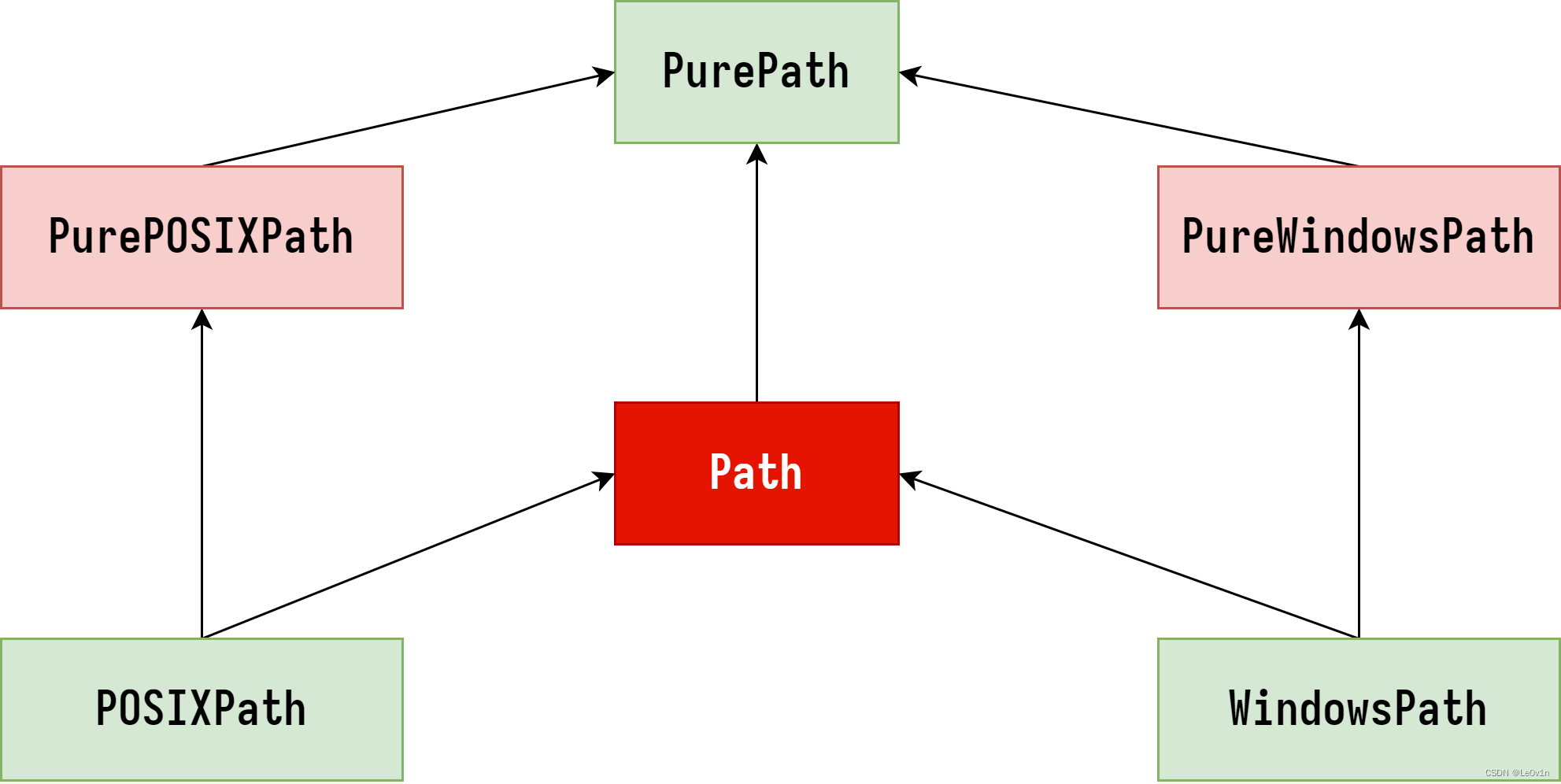
Path:是一个方便的别名,它自动选择PosixPath或WindowsPath,具体取决于我们的操作系统。- 在Unix-like系统上,
Path等同于PosixPath; - 在Windows系统上,
Path等同于WindowsPath。
- 在Unix-like系统上,
PurePath:这是一个抽象基类,提供了与操作系统无关的路径操作。它不能用于访问文件系统,但可以用于操作路径字符串。PurePath不处理路径的具体细节,如路径分隔符或文件系统的存在性。
PurePosixPath:PurePath的一个子类,用于表示类Unix操作系统的路径。- 它使用
/作为路径分隔符,并且遵循POSIX路径规则。
- 它使用
PureWindowsPath:PurePath的一个子类,用于表示Windows操作系统的路径。- 它使用
\作为路径分隔符,并且可以处理Windows特有的路径形式,如驱动器号和UNC路径。
- 它使用
PosixPath:Path的一个子类,用于表示实际存在于类Unix操作系统中的路径。- 它继承自
PurePosixPath,并且提供了与文件系统交互的方法,如检查路径是否存在、遍历目录等。
- 它继承自
WindowsPath:Path的一个子类,用于表示实际存在于Windows操作系统中的路径。- 它继承自
PureWindowsPath,并且提供了与文件系统交互的方法,如检查路径是否存在、遍历目录等。
- 它继承自
关系总结:
PurePath是所有路径类的抽象基类,提供了与操作系统无关的路径操作。PurePosixPath和PureWindowsPath继承自PurePath,分别提供了特定于POSIX和Windows的路径操作。PosixPath和WindowsPath继承自PurePosixPath和PureWindowsPath,分别提供了与实际文件系统交互的方法。Path是一个方便的别名,根据操作系统自动指向PosixPath或WindowsPath。
这种设计允许开发者编写可移植的代码,同时也能够处理特定操作系统的路径细节。通过使用Path,我们可以编写不依赖于操作系统的代码,而PurePath及其子类则提供了处理特定操作系统路径的能力。
1.5 补充
1.5.1 POSIX路径
POSIX(Portable Operating System Interface)路径是指遵循POSIX标准的文件系统路径。POSIX是一个IEEE标准,旨在为Unix-like操作系统提供一系列API规范,以确保软件可以在不同的操作系统上运行。
POSIX路径具有以下特点:
- 路径分隔符:POSIX路径使用
/作为目录分隔符。例如,/home/user/documents是一个POSIX路径。 - 相对路径和绝对路径:POSIX路径可以是相对路径,也可以是绝对路径。相对路径是相对于当前工作目录的路径,而绝对路径是从文件系统的根开始的完整路径。
- 当前目录和父目录:点
.表示当前目录,而双点..表示父目录。例如,../file.txt表示当前目录的父目录中的file.txt文件。 - 文件名和扩展名:文件名通常由两部分组成:基础名和扩展名。基础名是文件的名称,而扩展名通常是跟在最后一个点
.后面的部分,表示文件的类型。例如,在文件名document.txt中,document是基础名,txt是扩展名。 - 路径解析:POSIX路径解析遵循特定的规则,例如,连续的路径分隔符被视为单个分隔符,
.表示当前目录,而..用于返回到上一级目录。
POSIX路径规范被广泛应用于类Unix操作系统,如Linux、BSD、MacOS X等。这些系统的文件系统API通常遵循POSIX标准,以确保软件的兼容性和可移植性。
1.5.2 驱动器号和UNC(Universal Naming Convention)路径
它们俩都是Windows操作系统中的两个概念,用于指定文件或目录的位置。
- 驱动器号:
- 在Windows系统中,每个物理或逻辑磁盘分区都被分配一个驱动器号,通常是一个字母后跟一个冒号。例如,
C:通常是指系统启动磁盘,D:可能是指第二个磁盘分区,依此类推。驱动器号后面可以跟一个路径,如C:\Windows\System32,表示C:驱动器上的Windows\System32目录。 - 驱动器号是Windows特有的概念,不适用于Unix-like操作系统。
- 在Windows系统中,每个物理或逻辑磁盘分区都被分配一个驱动器号,通常是一个字母后跟一个冒号。例如,
- UNC路径:
- UNC路径是一种用于指定网络资源位置的通用命名约定。UNC路径的格式通常是
\\servername\sharename\path\filename,其中servername是网络服务器的主机名或IP地址,sharename是共享资源的名称,path是共享资源内的文件路径,filename是要访问的文件或目录的名称。 - UNC路径可以用于访问网络上的共享文件夹或打印机等资源,不依赖于特定的驱动器号。
- UNC路径在Windows网络环境中广泛使用,但也得到了其他支持SMB(Server Message Block)协议的系统的支持,如一些Unix-like系统。
- UNC路径是一种用于指定网络资源位置的通用命名约定。UNC路径的格式通常是
❗ 注意:驱动器号是Windows专有的,但UNC不是(Windows和Linux都有)。
2. pathlib库下Path类的基本使用
2.1 Path类的属性和方法概览
⚠️ 我这里使用的Python版本为:
Python 3.10.14 (main, Mar 21 2024, 16:24:04) [GCC 11.2.0] on linux
| 性质 | 是否常用 | 用法 | 说明 |
|---|---|---|---|
| 🛠️属性 | .drive | 获取路径的驱动器号(Windows系统) | |
| 🛠️属性 | 🔥 | .name | 获取最后一级的文件或目录名 |
| 🛠️属性 | 🔥 | .parent | 获取直接父目录的Path对象 |
| 🛠️属性 | .parents | 返回一个生成器,可以遍历当前Path对象的所有上级目录 | |
| 🛠️属性 | 🔥 | .parts | 获取路径的组成部分 |
| 🛠️属性 | .root | 获取路径的根部分 | |
| 🛠️属性 | 🔥 | .stem | 获取文件名的基础部分(无扩展名) |
| 🛠️属性 | 🔥 | .suffix | 获取文件名的扩展名 |
| 🛠️属性 | .suffixes | 获取文件名的所有扩展名 | |
| 🧊方法 | 🔥 | .absolute() | 返回路径的绝对形式 |
| 🧊方法 | .cwd() | 返回当前工作目录的Path对象 | |
| 🧊方法 | 🔥 | .exists() | 检查路径是否指向一个已存在的文件或目录 |
| 🧊方法 | .expanduser() | 展开路径中的~和~user | |
| 🧊方法 | 🔥 | .glob() | 根据模式匹配返回路径列表 |
| 🧊方法 | 🔥 | .is_absolute() | 检查路径是否为绝对路径 |
| 🧊方法 | 🔥 | .is_dir() | 检查路径是否指向一个目录 |
| 🧊方法 | 🔥 | .is_file() | 检查路径是否指向一个文件 |
| 🧊方法 | .iterdir() | 遍历目录中的所有项 | |
| 🧊方法 | 🔥 | .joinpath() | 将多个路径组件合并为一个路径 |
| 🧊方法 | 🔥 | .mkdir() | 创建一个新目录 |
| 🧊方法 | 🔥 | .open() | 打开文件 |
| 🧊方法 | 🔥 | .rename() | 重命名文件或目录(可以用来移动文件) |
| 🧊方法 | .resolve() | 解析路径,返回绝对路径 | |
| 🧊方法 | 🔥 | .rglob() | 递归地根据模式匹配目录中的路径 |
| 🧊方法 | .rmdir() | 删除目录 | |
| 🧊方法 | .samefile() | 检查两个路径是否指向同一个文件或目录 | |
| 🧊方法 | .stat() | 返回关于文件或目录的信息 | |
| 🧊方法 | 🔥 | .touch() | 创建一个空文件 |
| 🧊方法 | 🔥 | .unlink() | 删除文件或符号链接 |
| 🧊方法 | .with_name() | 返回一个新的Path对象,其文件名部分替换为给定名称 | |
| 🧊方法 | .with_suffix() | 返回一个新的Path对象,其扩展名部分替换为给定后缀 |
2.1 🛠️ 属性解析
🛠️ [1] .name:返回路径的最后一部分
- 作用:
Path.name属性用于获取路径的最后一个组成部分,即文件或文件夹的名称。 - 返回值类型:字符串(
str) - 💡 注意:
- 如果传入的路径不是指向文件或文件夹,而是例如驱动器或根目录,那么返回的可能是空字符串。
Path.name不会检查文件或文件夹是否存在,它只关注路径字符串的格式。- 如果路径以斜杠(
/或\)结束,表示它是一个目录路径,那么Path.name可能返回空字符串或最后一个目录名。
- 示例代码:
from pathlib import Path
dataset = Path('/mnt/f/Learning-Notebook-Codes/Datasets')
dataset_compressed_package = Path('/mnt/f/Learning-Notebook-Codes/Datasets.tar.gz')
image = Path('Datasets/coco128/train/images/000000000061.jpg')
label = Path('Datasets/coco128/train/labels/000000000061.txt')
print(f"{dataset.name = }")
print(f"{dataset_compressed_package.name = }")
print(f"{image.name = }")
print(f"{label.name = }")
dataset.name = 'Datasets'
dataset_compressed_package.name = 'Datasets.tar.gz'
image.name = '000000000061.jpg'
label.name = '000000000061.txt'
🛠️ [2] .stem和.suffix:获取文件前缀和后缀
- 作用:
Path.stem属性用于获取文件路径中除去文件扩展名(即后缀)的部分,而Path.suffix属性用于获取文件路径的文件扩展名。 - 返回值类型:字符串(
str) - 💡 注意:
- 这两个属性通常用于处理文件路径,如果传入的路径不是文件,而是目录,那么
Path.stem会返回目录名,而Path.suffix将返回空字符串。 Path.stem和Path.suffix不会检查文件或文件夹是否存在,它们只关注路径字符串的格式。- 如果路径不包含文件扩展名,
Path.suffix将返回空字符串。 - 如果路径以斜杠(
/或\)结束,表示它是一个目录路径,那么Path.stem可能返回空字符串或最后一个目录名,而Path.suffix将返回空字符串。 - 对于
.tar.gz这样的双后缀的文件,只会返回最后一个后缀。
- 这两个属性通常用于处理文件路径,如果传入的路径不是文件,而是目录,那么
- 示例代码:
from pathlib import Path
dataset = Path('/mnt/f/Learning-Notebook-Codes/Datasets')
dataset_compressed_package = Path('/mnt/f/Learning-Notebook-Codes/Datasets.tar.gz')
image = Path('Datasets/coco128/train/images/000000000061.jpg')
label = Path('Datasets/coco128/train/labels/000000000061.txt')
print(f"[前缀-{dataset.name}] {dataset.stem}")
print(f"[后缀-{dataset.name}] {dataset.suffix}")
print(f"[前缀-{dataset_compressed_package.name}] {dataset_compressed_package.stem}")
print(f"[后缀-{dataset_compressed_package.name}] {dataset_compressed_package.suffix}")
print(f"[前缀-{image.name}] {image.stem}")
print(f"[后缀-{image.name}] {image.suffix}")
print(f"[前缀-{label.name}] {label.stem}")
print(f"[后缀-{label.name}] {label.suffix}")
[前缀-Datasets] Datasets
[后缀-Datasets]
[前缀-Datasets.tar.gz] Datasets.tar # 💡 .tar也在前缀中
[后缀-Datasets.tar.gz] .gz # 💡 只会返回.gz这一个后缀(即只返回最后一个后缀)
[前缀-000000000061.jpg] 000000000061
[后缀-000000000061.jpg] .jpg
[前缀-000000000061.txt] 000000000061
[后缀-000000000061.txt] .txt
🛠️ [3] .parent:返回路径的父级目录
- 作用:
Path.parent属性用于获取路径中父目录的路径。对于任何给定的路径,Path.parent将返回一个Path对象,该对象表示当前路径的上一层目录。 - 返回值类型:
Path对象 - 💡 注意:
- 可以连续调用
.parent属性 - 如果 Path 对象创建时用的绝对路径,最终的父目录是
/ - 如果 Path 对象创建时用的相对路径,最终的父目录是
. - 如果传入的路径已经是根目录,那么
Path.parent可能会返回当前目录本身,因为根目录没有父目录。 Path.parent不会检查路径是否指向存在的文件或文件夹,它只操作路径字符串。- 如果路径不存在,
Path.parent仍然可以返回父目录的路径,因为它不验证路径的真实性。
- 可以连续调用
- 示例代码:
from pathlib import Path
def print_parents(p: Path):
parents = p.parents
print(f"{type(parents) = }")
for i, dirpath in enumerate(parents):
print(f"[{p.name}] [L{i}] {dirpath}")
print('-'*100)
dataset = Path('/mnt/f/Learning-Notebook-Codes/Datasets')
dataset_compressed_package = Path('/mnt/f/Learning-Notebook-Codes/Datasets.tar.gz')
image = Path('Datasets/coco128/train/images/000000000061.jpg')
label = Path('Datasets/coco128/train/labels/000000000061.txt')
print_parents(dataset)
print_parents(dataset_compressed_package)
print_parents(image)
print_parents(label)
dataset.parent = PosixPath('/mnt/f/Learning-Notebook-Codes')
dataset.parent.parent = PosixPath('/mnt/f')
dataset.parent.parent.parent = PosixPath('/mnt')
dataset.parent.parent.parent.parent = PosixPath('/')
dataset.parent.parent.parent.parent.parent = PosixPath('/')
----------------------------------------------------------------------------------------------------
dataset_compressed_package.parent = PosixPath('/mnt/f/Learning-Notebook-Codes')
dataset_compressed_package.parent.parent = PosixPath('/mnt/f')
dataset_compressed_package.parent.parent.parent = PosixPath('/mnt')
dataset_compressed_package.parent.parent.parent.parent = PosixPath('/')
dataset_compressed_package.parent.parent.parent.parent.parent = PosixPath('/')
----------------------------------------------------------------------------------------------------
image.parent = PosixPath('Datasets/coco128/train/images')
image.parent.parent = PosixPath('Datasets/coco128/train')
image.parent.parent.parent = PosixPath('Datasets/coco128')
image.parent.parent.parent.parent = PosixPath('Datasets')
image.parent.parent.parent.parent.parent = PosixPath('.')
----------------------------------------------------------------------------------------------------
label.parent = PosixPath('Datasets/coco128/train/labels')
label.parent.parent = PosixPath('Datasets/coco128/train')
label.parent.parent.parent = PosixPath('Datasets/coco128')
label.parent.parent.parent.parent = PosixPath('Datasets')
label.parent.parent.parent.parent.parent = PosixPath('.')
🛠️ [4] .parents:获取所有的父级目录
- 作用:
Path.parents属性用于生成一个迭代器,它按照从当前路径向上到根目录的顺序,产生所有父目录的Path对象。 - 返回值类型:可迭代类型(生成器)
- 💡 注意:
Path.parents可以用于任何路径,无论它是文件还是文件夹。- 如果传入的路径是文件,
Path.parents仍然会生成其父目录的Path对象,而不是报错。 Path.parents不会检查路径是否指向存在的文件或文件夹,它只操作路径字符串。- 如果路径不存在,
Path.parents仍然可以产生父目录的路径,因为它不验证路径的真实性。 - 如果 Path 对象创建时用的绝对路径,最终的父目录是
/ - 如果 Path 对象创建时用的相对路径,最终的父目录是
.
- 示例代码:
from pathlib import Path
def print_parents(p: Path):
parents = p.parents
print(f"[{p.name}] {type(parents) = }")
for i, dirpath in enumerate(p.parents):
print(f"[{p.name}] [L{i}] {dirpath}")
print('-'*100)
dataset = Path('/mnt/f/Learning-Notebook-Codes/Datasets')
dataset_compressed_package = Path('/mnt/f/Learning-Notebook-Codes/Datasets.tar.gz')
image = Path('Datasets/coco128/train/images/000000000061.jpg')
label = Path('Datasets/coco128/train/labels/000000000061.txt')
print_parents(dataset)
print_parents(dataset_compressed_package)
print_parents(image)
print_parents(label)
[Datasets] type(parents) = <class 'pathlib._PathParents'>
[Datasets] [L0] /mnt/f/Learning-Notebook-Codes
[Datasets] [L1] /mnt/f
[Datasets] [L2] /mnt
[Datasets] [L3] /
----------------------------------------------------------------------------------------------------
[Datasets.tar.gz] type(parents) = <class 'pathlib._PathParents'>
[Datasets.tar.gz] [L0] /mnt/f/Learning-Notebook-Codes
[Datasets.tar.gz] [L1] /mnt/f
[Datasets.tar.gz] [L2] /mnt
[Datasets.tar.gz] [L3] /
----------------------------------------------------------------------------------------------------
[000000000061.jpg] type(parents) = <class 'pathlib._PathParents'>
[000000000061.jpg] [L0] Datasets/coco128/train/images
[000000000061.jpg] [L1] Datasets/coco128/train
[000000000061.jpg] [L2] Datasets/coco128
[000000000061.jpg] [L3] Datasets
[000000000061.jpg] [L4] .
----------------------------------------------------------------------------------------------------
[000000000061.txt] type(parents) = <class 'pathlib._PathParents'>
[000000000061.txt] [L0] Datasets/coco128/train/labels
[000000000061.txt] [L1] Datasets/coco128/train
[000000000061.txt] [L2] Datasets/coco128
[000000000061.txt] [L3] Datasets
[000000000061.txt] [L4] .
----------------------------------------------------------------------------------------------------
🛠️ [5] .parts:返回路径的组成部分
- 作用:
Path.parts属性用于获取路径的组成部分,它将路径分割为一个元组,其中包含驱动器(如果有的话)、根目录(如果有的话)以及每个后续的目录或文件名。 - 返回值类型:元组(
tuple) - 💡 注意:
Path.parts可以用于任何路径,无论它是文件还是文件夹,不会因为路径是文件而报错。Path.parts不会检查路径是否指向存在的文件或文件夹,它只操作路径字符串。- 如果路径不存在,
Path.parts仍然可以分割并返回路径的组成部分,因为它不验证路径的真实性。
- 示例代码:
from pathlib import Path
dataset = Path('/mnt/f/Learning-Notebook-Codes/Datasets')
dataset_compressed_package = Path('/mnt/f/Learning-Notebook-Codes/Datasets.tar.gz')
image = Path('Datasets/coco128/train/images/000000000061.jpg')
label = Path('Datasets/coco128/train/labels/000000000061.txt')
print(f"[{dataset.name}] {dataset.parts}")
print(f"[{dataset_compressed_package.name}] {dataset_compressed_package.parts}")
print(f"[{image.name}] {image.parts}")
print(f"[{label.name}] {label.parts}")
[ Datasets ] ('/', 'mnt', 'f', 'Learning-Notebook-Codes', 'Datasets')
[Datasets.tar.gz ] ('/', 'mnt', 'f', 'Learning-Notebook-Codes', 'Datasets.tar.gz')
[000000000061.jpg] ('Datasets', 'coco128', 'train', 'images', '000000000061.jpg')
[000000000061.txt] ('Datasets', 'coco128', 'train', 'labels', '000000000061.txt')
2.2 🧊 方法解析
🧊 [1] Path.cwd():获取当前工作目录
- 作用:
Path.cwd()方法用于获取当前工作目录的Path对象,即当前Python进程的工作目录。 - 返回值类型:
Path对象 - 💡 注意:
Path.cwd()不需要传入参数,它直接返回当前工作目录的Path对象。- 如果直接调用
Path.cwd()返回是一个Path对象,如需获取字符串,则需要Path.cwd().name。 - 如果通过对象调用
p.cwd()返回是一个字符串,而非Path对象。
- 示例代码:
from pathlib import Path
import os
dataset = Path('/mnt/f/Learning-Notebook-Codes/Datasets')
dataset_compressed_package = Path('/mnt/f/Learning-Notebook-Codes/Datasets.tar.gz')
image = Path('Datasets/coco128/train/images/000000000061.jpg')
label = Path('Datasets/coco128/train/labels/000000000061.txt')
print(f"[使用os库] {os.getcwd() = }")
print(f"[直接调用] {Path.cwd() = }")
print(f"[直接调用] {Path.cwd().name = }")
print(f"[{dataset.name}] {dataset.cwd()}")
print(f"[{dataset_compressed_package.name}] {dataset_compressed_package.cwd()}")
print(f"[{image.name}] {image.cwd()}")
print(f"[{label.name}] {label.cwd()}")
[使用os库] os.getcwd() = '/mnt/f/Learning-Notebook-Codes'
[直接调用] Path.cwd() = PosixPath('/mnt/f/Learning-Notebook-Codes')
[直接调用] Path.cwd().name = 'Learning-Notebook-Codes'
[Datasets] /mnt/f/Learning-Notebook-Codes
[Datasets.tar.gz] /mnt/f/Learning-Notebook-Codes
[000000000061.jpg] /mnt/f/Learning-Notebook-Codes
[000000000061.txt] /mnt/f/Learning-Notebook-Codes
🧊 [2] Path.home():返回当前用户的家目录
- 作用:
Path.home()方法用于获取当前用户的主目录(也称为家目录,即/user/home)的Path对象。 - 返回值类型:
Path对象 - 💡 注意:
Path.home()不需要传入参数,它直接返回当前用户的主目录的Path对象。- 如果直接调用
Path.home()返回是一个Path对象,如需获取字符串,则需要.name - 如果通过对象调用
p.home()返回是一个字符串,而非Path对象 - 如果在多用户系统中,
Path.home()返回的是调用该方法的用户的主目录。
- 示例代码:
from pathlib import Path
dataset = Path('/mnt/f/Learning-Notebook-Codes/Datasets')
dataset_compressed_package = Path('/mnt/f/Learning-Notebook-Codes/Datasets.tar.gz')
image = Path('Datasets/coco128/train/images/000000000061.jpg')
label = Path('Datasets/coco128/train/labels/000000000061.txt')
print(f"[直接调用] {Path.home() = }")
print(f"[直接调用] {Path.home().name = }")
print(f"[{dataset.name}] {dataset.home()}")
print(f"[{dataset_compressed_package.name}] {dataset_compressed_package.home()}")
print(f"[{image.name}] {image.home()}")
print(f"[{label.name}] {label.home()}")
[直接调用] Path.home() = PosixPath('/home/leovin')
[直接调用] Path.home().name = 'leovin'
[Datasets] /home/leovin
[Datasets.tar.gz] /home/leovin
[000000000061.jpg] /home/leovin
[000000000061.txt] /home/leovin
🧊 [3] .stat():获取文件详细信息
- 作用:获取文件详细信息,包括文件大小、创建时间、最后访问时间、最后修改时间等。该方法返回一个
os.stat_result对象,其常用属性如下:st_mode: 文件类型和权限信息。st_size: 文件大小(以字节为单位)。st_atime: 文件最后访问时间。st_mtime: 文件最后修改时间。st_ctime: 文件状态改变时间(Windows上为创建时间)。- …(不常用)
- 返回值类型:
os.stat_result对象 - 💡 注意:
Path.stat()需要路径指向的文件或文件夹存在,否则会抛出FileNotFoundError。Path.stat()不会返回可迭代类型,而是返回一个包含文件状态信息的os.stat_result对象。- 文件大小、时间不易读,我们可以改为易读的形式。
- 示例代码:
from pathlib import Path
import datetime
image = Path('Datasets/coco128/train/images/000000000061.jpg')
print(f"------------------------------ 原始信息 ------------------------------")
print(f"获取文件详细信息: {image.stat()}")
print(f"获取文件字节大小: {image.stat().st_size}")
print(f"获取文件创建时间: {image.stat().st_ctime}") # c: create
print(f"获取文件上次修改时间: {image.stat().st_mtime}") # m:: modify
print(f"---------------------------- 改为易读形式 ----------------------------")
# 获取文件详细统计信息
stat_info = image.stat()
# 打印文件字节大小,并转换为KB和MB
file_size_bytes = stat_info.st_size
file_size_kb = file_size_bytes / 1024
file_size_mb = file_size_kb / 1024
print(f"文件字节大小: {file_size_bytes} bytes, {file_size_kb:.2f} KB, {file_size_mb:.2f} MB")
# 打印文件创建时间(转换为人类可读的格式)
create_time = datetime.datetime.fromtimestamp(stat_info.st_ctime).strftime('%Y-%m-%d %H:%M:%S')
print(f"文件创建时间: {create_time}")
# 打印文件上次修改时间(转换为人类可读的格式)
modify_time = datetime.datetime.fromtimestamp(stat_info.st_mtime).strftime('%Y-%m-%d %H:%M:%S')
print(f"文件上次修改时间: {modify_time}")
------------------------------ 原始信息 ------------------------------
获取文件详细信息: os.stat_result(st_mode=33279, st_ino=1125899907375496, st_dev=49, st_nlink=1,
st_uid=1000, st_gid=1000, st_size=135566, st_atime=1714285132,
st_mtime=1666146712, st_ctime=1707038640)
获取文件字节大小: 135566
获取文件创建时间: 1707038640.4572322
获取文件上次修改时间: 1666146712.0
---------------------------- 改为易读形式 ----------------------------
文件字节大小: 135566 bytes, 132.39 KB, 0.13 MB
文件创建时间: 2024-02-04 17:24:00
文件上次修改时间: 2022-10-19 10:31:52
🧊 [4] .exists():检查目录或者文件是否存在
- 作用:
Path.exists()方法用于检查路径所指的📑文件或📂文件夹是否存在。 - 返回值类型:布尔值(
bool) - 💡 注意:
- 等价于
os.path.exists(具体的路径)。 os.path.exists(Path)也是可以的(Path甚至都不用.name)。Path.exists()不会抛出异常,即使路径不存在也不会报错。Path.exists()只检查路径的存在性,而不检查路径的访问权限(潜在风险:即使路径存在,也可能由于权限问题而无法访问)。
- 等价于
- 示例代码:
from pathlib import Path
import os
dataset = Path('/mnt/f/Learning-Notebook-Codes/Datasets')
dataset_compressed_package = Path('/mnt/f/Learning-Notebook-Codes/Datasets.tar.gz')
image = Path('Datasets/coco128/train/images/000000000061.jpg')
label = Path('Datasets/coco128/train/labels/000000000061.txt')
print(f"[{dataset.name}] [调用os库] {os.path.exists(dataset) = }")
print(f"[{dataset.name}] {dataset.exists() = }")
print(f"[{dataset_compressed_package.name}] {dataset_compressed_package.exists() = }")
print(f"[{dataset_compressed_package.name}] [调用os库] {os.path.exists(dataset_compressed_package) = }")
print(f"[{image.name}] {image.exists() = }")
print(f"[{image.name}] [调用os库] {os.path.exists(image) = }")
print(f"[{label.name}] {label.exists() = }")
print(f"[{label.name}] [调用os库] {os.path.exists(label) = }")
[Datasets] [调用os库] os.path.exists(dataset) = True
[Datasets] dataset.exists() = True
[Datasets.tar.gz] dataset_compressed_package.exists() = False
[Datasets.tar.gz] [调用os库] os.path.exists(dataset_compressed_package) = False
[000000000061.jpg] image.exists() = True
[000000000061.jpg] [调用os库] os.path.exists(image) = True
[000000000061.txt] label.exists() = True
[000000000061.txt] [调用os库] os.path.exists(label) = True
🧊 [5] .is_file()和.is_dir():判断路径的性质(文件/文件夹)
- 作用:
Path.is_file()方法用于检查路径是否指向一个📑文件,而Path.is_dir()方法用于检查路径是否指向一个📂目录(文件夹)。 - 返回值类型:布尔值(
bool) - 💡 注意:
- 等价于
os.path.isfile(路径)和os.path.isdir(路径) Path.is_file()返回True如果路径所指的是一个🖺文件,否则返回False。Path.is_dir()返回True如果路径所指的是一个📂目录,否则返回False。- 在某些情况下,如果权限问题导致无法确定路径的类型,这两个方法可能会抛出
PermissionError或OSError。
- 等价于
- 示例代码:
from pathlib import Path
import os
def get_path_type_Path(path: Path) -> str:
if path.is_file():
return 'file'
elif path.is_dir():
return 'dir'
else:
return 'unknown'
def get_path_type_os(path: str) -> str:
if os.path.isfile(path):
return 'file'
elif os.path.isdir(path):
return 'dir'
else:
return 'unknown'
dataset = Path('/mnt/f/Learning-Notebook-Codes/Datasets')
dataset_compressed_package = Path('/mnt/f/Learning-Notebook-Codes/Datasets.tar.gz')
image = Path('Datasets/coco128/train/images/000000000061.jpg')
label = Path('Datasets/coco128/train/labels/000000000061.txt')
print(f"[{dataset.name}] [调用os库] {get_path_type_os(dataset.absolute()) = }")
print(f"[{dataset.name}] {get_path_type_Path(dataset) = }")
print(f"[{dataset_compressed_package.name}] [调用os库] {get_path_type_os(dataset_compressed_package.absolute()) = }")
print(f"[{dataset_compressed_package.name}] {get_path_type_Path(dataset_compressed_package) = }")
print(f"[{image.name}] [调用os库] {get_path_type_os(image.absolute()) = }")
print(f"[{image.name}] {get_path_type_Path(image) = }")
print(f"[{label.name}] [调用os库] {get_path_type_os(label.absolute()) = }")
print(f"[{label.name}] {get_path_type_Path(label) = }")
[Datasets] [调用os库] get_path_type_os(dataset.absolute()) = 'dir'
[Datasets] get_path_type_Path(dataset) = 'dir'
[Datasets.tar.gz] [调用os库] get_path_type_os(dataset_compressed_package.absolute()) = 'unknown'
[Datasets.tar.gz] get_path_type_Path(dataset_compressed_package) = 'unknown'
[000000000061.jpg] [调用os库] get_path_type_os(image.absolute()) = 'file'
[000000000061.jpg] get_path_type_Path(image) = 'file'
[000000000061.txt] [调用os库] get_path_type_os(label.absolute()) = 'file'
[000000000061.txt] get_path_type_Path(label) = 'file'
🧊 [6] .resolve():返回规范的绝对路径(解析路径)
- 作用:
Path.resolve()方法用于解析路径,返回一个绝对路径的Path对象。它会解决路径中的符号链接,.,..等相对路径组件,并返回一个规范化的绝对路径。 - 返回值类型:
Path对象 - 💡 注意:
- 不管传入的是相对路径还是绝对路径,返回的都是完整的绝对路径。
Path.resolve()返回的路径是绝对路径,如果传入的是相对路径,它会相对于当前工作目录进行解析。- 如果路径中包含符号链接,
Path.resolve()会解析符号链接指向的实际路径。 - 如果在解析过程中遇到权限问题,
Path.resolve()可能会抛出PermissionError或OSError。 Path.resolve()不会检查路径指向的文件或目录是否存在,它只负责路径解析和规范化。
- 示例代码:
from pathlib import Path
dataset = Path('/mnt/d/Learning-Notebook-Codes/Datasets')
dataset_compressed_package = Path('/mnt/d/Learning-Notebook-Codes/Datasets.tar.gz')
image = Path('Datasets/coco128/train/images/000000000061.jpg')
label = Path('Datasets/coco128/train/labels/000000000061.txt')
print(f"[绝对路径] [{dataset.name}] {dataset.resolve() = }")
print(f"[绝对路径] [{dataset_compressed_package.name}] {dataset_compressed_package.resolve() = }")
print(f"[相对路径] [{image.name}] {image.resolve() = }")
print(f"[相对路径] [{label.name}] {label.resolve() = }")
[绝对路径] [Datasets] dataset.resolve() = PosixPath('/mnt/d/Learning-Notebook-Codes/Datasets')
[绝对路径] [Datasets.tar.gz] dataset_compressed_package.resolve() = PosixPath('/mnt/d/Learning-Notebook-Codes/Datasets.tar.gz')
[相对路径] [000000000061.jpg] image.resolve() = PosixPath('/mnt/d/Learning-Notebook-Codes/Datasets/coco128/train/images/000000000061.jpg')
[相对路径] [000000000061.txt] label.resolve() = PosixPath('/mnt/d/Learning-Notebook-Codes/Datasets/coco128/train/labels/000000000061.txt')
🧊 [7] .iterdir():遍历一个目录(不会递归)
- 作用:
Path.iterdir()方法用于遍历路径所指的目录中的所有项(文件和子目录),返回一个迭代器,其中包含目录中每个项的Path对象。 - 返回值类型:迭代器(生成器)
- 💡 注意:
Path.iterdir()只适用于目录路径,如果路径指向的是文件,将会抛出NotADirectoryError。Path.iterdir()不会递归地遍历子目录,它只返回当前目录的直接项。- 如果目录不存在,
Path.iterdir()会抛出FileNotFoundError。 Path.iterdir()返回的迭代器中不包括.和..这两个特殊的目录项。- 在使用
Path.iterdir()时,如果目录中的项在迭代过程中被修改或删除,迭代行为可能不会反映这些变化。
- 示例代码:
from pathlib import Path
def iterate(it):
try:
for i, content in enumerate(it):
print(f"[{i}] {content}")
except Exception as e:
print(f"❌ 该对象不可迭代: {e}")
dataset = Path('/mnt/d/Learning-Notebook-Codes/Datasets')
dataset_compressed_package = Path('/mnt/d/Learning-Notebook-Codes/Datasets.tar.gz')
image = Path('Datasets/coco128/train/images/000000000061.jpg')
label = Path('Datasets/coco128/train/labels/000000000061.txt')
# 调用Path.iterdir()方法
iter_dataset = dataset.iterdir()
iter_dataset_compressed_package = dataset_compressed_package.iterdir()
iter_image = image.iterdir()
iter_label = label.iterdir()
iterate(iter_dataset)
iterate(iter_dataset_compressed_package)
iterate(image)
iterate(label)
[0] /mnt/d/Learning-Notebook-Codes/Datasets/coco128
[1] /mnt/d/Learning-Notebook-Codes/Datasets/coco128.tar.gz
[2] /mnt/d/Learning-Notebook-Codes/Datasets/imagenet_classes_indices.csv
[3] /mnt/d/Learning-Notebook-Codes/Datasets/VOCdevkit
[4] /mnt/d/Learning-Notebook-Codes/Datasets/Web
❌ 该对象不可迭代: [Errno 2] No such file or directory: '/mnt/d/Learning-Notebook-Codes/Datasets.tar.gz'
❌ 该对象不可迭代: 'PosixPath' object is not iterable
❌ 该对象不可迭代: 'PosixPath' object is not iterable
🧊 [8] .glob():获取所有符合pattern的文件
- 作用:
Path.glob()方法用于匹配路径下符合特定模式的所有文件和子目录的名称,返回一个迭代器,其中包含匹配的项的Path对象。 - 返回值类型:迭代器(生成器),例子:
generator -> <generator object Path.glob at 0x7fa812d2e7a0> - 💡 注意:
Path.glob()接受一个使用通配符的模式作为参数,如*.txt匹配所有扩展名为.txt的文件。Path.glob()可以使用相对路径或绝对路径,如果是相对路径,它将相对于调用glob()的Path对象所在的目录进行匹配。Path.glob()不会递归地匹配子目录中的文件,只匹配当前目录下符合模式的文件和子目录。- 如果需要递归地匹配所有子目录中的文件,可以使用
**通配符,例如**/*.txt。还是推荐使用 Path.rglob() 方法。 - 如果路径不存在,
Path.glob()将返回一个空的迭代器(不会报错)。 Path.glob()返回的迭代器中不会包含.和..这两个特殊的目录项。- 这里的pattern并不是正则表达式(Regex)而是 globbing 模式,这是一种比正则表达式更简单的模式匹配机制。
- 💡 Globbing 模式支持的通配符包括:
*:匹配任意数量的字符(不包括路径分隔符)?:匹配单个字符[seq]:匹配 seq 中的任意一个字符(字符集)[!seq]:匹配不在 seq 中的任意一个字符(否定字符集)
- Globbing 模式示例:
- 如果我们想匹配所有以
.txt结尾的文件,我们可以使用*.txt作为模式。 - 如果我们想匹配以数字开头,后面跟着任意字符的文件,我们可以使用
[0-9]*。
- 如果我们想匹配所有以
- 补充:如果我们需要使用正则表达式来匹配文件路径,我们可以使用标准库中的
re模块,或者结合Path对象使用Path.match()方法,后者接受一个正则表达式作为参数。 - 示例代码:
from pathlib import Path
directory = Path('Python/code/code_of_pathlib/files')
# 我们创建一个文件夹
directory.mkdir(parents=True, exist_ok=True)
# 再创建一些文件
filenames = [
'file1.txt',
'file2.txt',
'file2.py',
'file3.xml',
'file4.log',
'file5.csv',
'file6.json',
'fileA.txt',
'fileB.txt',
'fileBBBBB.txt',
'fileC.xml',
]
for filename in filenames:
# 组合路径
filepath = directory.joinpath(filename)
# 创建文件
filepath.touch(exist_ok=True) # 💡 如果文件已经存在,也会更新文件的时间戳
print("------〔1〕❌ 使用[seq]匹配以'file'开头,后面跟着'1'或'2'的.txt文件或.py文件 ------")
for txt_file in directory.glob('file[12]*.{txt,py}'): # 💡 这样写是不可以的
print(txt_file)
print("\n------〔1〕✅ 使用[seq]匹配以'file'开头,后面跟着'1'或'2'的.txt文件或.py文件 ------")
extensions = ['*.txt', '*.py']
for ext in extensions:
pattern = f"file[12]{ext}"
# pattern = "file[12]" + ext # 这里写也可以
for file in directory.glob(pattern):
print(file)
print("\n-----------〔2〕使用[seq]匹配以'file'开头,后面跟着'1'或'2'的.txt文件 -----------")
for txt_file in directory.glob('file[12]*.txt'):
print(txt_file)
print("\n--------------------〔3〕使用[!seq]匹配不以数字开头的.txt文件 --------------------")
for txt_file in directory.glob('file[!0-9]*.txt'): # 💡 这里加了*表示非数字后面可以后其他内容
print(txt_file)
print("\n--------------------〔4〕使用[!seq]匹配不以数字开头的.txt文件 ---------------------")
for txt_file in directory.glob('file[!0-9].txt'): # 💡 这里没有加*表示必须后面不可以后其他内容,file非数字内容.txt
print(txt_file)
print("\n-----〔5〕使用[seq]匹配以'file'开头,后面跟着'A'到'C'之间的任意字母的.txt文件 -----")
for txt_file in directory.glob('file[A-C].txt'):
print(txt_file)
print("\n-----------------〔6〕使用[!seq]匹配不以字母'A'或'B'开头的.txt文件 ----------------")
for log_file in directory.glob('file[!AB]*.txt'):
print(log_file)
------〔1〕❌ 使用[seq]匹配以'file'开头,后面跟着'1'或'2'的.txt文件或.py文件 ------
------〔1〕✅ 使用[seq]匹配以'file'开头,后面跟着'1'或'2'的.txt文件或.py文件 ------
Python/code/code_of_pathlib/files/file1.txt
Python/code/code_of_pathlib/files/file2.txt
Python/code/code_of_pathlib/files/file2.py
-----------〔2〕使用[seq]匹配以'file'开头,后面跟着'1'或'2'的.txt文件 -----------
Python/code/code_of_pathlib/files/file1.txt
Python/code/code_of_pathlib/files/file2.txt
--------------------〔3〕使用[!seq]匹配不以数字开头的.txt文件 --------------------
Python/code/code_of_pathlib/files/fileA.txt
Python/code/code_of_pathlib/files/fileB.txt
Python/code/code_of_pathlib/files/fileBBBBB.txt
--------------------〔4〕使用[!seq]匹配不以数字开头的.txt文件 ---------------------
Python/code/code_of_pathlib/files/fileA.txt
Python/code/code_of_pathlib/files/fileB.txt
-----〔5〕使用[seq]匹配以'file'开头,后面跟着'A'到'C'之间的任意字母的.txt文件 -----
Python/code/code_of_pathlib/files/fileA.txt
Python/code/code_of_pathlib/files/fileB.txt
-----------------〔6〕使用[!seq]匹配不以字母'A'或'B'开头的.txt文件 ----------------
Python/code/code_of_pathlib/files/file1.txt
Python/code/code_of_pathlib/files/file2.txt
🧊 [9] .rglob():递归地遍历文件夹(递归遍历目录树)
- 作用:
Path.rglob()方法用于递归地匹配路径下和所有子目录中符合特定模式的所有文件和子目录的名称,返回一个迭代器,其中包含匹配的项的Path对象。 - 返回值类型:迭代器(生成器),例子:
generator -> <generator object Path.rglob at 0x7ffa4746e810> - 小知识:
- rglob: recursive glob,即递归的glob
- glob 的名称来源于 Unix 中的 glob 函数,该函数用于将通配符扩展成匹配的文件列表。这个名字据说来源于 global,因为 glob 函数可以“全局”地匹配一组文件名。
- 💡 注意:
Path.rglob()接受一个使用通配符的模式作为参数,如*.txt匹配所有扩展名为.txt的文件。Path.rglob()可以使用相对路径或绝对路径,如果是相对路径,它将相对于调用rglob()的Path对象所在的目录进行递归匹配。Path.rglob()会递归地遍历所有子目录,匹配当前目录和所有子目录中符合模式的文件和子目录。- 如果路径不存在,
Path.rglob()将返回一个空的迭代器(不会报错)。 Path.rglob()返回的迭代器中不会包含.和..这两个特殊的目录项。Path.rglob('*')是一个比较通用的用法,即遍历所有文件和文件夹。
- 示例代码:
from pathlib import Path
def get_path_type_Path(path: Path) -> str:
if path.is_file():
return 'file'
elif path.is_dir():
return '📂 dir'
else:
return 'unknown'
directory = Path('Python/code/code_of_pathlib/files')
print(f"--------------------〔1〕遍历所有的文件和文件夹 ---------------------")
for path in directory.rglob('*'):
print(f"[{get_path_type_Path(path)}] {path}")
print(f"\n----------------------〔2〕遍历所有的.py文件 ------------------------")
for path in directory.rglob('*.py'):
print(f"[{get_path_type_Path(path)}] {path}")
print(f"\n----------------------〔3〕遍历所有的图片文件 -----------------------")
image_extensions = ['.jpg', '.jpeg', '.png', '.bmp', '.webp']
image_extensions = ['*' + x for x in image_extensions] # 变为*.格式
for ext in image_extensions:
for path in directory.rglob(ext):
print(f"[{get_path_type_Path(path)}] {path}")
--------------------〔1〕遍历所有的文件和文件夹 ---------------------
[file] Python/code/code_of_pathlib/files/code1.py
[file] Python/code/code_of_pathlib/files/code2.py
[📂 dir] Python/code/code_of_pathlib/files/docs
[📂 dir] Python/code/code_of_pathlib/files/images
[file] Python/code/code_of_pathlib/files/docs/aaa.txt
[file] Python/code/code_of_pathlib/files/docs/bbb.docx
[file] Python/code/code_of_pathlib/files/images/cat.png
[file] Python/code/code_of_pathlib/files/images/dog.jpeg
[file] Python/code/code_of_pathlib/files/images/eeg.jpg
[file] Python/code/code_of_pathlib/files/images/person.png
----------------------〔2〕遍历所有的.py文件 ------------------------
[file] Python/code/code_of_pathlib/files/code1.py
[file] Python/code/code_of_pathlib/files/code2.py
----------------------〔3〕遍历所有的图片文件 -----------------------
[file] Python/code/code_of_pathlib/files/images/eeg.jpg
[file] Python/code/code_of_pathlib/files/images/dog.jpeg
[file] Python/code/code_of_pathlib/files/images/cat.png
[file] Python/code/code_of_pathlib/files/images/person.png
🧊 [10] .unlink():删除文件(非目录)
- 作用:
Path.unlink()方法用于删除路径所指的文件。如果路径是一个文件,该方法将移除该文件,使其不再存在于文件系统中。 - 返回值类型:无返回值(
None) - 💡 注意:
Path.unlink()只能用于文件,如果用于目录,将会抛出IsADirectoryError。- 如果文件不存在,
Path.unlink()将抛出FileNotFoundError。 - 在某些操作系统中,如果文件被其他程序打开或占用,
Path.unlink()可能会抛出PermissionError。 Path.unlink()不会删除符号链接本身,而是删除它指向的目标文件。如果需要删除符号链接,请确保路径指向的是符号链接而不是它所指向的文件。Path.unlink()是一个破坏性操作,一旦文件被删除,除非有备份,否则无法恢复。
- 示例代码:
from pathlib import Path
directory = Path('Python/code/code_of_pathlib/files')
# 我们创建一个文件夹
directory.mkdir(parents=True, exist_ok=True)
# 再创建一些文件
filenames = [
'file1.txt',
'file2.txt',
'file2.py',
'file3.xml',
'file4.log',
'file5.csv',
'file6.json',
'fileA.txt',
'fileB.txt',
'fileBBBBB.txt',
'fileC.xml',
]
for filename in filenames:
# 组合路径
filepath = directory.joinpath(filename)
# 创建文件
filepath.touch(exist_ok=True) # 💡 如果文件已经存在,也会更新文件的时间戳
# 删除所有以file开头的文件
for file in directory.glob("file*"):
file.unlink()
print(f"✅ [file📑] {file} has been deleted!")
# 把文件夹也删除
directory.rmdir()
print(f"✅ [folder📂] {directory} has been deleted!")
✅ [file📑] Python/code/code_of_pathlib/files/file1.txt has been deleted!
✅ [file📑] Python/code/code_of_pathlib/files/file2.py has been deleted!
✅ [file📑] Python/code/code_of_pathlib/files/file2.txt has been deleted!
✅ [file📑] Python/code/code_of_pathlib/files/file3.xml has been deleted!
✅ [file📑] Python/code/code_of_pathlib/files/file4.log has been deleted!
✅ [file📑] Python/code/code_of_pathlib/files/file5.csv has been deleted!
✅ [file📑] Python/code/code_of_pathlib/files/file6.json has been deleted!
✅ [file📑] Python/code/code_of_pathlib/files/fileA.txt has been deleted!
✅ [file📑] Python/code/code_of_pathlib/files/fileB.txt has been deleted!
✅ [file📑] Python/code/code_of_pathlib/files/fileBBBBB.txt has been deleted!
✅ [file📑] Python/code/code_of_pathlib/files/fileC.xml has been deleted!
✅ [folder📂]Python/code/code_of_pathlib/files has been deleted!
🧊 [11] .open():打开文件
- 作用:
Path.open()方法用于打开路径所指的文件,并返回一个文件对象,该对象可以用于读取、写入或追加文件内容。 - 返回值类型:文件对象(
io.TextIOBase或io.BufferedIOBase的子类) - 💡 注意:
Path.open()接受的参数与内置的open()函数相同,例如模式('r','w','a'等)、编码和其他选项。- 打开文件的模式和编码可以指定,默认为文本模式(默认使用UTF-8)。
- 如果文件不存在且模式为写入或追加,
Path.open()将创建文件。 - 如果文件不存在且模式为读取,将抛出
FileNotFoundError。 - 如果路径是一个目录,
Path.open()将抛出IsADirectoryError。 - 在使用
Path.open()时,如果需要处理二进制文件,确保在模式中包含'b',例如'rb'或'wb'。 Path.open()返回的文件对象应该在使用后关闭,以释放系统资源。通常使用with语句来确保文件正确关闭。
- 示例代码:
from pathlib import Path
label = Path('Datasets/coco128/train/labels/000000000387.txt')
with label.open('r', encoding='utf-8') as f:
content = f.readlines()
content = [x.strip() for x in content]
for line in content:
print(line)
63 0.682586 0.394385 0.586516 0.577521
63 0.605953 0.430167 0.735719 0.650792
67 0.683594 0.33074 0.328125 0.195312
🧊 [12] .touch():创建空文件
- 作用:
Path.touch()方法用于创建一个空的文件,或者如果文件已经存在,则更新文件的访问和修改时间到当前时间。该方法模仿了触摸文件的行为,即使文件内容没有改变,也会更新文件的时间戳。 - 返回值类型:无返回值(
None) - 💡 注意:
- 如果文件不存在,
Path.touch()将创建一个新文件,但不会写入任何内容,文件大小将为0。 - 如果文件已经存在,
Path.touch()将更新文件的访问和修改时间,而不会改变文件的内容。 Path.touch()可以接受一个可选的mode参数来设置新创建文件的权限模式,以及一个exist_ok参数来控制如果文件已存在时是否抛出异常。- 如果路径指向一个已存在的目录,
Path.touch()将抛出FileExistsError。 - 在某些情况下,如果权限不足,
Path.touch()可能会抛出PermissionError。
- 如果文件不存在,
- 示例代码:
from pathlib import Path
label = Path('临时文件.txt')
# 先创建一次文件
label.touch(exist_ok=True) # 即便文件存在也不会报错,但会更新文件的“最近修改”时间戳
print(f"✅ {label.name} 创建成功!")
# 再次创建文件(exist_ok=False)
try:
label.touch(exist_ok=False)
except Exception as e:
print(f"⚠️ {e}")
# 删除掉这个文件
label.unlink()
print(f"✅ {label.name} 删除成功!")
✅ 临时文件.txt 创建成功!
⚠️ [Errno 17] File exists: '临时文件.txt'
✅ 临时文件.txt 删除成功!
🧊 [13] .mkdir():创建空文件夹
- 作用:
Path.mkdir()方法用于创建一个新的目录(文件夹)。如果指定路径的上层目录不存在,Path.mkdir()将抛出一个异常,除非使用了exist_ok=True参数。 - 返回值类型:无返回值(
None) - 💡 注意:
Path.mkdir()可以接受一个可选的mode参数来设置新创建目录的权限模式。- 如果目录已存在,
Path.mkdir()将抛出FileExistsError,除非exist_ok参数设置为True,在这种情况下,它将不会抛出异常。 - 如果路径的上层目录不存在,
Path.mkdir()将抛出FileNotFoundError,除非parents=True参数被使用,这将创建所有必要的中间目录。 - 在某些情况下,如果权限不足,
Path.mkdir()可能会抛出PermissionError。
- 示例代码:
from pathlib import Path
folder = Path('父级文件夹/临时文件夹')
# 先创建一次文件夹(parents=False, exist_ok=False)
try:
folder.mkdir()
print(f"✅ {folder.name} 创建成功!")
except Exception as e:
print(f"❌ {e}")
# 再次创建文件夹(parents=True, exist_ok=False)
try:
folder.mkdir(parents=True)
print(f"✅ {folder.name} 创建成功!")
except Exception as e:
print(f"❌ {e}")
# 再次创建文件夹(parents=True, exist_ok=False)
try:
folder.mkdir(parents=True)
print(f"✅ {folder.name} 创建成功!")
except Exception as e:
print(f"❌ {e}")
# 再次创建文件夹(parents=True, exist_ok=False)
try:
folder.mkdir(parents=True, exist_ok=True)
print(f"✅ {folder.name} 创建成功!")
except Exception as e:
print(f"❌ {e}")
# 直接删除掉它的父级文件夹
try:
folder.parent.rmdir()
print(f"✅ {folder.name} 删除成功!")
except Exception as e:
print(f"❌ {e}")
# 正确的删除方式
folder.rmdir()
print(f"✅ {folder.name} 删除成功!")
folder.parent.rmdir()
print(f"✅ {folder.parent.name} 删除成功!")
❌ [Errno 2] No such file or directory: '父级文件夹/临时文件夹'
✅ 临时文件夹 创建成功!
❌ [Errno 17] File exists: '父级文件夹/临时文件夹'
✅ 临时文件夹 创建成功!
❌ [Errno 39] Directory not empty: '父级文件夹'
✅ 临时文件夹 删除成功!
✅ 父级文件夹 删除成功!
🧊 [14] .rename():将文件或目录重命名为给定的目标路径。
- 作用:
Path.rename()方法用于将路径所指的文件或目录重命名为给定的目标路径。这个操作会将源路径的文件或目录移动到目标路径,并为其赋予新的名称。 - 返回值类型:新的
Path对象,表示重命名后的目标路径 - 💡 注意:
- 💡 这个可以用于移动文件!
Path.rename()接受一个目标路径作为参数,这个路径可以是相对于当前路径的相对路径,也可以是绝对路径。- 如果目标路径已经存在,
Path.rename()将会覆盖现有的文件或目录,除非它是一个非空的目录,这种情况下会抛出OSError。 - 如果源路径不存在,
Path.rename()将抛出FileNotFoundError。 - 在某些情况下,如果权限不足或文件被占用,
Path.rename()可能会抛出PermissionError或OSError。
- 示例代码:
from pathlib import Path
file = Path('父级文件夹/abc.txt')
# 先创建父级文件夹
parent_dir = Path('父级文件夹')
parent_dir.mkdir(exist_ok=True)
# 创建这个文件
file.touch(exist_ok=True)
# 将文件进行重命名
new_name = file.parent.joinpath('新名字.txt')
file = file.rename(new_name) # 💡 需要接受返回值,否则还是原来的路径
# 判断这个文件是否存在
print(f"重命名是否成功 -> {file.exists()}")
# 💡 .rename()方法也可以用于移动文件
target_dir = Path('新的文件夹')
target_dir.mkdir(exist_ok=True)
# 开始移动
target_path = target_dir.joinpath(file.name)
file = file.rename(target_path)
print(f"移动文件是否成功 -> {file.exists()}")
def delete_dir(folder: Path, del_content=False, verbose=False) -> bool:
"""使用Path类删除文件夹
Args:
folder (Path): 文件夹路径(Path实例化对象)
del_content (bool, optional): 是否要删除有内容的文件夹. Defaults to False.
Returns:
bool: 是否删除成功
"""
# 检查文件夹是否存在且为目录
if folder.exists() and folder.is_dir():
# 如果需要删除内容,则遍历并删除所有内容
if del_content:
# 遍历路径下的所有内容
for item in folder.iterdir():
# 如果是文件夹,则递归调用
if item.is_dir():
delete_dir(item, del_content=True)
# 如果是文件则直接删除
else:
try:
item.unlink()
print(f"[INFO] 文件 {item} 已被删除") if verbose else ...
except FileNotFoundError:
print(f"[⚠️ WARNING] 文件 {item} 不存在,可能已被其他程序删除")
# 尝试删除空文件夹
try:
folder.rmdir()
return True
except Exception as e:
print(f"[❌ ERROR] 删除文件夹 {folder} 失败:{e}")
return False
else:
print(f"[⚠️ WARNING] 路径不存在或者不是文件夹!")
return False
# 删除掉这两个文件夹
print(f"删除文件夹是否成功 -> {delete_dir(parent_dir, del_content=True)}")
print(f"删除文件夹是否成功 -> {delete_dir(target_dir, del_content=True, verbose=True)}")
重命名是否成功 -> True
移动文件是否成功 -> True
删除文件夹是否成功 -> True
[INFO] 文件 新的文件夹/新名字.txt 已被删除
删除文件夹是否成功 -> True
3. Path与os.path的对应关系
Path与os.path其实本质上没啥区别,但Path是一个类,而os.path则是各种函数,因此os.path更适合处理简单的任务,而Path适合处理复杂的任务。
| os.path | Path | 说明 |
|---|---|---|
| os.path.basename() | PurePath.name | 获取路径的最后一部分(文件名或目录名) |
| os.path.dirname() | PurePath.parent | 获取路径的目录部分 |
| os.path.splitext() | PurePath.stem 和 PurePath.suffix | 将文件名分割为名称和扩展名 |
| os.path.samefile() | Path.samefile() | 检查两个路径是否指向相同的文件或目录 |
| os.path.abspath() | Path.resolve() | 获取文件的绝对路径 |
| os.mkdir() | Path.mkdir() | 创建一个新目录 |
| os.makedirs() | Path.mkdir(parents=True) | 创建多个新目录,包括所有必需的中间目录 |
| os.rename() | Path.rename() | 将文件或目录重命名为新名称 |
| os.rmdir() | Path.rmdir() | 删除空目录 |
| os.remove(), os.unlink() | Path.unlink() | 删除文件或链接 |
| os.getcwd() | Path.cwd() | 获取当前工作目录 |
| os.path.exists() | Path.exists() | 检查文件或目录是否存在 |
| os.path.expanduser() | Path.expanduser() 和 Path.home() | 将用户目录(~)扩展为绝对路径 |
| os.listdir() | Path.iterdir() | 列出目录中的所有文件和子目录 |
| os.path.isdir() | Path.is_dir() | 检查路径是否为目录 |
| os.path.isfile() | Path.is_file() | 检查路径是否为文件 |
| os.path.relpath() | PurePath.relative_to() | 获取相对路径 |
| os.stat() | Path.stat(), Path.owner(), Path.group() | 获取文件或目录的状态信息 |
| os.path.join() | PurePath.joinpath() | 连接两个或多个路径组件 |
4. 自定义函数
4.1 删除有内容的文件夹
def delete_dir(folder: Path, del_content=False, verbose=False) -> bool:
"""使用Path类删除文件夹
Args:
folder (Path): 文件夹路径(Path实例化对象)
del_content (bool, optional): 是否要删除有内容的文件夹. Defaults to False.
Returns:
bool: 是否删除成功
"""
# 检查文件夹是否存在且为目录
if folder.exists() and folder.is_dir():
# 如果需要删除内容,则遍历并删除所有内容
if del_content:
# 遍历路径下的所有内容
for item in folder.iterdir():
# 如果是文件夹,则递归调用
if item.is_dir():
delete_dir(item, del_content=True)
# 如果是文件则直接删除
else:
try:
item.unlink()
print(f"[INFO] 文件 {item} 已被删除") if verbose else ...
except FileNotFoundError:
print(f"[⚠️ WARNING] 文件 {item} 不存在,可能已被其他程序删除")
# 尝试删除空文件夹
try:
folder.rmdir()
return True
except Exception as e:
print(f"[❌ ERROR] 删除文件夹 {folder} 失败:{e}")
return False
else:
print(f"[⚠️ WARNING] 路径不存在或者不是文件夹!")
return False
参考
- https://docs.python.org/zh-cn/3.10/library/pathlib.html#pathlib.Path
- https://chatglm.cn/main/alltoolsdetail















 1108
1108











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









