









 本文深入探讨了线性码的计算型解码问题,包括校验子映射、解码算法和相关密码学应用。通过定义和分析校验子映射,阐述了如何从校验子计算码的陪集,并介绍了不同类型的解码问题,如最小距离解码、计算型 syndrome 解码和完全解码。此外,还讨论了这些解码问题在密码学中的应用,如构造哈希函数和伪随机生成器,并分析了它们在信息安全性方面的重要性。
本文深入探讨了线性码的计算型解码问题,包括校验子映射、解码算法和相关密码学应用。通过定义和分析校验子映射,阐述了如何从校验子计算码的陪集,并介绍了不同类型的解码问题,如最小距离解码、计算型 syndrome 解码和完全解码。此外,还讨论了这些解码问题在密码学中的应用,如构造哈希函数和伪随机生成器,并分析了它们在信息安全性方面的重要性。
参考文献:
- [BMT78] E. Berlekamp, R. McEliece and H. van Tilborg, “On the inherent intractability of certain coding problems (Corresp.),” in IEEE Transactions on Information Theory, vol. 24, no. 3, pp. 384-386, May 1978, doi: 10.1109/TIT.1978.1055873.
- [OS09] Overbeck R, Sendrier N. Code-based cryptography[M]//Post-quantum cryptography. Springer, Berlin, Heidelberg, 2009: 95-145.
校验子映射
考虑
[
n
,
k
]
q
[n,k]_q
[n,k]q线性码
C
\mathscr C
C,定义余维度(codimension)
r
=
n
−
k
r = n-k
r=n−k,令
H
H
H是其校验矩阵。定义校验子映射(syndrome mapping):
S
H
:
G
F
(
q
)
n
→
G
F
(
q
)
r
y
↦
y
H
T
\begin{aligned} S_H: GF(q)^n &\to GF(q)^r\\ y &\mapsto y H^T \end{aligned}
SH:GF(q)ny→GF(q)r↦yHT
再定义关于校验子
s
∈
G
F
(
q
)
r
s \in GF(q)^r
s∈GF(q)r的字集合:
S
H
−
1
(
s
)
:
=
{
y
∈
G
F
(
q
n
)
:
y
H
T
=
s
}
S_H^{-1}(s) := \{y \in GF(q^n): yH^T=s\}
SH−1(s):={y∈GF(qn):yHT=s}
易知,
S
H
−
1
(
0
)
=
C
S_H^{-1}(\pmb 0) = \mathscr C
SH−1(0)=C,定义码的陪集(coset):
y
+
C
:
=
{
y
+
x
:
x
∈
C
}
=
S
H
−
1
(
s
←
y
H
T
)
y+\mathscr C := \{y+x: x\in\mathscr C\} = S_H^{-1}(s \leftarrow yH^T)
y+C:={y+x:x∈C}=SH−1(s←yHT)
一共存在
2
r
2^r
2r个陪集,每个陪集都恰好包含
2
k
2^k
2k个元素。
任给一个校验子,存在有效算法计算对应的陪集,
- 将校验矩阵 H H H化为系统型 H 0 = U H = [ I r ∣ X ] ∈ G F ( q ) r × n H_0 = UH = [I_r|X] \in GF(q)^{r \times n} H0=UH=[Ir∣X]∈GF(q)r×n,这里的 U U U就是 H H H前 r r r列的逆 U = H { 1 , ⋯ , r } − 1 U=H_{\{1,\cdots,r\}}^{-1} U=H{1,⋯,r}−1
- 构造 y = [ s U T ∣ 0 ] ∈ G F ( q ) n y = [sU^T|\pmb 0] \in GF(q)^n y=[sUT∣0]∈GF(q)n,易知 y H T = y ( U − 1 H 0 ) T = [ s U T ∣ 0 ] [ I r ∣ X ] T U − T = s yH^T = y(U^{-1}H_0)^T = [sU^T|0][I_r|X]^TU^{-T} = s yHT=y(U−1H0)T=[sUT∣0][Ir∣X]TU−T=s
上述算法的复杂度是 O ( r 3 ) O(r^3) O(r3),多项式级别。
解码问题
不失一般性的,令 q = 2 q=2 q=2。
Decoding problem:令线性码 C \mathscr C C的校验矩阵为 H H H,给定一个字 y ∈ G F ( q ) n y \in GF(q)^n y∈GF(q)n以及对应的校验子 s ∈ G F ( q ) r s \in GF(q)^r s∈GF(q)r,下面是三种等价描述,
- 寻找一个码字 x ∈ C x \in \mathscr C x∈C使得它拥有与 y y y的最小汉明距离。
- 寻找一个错误 e ∈ S H − 1 ( s ) e \in S_H^{-1}(s) e∈SH−1(s)使得它拥有最小的汉明重量。
- 寻找一个错误 e ∈ y + C e \in y+\mathscr C e∈y+C使得它拥有最小的汉明重量。
然而,我们很难验证一个错误 e e e是否真的是陪集 y + C y+\mathscr C y+C里有最小汉明重量的那个元素。因此上述问题不属于 N P NP NP(多项式时间可验证),我们做适当修改。
Computational Syndrome Decoding:令线性码 C \mathscr C C的校验矩阵为 H H H,给定校验子 s ∈ G F ( q ) r s \in GF(q)^r s∈GF(q)r以及正整数 w > 0 w>0 w>0,寻找一个错误 e ∈ S H − 1 ( s ) e \in S_H^{-1}(s) e∈SH−1(s)使得它的汉明重量小于等于 w w w,记做 C S D ( H , w , s ) CSD(H,w,s) CSD(H,w,s)。
仅当
w
w
w使得上述问题高概率有单个解时,上述问题才有意义。可以选取
w
=
⌈
1.05
⋅
d
G
V
(
n
,
r
)
⌉
w = \lceil 1.05 \cdot d_{GV}(n,r)\rceil
w=⌈1.05⋅dGV(n,r)⌉,这里的
d
G
V
d_{GV}
dGV是 Gilbert-Varshamov distance,它被定义为使得下述不等式成立的最大正整数:
∑
i
=
0
d
0
−
1
(
n
i
)
≤
2
r
\sum_{i=0}^{d_0-1} {n \choose i} \le 2^r
i=0∑d0−1(in)≤2r
大多数二元线性码的最小距离
d
m
i
n
d_{min}
dmin都接近其GV距离
d
G
V
d_{GV}
dGV。
Codeword Finding:令线性码 C \mathscr C C的校验矩阵为 H H H,给定正整数 w > 0 w>0 w>0,寻找一个非零的码字 0 ≠ c ∈ S H − 1 ( 0 ) \pmb 0 \neq c \in S_H^{-1}(\pmb 0) 0=c∈SH−1(0)使得它的汉明重量小于等于 w w w,记做 C F ( H , w ) CF(H,w) CF(H,w)。
令 C ′ = C ∪ ( y + C ) \mathscr C' = \mathscr C \cup (y+\mathscr C) C′=C∪(y+C),其校验矩阵为 H ′ H' H′。很明显 C S D ( H , w , y H T ) CSD(H,w,yH^T) CSD(H,w,yHT)的解 e e e就是 C F ( H ′ , w ) CF(H',w) CF(H′,w)的解,因为 e ∈ y + C ⊆ C ′ e \in y+\mathscr C \subseteq \mathscr C' e∈y+C⊆C′。反之 C F ( H ′ , w ) CF(H',w) CF(H′,w)的解 e e e,当 w t ( e ) < d 0 wt(e)<d_0 wt(e)<d0时,几乎就是 e < d m i n ( C ) e<d_{min}(\mathscr C) e<dmin(C),因此很可能 e ∈ y + C e \in y+\mathscr C e∈y+C,从而它是 C S D ( H , w , y H T ) CSD(H,w,yH^T) CSD(H,w,yHT)的解;而当 w t ( e ) ≥ d 0 wt(e)\ge d_0 wt(e)≥d0时, C F ( H ′ , w ) CF(H',w) CF(H′,w)的一个随机解可能落在 C \mathscr C C里也可能落在 y + C y+\mathscr C y+C里,由于高维度随机码的测度性质与相同基数的随机集合不可区分,于是它有 1 / 2 1/2 1/2的概率是 C S D ( H , w , y H T ) CSD(H,w,yH^T) CSD(H,w,yHT)的解。
Complete Decoding:令线性码 C \mathscr C C的校验矩阵为 H H H,给定校验子 s ∈ G F ( q ) r s \in GF(q)^r s∈GF(q)r,寻找一个错误 e ∈ S H − 1 ( s ) e \in S_H^{-1}(s) e∈SH−1(s)使得它的汉明重量小于等于 d G V ( n , r ) d_{GV}(n,r) dGV(n,r)。
这个问题是最一般、同时也是最困难的计算型解码问题。
另外还有相应的决策版本解码问题(decisional syndrome decoding)。敌手可以通过访问线性次决策版本的预言机,便可以求解任意的 C S D CSD CSD实例,因此计算型和决策型之间没有“gap”。有文章证明,决策型解码问题属于 N P C NPC NPC。于是计算型解码问题在最坏情况下是 N P − h a r d NP-hard NP−hard的。
人们不认为存在关于 N P C NPC NPC类问题的量子算法,同时针对 N P NP NP类问题的量子算法也很难构造。
构造密码学部件
令可逆映射
ϕ
n
,
w
:
G
F
(
q
)
l
→
G
F
(
q
)
n
\phi_{n,w}: GF(q)^l \to GF(q)^n
ϕn,w:GF(q)l→GF(q)n定义为
ϕ
n
,
w
(
x
)
=
e
s
.
t
.
w
t
(
e
)
=
w
\phi_{n,w}(\pmb x) = e\,\,\, s.t.\,\,\, wt(e)=w
ϕn,w(x)=es.t.wt(e)=w
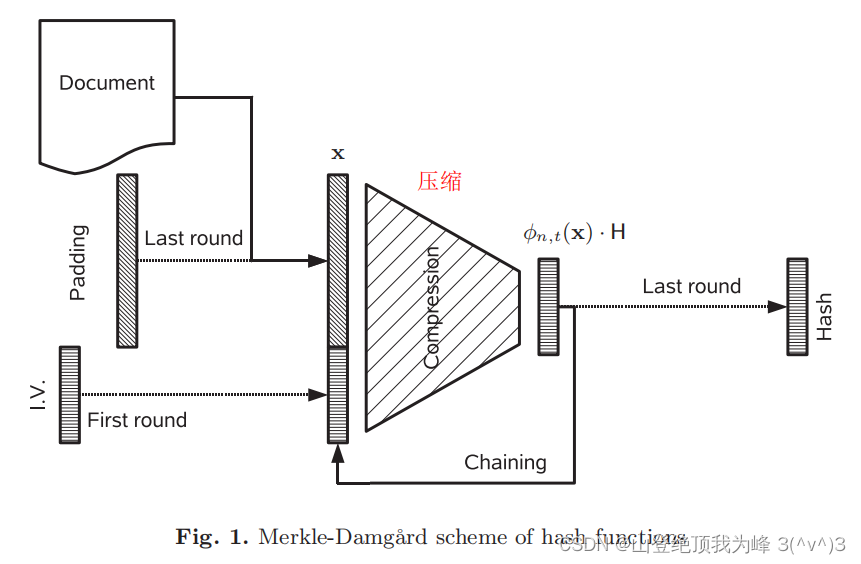
Hash
对于
[
n
,
k
]
[n,k]
[n,k]线性码,如果选择合适的
w
w
w满足如下关系:
(
n
w
)
(
q
−
1
)
w
−
1
≥
q
n
−
k
{n \choose w}(q-1)^{w-1} \ge q^{n-k}
(wn)(q−1)w−1≥qn−k
那么重量为
w
w
w的向量个数比线性码的校验子要多。如果针对校验子
s
s
s难以恢复重量为
w
w
w的向量(抗第二原像),那么计算校验子的过程可以作为一个压缩函数:
x
↦
ϕ
n
,
w
(
x
)
H
T
\pmb x \mapsto \phi_{n,w}(\pmb x)H^T
x↦ϕn,w(x)HT
PRG
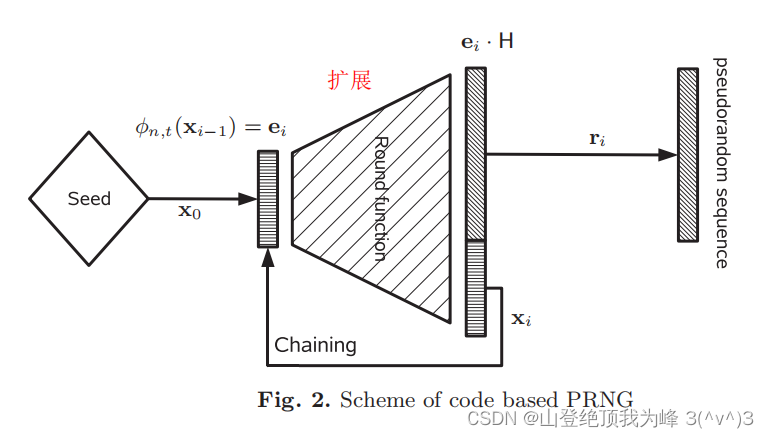
对于
[
n
,
k
]
[n,k]
[n,k]线性码,如果选择合适的
w
w
w满足如下关系:
(
n
w
)
(
q
−
1
)
w
−
1
≤
q
n
−
k
{n \choose w}(q-1)^{w-1} \le q^{n-k}
(wn)(q−1)w−1≤qn−k
那么重量为
w
w
w的向量个数比线性码的校验子要少。如果针对校验子
s
s
s依然难以恢复重量为
w
w
w的向量(OWP),那么计算校验子的过程可以作为一个扩展函数:
x
↦
ϕ
n
,
w
(
x
)
H
T
\pmb x \mapsto \phi_{n,w}(\pmb x)H^T
x↦ϕn,w(x)HT

















 975
975

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









